 NEWSLETTER
NEWSLETTER
Phishing is the process of attempting to acquire sensitive information such as usernames, passwords and credit card details by masquerading as a trustworthy entity using email, telephone or text messages. There are many types of phishing based on the mode of communication and targeted victims. In an Email phishing attempt, an email is sent as a mode of communication to group of people. There are traditional rule-based approaches to detect email phishing. However, new trends are emerging that are hard to handle with a rule-based approach. There is need to use machine learning (ML) techniques to augment rule-based approaches for email phishing detection.
In this post, we show how to use amazon Comprehend Custom to train and host an ML model to classify if the input email is an phishing attempt or not. amazon Comprehend is a natural-language processing (NLP) service that uses ML to uncover valuable insights and connections in text. You can use amazon Comprehend to identify the language of the text; extract key phrases, places, people, brands, or events; understand sentiment about products or services; and identify the main topics from a library of documents. You can customize amazon Comprehend for your specific requirements without the skillset required to build ML-based NLP solutions. Comprehend Custom builds customized NLP models on your behalf, using training data that you provide. Comprehend Custom supports custom classification and custom entity recognition.
Solution overview
This post explains how you can use amazon Comprehend to easily train and host an ML based model to detect phishing attempt. The following diagram shows how the phishing detection works.
You can use this solution with your email servers in which emails are passed through this phishing detector. When an email is flagged as a phishing attempt, the email recipient still gets the email in their mailbox, but they can be shown an additional banner highlighting a warning to the user.
You can use this solution for experimentation with the use case, but AWS recommends building a training pipeline for your environments. For details on how to build a classification pipeline with amazon Comprehend, see Build a classification pipeline with amazon Comprehend custom classification.
We walk through the following steps to build the phishing detection model:
- Collect and prepare the dataset.
- Load the data in an amazon Simple Storage Service (amazon S3) bucket.
- Create the amazon Comprehend custom classification model.
- Create the amazon Comprehend custom classification model endpoint.
- Test the model.
Prerequisites
Before diving into this use case, complete the following prerequisites:
- Set up an AWS account.
- Create an S3 bucket. For instructions, see Create your first S3 bucket.
- Download the email-trainingdata.csv and upload the file to the S3 bucket.
Collect and prepare the dataset
Your training data should have both phishing and non-phishing emails. Email users with in the organization are asked to report phishing through their email clients. Gather all these phishing reports and examples of non-phishing emails to prepare the training data. You should have a minimum 10 examples per class. Label phishing emails as phishing and non-phishing emails as nonphishing. For minimum training requirements, see General quotas for document classification. Although minimum labels per class is a starting point, it’s recommended to provide hundreds of labels per class for performance on classification tasks across new inputs.
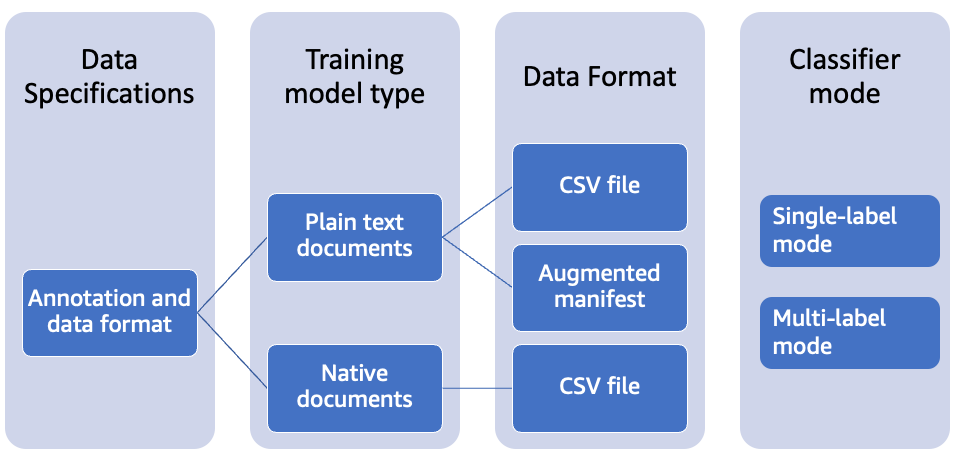
For custom classification, you train the model in either single-label mode or multi-label mode. Single-label mode associates a single class with each document. Multi-label mode associates one or more classes with each document. For this case, we will use single-label mode – phishing or nonphishing. The individual classes are mutually exclusive. For example, you can classify an email as phishing or not-phishing, but not both.
Custom classification supports models that you train with plain-text documents and models that you train with native documents (such as PDF, Word, or images). For more information about classifier models and their supported document types, see Training classification models. For a plain-text model, you can provide classifier training data as a CSV file or as an augmented manifest file that you create using amazon SageMaker Ground Truth. The CSV file or augmented manifest file includes the text for each training document, and its associated labels.For a native document model, you provide classifier training data as a CSV file. The CSV file includes the file name for each training document and its associated labels. You include the training documents in the S3 input folder for the training job.
For this case, we will train a plain-text model using CSV file format. For each row, the first column contains the class label value. The second column contains an example text document for that class. Each row must end with \n or \r\n characters.
The following example shows a CSV file containing two documents.
CLASS,Text of document 1
CLASS,Text of document 2
The following example shows two rows of a CSV file that trains a custom classifier to detect whether an email message is phishing:
phishing, “Hi, we need account details and SSN information to complete the payment. Please furnish your credit card details in the attached form.”
nonphishing,” Dear Sir / Madam, your latest statement was mailed to your communication address. After your payment is received, you will receive a confirmation text message at your mobile number. Thanks, customer support”
For information about preparing your training documents, see Preparing classifier training data.
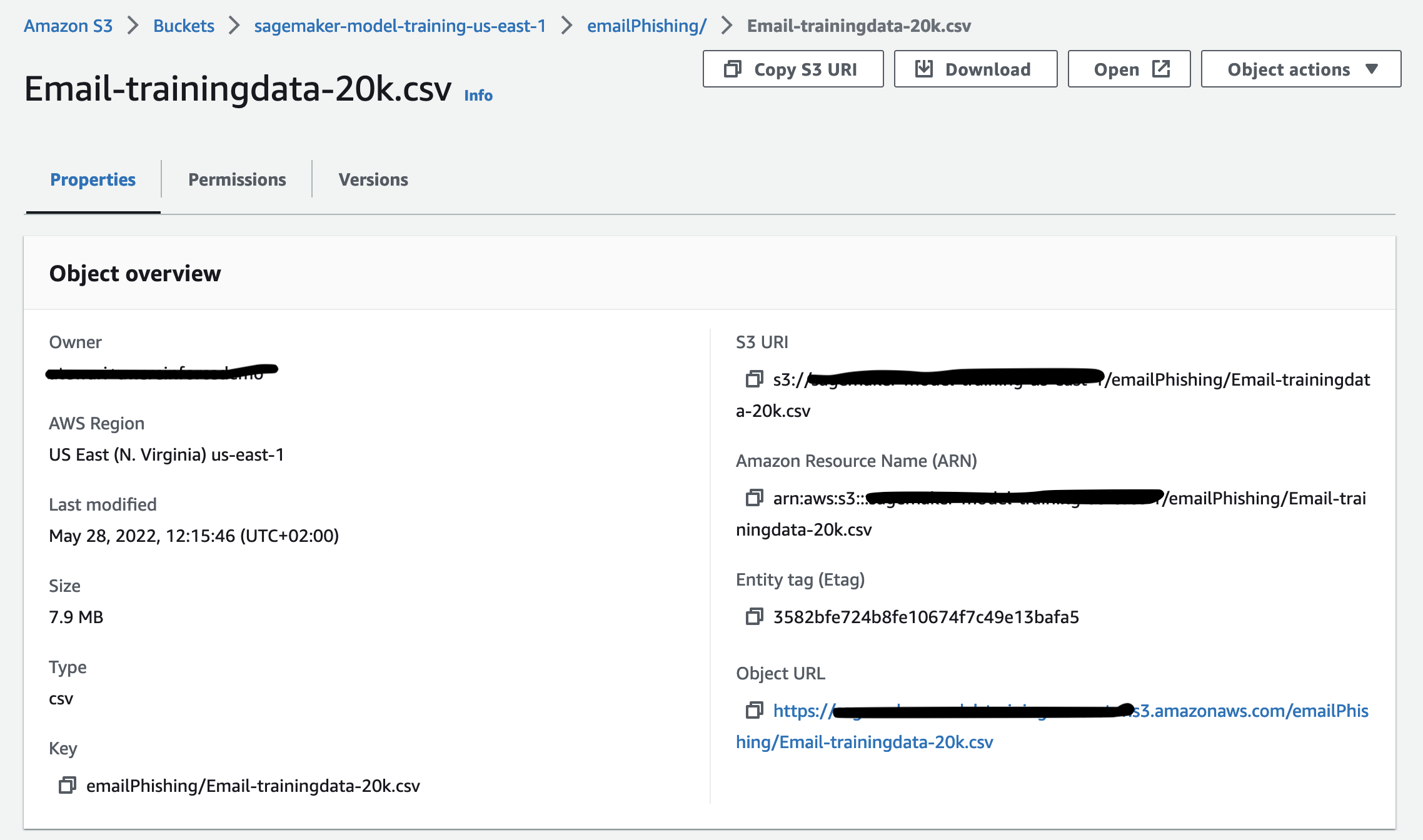
Load the data in the S3 bucket
Load the training data in CSV format to the S3 bucket you created in the prerequisite steps. For instructions, refer to Uploading objects.
Create the amazon Comprehend custom classification model
Custom classification supports two types of classifier models: plain-text models and native document models. A plain-text model classifies documents based on their text content. You can train the plain-text model using documents in one of following languages: English, Spanish, German, Italian, French, or Portuguese. The training documents for a given classifier must all use the same language. A native document model has the ability to process both scanned or digital semi-structured documents like PDFs, Microsoft Word documents, and images in their native format. A native document model also classifies documents based on text content. A native document model can also use additional signals, such as from the layout of the document. You train a native document model with native documents for the model to learn the layout information. You train the model using semi-structured documents, which includes the following document types such as digital and scanned PDF documents and Word documents; Images sunch as JPG files, PNG files, and single-page TIFF files and amazon Textract API output JSON files. AWS recommends using a plain-text model to classify plain-text documents and a native document model to classify semi-structured documents.
Data specification for the custom classification model can be represented as follows.
You can train a custom classifier using either the amazon Comprehend console or API. Allow several minutes to a few hours for the classification model creation to complete. The length of time varies based on the size of your input documents.
For training a customer classifier on the amazon Comprehend console, set the following data specification options.
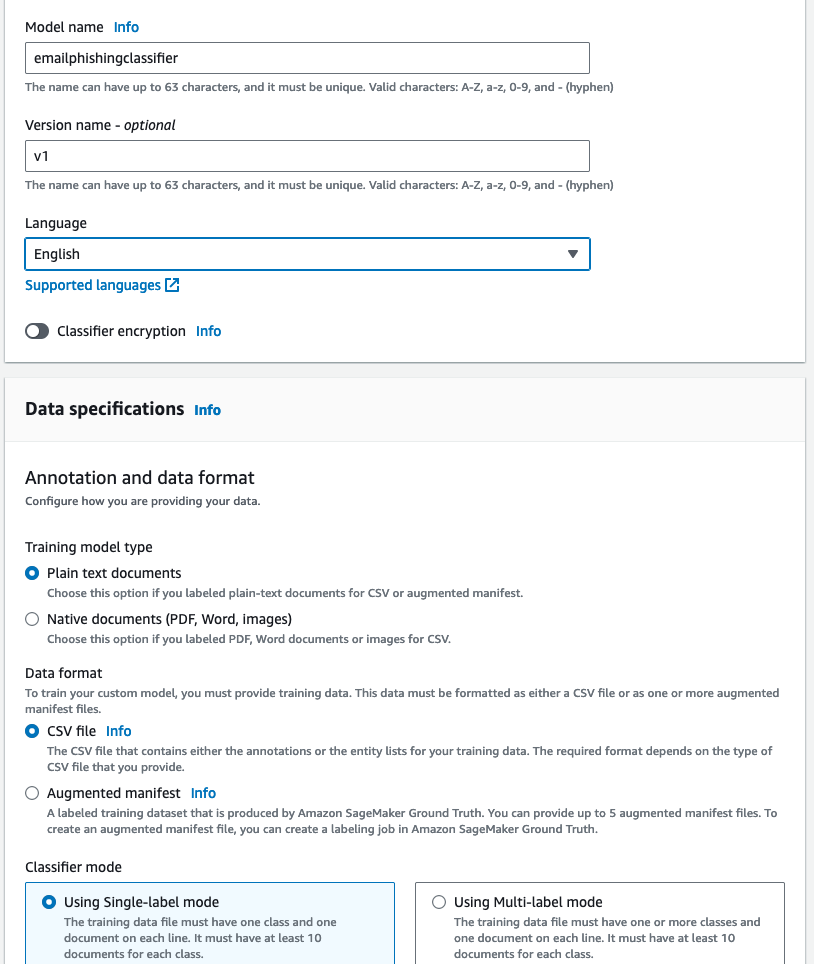
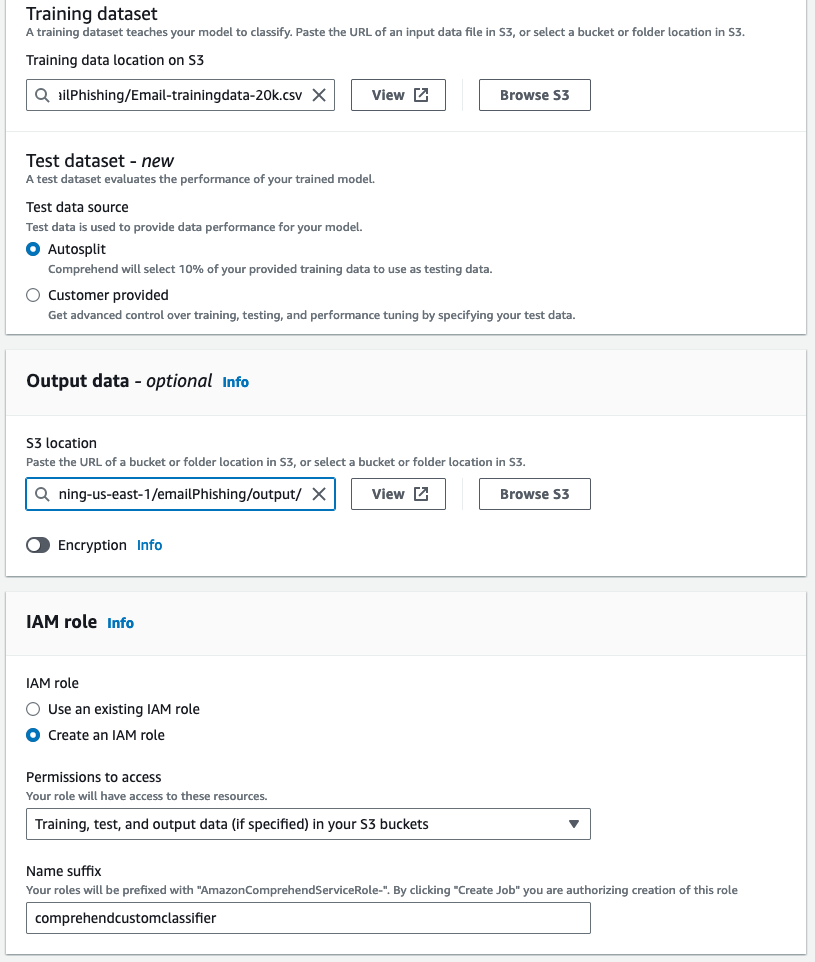
On the Classifiers page of the amazon Comprehend console, the new classifier appears in the table, showing Submitted as its status. When the classifier starts processing the training documents, the status changes to Training. When a classifier is ready to use, the status changes to Trained or Trained with warnings. If the status is Trained with Warnings, review the skipped files folder in the classifier training output.
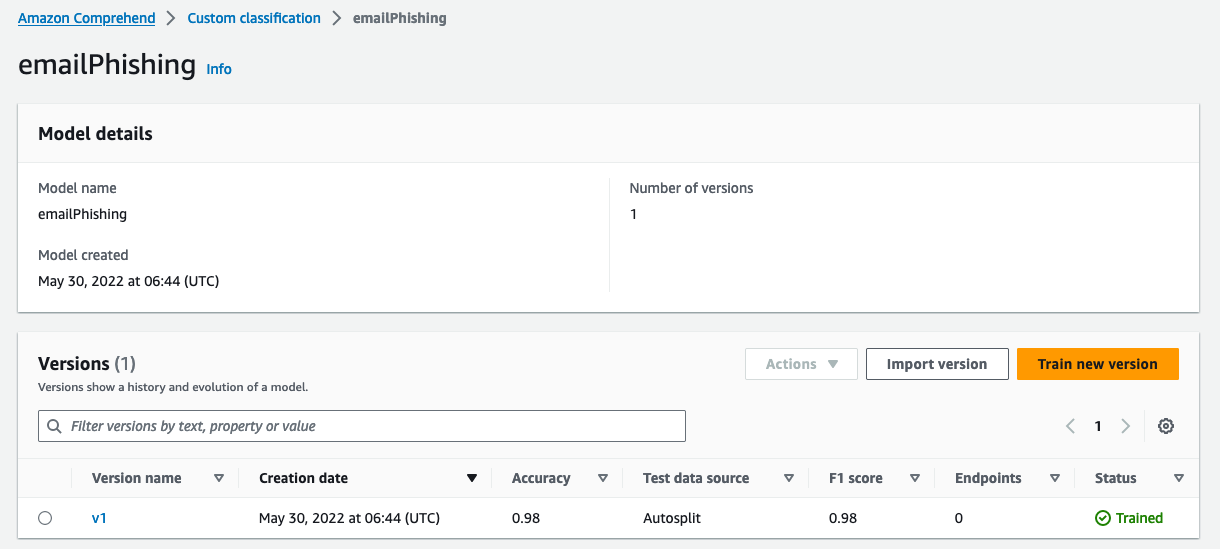
If amazon Comprehend encountered errors during creation or training, the status changes to In error. You can choose a classifier job in the table to get more information about the classifier, including any error messages.
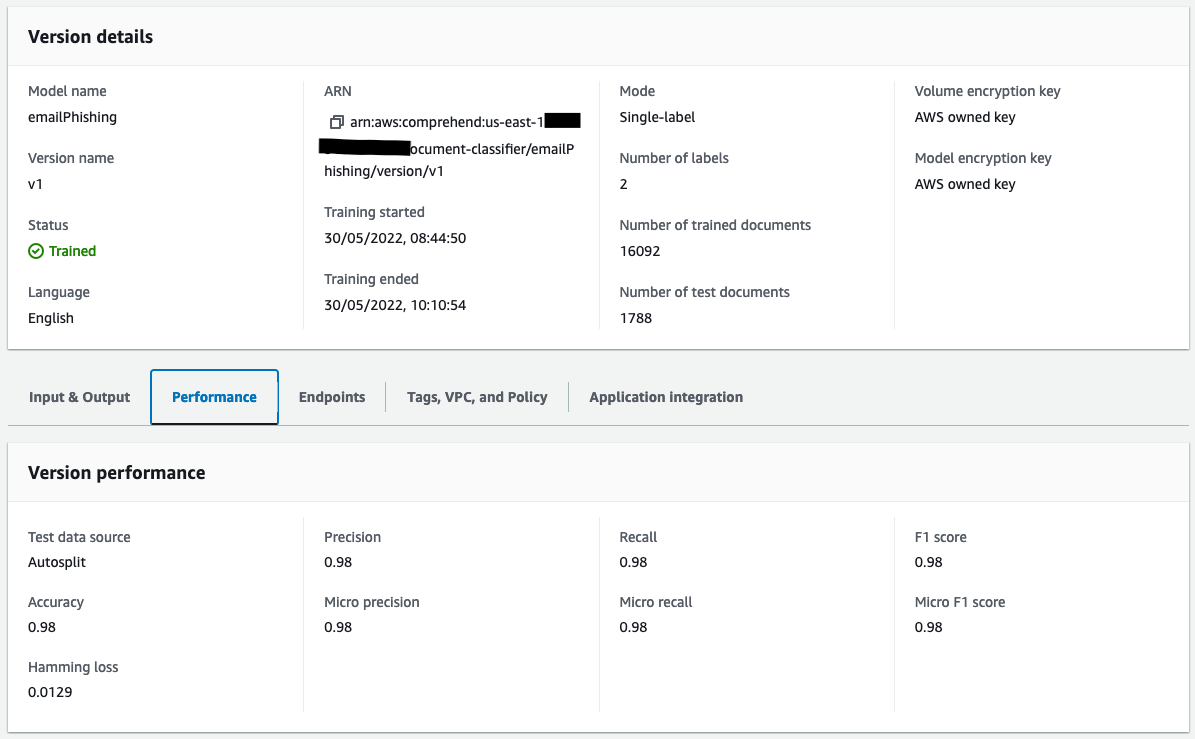
After training the model, amazon Comprehend tests the custom classifier model. If you don’t provide a test dataset, amazon Comprehend trains the model with 90% of the training data. It reserves 10% of the training data to use for testing. If you do provide a test dataset, the test data must include at least one example for each unique label in the training dataset.
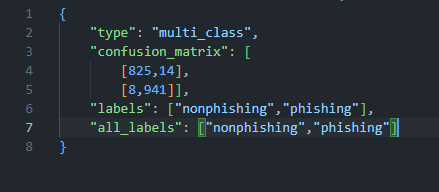
After amazon Comprehend completes the custom classifier model training, it creates output files in the amazon S3 output location that you specified in the CreateDocumentClassifier API request or the equivalent amazon Comprehend console request. These output files are a confusion matrix and additional outputs for native document models. The format of the confusion matrix varies, depending on whether you trained your classifier using multi-class mode or multi-label mode.
After amazon Comprehend creates the classifier model, the confusion matrix is available in the confusion_matrix.json file in the amazon S3 output location. This confusion matrix provides metrics on how well the model performed in training. This matrix shows a matrix of labels that the model predicted, compared to the actual document labels. amazon Comprehend uses a portion of the training data to create the confusion matrix. The following JSON file represents the matrix in confusion_matrix.json as an example.
amazon Comprehend provides metrics to help you estimate how well a custom classifier performs. amazon Comprehend calculates the metrics using the test data from the classifier training job. The metrics accurately represent the performance of the model during training, so they approximate the model performance for classification of similar data.
Use the amazon Comprehend console or API operations such as DescribeDocumentClassifier to retrieve the metrics for a custom classifier.
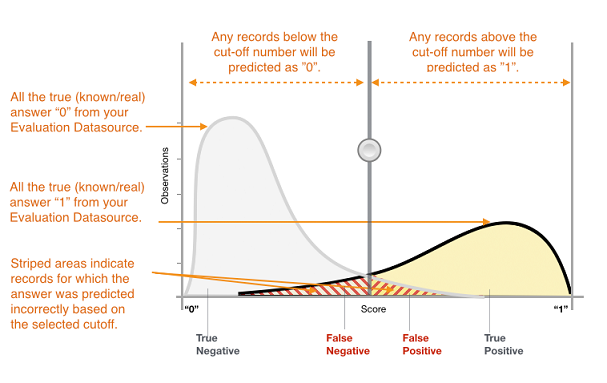
The actual output of many binary classification algorithms is a prediction score. The score indicates the system’s certainty that the given observation belongs to the positive class. To make the decision about whether the observation should be classified as positive or negative, as a consumer of this score, you interpret the score by picking a classification threshold and comparing the score against it. Any observations with scores higher than the threshold are predicted as the positive class, and scores lower than the threshold are predicted as the negative class.
Create the amazon Comprehend custom classification model endpoint
After you train a custom classifier, you can classify documents using Real-time analysis or an analysis job. Real-time analysis takes a single document as input and returns the results synchronously. An analysis job is an asynchronous job to analyze large documents or multiple documents in one batch. The following are the different options for using the custom classifier model.
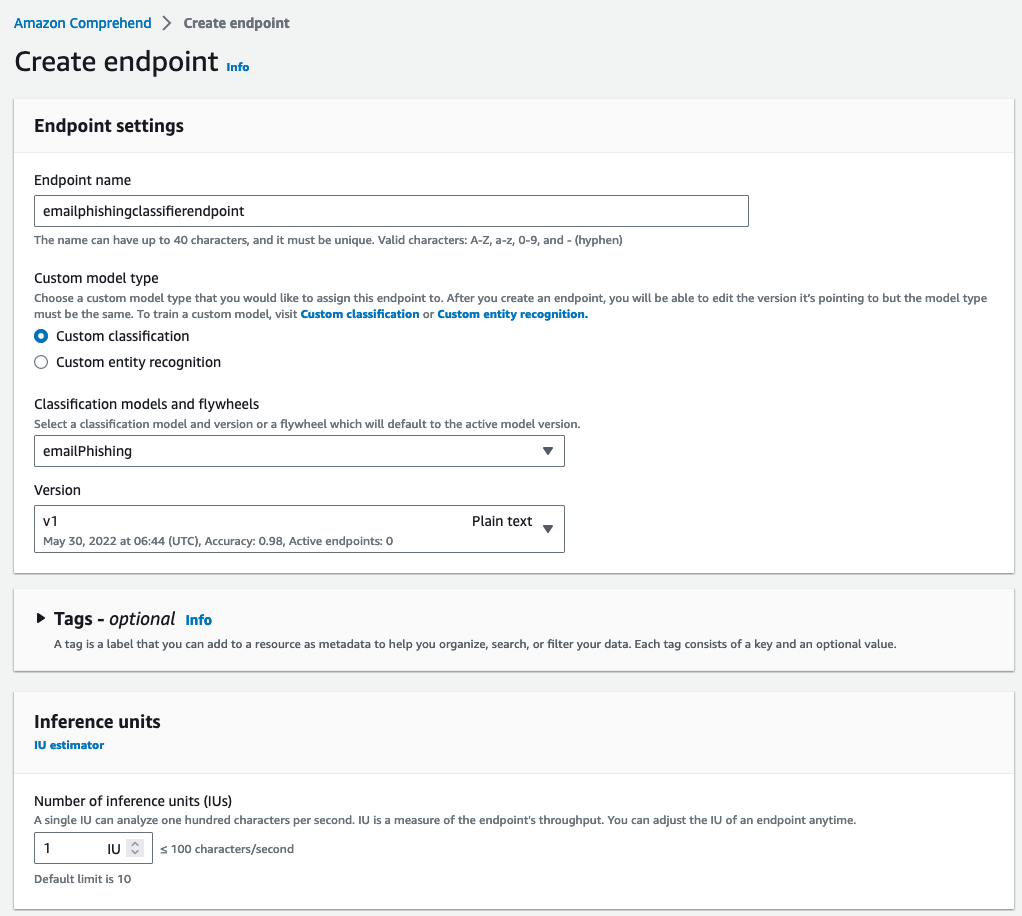
Create an endpoint for the trained model. For instructions, refer to Real-tome analysis for customer classification (console). amazon Comprehend assigns throughput to an endpoint using Inference Units (IU). An IU represents data throughput of 100 characters per second. You can provision the endpoint with up to 10 IU. You can scale the endpoint throughput either up or down by updating the endpoint. Endpoints are billed on 1-second increments, with a minimum of 60 seconds. Charges will continue to incur from the time you start the endpoint until it is deleted even if no documents are analyzed.
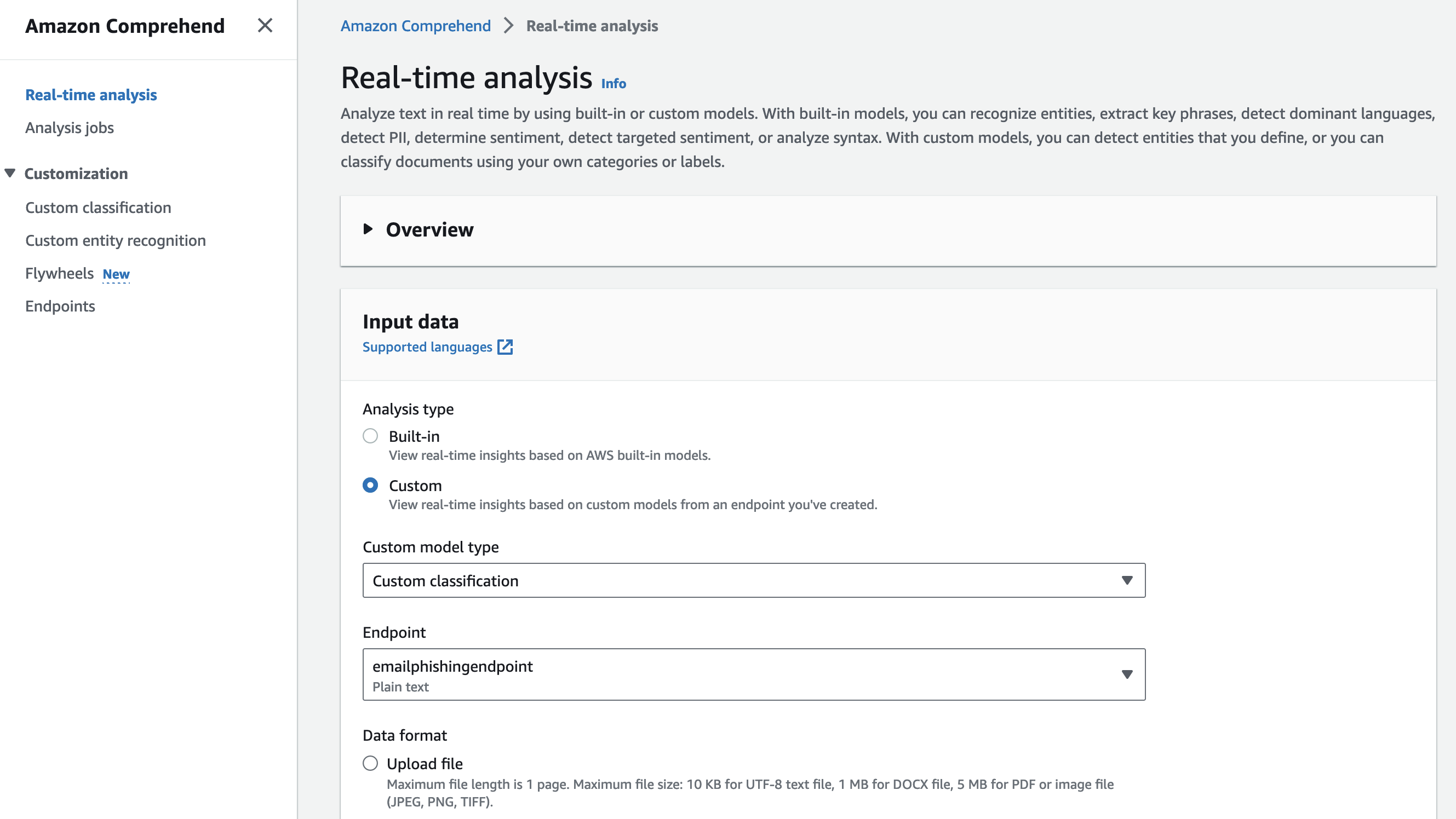
Test the Model
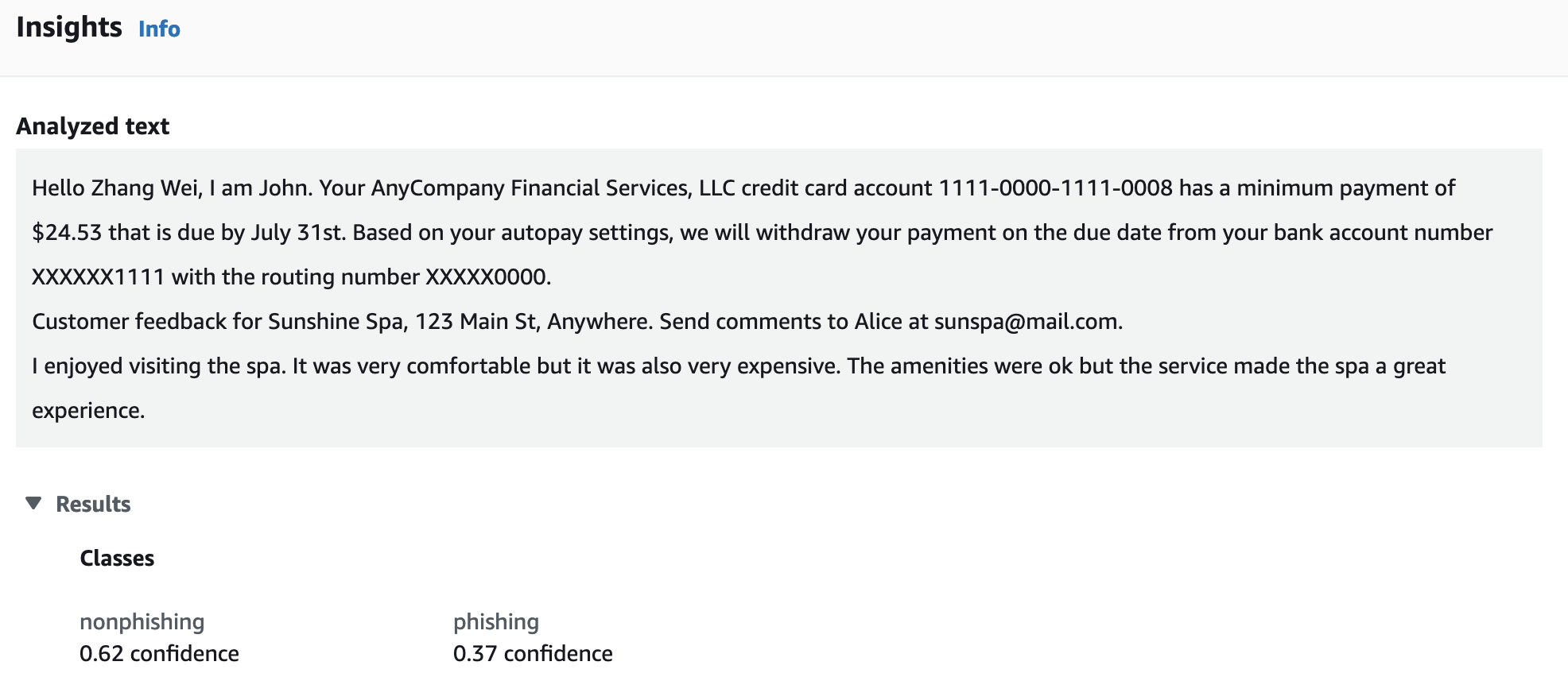
After the endpoint is ready, you can run the real-time analysis from the amazon Comprehend console.
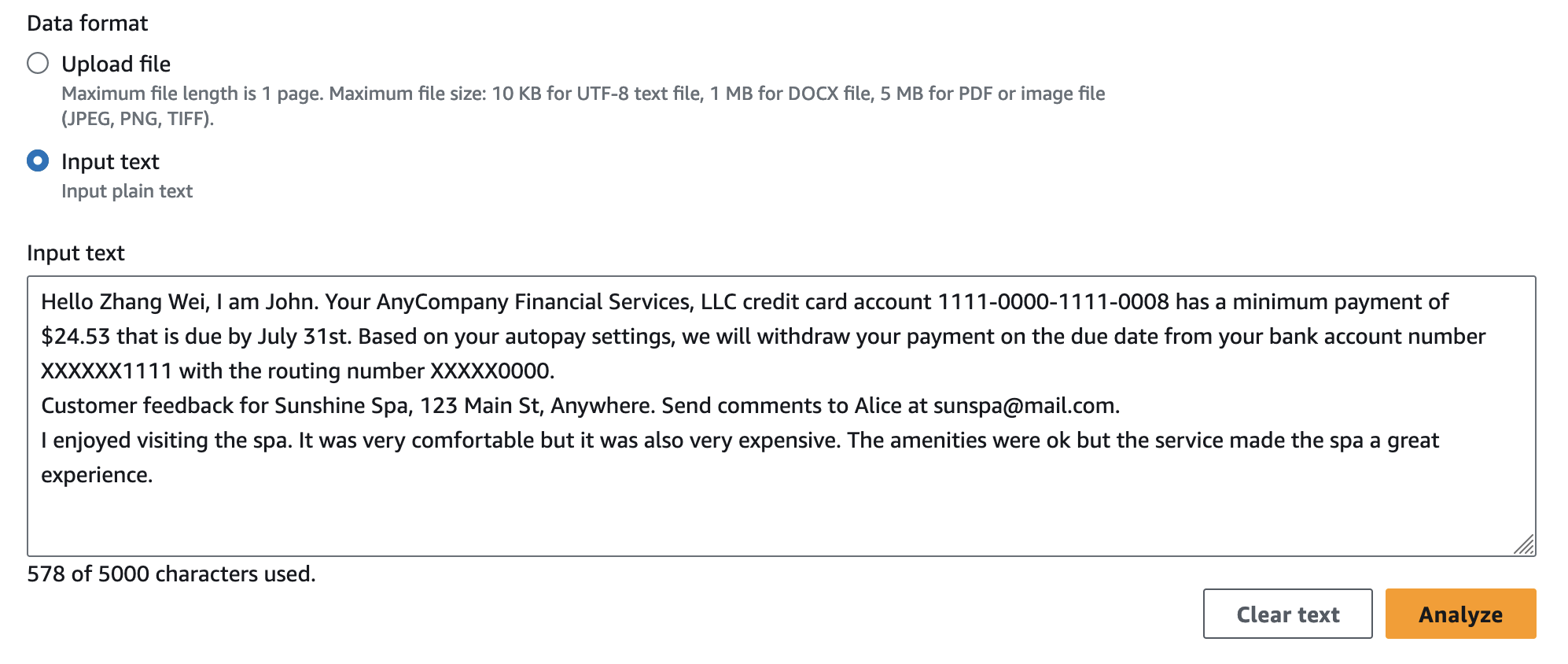
The sample input represents the email text, which is used for real-time analysis to detect if the email text is a phishing attempt or not.
amazon Comprehend analyzes the input data using the custom model. amazon Comprehend displays the discovered classes, along with a confidence assessment for each class. The insights section shows the inference results with confidence levels of the nonphishing and phishing classes. You can decide the threshold to decide the class of the inference. In this case, nonphishing is the inference results because this has more confidence than the phishing class. The model detects the input email text is a non-phishing email.
To integrate this capability of phishing detection in your real-world applications, you can use the amazon API Gateway REST API with an AWS Lambda integration. Refer to the serverless pattern in amazon-api-gateway-to-aws-lambda-to-amazon-comprehend” target=”_blank” rel=”noopener”>amazon API Gateway to AWS Lambda to amazon Comprehend to know more.
Clean up
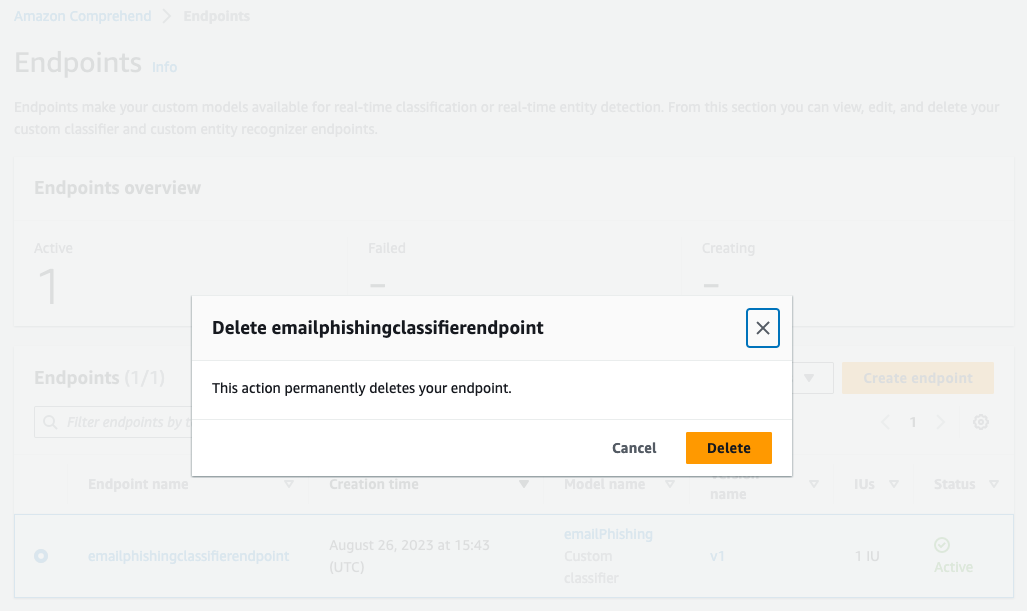
When you no longer need your endpoint, you should delete it so that you stop incurring costs from it. Also, delete the data file from S3 bucket. For more information on costs, see amazon Comprehend Pricing.
Conclusion
In this post, we walked you through the steps to create a phishing attempt detector using amazon Comprehend custom classification. You can customize amazon Comprehend for your specific requirements without the skillset required to build ML-based NLP solutions.
You can also visit the amazon Comprehend Developer Guide, amazon-comprehend-examples” target=”_blank” rel=”noopener”>GitHub repository
About the author
![]() Ajeet Tewari is a Solutions Architect for amazon Web Services. He works with enterprise customers to help them navigate their journey to AWS. His specialties include architecting and implementing highly scalable OLTP systems and leading strategic AWS initiatives.
Ajeet Tewari is a Solutions Architect for amazon Web Services. He works with enterprise customers to help them navigate their journey to AWS. His specialties include architecting and implementing highly scalable OLTP systems and leading strategic AWS initiatives.





{kind=link}