 NEWSLETTER
NEWSLETTER
El lenguaje de consulta estructurado (SQL) es un lenguaje complejo que requiere comprensión de bases de datos y metadatos. Hoy en día, la IA generativa puede ayudar a personas sin conocimientos de SQL. Esta tarea generativa de IA se llama texto a SQL, que genera consultas SQL a partir del procesamiento del lenguaje natural (NLP) y convierte el texto en SQL semánticamente correcto. La solución de esta publicación tiene como objetivo llevar las operaciones de análisis empresarial al siguiente nivel al acortar el camino hacia sus datos utilizando lenguaje natural.
Con la aparición de grandes modelos de lenguaje (LLM), la generación de SQL basada en PNL ha experimentado una transformación significativa. Al demostrar un rendimiento excepcional, los LLM ahora son capaces de generar consultas SQL precisas a partir de descripciones en lenguaje natural. Sin embargo, aún persisten desafíos. En primer lugar, el lenguaje humano es inherentemente ambiguo y depende del contexto, mientras que SQL es preciso, matemático y estructurado. Esta brecha puede resultar en una conversión inexacta de las necesidades del usuario en el SQL que se genera. En segundo lugar, es posible que necesite crear funciones de texto a SQL para cada base de datos porque los datos a menudo no se almacenan en un único destino. Es posible que deba volver a crear la capacidad de cada base de datos para permitir a los usuarios la generación de SQL basada en NLP. En tercer lugar, a pesar de la mayor adopción de soluciones de análisis centralizadas, como lagos y almacenes de datos, la complejidad aumenta con los diferentes nombres de tablas y otros metadatos que se requieren para crear el SQL para las fuentes deseadas. Por lo tanto, la recopilación de metadatos completos y de alta calidad también sigue siendo un desafío. Para obtener más información sobre las mejores prácticas y patrones de diseño de texto a SQL, consulte Generación de valor a partir de datos empresariales: mejores prácticas para Text2SQL e IA generativa.
Nuestra solución tiene como objetivo abordar esos desafíos utilizando Amazon Bedrock y AWS Analytics Services. Usamos Anthropic Claude v2.1 en Amazon Bedrock como nuestro LLM. Para abordar los desafíos, nuestra solución primero incorpora los metadatos de las fuentes de datos dentro del catálogo de datos de AWS Glue para aumentar la precisión de la consulta SQL generada. El flujo de trabajo también incluye un ciclo de evaluación y corrección final, en caso de que Amazon Athena, que se utiliza en sentido descendente como motor SQL, identifique algún problema de SQL. Athena también nos permite utilizar una multitud de terminales y conectores compatibles para cubrir un gran conjunto de fuentes de datos.
Después de seguir los pasos para crear la solución, presentamos los resultados de algunos escenarios de prueba con distintos niveles de complejidad de SQL. Finalmente, analizamos cómo es sencillo incorporar diferentes fuentes de datos a sus consultas SQL.
Descripción general de la solución
Hay tres componentes críticos en nuestra arquitectura: recuperación de generación aumentada (RAG) con metadatos de base de datos, un bucle de autocorrección de varios pasos y Athena como nuestro motor SQL.
Usamos el método RAG para recuperar las descripciones de las tablas y las descripciones de los esquemas (columnas) del metastore de AWS Glue para garantizar que la solicitud esté relacionada con la tabla y los conjuntos de datos correctos. En nuestra solución, creamos los pasos individuales para ejecutar un marco RAG con el catálogo de datos de AWS Glue con fines de demostración. Sin embargo, también puede utilizar las bases de conocimientos de Amazon Bedrock para crear soluciones RAG rápidamente.
El componente de varios pasos permite al LLM corregir la precisión de la consulta SQL generada. Aquí, el SQL generado se envía en caso de errores de sintaxis. Usamos mensajes de error de Athena para enriquecer nuestro mensaje para el LLM y obtener correcciones más precisas y efectivas en el SQL generado.
Puede considerar los mensajes de error que ocasionalmente provienen de Athena como comentarios. Las implicaciones de costos de un paso de corrección de errores son insignificantes en comparación con el valor entregado. Incluso puede incluir estos pasos correctivos como ejemplos de aprendizaje reforzado supervisado para perfeccionar sus LLM. Sin embargo, no cubrimos este flujo en nuestra publicación por motivos de simplicidad.
Tenga en cuenta que siempre existe un riesgo inherente de tener imprecisiones, lo que naturalmente viene con las soluciones de IA generativa. Incluso si los mensajes de error de Athena son muy eficaces para mitigar este riesgo, puede agregar más controles y vistas, como comentarios humanos o consultas de ejemplo para realizar ajustes, para minimizar aún más dichos riesgos.
Athena no solo nos permite corregir las consultas SQL, sino que también nos simplifica el problema general porque sirve como centro, donde los radios son múltiples fuentes de datos. La gestión del acceso, la sintaxis SQL y más se gestionan a través de Athena.
El siguiente diagrama ilustra la arquitectura de la solución.
Figura 1. La arquitectura de la solución y el flujo del proceso.
El flujo del proceso incluye los siguientes pasos:
- Cree el catálogo de datos de AWS Glue mediante un rastreador de AWS Glue (o un método diferente).
- Utilizando el modelo Titan-Text-Embeddings en Amazon Bedrock, convierta los metadatos en incrustaciones y guárdelos en un almacén de vectores sin servidor de Amazon OpenSearch, que sirve como nuestra base de conocimientos en nuestro marco RAG.
En esta etapa el proceso está listo para recibir la consulta en lenguaje natural. Los pasos 7 a 9 representan un ciclo de corrección, si corresponde.
- El usuario ingresa su consulta en lenguaje natural. Puede utilizar cualquier aplicación web para proporcionar la interfaz de usuario del chat. Por lo tanto, no cubrimos los detalles de la interfaz de usuario en nuestra publicación.
- La solución aplica un marco RAG mediante búsqueda por similitud, que agrega contexto adicional de los metadatos de la base de datos vectorial. Esta tabla se utiliza para encontrar la tabla, la base de datos y los atributos correctos.
- La consulta se fusiona con el contexto y se envía a Anthropic Claude v2.1 en Amazon Bedrock.
- El modelo obtiene la consulta SQL generada y se conecta a Athena para validar la sintaxis.
- Si Athena proporciona un mensaje de error que menciona que la sintaxis es incorrecta, el modelo utiliza el texto de error de la respuesta de Athena.
- El nuevo mensaje agrega la respuesta de Athena.
- El modelo crea el SQL corregido y continúa el proceso. Esta iteración se puede realizar varias veces.
- Finalmente, ejecutamos SQL usando Athena y generamos resultados. Aquí, el resultado se presenta al usuario. Por motivos de simplicidad arquitectónica, no mostramos este paso.
Requisitos previos
Para esta publicación, debe completar los siguientes requisitos previos:
- Tener una cuenta de AWS.
- Instale la interfaz de línea de comandos de AWS (AWS CLI).
- Configurar el SDK para Python (Boto3).
- Cree el catálogo de datos de AWS Glue mediante un rastreador de AWS Glue (o un método diferente).
- Utilizando el modelo Titan-Text-Embeddings en Amazon Bedrock, convierta los metadatos en incrustaciones y guárdelos en un almacén de vectores OpenSearch Serverless.
Implementar la solución
Puedes usar lo siguiente cuaderno jupyter, que incluye todos los fragmentos de código proporcionados en esta sección, para crear la solución. Recomendamos utilizar Amazon SageMaker Studio para abrir este cuaderno con una instancia ml.t3.medium con el kernel Python 3 (Ciencia de datos). Para obtener instrucciones, consulte Entrenar un modelo de aprendizaje automático. Complete los siguientes pasos para configurar la solución:
- Cree la base de conocimientos en OpenSearch Service para el marco RAG:
- Construya el mensaje (
final_question) combinando la entrada del usuario en lenguaje natural (user_query), los metadatos relevantes del almacén de vectores (vector_search_match), y nuestras instrucciones (details): - Invoque Amazon Bedrock para el LLM (Claude v2) y solicite que genere la consulta SQL. En el siguiente código, realiza varios intentos para ilustrar el paso de autocorrección:x
- Si se recibe algún problema con la consulta SQL generada (
{sqlgenerated}) de la respuesta de Atenas ({syntaxcheckmsg}), el nuevo mensaje (prompt) se genera en función de la respuesta y el modelo intenta nuevamente generar el nuevo SQL: - Una vez generado el SQL, se invoca al cliente Athena para ejecutarlo y generar el resultado:
Prueba la solución
En esta sección, ejecutamos nuestra solución con diferentes escenarios de ejemplo para probar diferentes niveles de complejidad de consultas SQL.
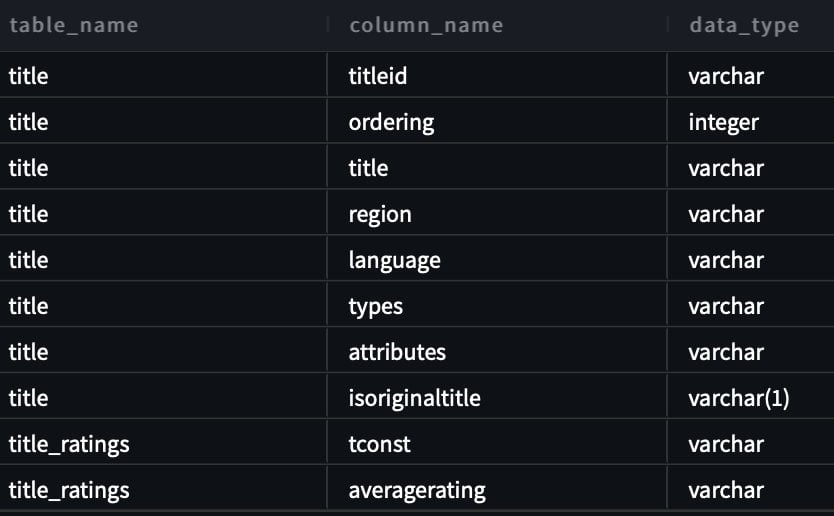
Para probar nuestro texto a SQL, utilizamos dos conjuntos de datos disponibles en IMDB. Subconjuntos de datos de IMDb están disponibles para uso personal y no comercial. Puede descargar los conjuntos de datos y almacenarlos en Amazon Simple Storage Service (Amazon S3). Puede utilizar el siguiente fragmento de Spark SQL para crear tablas en AWS Glue. Para este ejemplo, utilizamos title_ratings y title:
Almacene datos en Amazon S3 y metadatos en AWS Glue
En este escenario, nuestro conjunto de datos se almacena en un depósito de S3. Athena tiene un conector S3 que le permite utilizar Amazon S3 como fuente de datos que se puede consultar.
Para nuestra primera consulta, proporcionamos la entrada “Soy nuevo en esto. ¿Puedes ayudarme a ver todas las tablas y columnas en el esquema imdb?
La siguiente es la consulta generada:
La siguiente captura de pantalla y el código muestran nuestro resultado.
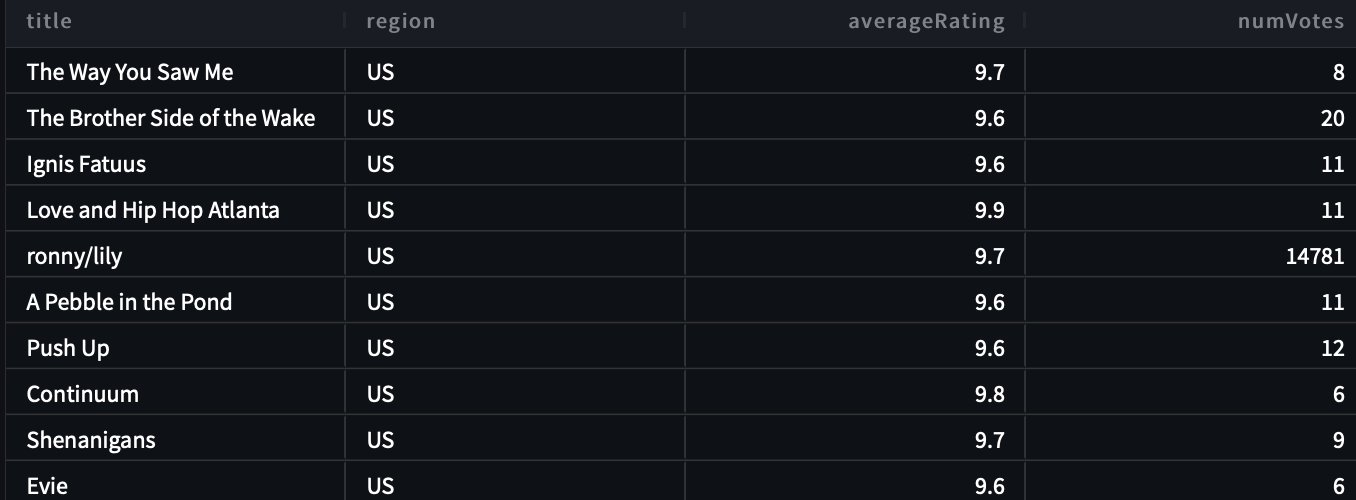
Para nuestra segunda consulta, preguntamos “Muéstreme todos los títulos y detalles en la región de EE. UU. cuya calificación sea superior a 9,5”.
La siguiente es nuestra consulta generada:
La respuesta es la siguiente.
Para nuestra tercera consulta, ingresamos “¡Excelente respuesta! Ahora muéstrame todos los títulos de tipo original que tengan calificaciones superiores a 7,5 y que no estén en la región de EE. UU.”.
Se genera la siguiente consulta:
Obtenemos los siguientes resultados.

Generar SQL autocorregido
Este escenario simula una consulta SQL que tiene problemas de sintaxis. Aquí, el SQL generado se autocorregirá según la respuesta de Athena. En la siguiente respuesta, Atenea dio una COLUMN_NOT_FOUND error y menciono que table_description no se puede resolver:
Usar la solución con otras fuentes de datos
Para utilizar la solución con otras fuentes de datos, Athena se encarga del trabajo por usted. Para ello, Athena utiliza conectores de fuentes de datos que se pueden utilizar con consultas federadas. Puede considerar un conector como una extensión del motor de consultas de Athena. Existen conectores de fuentes de datos Athena prediseñados para fuentes de datos como Amazon CloudWatch Logs, Amazon DynamoDB, Amazon DocumentDB (con compatibilidad con MongoDB) y Amazon Relational Database Service (Amazon RDS), y fuentes de datos relacionales compatibles con JDBC como MySQL y PostgreSQL en la licencia Apache 2.0. Después de configurar una conexión a cualquier fuente de datos, puede utilizar el código base anterior para ampliar la solución. Para obtener más información, consulte Consultar cualquier origen de datos con la nueva consulta federada de Amazon Athena.
Limpiar
Para limpiar los recursos, puede comenzar limpiando su depósito S3 donde residen los datos. A menos que su aplicación invoque Amazon Bedrock, no generará ningún costo. En aras de las mejores prácticas de gestión de infraestructura, recomendamos eliminar los recursos creados en esta demostración.
Conclusión
En esta publicación, presentamos una solución que le permite utilizar PNL para generar consultas SQL complejas con una variedad de recursos habilitados por Athena. También aumentamos la precisión de las consultas SQL generadas a través de un ciclo de evaluación de varios pasos basado en mensajes de error de procesos posteriores. Además, utilizamos los metadatos del catálogo de datos de AWS Glue para considerar los nombres de las tablas solicitados en la consulta a través del marco RAG. Luego probamos la solución en varios escenarios realistas con diferentes niveles de complejidad de consultas. Finalmente, discutimos cómo aplicar esta solución a diferentes fuentes de datos respaldadas por Athena.
Amazon Bedrock está en el centro de esta solución. Amazon Bedrock puede ayudarle a crear muchas aplicaciones de IA generativa. Para comenzar con Amazon Bedrock, recomendamos seguir el inicio rápido a continuación repositorio de GitHub y familiarizarse con la creación de aplicaciones de IA generativa. También puede probar las bases de conocimientos en Amazon Bedrock para crear rápidamente este tipo de soluciones RAG.
Sobre los autores
 Panda Sanjeeb es ingeniero de datos y aprendizaje automático en Amazon. Con experiencia en IA/ML, ciencia de datos y Big Data, Sanjeeb diseña y desarrolla datos innovadores y soluciones de ML que resuelven desafíos técnicos complejos y logran objetivos estratégicos para los vendedores 3P globales que administran sus negocios en Amazon. Además de su trabajo como ingeniero de datos y aprendizaje automático en Amazon, Sanjeeb Panda es un ávido entusiasta de la comida y la música.
Panda Sanjeeb es ingeniero de datos y aprendizaje automático en Amazon. Con experiencia en IA/ML, ciencia de datos y Big Data, Sanjeeb diseña y desarrolla datos innovadores y soluciones de ML que resuelven desafíos técnicos complejos y logran objetivos estratégicos para los vendedores 3P globales que administran sus negocios en Amazon. Además de su trabajo como ingeniero de datos y aprendizaje automático en Amazon, Sanjeeb Panda es un ávido entusiasta de la comida y la música.
 Burak Gozluklu es un arquitecto principal de soluciones especializado en IA/ML ubicado en Boston, MA. Ayuda a clientes estratégicos a adoptar tecnologías de AWS y específicamente soluciones de IA generativa para lograr sus objetivos comerciales. Burak tiene un doctorado en Ingeniería Aeroespacial de METU, una maestría en Ingeniería de Sistemas y un postdoctorado en dinámica de sistemas del MIT en Cambridge, MA. Burak sigue siendo un afiliado de investigación en el MIT. Burak es un apasionado del yoga y la meditación.
Burak Gozluklu es un arquitecto principal de soluciones especializado en IA/ML ubicado en Boston, MA. Ayuda a clientes estratégicos a adoptar tecnologías de AWS y específicamente soluciones de IA generativa para lograr sus objetivos comerciales. Burak tiene un doctorado en Ingeniería Aeroespacial de METU, una maestría en Ingeniería de Sistemas y un postdoctorado en dinámica de sistemas del MIT en Cambridge, MA. Burak sigue siendo un afiliado de investigación en el MIT. Burak es un apasionado del yoga y la meditación.





{kind=link}