
High-resolution images are very common in today’s world, from satellite images to drones and DLSR cameras. From these images, we can capture damage due to natural disasters, anomalies in manufacturing equipment, or very small defects such as defects in printed circuit boards (PCBs) or semiconductors. Building anomaly detection models using high-resolution images can be challenging because modern computer vision models typically resize images to a lower resolution to fit them in memory for training and running inferences. Significantly reducing image resolution means that visual information related to the defect is degraded or lost completely.
One approach to overcome these challenges is to build two-stage models. Stage 1 models detect a region of interest and stage 2 models detect defects in the cropped region of interest, thus maintaining sufficient resolution for small detection.
In this post, we review how to build an effective two-stage defect detection system using custom Amazon Rekognition tags and compare the results for this specific use case with one-stage models. Note that several single-stage models are effective even at lower or resized image resolutions, and others can accommodate large images in smaller batches.
Solution Overview
For our use case, we use a PCB image data set with synthetically generated missing hole pins, as shown in the example below.

We use this data set to demonstrate that a one-stage approach using object detection results in poor detection performance for missing pin defects. A two-step model is preferred, where we use custom Rekognition labels first for object detection to identify pins and then a second-stage model to classify cropped images of pins into pins to which Normal holes or pins are missing.
The training process for a Rekognition custom tag model consists of several steps, as illustrated in the following diagram.
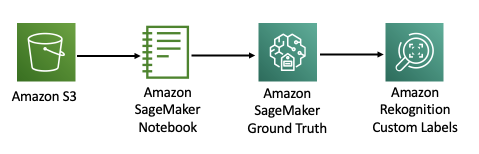
First, we use Amazon Simple Storage Service (Amazon S3) to store the image data. The data is fed into Amazon Sagemaker Jupyter notebooks, where a data scientist typically inspects the images and pre-processes them, removing any images that are of poor quality, such as blurry images or poor lighting conditions, and resizing them or resizing them. trim. The data is then split into training and test sets, and Amazon SageMaker Ground Truth labeling jobs are run to label the image sets and generate a training and test manifest file. Rekognition Custom Labels uses the manifest files for training.
One-stage model approach
The first approach we take to identify missing holes on the PCB is to label the missing holes and train an object detection model to identify the missing holes. The following is an example image of the data set.

We train a model with a dataset with 95 images used as training and 20 images used for testing. The following table summarizes our results.
| Evaluation results | |||||
| F1 Score | Average precision | General reminder | |||
| 0.468 | 0.750 | 0.340 | |||
| Training time | Training data set | Test data set | |||
| Formed in 1,791 hours | 1 tag, 95 images | 1 tag, 20 images | |||
| Performance by label | |||||
| Tag name | F1 Score | test images | Precision | Remember | Assumed threshold |
missing_hole |
0.468 | twenty | 0.750 | 0.340 | 0.053 |
The resulting model has high precision but low recall, meaning that when we locate a region for a missing hole, we usually get it right, but we are missing many missing holes that are present on the PCB. To build an effective defect detection system, we need to improve recovery. The poor performance of this model may be because the defects are small in this high resolution image of the PCB, so the model does not have a reference of a good pin.
Next, we explored dividing the image into four or six crops based on the size of the PCB and labeling the healthy and missing holes. The following is an example of the resulting cropped image.
We trained a model with 524 images used for training and 106 images used for testing. We maintain the same PCBs used in training and testing as the full board model. The results for trimmed healthy pins versus missing holes are shown in the table below.
| Evaluation results | |||||
| F1 Score | Average precision | General reminder | |||
| 0.967 | 0.989 | 0.945 | |||
| Training time | Training data set | Test data set | |||
| Trained in 2,118 hours | 2 tags, 524 images | 2 tags, 106 images | |||
| Performance by label | |||||
| Tag name | F1 Score | test images | Precision | Remember | Assumed threshold |
missing_hole |
0.949 | 42 | 0.980 | 0.920 | 0.536 |
pin |
0.984 | 106 | 0.998 | 0.970 | 0.696 |
Both precision and recall have improved significantly. It was helpful to train the model with zoomed-in cropped images and a reference to the model for healthy pins. However, the recovery is still 92%, meaning we would still miss 8% of the missing holes and let the defects go unnoticed.
Next, we explore a two-stage model approach in which we can further improve the model performance.
Two-stage model approach
For the two-stage model, we train two models: one to detect pins and another to detect whether the pin is missing or not in enlarged cropped images of the pin. The following is a picture of the pin detection data set.

The data is similar to our previous experiment, where we cropped the PCB into four or six cropped images. This time, we label all the pins and make no distinction whether the pin is missing a hole or not. We trained this model with 522 images and tested it with 108 images, keeping the same train/test split as in previous experiments. The results are shown in the following table.
| Evaluation results | |||||
| F1 Score | Average precision | General reminder | |||
| 1,000 | 0.999 | 1,000 | |||
| Training time | Training data set | Test data set | |||
| Formed in 1,581 hours | 1 tag, 522 images | 1 tag, 108 images | |||
| Performance by label | |||||
| Tag name | F1 Score | test images | Precision | Remember | Assumed threshold |
pin |
1,000 | 108 | 0.999 | 1,000 | 0.617 |
The model perfectly detects the pins in this synthetic data set.
Next, we build the model to distinguish the missing holes. We use cropped images of the holes to train the second stage of the model, as shown in the following examples. This model is separate from the previous models because it is a classification model and will focus on the specific task of determining if the pin is missing a hole.
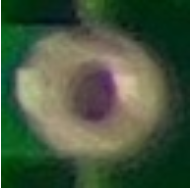

We trained this second-stage model on 16,624 images and tested on 3,266, keeping the same training/test splits as in the previous experiments. The following table summarizes our results.
| Evaluation results | |||||
| F1 Score | Average precision | General reminder | |||
| 1,000 | 1,000 | 1,000 | |||
| Training time | Training data set | Test data set | |||
| Trained in 6,660 hours | 2 tags, 16,624 images | 2 tags, 3266 images | |||
| Performance by label | |||||
| Tag name | F1 Score | test images | Precision | Remember | Assumed threshold |
anomaly |
1,000 | 88 | 1,000 | 1,000 | 0.960 |
normal |
1,000 | 3,178 | 1,000 | 1,000 | 0.996 |
Again, we received perfect precision and recall on this synthetic data set. By combining the above pin detection model with this second-stage missing hole classification model, we can build a model that outperforms any single-stage model.
The following table summarizes the experiments we performed.
| Experiment | Guy | Description | F1 Score | Precision | Remember |
| 1 | One stage model | Object detection model to detect missing holes in full images | 0.468 | 0.75 | 0.34 |
| 2 | One stage model | Object detection model to detect healthy pins and missing holes in cropped images | 0.967 | 0.989 | 0.945 |
| 3 | Two-stage model | Stage 1: Object detection on all pins | 1,000 | 0.999 | 1,000 |
| Stage 2: Classification of images of healthy pins or missing holes | 1,000 | 1,000 | 1,000 | ||
| End-to-end average | 1,000 | 0.9995 | 1,000 |
inference pipeline
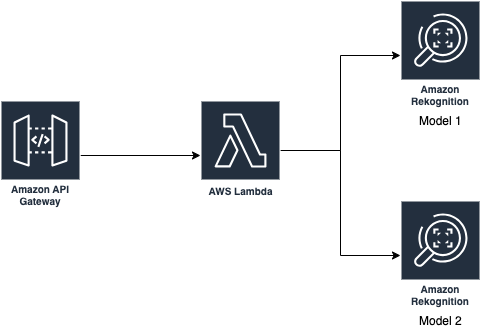
You can use the following architecture to implement the one- and two-stage models we describe in this post. The following main components are involved:
For single-stage models, you can send an input image to the API Gateway endpoint, followed by Lambda for any basic image preprocessing, and route it to the Rekognition Custom Labels trained model endpoint. In our experiments, we explore one-stage models that can detect only missing holes, missing holes, and healthy pins.

For two-stage models, you can similarly push an image to the API Gateway endpoint, followed by Lambda. Lambda acts as an orchestrator that first calls the object detection model (trained with custom Rekognition tags), which generates the region of interest. The original image is then cropped in the Lambda function and sent to another Rekognition custom label classification model to detect defects in each cropped image.
Conclusion
In this post, we train one- and two-stage models to detect missing holes in PCBs using custom Rekognition tags. We report results for several models; In our case, the two-stage models outperformed other variants. We encourage customers with high-resolution images from other domains to test model performance with one- and two-stage models. Additionally, consider the following ways to extend the solution:
- Sliding window snippets for your real data sets
- Reuse your object detection models in the same process
- Pre-labeling workflows using bounding box predictions
About the authors
 Andreas Karagounis is a data science manager at Accenture. She has a master’s degree in Computer Science from Brown University. She has a background in computer vision and works with clients to solve their business challenges using data science and machine learning.
Andreas Karagounis is a data science manager at Accenture. She has a master’s degree in Computer Science from Brown University. She has a background in computer vision and works with clients to solve their business challenges using data science and machine learning.
 Yogesh Chaturvedi is a Principal Solutions Architect at AWS with a focus on computer vision. He works with clients to address their business challenges using cloud technologies. Outside of work, he enjoys hiking, traveling, and watching sports.
Yogesh Chaturvedi is a Principal Solutions Architect at AWS with a focus on computer vision. He works with clients to address their business challenges using cloud technologies. Outside of work, he enjoys hiking, traveling, and watching sports.
 Shreyas Subramanian is a Principal Data Scientist and helps clients by using machine learning to solve their business challenges using the AWS platform. Shreyas has experience in large-scale optimization and machine learning, and using machine learning and reinforcement learning to accelerate optimization tasks.
Shreyas Subramanian is a Principal Data Scientist and helps clients by using machine learning to solve their business challenges using the AWS platform. Shreyas has experience in large-scale optimization and machine learning, and using machine learning and reinforcement learning to accelerate optimization tasks.
 Selimcan “Can” Sakar is a cloud developer and solutions architect at AWS Accenture Business Group with a focus on emerging technologies such as GenAI, ML, and blockchain. When he’s not watching models converge, he can be seen riding a bicycle or playing the clarinet.
Selimcan “Can” Sakar is a cloud developer and solutions architect at AWS Accenture Business Group with a focus on emerging technologies such as GenAI, ML, and blockchain. When he’s not watching models converge, he can be seen riding a bicycle or playing the clarinet.






{kind=link}