 NEWSLETTER
NEWSLETTER
Los clientes de atención médica y ciencias biológicas (HCLS) están adoptando la IA generativa como herramienta para sacar más provecho de sus datos. Los casos de uso incluyen el resumen de documentos para ayudar a los lectores a centrarse en los puntos clave de un documento y la transformación de texto no estructurado en formatos estandarizados para resaltar atributos importantes. Con formatos de datos únicos y requisitos regulatorios estrictos, los clientes buscan opciones para seleccionar el modelo más eficaz y rentable, así como la capacidad de realizar la personalización necesaria (ajustes) para adaptarse a su caso de uso empresarial. En esta publicación, lo guiaremos en la implementación de un modelo de lenguaje grande (LLM) de Falcon utilizando Amazon SageMaker JumpStart y el uso del modelo para resumir documentos largos con LangChain y Python.
Descripción general de la solución
Amazon SageMaker se basa en las dos décadas de experiencia de Amazon en el desarrollo de aplicaciones de aprendizaje automático del mundo real, incluidas recomendaciones de productos, personalización, compras inteligentes, robótica y dispositivos asistidos por voz. SageMaker es un servicio administrado elegible para HIPAA que proporciona herramientas que permiten a los científicos de datos, ingenieros de ML y analistas de negocios innovar con ML. Dentro de SageMaker se encuentra Amazon SageMaker Studio, un entorno de desarrollo integrado (IDE) diseñado específicamente para flujos de trabajo de ML colaborativos, que, a su vez, contiene una amplia variedad de soluciones de inicio rápido y modelos de ML previamente entrenados en un centro integrado llamado SageMaker JumpStart. Con SageMaker JumpStart, puede utilizar modelos previamente entrenados, como Falcon LLM, con cuadernos de muestra prediseñados y compatibilidad con SDK para experimentar e implementar estos potentes modelos de transformadores. Puede utilizar SageMaker Studio y SageMaker JumpStart para implementar y consultar su propio modelo generativo en su cuenta de AWS.
También puede asegurarse de que los datos de la carga útil de inferencia no abandonen su VPC. Puede aprovisionar modelos como puntos finales de un solo inquilino e implementarlos con aislamiento de red. Además, puede seleccionar y administrar el conjunto seleccionado de modelos que satisfagan sus propios requisitos de seguridad utilizando la capacidad del centro de modelos privado dentro de SageMaker JumpStart y almacenando allí los modelos aprobados. SageMaker está dentro del alcance de HIPAA BAA, SOC123 y HITRUST CSF.
El Falcón LLM es un modelo de lenguaje grande, capacitado por investigadores del Instituto de Innovación Tecnológica (TII) en más de 1 billón de tokens utilizando AWS. Falcon tiene muchas variaciones diferentes, con sus dos componentes principales Falcon 40B y Falcon 7B, compuestos por 40 mil millones y 7 mil millones de parámetros, respectivamente, con versiones ajustadas entrenadas para tareas específicas, como seguir instrucciones. Falcon se desempeña bien en una variedad de tareas, incluido el resumen de texto, el análisis de sentimientos, la respuesta a preguntas y la conversación. Esta publicación proporciona un tutorial que puede seguir para implementar Falcon LLM en su cuenta de AWS, utilizando una instancia de cuaderno administrada a través de SageMaker JumpStart para experimentar con el resumen de texto.
El centro de modelos SageMaker JumpStart incluye cuadernos completos para implementar y consultar cada modelo. Al momento de escribir este artículo, hay seis versiones de Falcon disponibles en el centro de modelos SageMaker JumpStart: Falcon 40B Instruct BF16, Falcon 40B BF16, Falcon 180B BF16, Falcon 180B Chat BF16, Falcon 7B Instruct BF16 y Falcon 7B BF16. Esta publicación utiliza el modelo Falcon 7B Instruct.
En las siguientes secciones, mostramos cómo comenzar con el resumen de documentos implementando Falcon 7B en SageMaker Jumpstart.
Requisitos previos
Para este tutorial, necesitará una cuenta de AWS con un dominio de SageMaker. Si aún no tiene un dominio de SageMaker, consulte Incorporación al dominio de Amazon SageMaker para crear uno.
Implemente Falcon 7B usando SageMaker JumpStart
Para implementar su modelo, complete los siguientes pasos:
- Navegue a su entorno de SageMaker Studio desde la consola de SageMaker.
- Dentro del IDE, bajo Inicio rápido de SageMaker en el panel de navegación, elija Modelos, cuadernos, soluciones..
- Implemente el modelo Falcon 7B Instruct en un punto final para realizar inferencias.
Esto abrirá la tarjeta de modelo para el modelo Falcon 7B Instruct BF16. En esta página podrás encontrar el Desplegar o Tren opciones, así como enlaces para abrir los cuadernos de muestra en SageMaker Studio. Esta publicación utilizará el cuaderno de muestra de SageMaker JumpStart para implementar el modelo.
- Elegir Cuaderno abierto.
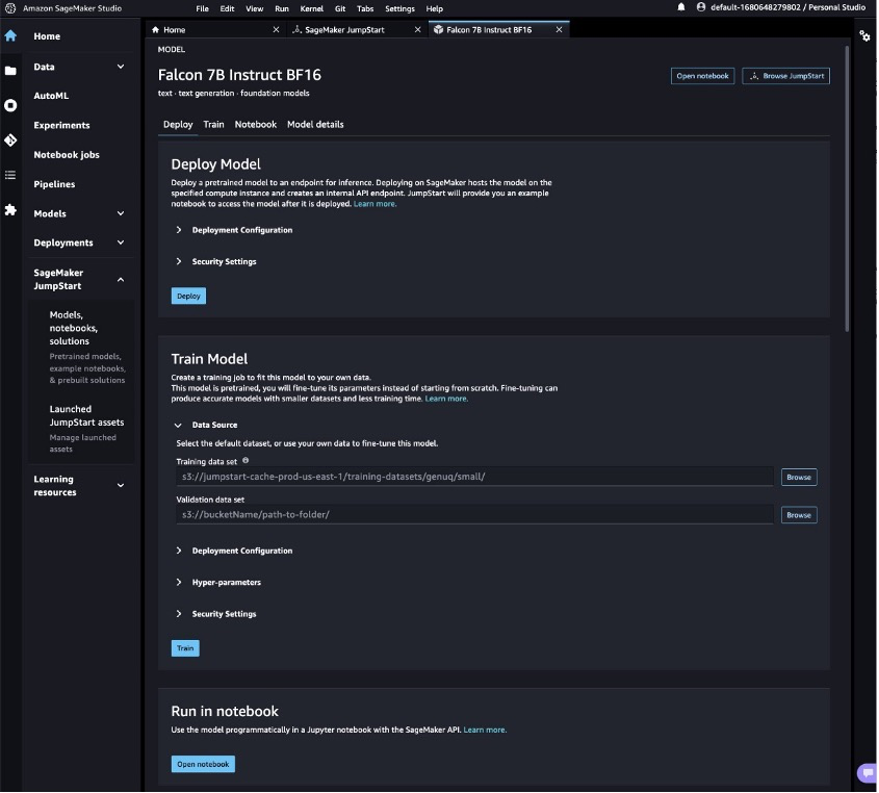
- Ejecute las primeras cuatro celdas del cuaderno para implementar el punto final Falcon 7B Instruct.
Puede ver sus modelos JumpStart implementados en la Activos JumpStart lanzados página.
- En el panel de navegación, en Inicio rápido de SageMakerelegir Activos JumpStart lanzados.
- Elegir el Puntos finales del modelo para ver el estado de su punto final.
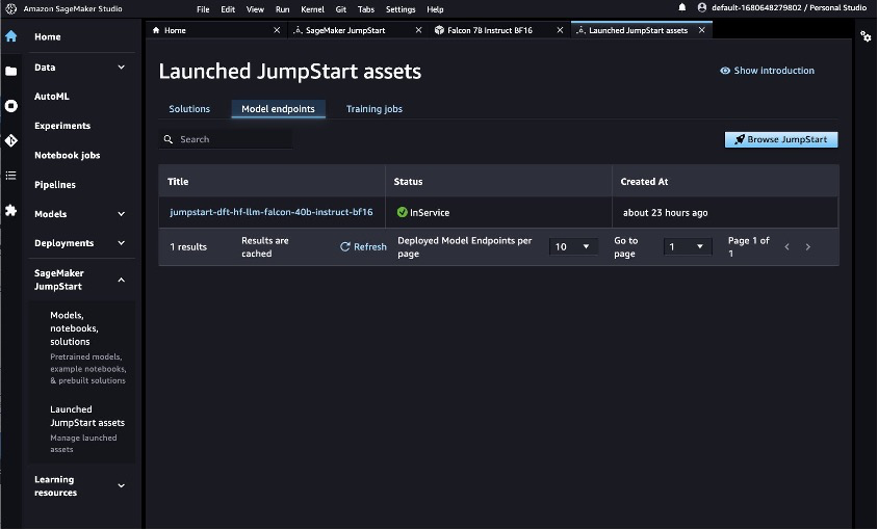
Con el terminal Falcon LLM implementado, estará listo para consultar el modelo.
Ejecute su primera consulta
Para ejecutar una consulta, complete los siguientes pasos:
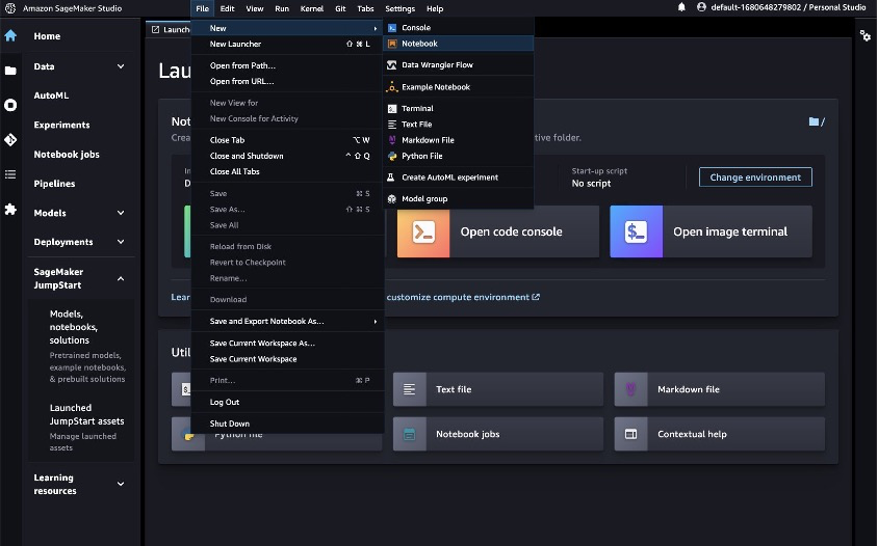
- Sobre el Archivo menú, elija Nuevo y Computadora portátil para abrir un nuevo cuaderno.
También puedes descargar el cuaderno completo. aquí.
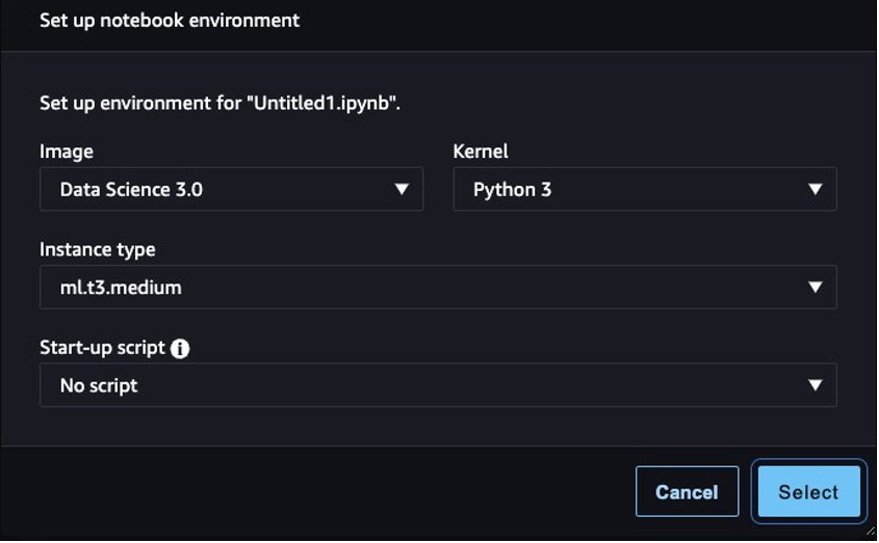
- Seleccione la imagen, el kernel y el tipo de instancia cuando se le solicite. Para esta publicación, elegimos la imagen Data Science 3.0, el kernel Python 3 y la instancia ml.t3.medium.
- Importe los módulos Boto3 y JSON ingresando las dos líneas siguientes en la primera celda:
- Prensa Mayús + Intro para ejecutar la celda.
- A continuación, puede definir una función que llamará a su punto final. Esta función toma una carga útil del diccionario y la utiliza para invocar el cliente de ejecución de SageMaker. Luego deserializa la respuesta e imprime la entrada y el texto generado.
La carga útil incluye el mensaje como entradas, junto con los parámetros de inferencia que se pasarán al modelo.
- Puede utilizar estos parámetros con el mensaje para ajustar la salida del modelo para su caso de uso:
Consulta con un mensaje de resumen
Esta publicación utiliza un trabajo de investigación de muestra para demostrar el resumen. El archivo de texto de ejemplo trata sobre el resumen automático de texto en literatura biomédica. Complete los siguientes pasos:
- Descargar el PDF y copie el texto en un archivo llamado
document.txt. - En SageMaker Studio, elija el icono de carga y cargue el archivo en su instancia de SageMaker Studio.
Desde el primer momento, Falcon LLM brinda soporte para el resumen de texto.
- Creemos una función que utilice técnicas de ingeniería rápidas para resumir
document.txt:
Notarás que para documentos más largos, aparece un error: Falcon, junto con todos los demás LLM, tiene un límite en la cantidad de tokens pasados como entrada. Podemos sortear este límite utilizando las capacidades de resumen mejoradas de LangChain, que permiten pasar una entrada mucho mayor al LLM.
Importar y ejecutar una cadena de resumen
LangChain es una biblioteca de software de código abierto que permite a los desarrolladores y científicos de datos crear, ajustar e implementar rápidamente aplicaciones generativas personalizadas sin administrar interacciones complejas de aprendizaje automático, comúnmente utilizada para abstraer muchos de los casos de uso comunes de los modelos de lenguaje generativo de IA en solo unos pocos. líneas de código. El soporte de LangChain para los servicios de AWS incluye soporte para puntos finales de SageMaker.
LangChain proporciona una interfaz accesible para los LLM. Sus características incluyen herramientas para crear plantillas y encadenar mensajes. Estas cadenas se pueden utilizar para resumir documentos de texto que sean más largos de lo que admite el modelo de lenguaje en una sola llamada. Puede utilizar una estrategia de reducción de mapas para resumir documentos extensos dividiéndolos en partes manejables, resumiéndolos y combinándolos (y resumiéndolos nuevamente, si es necesario).
- Instalemos LangChain para comenzar:
- Importe los módulos relevantes y divida el documento largo en partes:
- Para que LangChain funcione eficazmente con Falcon, debe definir las clases de controlador de contenido predeterminadas para entradas y salidas válidas:
- Puede definir mensajes personalizados como
PromptTemplateobjetos, el vehículo principal para solicitar con LangChain, para el enfoque de resumen de reducción de mapas. Este es un paso opcional porque los mensajes de asignación y combinación se proporcionan de forma predeterminada si los parámetros dentro de la llamada para cargar la cadena de resumen (load_summarize_chain) no están definidos.
- LangChain admite LLM alojados en puntos finales de inferencia de SageMaker, por lo que en lugar de utilizar el SDK de AWS Python, puede inicializar la conexión a través de LangChain para una mayor accesibilidad:
- Finalmente, puede cargar una cadena de resumen y ejecutar un resumen de los documentos de entrada usando el siguiente código:
Porque el verbose El parámetro está configurado en True, verá todos los resultados intermedios del enfoque de reducción de mapas. Esto es útil para seguir la secuencia de eventos para llegar a un resumen final. Con este enfoque de reducción de mapas, puede resumir documentos de manera efectiva durante mucho más tiempo de lo que normalmente permite el límite máximo de token de entrada del modelo.
Limpiar
Una vez que haya terminado de usar el punto final de inferencia, es importante eliminarlo para evitar incurrir en costos innecesarios a través de las siguientes líneas de código:
Usar otros modelos de cimentación en SageMaker JumpStart
La utilización de otros modelos básicos disponibles en SageMaker JumpStart para el resumen de documentos requiere una sobrecarga mínima de configuración e implementación. Los LLM ocasionalmente varían según la estructura de los formatos de entrada y salida y, a medida que se agregan nuevos modelos y soluciones prediseñadas a SageMaker JumpStart, según la implementación de la tarea, es posible que deba realizar los siguientes cambios en el código:
- Si está realizando un resumen a través del
summarize()método (el método sin usar LangChain), es posible que tenga que cambiar la estructura JSON delpayloadparámetro, así como el manejo de la variable de respuesta en elquery_endpoint()función - Si está realizando un resumen a través de LangChain’s
load_summarize_chain()método, es posible que tenga que modificar elContentHandlerTextSummarizationclase, específicamente latransform_input()ytransform_output()funciones, para manejar correctamente la carga útil que espera el LLM y la salida que devuelve el LLM
Los modelos básicos varían no solo en factores como la velocidad y la calidad de la inferencia, sino también en los formatos de entrada y salida. Consulte la página de información relevante del LLM sobre los aportes y resultados esperados.
Conclusión
El modelo Falcon 7B Instruct está disponible en el centro de modelos SageMaker JumpStart y funciona en varios casos de uso. Esta publicación demostró cómo puede implementar su propio punto final Falcon LLM en su entorno utilizando SageMaker JumpStart y realizar sus primeros experimentos desde SageMaker Studio, lo que le permitirá crear rápidamente prototipos de sus modelos y realizar una transición sin problemas a un entorno de producción. Con Falcon y LangChain, puede resumir de forma eficaz documentos extensos sobre ciencias biológicas y de atención médica a escala.
Para obtener más información sobre cómo trabajar con IA generativa en AWS, consulte Anuncio de nuevas herramientas para crear con IA generativa en AWS. Puede comenzar a experimentar y crear pruebas de concepto de resúmenes de documentos para sus aplicaciones GenAI orientadas a la atención médica y las ciencias biológicas utilizando el método descrito en esta publicación. Cuando Amazon Bedrock esté disponible de forma generalizada, publicaremos una publicación de seguimiento que mostrará cómo puede implementar el resumen de documentos utilizando Amazon Bedrock y LangChain.
Sobre los autores
 John Kitaoka es arquitecto de soluciones en Amazon Web Services. John ayuda a los clientes a diseñar y optimizar cargas de trabajo de IA/ML en AWS para ayudarlos a alcanzar sus objetivos comerciales.
John Kitaoka es arquitecto de soluciones en Amazon Web Services. John ayuda a los clientes a diseñar y optimizar cargas de trabajo de IA/ML en AWS para ayudarlos a alcanzar sus objetivos comerciales.
 Josh Famestad es arquitecto de soluciones en Amazon Web Services. Josh trabaja con clientes del sector público para crear y ejecutar enfoques basados en la nube para cumplir con las prioridades comerciales.
Josh Famestad es arquitecto de soluciones en Amazon Web Services. Josh trabaja con clientes del sector público para crear y ejecutar enfoques basados en la nube para cumplir con las prioridades comerciales.






{kind=link}