 NEWSLETTER
NEWSLETTER

Image by Author
When you thought you had heard enough news about Large Language Models (LLMs), Microsoft Research has come out to disturb the market again. In June 2023, Microsoft Research released a paper called “Textbooks is All You Need,” where they introduced phi-1, a new large language model for code. phi-1 is a transformer-based model with 1.3B parameters, which was trained for 4 days on 8 A100s GPUs, which used a selection of “textbook quality” data from the web.
It seems like LLMs are getting smaller and smaller.
Now Microsoft Research introduces to you phi-1.5, a Transformer with 1.3B parameters, which was trained using the same data sources as phi-1. As stated above, phi-1 was trained on high-quality textbook data, whereas phi-1.5 was trained on synthetic data only.
phi-1.5 used 32xA100-40G GPUs and was successfully trained in 8 days. The aim behind phi-1.5 was to craft an open-source model that can play a role in the research community using a non-restricted small model which allows you to explore the different safety challenges with LLMs, such as reducing toxicity, enhancing controllability, and more.
By using the ‘Synthetic Data Generation’ approach, phi-1.5 performance is equivalent to models that are 5x larger on natural language tests and has been shown to outperform most LLMs on more difficult reasoning tasks.
Pretty impressive right?
The model’s learning journey is very interesting. It draws data from a variety of sources, including Python code snippets from StackOverflow, synthetic Python textbooks as well exercises that were generated by GPT-3.5-turbo-0301.
One of the major challenges with LLMs is toxicity and biased content. Microsoft Research aimed to overcome this ongoing challenge of harmful/offensive content and content that promotes a specific ideology.
The synthetic data used to train the model generated responses with a lower propensity for generating toxic content in comparison to other LLMs such as Falcon-7B and Llama 2–7B, as shown in the image below:
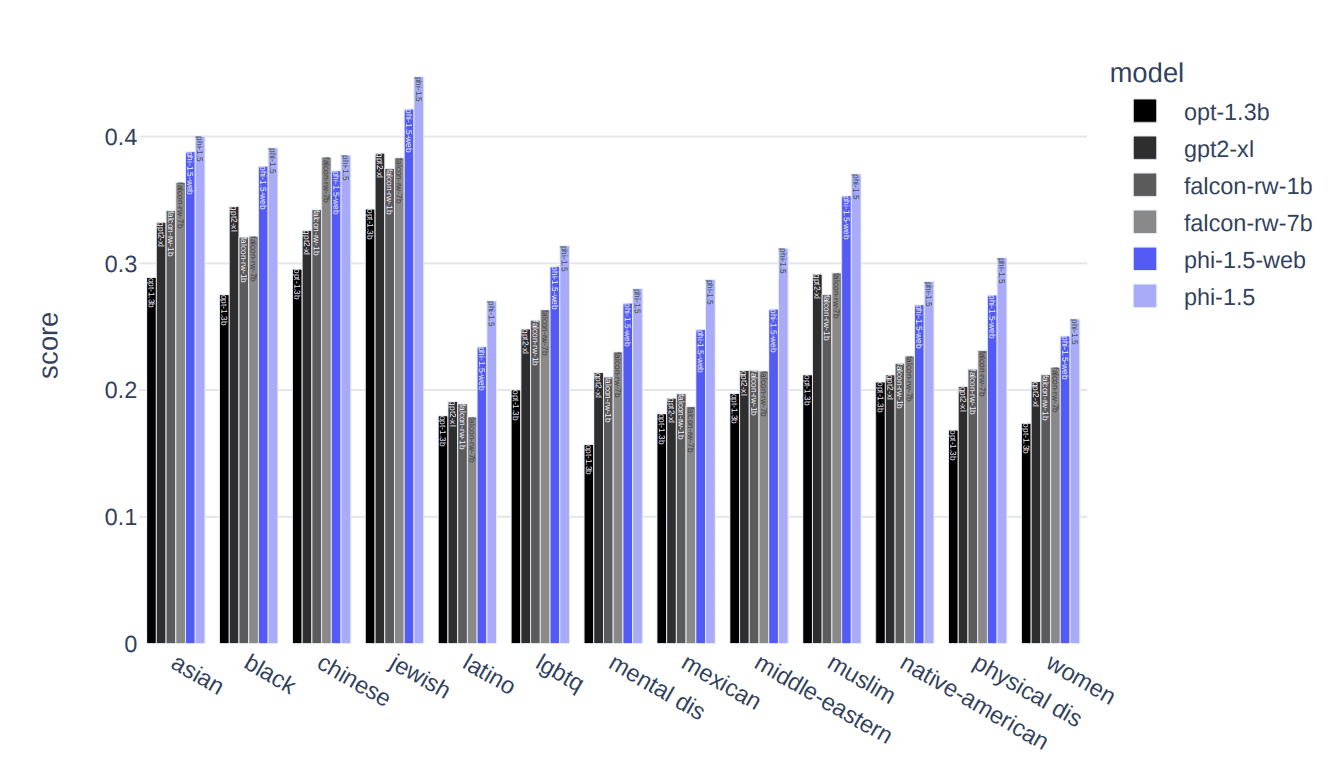
Image via Textbooks Are All You Need II: phi-1.5 technical report
The image below shows how phi-1.5 performed slightly better than state-of-the-art models, such as Llama 2–7B, Llama-7B, and Falcon-RW-1.3B) on 3 benchmarks: common sense reasoning, language skills, and multi-step reasoning.

Image via Textbooks Are All You Need II: phi-1.5 technical report
How was this done?
The use of textbook-like data differentiated the use of such data in LLMs in comparison to data extracted from the internet. To further assess how the model deals with toxic content, ToxiGen was used as well 86 prompts were designed and manually labeled ‘pass’, ‘fail’ or ‘did not understand’ to get a better understanding of the model’s limitations.
With this being said, phi-1.5 passed 47 prompts, failed 34 prompts and did not understand 4 prompts. The HumanEval approach to assess the models generates responses showing that phi-1.5 scored higher in comparison to other well-known models.
Here are the major talking points you should take away from here regarding phi-1.5:
- Is a transformer-based model
- Is a LLM that focuses on next-word prediction objectives
- Was trained on 30 billion tokens
- Used 32xA100-40G GPUs
- Was successfully trained in 8 days
Nisha Arya is a Data Scientist, Freelance Technical Writer and Community Manager at KDnuggets. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways artificial intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.






{kind=link}