 NEWSLETTER
NEWSLETTER
Using advanced ai models, video generation involves creating moving images from textual descriptions or static images. This area of research seeks to produce high-quality, realistic videos while overcoming significant computational challenges. ai-generated videos find applications in diverse fields such as cinematography, education, and video simulations, and offer an efficient way to automate video production. However, the computational demands for generating long, visually consistent videos remain a key hurdle, driving researchers to develop methods that balance quality and efficiency in video generation.
A major problem in video generation is the huge computational cost associated with creating each frame. The iterative process of denoising, where noise is gradually removed from a latent representation until the desired visual quality is achieved, is time-consuming. This process must be repeated for each frame of a video, making the time and resources required to produce high-resolution or long-form videos prohibitive. The challenge, therefore, is to optimize this process without sacrificing the quality and consistency of the video content.
Existing methods such as probabilistic denoising diffusion models (DDPM) and video diffusion models (VDM) have successfully generated high-quality videos. These models refine video frames using denoising steps, resulting in detailed and coherent images. However, each frame undergoes a full denoising process, which increases computational demands. Solutions such as latent shifting attempt to reuse latent features across frames, but still require improvements in terms of efficiency. These methods struggle to generate long-duration or high-resolution videos without significant computational overhead, leading to the need for more effective approaches.
A research team has introduced the Diffusion Reuse Motion (Dr. Mo) network to solve the inefficiency of current video generation models. Dr. Mo reduces the computational burden by leveraging motion coherence across consecutive video frames. The researchers observed that noise patterns remain constant across many frames in the early stages of the denoising process. Dr. Mo uses this coherence to propagate coarse-grained noise from one frame to the next, eliminating redundant computations. Furthermore, the Denoising Step Selector (DSS), a meta-network, dynamically determines the appropriate step to switch from motion propagation to traditional denoising, further optimizing the generation process.
In detail, Dr. Mo constructs motion matrices to capture semantic motion features between frames. These matrices are formed from the latent features extracted by a U-Net-like decoder, which analyzes motion between consecutive video frames. The DSS then evaluates which denoising steps can reuse motion-based estimates instead of recomputing each frame from scratch. This approach allows the system to balance efficiency and video quality. Dr. Mo reuses noise patterns to speed up the process in the early stages of denoising. As video generation nears completion, finer details are restored through the traditional diffusion model, ensuring high visual quality. The result is a faster system that generates video frames while maintaining clarity and realism.
The research team extensively evaluated Dr. Mo’s performance on well-known datasets such as UCF-101 and MSR-VTT. The results showed that Dr. Mo not only significantly reduced computational time but also maintained high video quality. When generating 16-frame videos at 256×256 resolution, Dr. Mo achieved a 4x speedup compared to Latent-Shift, completing the task in just 6.57 seconds, while Latent-Shift required 23.4 seconds. For videos at 512×512 resolution, Dr. Mo was 1.5x faster than competing models such as SimDA and LaVie, generating videos in 23.62 seconds compared to SimDA’s 34.2 seconds. Despite this speedup, Dr. Mo preserved 96% of the inception score (IS) and even improved the Fréchet video distance (FVD) score, indicating that he produced visually coherent videos closely aligned with the ground truth.
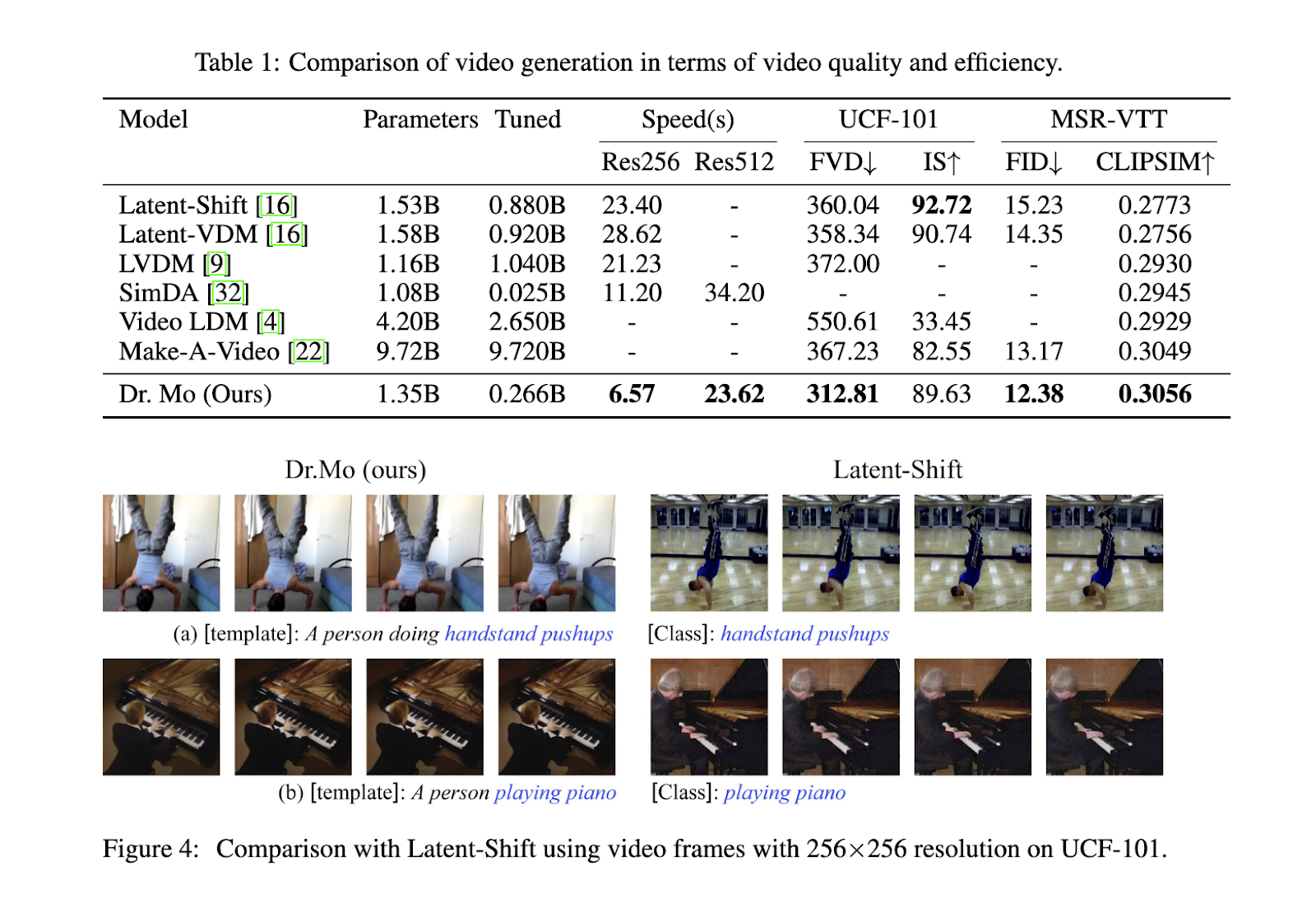
Video quality metrics further emphasized Dr. Mo’s efficiency. On the UCF-101 dataset, Dr. Mo achieved an FVD score of 312.81, significantly outperforming Latent-Shift, which had a score of 360.04. Dr. Mo scored 0.3056 on the CLIPSIM metric on the MSR-VTT dataset, a measure of semantic alignment between video frames and text inputs. This score outperformed all tested models, demonstrating his superior performance on text-to-video generation tasks. Additionally, Dr. Mo excelled in style transfer applications, where motion information from real-world videos was applied to the first few style-transferred frames, yielding consistent and realistic results across all generated frames.
In conclusion, Dr. Mo provides a significant advancement in the field of video generation by offering a method that dramatically reduces computational demands without compromising video quality. By intelligently reusing motion information and employing a dynamic denoising step selector, the system efficiently generates high-quality videos in less time. This balance between efficiency and quality marks a fundamental advancement in addressing the challenges associated with video generation.
Take a look at the Paperto and ProjectAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
FREE ai WEBINAR: 'SAM 2 for Video: How to Optimize Your Data' (Wednesday, September 25, 4:00 am – 4:45 am EST)
Nikhil is a Consultant Intern at Marktechpost. He is pursuing an integrated dual degree in Materials from Indian Institute of technology, Kharagpur. Nikhil is an ai and Machine Learning enthusiast who is always researching applications in fields like Biomaterials and Biomedical Science. With a strong background in Materials Science, he is exploring new advancements and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}