 NEWSLETTER
NEWSLETTER
Imagen del autor
Los árboles de decisión dividen las decisiones difíciles en fases sencillas y fáciles de seguir, funcionando así como cerebros humanos.
En la ciencia de datos, estos potentes instrumentos se aplican ampliamente para ayudar en el análisis de datos y la dirección de la toma de decisiones.
En este artículo, repasaré cómo funcionan los árboles de decisión, daré ejemplos del mundo real y daré algunos consejos para mejorarlos.
Estructura de los árboles de decisión
En esencia, los árboles de decisión son herramientas sencillas y claras que descomponen las opciones difíciles en opciones más simples y secuenciales, reflejando así la toma de decisiones humana. Exploremos ahora los principales elementos que forman un árbol de decisión.
Nodos, ramas y hojas
Tres componentes básicos definen un árbol de decisiones: hojas, ramas y nodos. Cada uno de ellos es absolutamente esencial para el proceso de toma de decisiones.
- Nodos:Son puntos de decisión por los cuales el árbol decide en función de los datos de entrada. Al representar todos los datos, el nodo raíz es el punto de partida.
- Sucursales: Relacionan el resultado de una decisión y enlazan nodos. Cada rama coincide con un resultado o valor potencial de un nodo de decisión.
- Hojas: Los extremos del árbol de decisiones son hojas, a veces denominadas nodos de hoja. Cada nodo de hoja ofrece una determinada consecuencia o etiqueta; reflejan la última elección o clasificación.
Ejemplo conceptual
Supongamos que estás eligiendo si salir o no al exterior en función de la temperatura. “¿Está lloviendo?”, preguntaría el nodo raíz. Si es así, es posible que encuentres una rama que diga “Lleva un paraguas”. Este no debería ser el caso; otra rama podría decir “Usa gafas de sol”.
Estas estructuras hacen que los árboles de decisiones sean fáciles de interpretar y visualizar, por lo que son populares en diversos campos.
Ejemplo del mundo real: La aventura de la aprobación del préstamo
Imagínate esto: eres un mago del banco Gringotts y debes decidir quién obtiene un préstamo para su nueva escoba.
- Nodo raíz: “¿Su puntuación crediticia es mágica?”
- Si es así → Pasa a “¡Aprueba más rápido de lo que puedes decir Quidditch!”
- Si no, pasa a “Verificar sus reservas de oro goblin”.
- Si es alto →, “Apruébalo, pero vigílalos”.
- Si es bajo → “Denegar más rápido que un Nimbus 2000”.
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
data = {
'Credit_Score': (700, 650, 600, 580, 720),
'Income': (50000, 45000, 40000, 38000, 52000),
'Approved': ('Yes', 'No', 'No', 'No', 'Yes')
}
df = pd.DataFrame(data)
x = df(('Credit_Score', 'Income'))
y = df('Approved')
clf = DecisionTreeClassifier()
clf = clf.fit(x, y)
plt.figure(figsize=(10, 8))
tree.plot_tree(clf, feature_names=('Credit_Score', 'Income'), class_names=('No', 'Yes'), filled=True)
plt.show()Aquí está el resultado.
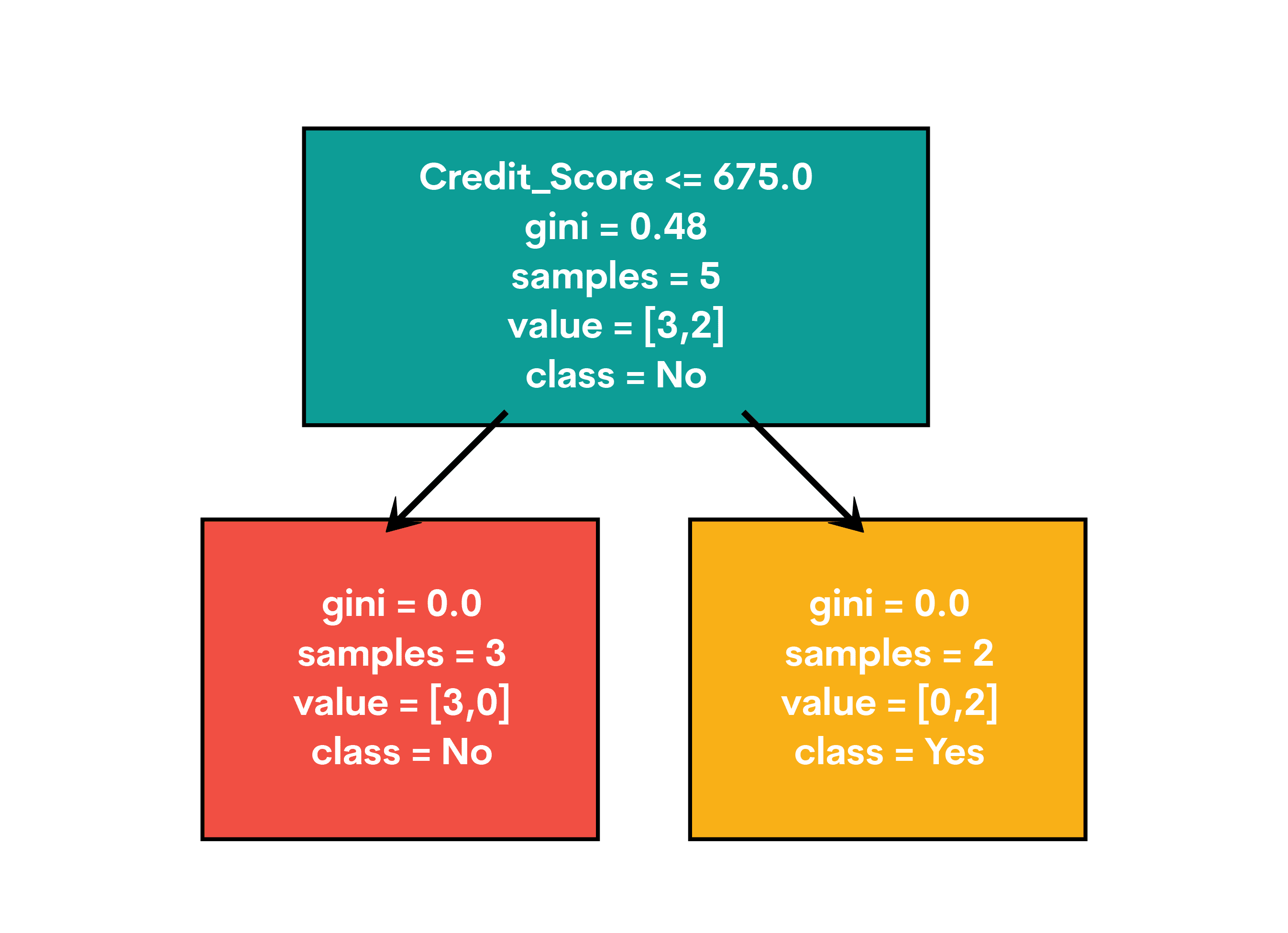 Cuando ejecutes este hechizo, verás que aparece un árbol. Es como el Mapa del Merodeador de las aprobaciones de préstamos:
Cuando ejecutes este hechizo, verás que aparece un árbol. Es como el Mapa del Merodeador de las aprobaciones de préstamos:
- El nodo raíz se divide en Credit_Score
- Si es ≤ 675, nos aventuramos hacia la izquierda.
- Si es > 675, vamos hacia la derecha
- Las hojas muestran nuestras decisiones finales: “Sí” para aprobado, “No” para denegado.
¡Listo! ¡Acabas de crear una bola de cristal para tomar decisiones!
Alucinante: Si tu vida fuera un árbol de decisiones, ¿cuál sería la pregunta del nodo raíz? “¿Tomé café esta mañana?” ¡Podría dar lugar a algunas ramas interesantes!
Árboles de decisión: detrás de las ramas
Los árboles de decisión funcionan de manera similar a un diagrama de flujo o una estructura de árbol, con una sucesión de puntos de decisión. Comienzan dividiendo un conjunto de datos en partes más pequeñas y luego construyen un árbol de decisión para acompañarlo. La forma en que estos árboles abordan la división de datos y las diferentes variables es algo que deberíamos analizar.
Criterios de división: impureza del coeficiente de Gini y ganancia de información
La elección de la mejor calidad para dividir los datos es el objetivo principal de la construcción de un árbol de decisiones. Es posible determinar este procedimiento utilizando los criterios proporcionados por la ganancia de información y la impureza de Gini.
- Impureza de Gini: Imagínese en medio de un juego de adivinanzas. ¿Con qué frecuencia se equivocaría si seleccionara una etiqueta al azar? Eso es lo que mide el coeficiente de impureza de Gini. Podemos hacer mejores conjeturas y tener un árbol más feliz con un coeficiente de Gini más bajo.
- Ganancia de información:El momento “¡Ajá!” en una historia de misterio es con lo que se puede comparar esto. En qué medida una pista (atributo) ayuda a resolver el caso se mide por este momento. Un “¡Ajá!” más grande significa más ganancia, lo que significa un árbol extático.
Para predecir si un cliente compraría un producto de su conjunto de datos, puede comenzar con información demográfica básica, como edad, ingresos e historial de compras. El enfoque tiene en cuenta todos estos factores y encuentra el que diferencia a los compradores de los demás.
Manejo de datos continuos y categóricos
No hay ningún tipo de información que nuestros detectives de árboles no puedan investigar.
En el caso de las características que son fáciles de cambiar, como la edad o los ingresos, el árbol establece una trampa de velocidad: “¡Cualquiera mayor de 30 años, por aquí!”.
Cuando se trata de datos categóricos, como el género o el tipo de producto, se trata más bien de una clasificación: “Los teléfonos inteligentes están a la izquierda; las computadoras portátiles, a la derecha”.
Caso real sin resolver: el predictor de compra del cliente
Para entender mejor cómo funcionan los árboles de decisión, veamos un ejemplo de la vida real: utilizar la edad y los ingresos de un cliente para adivinar si comprará un producto.
Para adivinar lo que la gente comprará, haremos una colección simple y un árbol de decisiones.
Una descripción del código
- Importamos bibliotecas como pandas para trabajar con los datos, DecisionTreeClassifier de scikit-learn para construir el árbol y matplotlib para mostrar los resultados.
- Crear un conjunto de datos: la edad, los ingresos y el estado de compra se utilizan para crear un conjunto de datos de muestra.
- Prepare las funciones y los objetivos: la variable objetivo (Comprado) y las características (Edad, Ingresos) están configuradas.
- Entrenar el modelo: La información se utiliza para configurar y entrenar el clasificador del árbol de decisiones.
- Ver el árbol: Finalmente, dibujamos el árbol de decisiones para que podamos ver cómo se toman las decisiones.
Aquí está el código.
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
data = {
'Age': (25, 45, 35, 50, 23),
'Income': (50000, 100000, 75000, 120000, 60000),
'Purchased': ('No', 'Yes', 'No', 'Yes', 'No')
}
df = pd.DataFrame(data)
x = df(('Age', 'Income'))
y = df('Purchased')
clf = DecisionTreeClassifier()
clf = clf.fit(x, y)
plt.figure(figsize=(10, 8))
tree.plot_tree(clf, feature_names=('Age', 'Income'), class_names=('No', 'Yes'), filled=True)
plt.show()Aquí está el resultado.
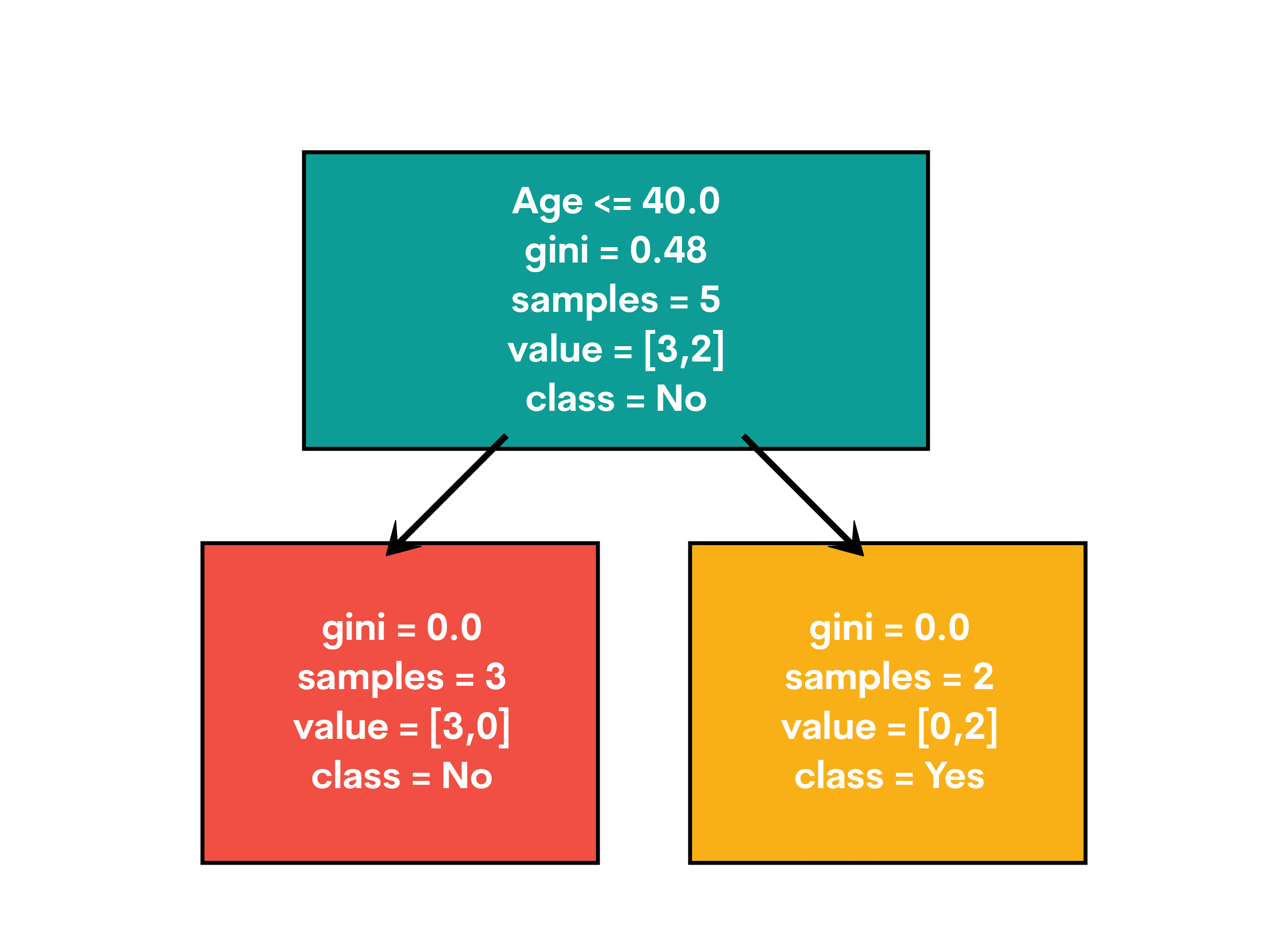
El árbol de decisión final mostrará cómo se divide el árbol en función de la edad y los ingresos para determinar si es probable que un cliente compre un producto. Cada nodo es un punto de decisión y las ramas muestran diferentes resultados. La decisión final se muestra en los nodos de hoja.
¡Ahora, veamos cómo se pueden utilizar las entrevistas en el mundo real!
Aplicaciones en el mundo real
Este proyecto está diseñado como una tarea para llevar a casa para los puestos de ciencia de datos de Meta (facebook). El objetivo es crear un algoritmo de clasificación que prediga si una película en Rotten Tomatoes está etiquetada como “Podrida”, “Fresca” o “Certificada como fresca”.
Aquí está el enlace a este proyecto: https://platform.stratascratch.com/data-projects/rotten-tomatoes-movies-rating-prediction
Ahora, dividamos la solución en pasos codificables.
Solución paso a paso
- Preparación de datos:Fusionaremos los dos conjuntos de datos en el enlace de tomates podridos Columna. Esto nos proporcionará un conjunto de datos completo con información de películas y críticas de los críticos.
- Selección de características e ingeniería:Seleccionaremos las características relevantes y realizaremos las transformaciones necesarias. Esto incluye convertir variables categóricas en numéricas, manejar valores faltantes y normalizar los valores de las características.
- Entrenamiento de modelosEntrenaremos un clasificador de árbol de decisiones en el conjunto de datos procesados y utilizaremos la validación cruzada para evaluar el desempeño sólido del modelo.
- Evaluación:Por último, evaluaremos el rendimiento del modelo utilizando métricas como precisión, exactitud, recuperación y puntuación F1.
Aquí está el código.
import pandas as pd
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler
movies_df = pd.read_csv('rotten_tomatoes_movies.csv')
reviews_df = pd.read_csv('rotten_tomatoes_critic_reviews_50k.csv')
merged_df = pd.merge(movies_df, reviews_df, on='rotten_tomatoes_link')
features = ('content_rating', 'genres', 'directors', 'runtime', 'tomatometer_rating', 'audience_rating')
target="tomatometer_status"
merged_df('content_rating') = merged_df('content_rating').astype('category').cat.codes
merged_df('genres') = merged_df('genres').astype('category').cat.codes
merged_df('directors') = merged_df('directors').astype('category').cat.codes
merged_df = merged_df.dropna(subset=features + (target))
x = merged_df(features)
y = merged_df(target).astype('category').cat.codes
scaler = StandardScaler()
X_scaled = scaler.fit_transform(x)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
clf = DecisionTreeClassifier(max_depth=10, min_samples_split=10, min_samples_leaf=5)
scores = cross_val_score(clf, X_train, y_train, cv=5)
print("Cross-validation scores:", scores)
print("Average cross-validation score:", scores.mean())
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
classification_report_output = classification_report(y_test, y_pred, target_names=('Rotten', 'Fresh', 'Certified-Fresh'))
print(classification_report_output)Aquí está el resultado.
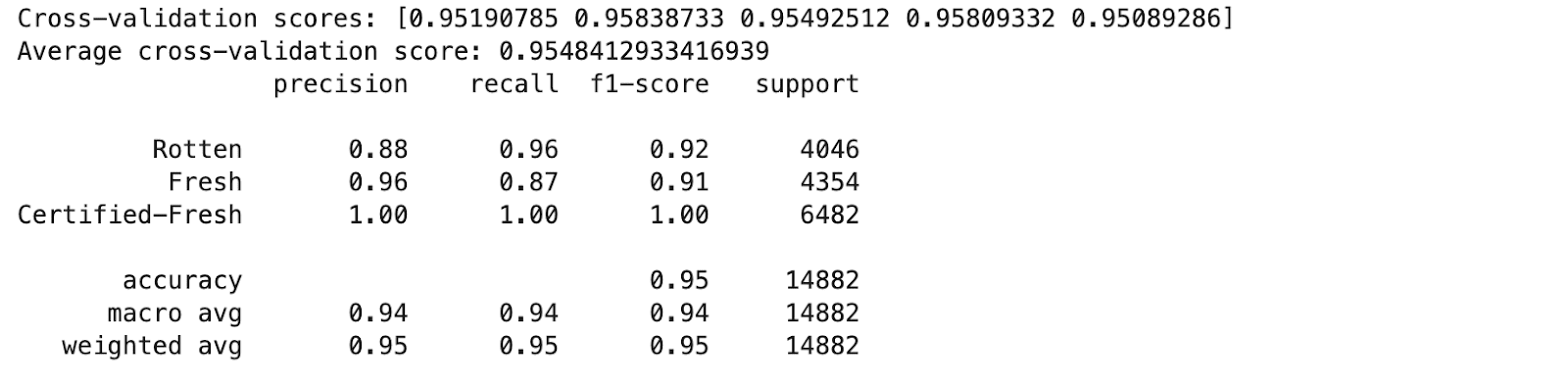
El modelo muestra una alta precisión y puntuaciones F1 en todas las clases, lo que indica un buen rendimiento. Veamos las conclusiones clave.
Puntos clave
- La selección de características es crucial para el rendimiento del modelo. La clasificación de contenido, los géneros, la duración de los directores y las clasificaciones resultaron ser predictores valiosos.
- Un clasificador de árbol de decisiones captura eficazmente relaciones complejas en datos de películas.
- La validación cruzada garantiza la confiabilidad del modelo en diferentes subconjuntos de datos.
- El alto rendimiento en la clase “Certificado Fresco” justifica una mayor investigación sobre el posible desequilibrio de clase.
- El modelo parece prometedor para su aplicación en el mundo real a la hora de predecir las clasificaciones de películas y mejorar la experiencia del usuario en plataformas como Rotten Tomatoes.
Mejorar los árboles de decisión: convertir su retoño en un poderoso roble
Entonces, ya has hecho crecer tu primer árbol de decisiones. ¡Impresionante! Pero, ¿por qué detenerte ahí? Convirtamos ese retoño en un gigante forestal que pondría celoso hasta a Groot. ¿Estás listo para fortalecer tu árbol? ¡Vamos a sumergirnos en ello!
Técnicas de poda
La poda es un método que se utiliza para reducir el tamaño de un árbol de decisiones eliminando las partes que tienen una capacidad mínima para predecir la variable objetivo. Esto ayuda a reducir el sobreajuste en particular.
- Prepoda:A menudo denominado detención temprana, esto implica detener el crecimiento del árbol de inmediato. Antes del entrenamiento, se especifican los parámetros del modelo, incluida la profundidad máxima (profundidad máxima), muestras mínimas necesarias para dividir un nodo (división de muestras mínimas), y muestras mínimas requeridas en un nodo hoja (min_muestras_hoja). Esto evita que el árbol crezca demasiado complicado.
- Post-poda:Este método hace crecer el árbol hasta su máxima profundidad y elimina los nodos que no ofrecen mucha potencia. Aunque es más exigente en términos computacionales que la poda previa, la poda posterior puede ser más exitosa.
Métodos de conjunto
Las técnicas de conjunto combinan varios modelos para generar un rendimiento superior al de cualquier modelo individual. Dos formas principales de técnicas de conjunto aplicadas con árboles de decisión son bagging y boosting.
- Ensacado (agregación bootstrap):Este método entrena varios árboles de decisión en varios subconjuntos de los datos (generados por muestreo con reemplazo) y luego promedia sus predicciones. Una técnica de bagging que se usa a menudo es Random Forest. Reduce la varianza y ayuda a prevenir el sobreajuste. Vea “Algoritmo de árboles de decisión y bosque aleatorio“abordar en profundidad todo lo relacionado con el algoritmo Decision Tree y su extensión “Random Forest algorithm”.
- Impulsando:El boosting crea árboles uno tras otro, ya que cada uno busca corregir los errores del siguiente. Las técnicas de boosting abundan en algoritmos como AdaBoost y Gradient Boosting. Al enfatizar los ejemplos difíciles de predecir, estos algoritmos a veces proporcionan modelos más exactos.
Ajuste de hiperparámetros
El ajuste de hiperparámetros es el proceso de determinar el conjunto de hiperparámetros óptimo para un modelo de árbol de decisiones con el fin de aumentar su rendimiento. Esto se puede lograr mediante el uso de métodos como la búsqueda en cuadrícula o la búsqueda aleatoria, mediante los cuales se evalúan varias combinaciones de hiperparámetros para identificar la mejor configuración.
Conclusión
En este artículo, analizamos la estructura, el mecanismo de funcionamiento, las aplicaciones en el mundo real y los métodos para mejorar el rendimiento del árbol de decisiones.
Practicar los árboles de decisión es fundamental para dominar su uso y comprender sus matices. Trabajar en proyectos de datos del mundo real también puede brindar una experiencia valiosa y mejorar las habilidades de resolución de problemas.
twitter.com/StrataScratch” rel=”noopener”>twitter.com/StrataScratch” target=”_blank” rel=”noopener noreferrer”>Nate Rosidi Nate es un científico de datos y especialista en estrategia de productos. También es profesor adjunto de analítica y es el fundador de StrataScratch, una plataforma que ayuda a los científicos de datos a prepararse para sus entrevistas con preguntas de entrevistas reales de las principales empresas. Nate escribe sobre las últimas tendencias en el mercado laboral, brinda consejos para entrevistas, comparte proyectos de ciencia de datos y cubre todo lo relacionado con SQL.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}