
Introducción
Durante uno de los partidos de cricket en el Campeonato ICC World Cup T20, Rohit Sharma, capitán del equipo de cricket indio, aplaudió a Jasprit Bumrah como Genius Bowler. Decidí realizar un experimento y probarlo utilizando datos disponibles públicamente. Aunque es un proyecto divertido, los resultados me sorprendieron gratamente. Empecemos.
Definición del problema
Para realizar análisis de datos o construir modelos, necesitamos convertir un problema comercial en un problema de datos. ¿Cómo hacemos que nuestro modelo comprenda el significado de Genio? Bueno, Genius se puede definir como “Muy por encima o muy por encima del resto”. ¿Podemos formular esto como un problema de detección de anomalías? Sí.
Hay muchas formas de resolver el problema de detección de anomalías. Nos limitaríamos a AutoEncoders usando PyTorch.
Utilizaríamos las estadísticas de jugadores T20 disponibles públicamente del paquete R de datos de cricket para entrenar nuestro modelo AutoEncoders. Si AutoEncoders tiene dificultades para reconstruir los valores, el error cuadrático medio (MSE) sería alto. MSE por encima de un umbral sería una anomalía.
En nuestro caso, el MSE de Jasprit Bumrah debería ser lo suficientemente alto como para marcarlo como anomalía o Genio.
Objetivos de aprendizaje
- Comprender la arquitectura básica de AutoEncoders, incluidas las funciones de las redes de codificador y decodificador.
- Comprenda cómo utilizar el error de reconstrucción (error cuadrático medio) de AutoEncoders para identificar anomalías.
- Aprenda a preprocesar datos, crear conjuntos de datos y configurar cargadores de datos para entrenar y probar modelos.
- Comprenda el proceso de entrenamiento de AutoEncoders, incluida la configuración de hiperparámetros, funciones de pérdida y optimizadores.
- Explore aplicaciones del mundo real de detección de anomalías, como gestión de clientes y detección de fraude.
Este artículo fue publicado como parte de la Blogatón de ciencia de datos.
¿Qué son los codificadores automáticos?
Los AutoEncoders se componen de dos redes, codificador y decodificador. El codificador recibe el vector V de D dimensión y lo codifica en un vector x de dimensión M en el que M <D. Por lo tanto, el codificador comprime nuestra entrada. Decoder descomprime x e intenta recrear V tanto como sea posible. Llamemos a la salida del decodificador como Z.
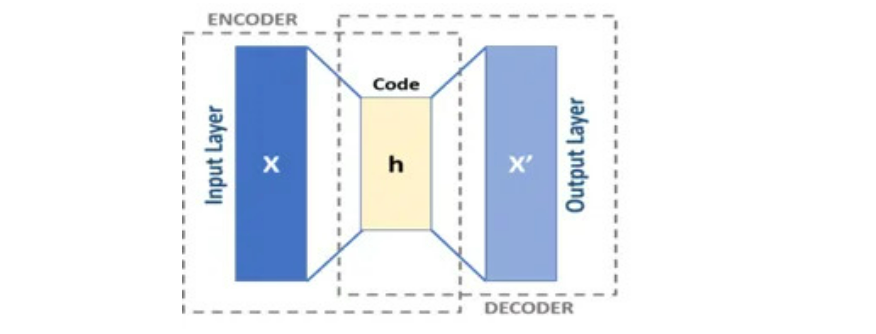
Normalmente, Decoder podría recrear V para la mayoría de las filas, es decir, para la mayoría de las filas, Z estaría más cerca de V. Pero para ciertas filas, Decoder tendría dificultades para decodificar y la diferencia entre Z y V sería enorme. A estos valores los llamaríamos Anomalía. Los valores de anomalía suelen tener un error cuadrático medio o MSE alto.
Aplicaciones del mundo real de AutoEncoder
Exploremos ahora las aplicaciones del mundo real de AutoEncoder.
Gestión de clientes
Supongamos que una organización trata con muchos clientes y tiene una metodología para etiquetar a los clientes como buenos o malos, limpios o riesgosos, ricos o no ricos. Auto Encoder, cuando se entrena solo con clientes buenos, limpios o ricos, puede descifrar el patrón de estos clientes principales o ideales. Cuando llega un nuevo cliente, tenemos una forma confiable de saber en qué se diferencia el nuevo cliente del cliente ideal. Se puede argumentar que se puede hacer manualmente. Los humanos están limitados por la cantidad de variables y datos que pueden manejar. Las máquinas no tienen esta limitación.
Gestión de fraude
Similar a lo anterior, si una organización tiene una metodología para etiquetar las transacciones como fraudulentas o no fraudulentas. Podemos entrenar nuestro Autoencoder solo en transacciones no fraudulentas y en entornos de producción, tenemos un mecanismo confiable para saber en qué se diferencia la nueva transacción de la transacción ideal.
La anterior no es una lista exhaustiva de aplicaciones de AutoEncoder.
Volvamos ahora a nuestro problema original.
Recopilación de datos, limpieza e ingeniería de funciones.
Recopilé datos estadísticos de carrera T20 de jugadores de bolos. aquí.
Utilicé cricketdata de la biblioteca R para descargar las estadísticas de carrera del jugador T20, ya que, hasta donde yo sé, la versión Python del mismo no está disponible. Las estadísticas de T20 no incluyen ligas como IPL.
library(cricketdata)
# T20 Career Data
t20_career <- fetch_cricinfo("T20", "men", "Bowling",'career')
# T20 Innings Data
t20_innings <- fetch_cricinfo("T20", "men", "Bowling",'innings')Necesitamos unir ambos conjuntos de datos y crear un conjunto de datos de entrada final que se utilizará para entrenar AutoEncoders en Python. Antes de guardar el archivo en el disco, debemos considerar solo los países de prueba para nuestro análisis.
final<-final(Country %in% c('Australia','West Indies','South Africa'
,'Pakistan','Afghanistan','India'
,'Sri Lanka','England','New Zealand'
,'BAN'))
fwrite(final,'T20_Stats_Career.txt',sep="|")Podemos nombrar el conjunto de datos final como “T20_Stats_Career.txt”.
Ahora usaremos Python para el resto del análisis.
import numpy as np
import torch
import torch.optim as optim
import numpy as np
import torch
import torch.optim as optim
import torch.nn as nn
from torch.utils.data import TensorDataset,DataLoader
from sklearn.preprocessing import StandardScaler
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import randomHemos importado todas las bibliotecas necesarias. Ahora leeríamos los datos del jugador.
df = pd.read_csv('T20_Stats_Career.txt',sep='|')
df.head()Las primeras 5 filas del conjunto de datos se muestran a continuación:

Para cada jugador, tenemos datos de número de entradas, overs, doncellas, carreras, terrenos, promedio, economía y tasa de strike.
Ingeniería de características
He añadido dos nuevas características:
- Porcentaje de Doncellas: No de Doncellas / No de Overs
- Wickets por over: No de Wickets / No de Overs
df('Maiden_PCT') = df('Maidens') / df('Overs') * 100
df('Wickets_Per_over') = df('Wickets') / df('Overs')También debemos eliminar a los jugadores con un número de entradas inferior a 15 para utilizar solo aquellos jugadores con suficiente experiencia en partidos para nuestro análisis.
Conjunto de datos de entrenamiento y prueba
Conjunto de datos de trenes: los conjuntos de datos de trenes tendrían estadísticas T20 de jugadores de nacionalidades distintas a la India.
Conjunto de datos de prueba: solo jugadores indios.
# Create Train and Test Dataset
test = df(df('Country') == 'India')
train = df(df('Country') != 'India')Usamos las siguientes características para entrenar nuestro modelo:
- Promedio
- Economía
- Porcentaje de acertamiento
- No de cuatro ventanillas
- No de cinco ventanillas
- Porcentaje de soltera
- Wickets por encima
Elimine funciones innecesarias
features = ('Average','Economy','StrikeRate','FourWickets','FiveWickets'
,'Maiden_PCT','Wickets_Per_over')
X_train = train(features)
X_test = test(features)
print("Number of Players in Train Dataset",X_train.shape)
print("Number of Players in Test Dataset",X_test.shape)
X_train.head()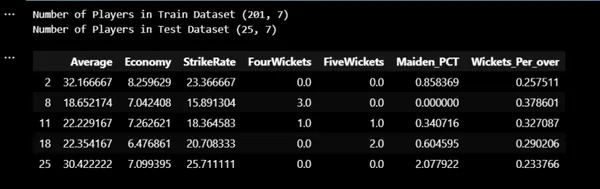
Estandarización de datos
Tenemos un conjunto de datos de entrenamiento y prueba. Ahora necesitamos estandarizar los datos.
sc = StandardScaler()
sc.fit(X_train)
X_train = sc.transform(X_train)
X_test = sc.transform(X_test)Entrenamiento modelo
Ahora configuramos el dispositivo apropiado y configuramos cargadores de datos con un tamaño de lote de 16.
# Create Tensor Dataset and Dataloders
device="cuda" if torch.cuda.is_available() else 'cpu'
torch.manual_seed(13)
x_train_tensor = torch.as_tensor(X_train).float().to(device)
y_train_tensor = torch.as_tensor(X_train).float().to(device)
x_test_tensor = torch.as_tensor(X_test).float().to(device)
y_test_tensor = torch.as_tensor(X_test).float().to(device)
train_dataset = TensorDataset(x_train_tensor,y_train_tensor)
test_dataset = TensorDataset(x_test_tensor,y_test_tensor)
train_loader = DataLoader(dataset=train_dataset,batch_size=16,shuffle=True)
test_loader = DataLoader(dataset=test_dataset,batch_size=16)Configuramos la arquitectura de AutoEncoders de la siguiente manera:
7 ->4->2->4->7.
Como estamos tratando con muy pocos datos, construiríamos un modelo simple.
Usamos Learning Rate como 0.001 y Adam como Optimizer.
# AutoEncoder Architecture
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder,self).__init__()
self.encoder = nn.Sequential()
self.encoder.add_module('Hidden1',nn.Linear(7,4))
self.encoder.add_module('Relu1',nn.ReLU())
self.encoder.add_module('Hidden2',nn.Linear(4,2))
self.decoder = nn.Sequential()
self.decoder.add_module('Hidden3',nn.Linear(2,4))
self.decoder.add_module('Relu2',nn.ReLU())
self.decoder.add_module('Hidden4',nn.Linear(4,7))
def forward(self,x):
encoder = self.encoder(x)
return self.decoder(encoder)
# Predict Method
def predict(model,x):
model.eval()
x_tensor = torch.as_tensor(x).float()
y_hat = model(x_tensor.to(device))
model.train()
return y_hat.detach().cpu().numpy()
# Plot Losses
def plot_losses(train_losses,test_losses):
fig = plt.figure(figsize=(10,4))
plt.plot(train_losses,label="training_loss",c="b")
#plt.plot(self.val_losses,label="val loss",c="r")
if test_loader:
plt.plot(test_losses,label="test loss",c="r")
#plt.yscale('log')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
return fig
# Model Loss and Optimizer
lr = 0.001
torch.manual_seed(21)
model = AutoEncoder().to(device)
optimizer = optim.Adam(model.parameters(),lr = lr)
loss_fn =nn.MSELoss()Entrenamos nuestro modelo durante 250 épocas.
num_epochs=250
train_loss=()
test_loss=()
seed=42
torch.backends.cudnn.deterministic=True
torch.backends.cudnn.benchmark=False
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
for epoch in range(num_epochs):
mini_batch_train_loss=()
mini_batch_test_loss=()
for train_batch,y_train in train_loader:
train_batch =train_batch.to(device)
model.train()
yhat = model(train_batch)
loss = loss_fn(yhat,y_train)
mini_batch_train_loss.append(loss.cpu().detach().numpy())
loss.backward()
optimizer.step()
optimizer.zero_grad()
train_epoch_loss = np.mean(mini_batch_train_loss)
train_loss.append(train_epoch_loss)
with torch.no_grad():
for test_batch,y_test in test_loader:
test_batch = test_batch.to(device)
model.eval()
yhat = model(test_batch)
loss = loss_fn(yhat,y_test)
mini_batch_test_loss.append(loss.cpu().detach().numpy())
test_epoch_loss = np.mean(mini_batch_test_loss)
test_loss.append(test_epoch_loss)
fig = plot_losses(train_loss,test_loss)
fig.savefig('Train_Test_Loss.png')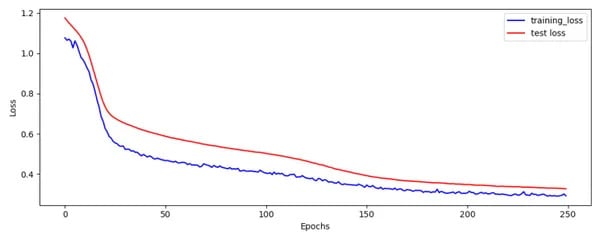
El gráfico de pérdida de tren y prueba se ve bien.
Error cuadrático medio (MSE)
Usando la función de predicción podemos predecir el conjunto de datos del tren. Luego calculamos el error cuadrático medio elevando al cuadrado la diferencia entre los valores reales y los previstos. También calcularemos Z-Score utilizando la media y la desviación estándar de MSE.
# Predict Train Dataset and get error
train_pred = predict(model,X_train)
print(train_pred.shape)
error = np.mean(np.power(X_train - train_pred,2),axis=1)
print(error.shape)
train('error') = error
mean_error = np.mean(train('error'))
std_error =np.std(train('error'))
train('zscore') = (train('error') - mean_error) / std_error
train = train.sort_values(by='error').reset_index()
train.to_csv('Train_Output.txt',sep="|",index=None)
fig = plt.figure(figsize=(10,4))
plt.title('Distribution of MSE in Train Dataset')
train('error').plot(kind='line')
plt.ylabel('MSE')
plt.show()
fig.savefig('Train_MSE.png')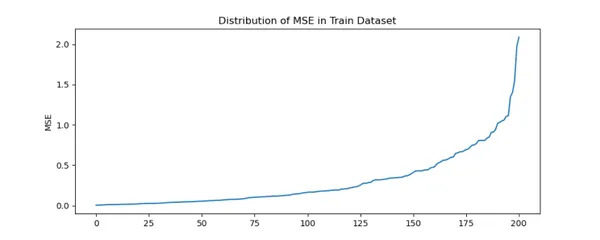
Podemos inferir que hay un fuerte aumento en el MSE para ciertos jugadores.
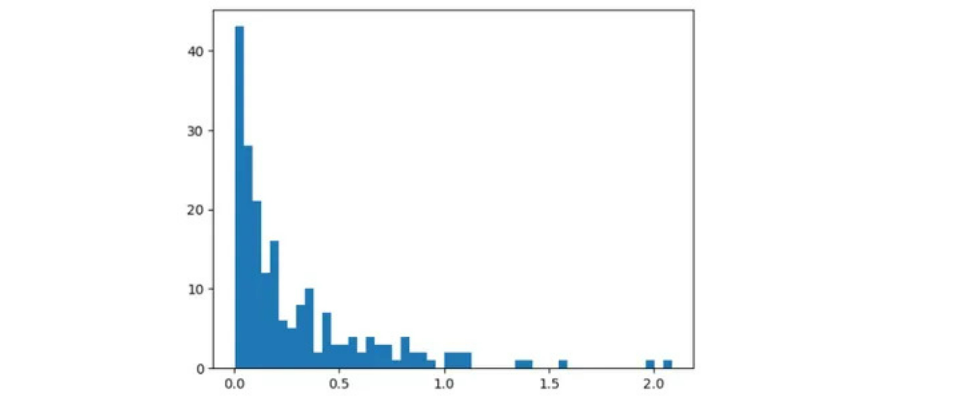
La mayoría de los jugadores están dentro de MSE de 1. Más allá de 1,2 MSE hay sólo unos pocos jugadores.
Los 3 mejores jugadores en el conjunto de datos de trenes con mayor MSE son:
train.tail(3)Tenga en cuenta que estamos utilizando la función Tail
Podemos inferir que, para algunos reproductores, el codificador automático tiene dificultades para reconstruir los valores originales, lo que genera un MSE alto.
Al observar los gráficos anteriores, podemos establecer el umbral en 1,2.
Estoy de acuerdo en que necesitamos dividir los datos en tren y validación y usar datos del conjunto de datos de validación para establecer el umbral. Pero en este caso sólo tenemos 200 filas. Nos vemos obligados a adoptar este enfoque.
Conjunto de datos de prueba: jugadores o jugadores de bolos indios
Calculemos ahora el error cuadrático medio y el puntaje Z para los datos de prueba.
# Predict Test Dataset and get error
test_pred = predict(model,X_test)
test_error = np.mean(np.power(X_test - test_pred,2),axis=1)
test('error') = test_error
test('zscore') = (test('error') - mean_error) / std_error
test = test.sort_values(by='error').reset_index()
test.to_csv('Test_Output.txt',sep="|",index=None)
fig = plt.figure(figsize=(10,4))
plt.title('Distribution of MSE in Test Dataset')
test('error').plot(kind='line')
plt.ylabel('MSE')
plt.show()
fig.savefig('Test_MSE.png')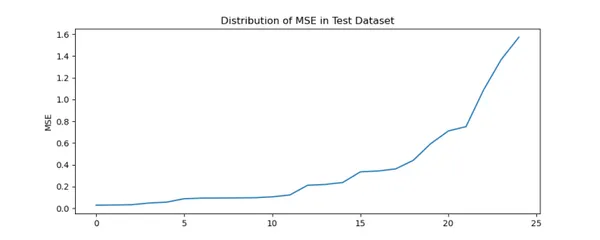
Al igual que en Train Dataset, hay un fuerte aumento en MSE para ciertos jugadores indios.
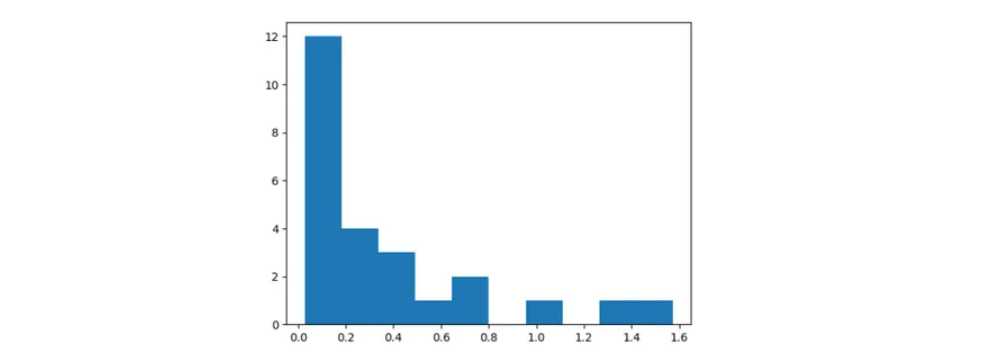
test.tail(3)Tenga en cuenta que estamos utilizando la función Tail. Por lo tanto, el orden correcto es Kuldeep Yadav, JJ Bumrah y Harbhajan Singh.
Al igual que en el conjunto de datos del tren, creamos una nueva columna llamada Error en el conjunto de datos de prueba que tiene valores MSE. Al igual que Train Dataset, Autoencoder tiene dificultades para reconstruir los valores originales de algunos jugadores indios.
Usando Train MSE hemos calculado la media y la desviación estándar. Para cada valor en el conjunto de datos de prueba, calculamos Z-Score como (error de prueba – error medio del tren) / desviación estándar del error del tren.
Podemos verificar que Z-Score para Bumrah es superior a 3, lo que significa anomalía o genio.
Desglose o profundización de MSE
Conozcamos ahora el desglose de MSE para los jugadores.
jasprit bumrah
Entendamos ahora por qué el MSE es alto para Jasprit Bumrah. El MSE de Jasprit Bumrah es 1,36. Profundicemos más en el MSE a nivel variable para comprender los factores que contribuyen.
MSE se calcula como (Real – Previsto) * (Real – Predicho).
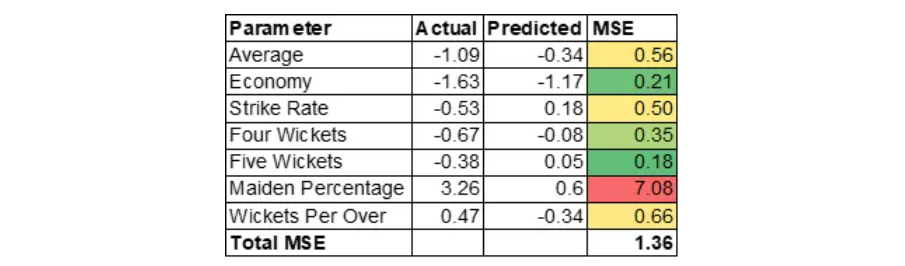
Tenga en cuenta que estamos tratando con valores estandarizados. La razón del alto MSE se debe principalmente al alto porcentaje de doncellas. Esto significa que Bumrah sería un excelente jugador de bolos en el puesto 19 o 20 de las entradas. Un alto porcentaje de doncellas crearía presión sobre el bateador, lo que puede provocar que otros jugadores tomen ventanillas en el siguiente over. Tenga en cuenta que la variable Porcentaje de doncella fue creada por Feature Engineering.
Kuldeep Yadav
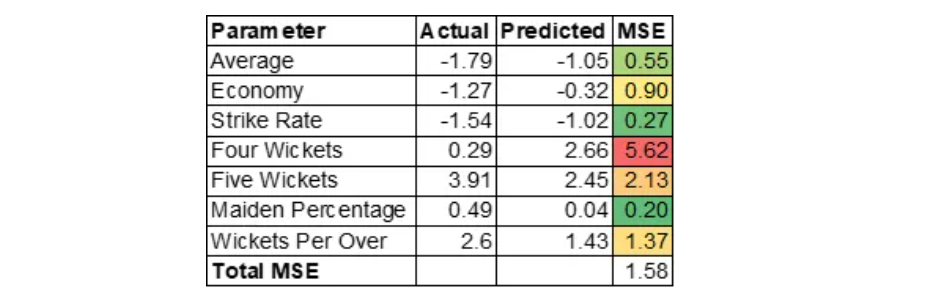
Kuldeep Yadav tiene una asombrosa habilidad para recoger ventanillas que serán útiles en los intermedios. Codificador automático sobre la variable de cuatro ventanillas predicha.
Estadísticas generales de los 2 mejores jugadores de bolos indios
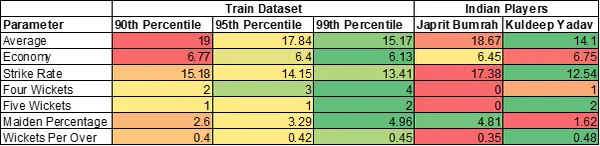
Jasprit Bumrah tiene 2 variables en más del percentil 90. Kuldeep Yadav tiene 4 variables en más del percentil 99.
Espero ver a Kuldeep Yadav en acción pronto.
Puedes encontrar el código completo aquí.
Conclusión
AutoEncoder es una poderosa herramienta en el arsenal para la detección de anomalías, pero no es el único método. También podemos considerar el uso de algoritmos de ML como Isolation Forest u otros métodos más simples. Volviendo a nuestro problema, podemos inferir que AutoEncoder es capaz de identificar correctamente las anomalías. La parte más difícil de la detección de anomalías es convencer a las partes interesadas de las razones de la anomalía. Aquí calculamos un desglose de MSE para identificar las razones de la anomalía. Estos conocimientos son tan importantes como detectar la anomalía misma. La IA explicable es importante.
Conclusiones clave
- Usamos R Package cricketdata para descargar Estadísticas de jugadores T20 para países de prueba y guardar los datos en el disco.
- Realice ingeniería de funciones calculando el porcentaje de doncella y los terrenos por encima.
- Usando PyTorch entrenaríamos el modelo de Auto Encoder durante 250 épocas en Train Dataset. Usamos el optimizador como Adam y establecemos la tasa de aprendizaje en 0,001.
- Calcule el error cuadrático medio calculando la diferencia entre Real y Predicción tanto en el tren como en el conjunto de datos de prueba.
- Consideramos el error de reconstrucción más allá de un cierto umbral como una anomalía. En nuestro caso es 1,2.
- Al observar la ruptura de MSE, podemos inferir que Bumrah sobresale en los bolos Maidens, que es oro en T20.
Preguntas frecuentes
R. Sí, podemos usar métodos de aprendizaje automático como Isolation Forest u otros métodos más simples para resolver este problema. He usado AutoEncoder solo para ilustración.
R. Sí, el resultado es diferente cuando se entrena con diferentes semillas, ya que los datos son pequeños. El motivo principal de este blog es demostrar la aplicación de AutoEncoder y cómo se puede utilizar para generar conocimientos que ayuden en la toma de decisiones.
R. El tiempo de entrenamiento es inferior a un minuto.
R. El marco de aprendizaje profundo no debería importar. Todo depende del marco con el que uno se sienta cómodo.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.

Entusiasta de los datos. Me encanta cerrar la brecha entre los datos y la estrategia y trabajar en cualquier punto intermedio que incluya la ciencia de datos.





