 NEWSLETTER
NEWSLETTER
When writing the code for any program or algorithm, developers can have difficulty filling in gaps in incomplete code and often make mistakes when trying to fit new pieces into existing structures or code fragments. These challenges arise from the difficulty of adapting the latest code to the previous and next parts, especially when the broader part of the context is not taken into account. In recent years, Fill in the middle (FIM) has become an integral part of code language models, allowing the generation of missing code in both left and right contexts. Currently, the Fill-in-the-Middle (FIM) model works by rearranging sequences of code and using next token prediction (NTP) to fill in the gaps in the incomplete code. FIM also requires planning capabilities and the lack of them can make it difficult to predict missing code.
The current methods for FIM depend mainly on NLP techniques to estimate the missing part of the code and rely on reordering the training sequences and performing next token prediction (NTP). However, these methods do not work well in real-world coding scenarios because they are based on strict rules, such as generating the exact number of lines present in the original code, etc. Furthermore, the model's performance on FIM tasks deteriorates significantly without these unrealistic assumptions. . Standard NTP training does not efficiently prepare models for this long-term planning task. Consequently, models often struggle to maintain consistency over the longer sequences required in FIMparticularly when addressing the transition to the appropriate context. We believe that the prediction of the next token (NTP) alone does not help models plan well enough when it comes to the distant part of the code that comes after the missing section, which is crucial for generating accurate code in between.
To mitigate this problem, an auxiliary training objective, namely horizon length prediction (HLP), is added to improve the planning capabilities of LLMs at long horizons. Specifically, given the hidden state of the current token, HLP tasks the model with predicting the number of future tokens needed to complete the medium.
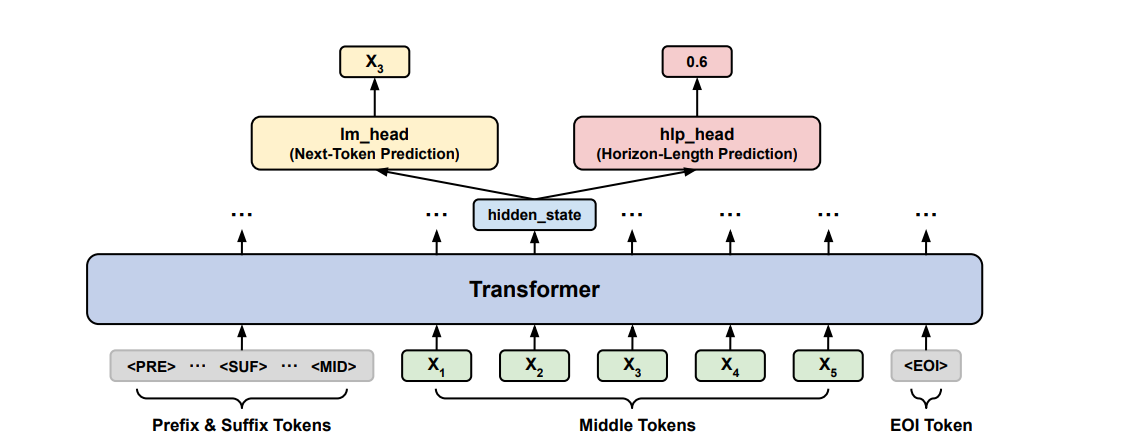
To solve this problem, researchers from the University of Illinois Urbana-Champaign and AWS-ai Labs collaborated to propose Horizon Longitude Prediction (HLP)as an efficient solution. HLLP is a novel training approach that teaches models to predict the number of remaining intermediate tokens (horizon length) at each step. It is implemented as a linear layer on top of the weighted transformer model, whose input is the hidden state of the last attention layer. Improves Fill-in-the-Middle (FIM) by teaching models to plan and consider a larger part. This helps models naturally learn how to fill in the blanks of any left and right sections of code, without the need for special rules or additional tuning. Unlike rule-based post-processing, HLP is generalizable as it does not require any task-specific knowledge.
The evaluation by the researchers also shows that HLP not only improves code filling by up to 24% on various benchmarks without using any rules-based post-processing and/or specific data set, but also improves performance on the reasoning of the code. They also found that HLP is super efficient as it only incurs negligible training overhead and does not add any inference overhead. Additionally, HLP adds minimal overhead during training and incurs no additional costs during inference, making it practical for real-world applications.
In conclusion, this paper presents horizon length prediction (HLP), a novel training objective designed to improve fill-in-the-middle (FIM) capabilities in code language models. By teaching models to predict the number of remaining tokens, HLP significantly improves the planning and consistency of generated code, achieving performance gains of up to 24% across various benchmarks without relying on restrictive post-processing methods. Furthermore, the improved planning ability acquired through HLP training also increases the performance of models on code reasoning tasks, suggesting that HLP can broadly improve the reasoning capabilities of language models. Furthermore, HLP is also efficient as it does not cause any inference overhead and the training overhead is also negligible. This research marks a significant step in developing more effective code language models for real-world applications.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 50,000ml
(Next Event: Oct 17, 202) RetrieveX – The GenAI Data Recovery Conference (Promoted)
Divyesh is a Consulting Intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of technology Kharagpur. He is a data science and machine learning enthusiast who wants to integrate these leading technologies in agriculture and solve challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}