 NEWSLETTER
NEWSLETTER
artificial intelligence, in particular the development of large language models (LLMs), has advanced rapidly and has focused on improving the reasoning capabilities of these models. As ai systems are increasingly faced with solving complex problems, it is critical that they not only generate accurate solutions but also possess the ability to critically evaluate and refine their results. This improvement in reasoning is essential to create ai that can operate more autonomously and reliably on a variety of sophisticated tasks. Ongoing research in this field reflects the growing demand for ai systems that can independently evaluate their reasoning processes and correct potential errors, thereby becoming more effective and reliable tools.
A major challenge to the advancement of LLMs is the development of mechanisms that enable these models to effectively critique their reasoning processes. Current methods often rely on basic prompts or external feedback, which are limited in scope and effectiveness. These approaches typically involve simple critiques that point out errors but do not provide the depth of understanding needed to substantially improve the model’s reasoning accuracy. This limitation results in errors going unnoticed or being addressed incorrectly, restricting ai’s ability to reliably perform complex tasks. The challenge, therefore, lies in creating a self-critique framework that enables ai models to critically analyze and meaningfully improve their results.
Traditionally, ai systems have improved their reasoning capabilities through external feedback mechanisms, where human annotators or other systems provide corrective feedback. While these methods can be effective, they are also resource-intensive and scalable, making them impractical for widespread use. Furthermore, some existing approaches incorporate basic forms of self-criticism, but these often need to be revised to significantly improve model performance. The key problem with these methods is that they do not sufficiently improve the model’s intrinsic ability to evaluate and refine its reasoning, which is essential for developing smarter ai systems.
Researchers from the China Key Laboratory of Information Processing, the Chinese Academy of Sciences, the University of the Chinese Academy of Sciences and Xiaohongshu Inc. have developed a new framework called Critical-CoTThis framework is designed to significantly improve LLMs’ self-criticism skills by guiding them toward more rigorous, System 2-like reasoning. The Critic-CoT framework leverages a structured Chain of Thought (CoT) format, which enables models to evaluate their reasoning steps and make necessary adjustments in a systematic manner. This innovative approach reduces the need for costly human annotations while pushing the boundaries of what ai can achieve in self-assessment and correction.
The Critic-CoT framework works by engaging LLMs in a process of gradual critique. The model first generates a solution to a given problem and then critiques its result, identifying errors or areas for improvement. The model then refines the solution based on the critique, and this process is repeated iteratively until the solution is either corrected or validated. For example, during experiments with the GSM8K and MATH datasets, the Critic-CoT model was able to detect and correct errors in its solutions with high accuracy. The iterative nature of this process allows the model to continually improve its reasoning capabilities, making it better suited to handle complex tasks.
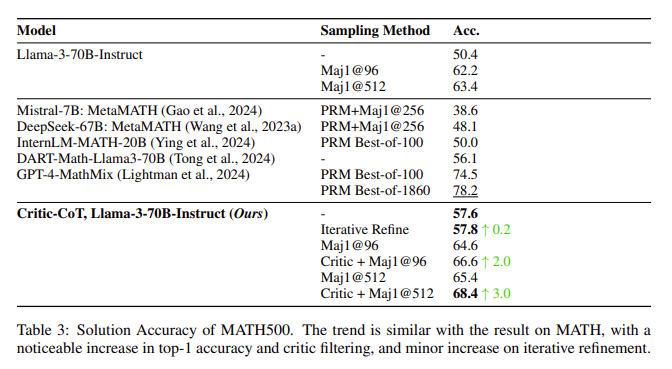
The effectiveness of the Critic-CoT framework was demonstrated through extensive experiments. On the GSM8K dataset, which consists of elementary school-level math problems, the LLM’s accuracy improved from 89.6% to 93.3% after iterative refinement, with a critical filter further increasing the accuracy to 95.4%. Similarly, on the more challenging MATH dataset, which includes high school math proficiency problems, the model’s accuracy increased from 51.0% to 57.8% after employing the Critic-CoT framework, with additional gains observed when applying the critical filter. These results highlight the significant improvements in task-solving performance that can be achieved through the Critic-CoT framework, particularly when the model is faced with complex reasoning scenarios.
In conclusion, the Critic-CoT framework represents a substantial advance in developing self-criticism capabilities for LLMs. This research addresses the critical challenge of enabling ai models to evaluate and improve their reasoning by introducing a structured and iterative refinement process. The impressive gains in accuracy observed on the GSM8K and MATH datasets demonstrate the potential of Critic-CoT to improve the performance of ai systems on a variety of complex tasks. This framework improves the accuracy and reliability of ai reasoning and reduces the need for human intervention, making it a scalable and efficient solution for future ai development.
Take a look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and LinkedInJoin our Telegram Channel. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
Sana Hassan, a Consulting Intern at Marktechpost and a dual degree student at IIT Madras, is passionate about applying technology and ai to address real-world challenges. With a keen interest in solving practical problems, she brings a fresh perspective to the intersection of ai and real-life solutions.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}