
Detección es una tarea de visión fundamental que tiene como objetivo localizar y reconocer objetos en una imagen. Sin embargo, el proceso de recopilación de datos de anotar manualmente cuadros delimitadores o máscaras de instancias es tedioso y costoso, lo que limita el tamaño del vocabulario de detección moderno a aproximadamente 1000 clases de objetos. Esto es mucho más pequeño que el vocabulario que la gente usa para describir el mundo visual y deja fuera muchas categorías. Modelos recientes de visión y lenguaje (VLM), como ACORTAR, han demostrado capacidades mejoradas de reconocimiento visual de vocabulario abierto a través del aprendizaje de pares de imagen y texto a escala de Internet. Estos VLM se aplican a la clasificación de tiro cero utilizando pesos de modelo congelados sin necesidad de ajuste fino, lo que contrasta con los paradigmas existentes que se utilizan para volver a entrenar o ajustar los VLM para tareas de detección de vocabulario abierto.
Intuitivamente, para alinear el contenido de la imagen con la descripción del texto durante el entrenamiento, los VLM pueden aprender características discriminativas y sensibles a la región que son transferibles a la detección de objetos. Sorprendentemente, las características de un VLM congelado contienen información valiosa que es sensible a la región para describir formas de objetos (segunda columna a continuación) y discriminatoria para la clasificación de regiones (tercera columna a continuación). De hecho, la agrupación de funciones puede delinear muy bien los límites de los objetos sin ninguna supervisión. Esto nos motiva a explorar el uso de VLM congelados para la detección de objetos de vocabulario abierto con el objetivo de expandir la detección más allá del conjunto limitado de categorías anotadas.
 |
| Exploramos el potencial de la visión congelada y las características del lenguaje para la detección de vocabulario abierto. El K-medias la agrupación de características revela una rica información semántica y sensible a la región donde los límites de los objetos están bien delineados (columna 2). Las mismas características congeladas pueden clasificar bien las regiones de GroundTruth (GT) sin un ajuste fino (columna 3). |
En “F-VLM: Detección de objetos de vocabulario abierto en modelos de visión y lenguaje congelados”, presentado en ICLR 2023, presentamos un enfoque de detección de vocabulario abierto simple y escalable basado en VLM congelados. F-VLM reduce la complejidad de entrenamiento de un detector de vocabulario abierto por debajo de la de un detector estándar, obviando la necesidad de destilación del conocimientoformación previa adaptada a la detección, o aprendizaje poco supervisado. Demostramos que al preservar completamente el conocimiento de los VLM pre-entrenados, F-VLM mantiene una filosofía similar a Húmedo y desacopla el aprendizaje específico del detector del conocimiento de visión más independiente de la tarea en la columna vertebral del detector. También estamos lanzando el F-VLM código junto con una demostración en nuestro página del proyecto.
Aprendizaje sobre modelos de visión y lenguaje congelados
Deseamos retener el conocimiento de los VLM preentrenados tanto como sea posible con el fin de minimizar el esfuerzo y el costo necesarios para adaptarlos para la detección de vocabulario abierto. Usamos un codificador de imagen VLM congelado como la columna vertebral del detector y un codificador de texto para almacenar en caché las incrustaciones de texto de detección del vocabulario del conjunto de datos fuera de línea. Tomamos esta columna vertebral de VLM y adjuntamos un cabeza detectora, que predice regiones de objetos para la localización y genera puntuaciones de detección que indican la probabilidad de que un cuadro detectado pertenezca a una determinada categoría. Las puntuaciones de detección son las similitud de coseno de características de la región (un conjunto de cuadros delimitadores que genera el cabezal del detector) e incrustaciones de texto de categoría. Las incrustaciones de texto de categoría se obtienen alimentando los nombres de categoría a través del modelo de texto de VLM preentrenado (que tiene modelos de imagen y de texto)r.
El codificador de imágenes VLM consta de dos partes: 1) un extractor de características y 2) una característica capa de agrupación. Adoptamos el extractor de características para el entrenamiento del cabezal del detector, que es el único paso que entrenamos (en detección estándar datos), para permitirnos usar pesos congelados directamente, heredando un rico conocimiento semántico (por ejemplo, categorías de cola larga como martini, sombrero fedora, banderín) de la columna vertebral de VLM. Las pérdidas de detección incluyen regresión de caja y pérdidas de clasificación.
 |
| En el momento del entrenamiento, F-VLM es simplemente un detector con la última capa de clasificación reemplazada por incrustaciones de texto de categoría base. |
Reconocimiento de vocabulario abierto a nivel regional
La capacidad de realizar reconocimiento de vocabulario abierto a nivel de región (es decir, nivel de cuadro delimitador en lugar de nivel de imagen) es parte integral de F-VLM. Dado que las características de la columna vertebral están congeladas, no se adaptan demasiado a las categorías de entrenamiento (p. ej., rosquilla, cebra) y se pueden recortar directamente para la clasificación a nivel de región. F-VLM realiza esta clasificación de vocabulario abierto solo en el momento de la prueba. Para obtener las características de VLM para una región, aplicamos la capa de agrupación de características en las características de salida de la red troncal recortada. Debido a que la capa de agrupación requiere entradas de tamaño fijo, por ejemplo, 7×7 para ResNet50 (R50) ACORTAR backbone, recortamos y redimensionamos las características de la región con el Capa ROI-Align (mostrado a continuación). A diferencia de la detección de vocabulario abierto existente enfoques, no recortamos ni cambiamos el tamaño de las regiones de la imagen RGB y almacenamos en caché sus incrustaciones en un proceso fuera de línea separado, sino que entrenamos el cabezal del detector en una etapa. Esto es más simple y hace un uso más eficiente del espacio de almacenamiento en disco. Además, no recortamos las características de la región VLM durante el entrenamiento porque las características de la columna vertebral están congeladas.
A pesar de que nunca se entrenó en regiones, las características de la región recortada mantienen una buena capacidad de reconocimiento de vocabulario abierto. Sin embargo, observamos que las características de la región recortada no son lo suficientemente sensibles a la calidad de localización de las regiones, es decir, un cuadro poco localizado frente a uno muy localizado tienen características similares. Esto puede ser bueno para la clasificación, pero es problemático para la detección porque necesitamos que las puntuaciones de detección reflejen también la calidad de la localización. Para remediar esto, aplicamos el significado geometrico para combinar las puntuaciones de VLM con las puntuaciones de detección para cada región y categoría. Las puntuaciones de VLM indican la probabilidad de que un cuadro de detección sea de una determinada categoría según el VLM preentrenado. Los puntajes de detección indican la distribución de probabilidad de clase de cada cuadro en función de la similitud de las características de la región y las incrustaciones de texto de entrada.
 |
| En el momento de la prueba, F-VLM usa las propuestas de región para recortar las funciones de nivel superior de la red troncal de VLM y calcular la puntuación de VLM por región. El cabezal detector capacitado proporciona las cajas y máscaras de detección, mientras que las puntuaciones finales de detección son una combinación de puntuaciones de detección y VLM. |
Evaluación
Aplicamos F-VLM al popular climatización punto de referencia de detección de vocabulario abierto. A nivel de sistema, el mejor F-VLM alcanza 32,8 precisión media (AP) sobre categorías raras (Abr), que supera al estado del arte en 6,5 máscara de abril y muchos otros enfoques basados en la destilación de conocimientos, la formación previa o la formación conjunta con una supervisión débil. F-VLM muestra una fuerte propiedad de escalado con capacidad de modelo congelado, mientras que la cantidad de parámetros entrenables es fija. Además, F-VLM generaliza y escala bien en las tareas de detección de transferencias (por ejemplo, Objetos365 y Ego4D conjuntos de datos) simplemente reemplazando los vocabularios sin ajustar el modelo. Probamos los modelos entrenados por LVIS en el popular Objetos365 conjuntos de datos y demostrar que el modelo puede funcionar muy bien sin entrenamiento en datos de detección en el dominio.
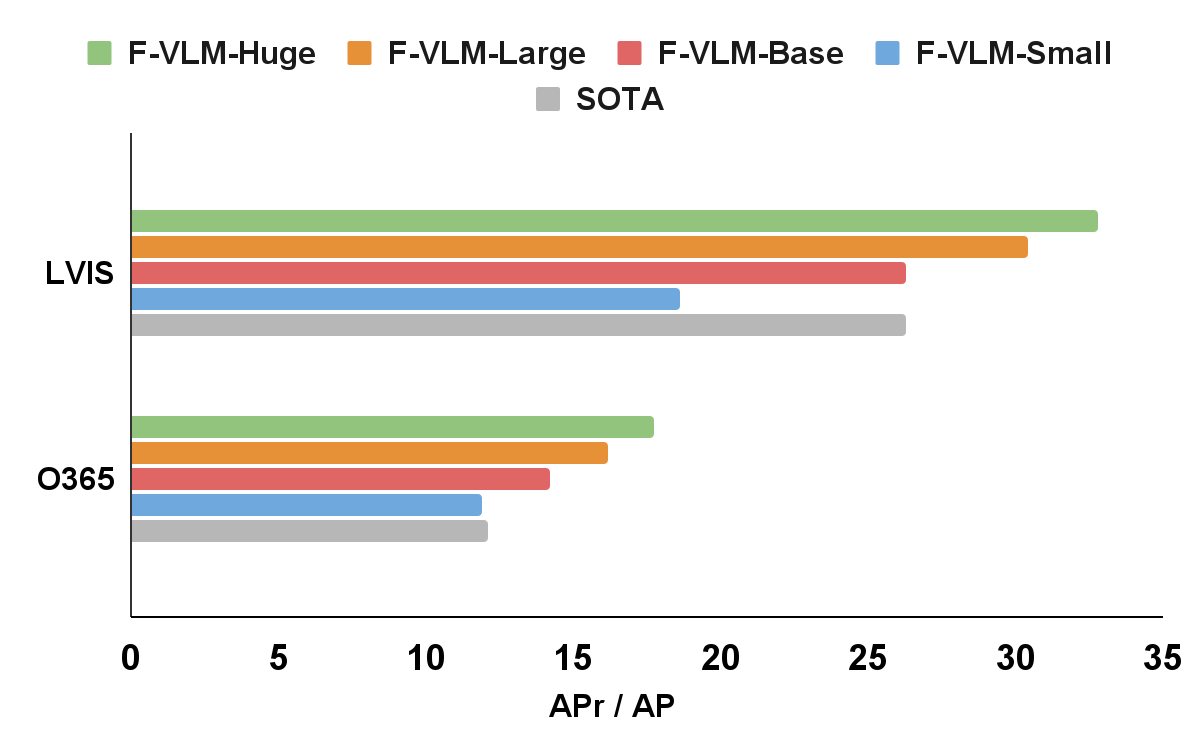 |
| F-VLM supera el estado del arte (SOTA) en el punto de referencia de detección de vocabulario abierto LVIS y detección de objetos de transferencia. En el eje x, mostramos la máscara métrica LVIS AP en categorías raras (APr) y el cuadro métrico Objects365 (O365) AP en todas las categorías. Los tamaños de las redes troncales del detector son los siguientes: Pequeño (R50), Base (R50x4), Grande (R50x16), Enorme (R50x64). La denominación sigue la convención CLIP. |
Visualizamos F-VLM en tareas de detección de transferencia y detección de vocabulario abierto (que se muestra a continuación). En LVIS y Objects365, F-VLM detecta correctamente objetos nuevos y comunes. Un beneficio clave de la detección de vocabulario abierto es probar sobre la marcha datos fuera de distribución con categorías proporcionadas por los usuarios. Consulte el documento F-VLM para obtener más visualización sobre climatización, Objetos365 y Ego4D conjuntos de datos
 |
| Detecciones de transferencia y vocabulario abierto F-VLM. Arriba: Detección de vocabulario abierto en LVIS. Solo mostramos las categorías novedosas para mayor claridad. Abajo: Transferir a Objetos365 El conjunto de datos muestra una detección precisa de muchas categorías. Categorías novedosas detectadas: sombrero de fieltro, martini, banderín, casco de fútbol americano (LVIS); diapositiva (Objects365). |
Eficiencia del entrenamiento
Mostramos que F-VLM puede lograr el máximo rendimiento con muchos menos recursos computacionales en la siguiente tabla. En comparación con el estado del arte acercarse, F-VLM puede lograr un mejor rendimiento con 226 veces menos recursos y un tiempo de reloj de pared 57 veces más rápido. Aparte de los ahorros en recursos de entrenamiento, F-VLM tiene potencial para ahorros sustanciales de memoria en el tiempo de entrenamiento al ejecutar la red troncal en modo de inferencia. El sistema F-VLM funciona casi tan rápido como un detector estándar en el momento de la inferencia, porque la única adición es una única capa de agrupación de atención en las características de la región detectada.
| Método | Abr | Épocas de entrenamiento | Costo de entrenamiento (por núcleo-hora) |
Ahorro de costes de formación | ||||||||||
| SOTA | 26.3 | 460 | 8,000 | 1x | ||||||||||
| F-VLM | 32.8 | 118 | 565 | 14x | ||||||||||
| F-VLM | 31.0 | 14.7 | 71 | 113x | ||||||||||
| F-VLM | 27.7 | 7.4 | 35 | 226x |
Proporcionamos resultados adicionales usando el más corto detector2 recetas de entrenamiento (12 y 36 épocas) y muestran un rendimiento igualmente fuerte al usar una columna vertebral congelada. La configuración predeterminada está marcada en gris.
| Columna vertebral | Jitter a gran escala | #épocas | Tamaño del lote | Abr | ||||||||||
| R50 | 12 | dieciséis | 18.1 | |||||||||||
| R50 | 36 | 64 | 18.5 | |||||||||||
| R50 | ✓ | 100 | 256 | 18.6 | ||||||||||
| R50x64 | 12 | dieciséis | 31,9 | |||||||||||
| R50x64 | 36 | 64 | 32.6 | |||||||||||
| R50x64 | ✓ | 100 | 256 | 32.8 |
Conclusión
Presentamos F-VLM, un método simple de detección de vocabulario abierto que aprovecha el poder de los grandes modelos de lenguaje de visión preentrenados congelados para detectar objetos novedosos. Esto se hace sin necesidad de destilación de conocimientos, capacitación previa adaptada a la detección o aprendizaje poco supervisado. Nuestro enfoque ofrece importantes ahorros informáticos y elimina la necesidad de etiquetas a nivel de imagen. F-VLM logra el nuevo estado del arte en detección de vocabulario abierto en el punto de referencia LVIS a nivel de sistema y muestra una detección de transferencia muy competitiva en otros conjuntos de datos. Esperamos que este estudio pueda facilitar una mayor investigación en la detección de objetos nuevos y ayudar a la comunidad a explorar VLM congelados para una gama más amplia de tareas de visión.
Agradecimientos
Este trabajo es realizado por Weicheng Kuo, Yin Cui, Xiuye Gu, AJ Piergiovanni y Anelia Angelova. Nos gustaría agradecer a nuestros colegas de Google Research por sus consejos y debates útiles.






{kind=link}