 NEWSLETTER
NEWSLETTER
La publicación está coescrita con Michael Shaul y Sasha Korman de NetApp.
Las aplicaciones de inteligencia artificial (IA) generativa se construyen comúnmente utilizando una técnica llamada Generación Aumentada de Recuperación (RAG, por sus siglas en inglés) que brinda a los modelos de base (FM, por sus siglas en inglés) acceso a datos adicionales que no tenían durante el entrenamiento. Estos datos se utilizan para enriquecer el mensaje de IA generativa para brindar respuestas más precisas y específicas del contexto sin volver a entrenar continuamente al FM, al mismo tiempo que se mejora la transparencia y se minimizan las alucinaciones.
En esta publicación, demostramos una solución que utiliza amazon FSx para NetApp ONTAP con amazon Bedrock para brindar una experiencia RAG para sus aplicaciones de IA generativa en AWS al llevar datos de archivos de usuarios no estructurados y específicos de la empresa a amazon Bedrock de una manera sencilla, rápida y segura.
Nuestra solución utiliza un sistema de archivos FSx para ONTAP como fuente de datos no estructurados y llena continuamente una base de datos vectorial de amazon OpenSearch Serverless con los archivos y carpetas existentes del usuario y los metadatos asociados. Esto permite un escenario RAG con amazon Bedrock al enriquecer el indicador de IA generativa mediante las API de amazon Bedrock con los datos específicos de su empresa recuperados de la base de datos vectorial de OpenSearch Serverless.
Al desarrollar aplicaciones de IA generativa, como un chatbot de preguntas y respuestas que utiliza RAG, los clientes también se preocupan por mantener sus datos seguros y evitar que los usuarios finales consulten información de fuentes de datos no autorizadas. Nuestra solución también utiliza FSx for ONTAP para permitir que los usuarios amplíen sus mecanismos de acceso y seguridad de datos actuales para aumentar las respuestas del modelo de amazon Bedrock. Usamos FSx for ONTAP como fuente de metadatos asociados, específicamente las configuraciones de la lista de control de acceso (ACL) de seguridad del usuario adjuntas a sus archivos y carpetas, y completamos esos metadatos en OpenSearch Serverless. Al combinar las operaciones de control de acceso con eventos de archivos que notifican a la aplicación RAG sobre datos nuevos y modificados en el sistema de archivos, nuestra solución demuestra cómo FSx for ONTAP permite que amazon Bedrock solo use incrustaciones de archivos autorizados para los usuarios específicos que se conectan a nuestra aplicación de IA generativa.
Los servicios sin servidor de AWS facilitan la tarea de centrarse en la creación de aplicaciones de IA generativas al proporcionar escalabilidad automática, alta disponibilidad integrada y un modelo de facturación de pago por uso. El cómputo basado en eventos con AWS Lambda es una buena opción para tareas a pedido que requieren un uso intensivo de los recursos informáticos, como la incorporación de documentos y la orquestación flexible de modelos de lenguaje grandes (LLM), y amazon API Gateway proporciona una interfaz de API que permite interfaces conectables e invocación basada en eventos de los LLM. Nuestra solución también demuestra cómo crear una capa de aplicación sin servidor escalable, automatizada y basada en API sobre amazon Bedrock y FSx para ONTAP utilizando API Gateway y Lambda.
Descripción general de la solución
La solución prevé una amazon-fsx-for-netapp-ontap” target=”_blank” rel=”noopener”>FSx para ONTAP Multi-AZ Sistema de archivos con una máquina virtual de almacenamiento (SVM) unida a un dominio de AWS Managed Microsoft AD. Una colección de búsqueda de vectores sin servidor OpenSearch proporciona una capacidad de búsqueda por similitud escalable y de alto rendimiento. Usamos un servidor Windows amazon Elastic Compute Cloud (amazon EC2) como cliente SMB/CIFS para el volumen FSx for ONTAP y configuramos el uso compartido de datos y las ACL para los recursos compartidos SMB en el volumen. Usamos estos datos y ACL para probar el acceso basado en permisos a las incrustaciones en un escenario RAG con amazon Bedrock.
El componente contenedor de integraciones de nuestra solución se implementa en un servidor EC2 Linux y se monta como un cliente NFS en el volumen FSx for ONTAP. Migra periódicamente los archivos y carpetas existentes junto con sus configuraciones de ACL de seguridad a OpenSearch Serverless. Rellena un índice en la colección de búsqueda vectorial de OpenSearch Serverless con datos específicos de la empresa (y metadatos y ACL asociados) desde el recurso compartido NFS en el sistema de archivos FSx for ONTAP.
La solución implementa una función Lambda de recuperación de RAG que permite la integración de RAG con amazon Bedrock al enriquecer el mensaje de IA generativa mediante las API de amazon Bedrock con los datos específicos de su empresa y los metadatos asociados (incluidas las listas de control de acceso) recuperados del índice de OpenSearch Serverless que se completó con el componente contenedor de incrustaciones. La función Lambda de recuperación de RAG almacena el historial de conversaciones de la interacción del usuario en una tabla de amazon DynamoDB.
Los usuarios finales interactúan con la solución enviando un mensaje en lenguaje natural, ya sea a través de una aplicación de chatbot o directamente a través de la interfaz API Gateway. El contenedor de la aplicación de chatbot se crea utilizando Agilizart y está liderado por un balanceador de carga de aplicaciones (ALB) de AWS. Cuando un usuario envía un mensaje de lenguaje natural a la interfaz de usuario del chatbot mediante el ALB, el contenedor del chatbot interactúa con la interfaz de API Gateway que luego invoca la función Lambda de recuperación de RAG para obtener la respuesta para el usuario. El usuario también puede enviar solicitudes de mensajes directamente a API Gateway y obtener una respuesta. Demostramos el acceso basado en permisos a los documentos RAG recuperando explícitamente el SID de un usuario y luego usando ese SID en la solicitud del chatbot o API Gateway, donde la función Lambda de recuperación de RAG luego hace coincidir el SID con las ACL de Windows configuradas para el documento. Como paso de autenticación adicional en un entorno de producción, es posible que también desee autenticar al usuario con un proveedor de identidad y luego hacer coincidir al usuario con los permisos configurados para los documentos.
El siguiente diagrama ilustra el flujo de extremo a extremo de nuestra solución. Comenzamos configurando el uso compartido de datos y las listas de control de acceso con FSx para ONTAP, y luego el contenedor de incrustaciones los escanea periódicamente. El contenedor de incrustaciones divide los documentos en fragmentos y utiliza el modelo amazon Titan Embeddings para crear incrustaciones vectoriales a partir de estos fragmentos. Luego, almacena estas incrustaciones vectoriales con metadatos asociados en nuestra base de datos vectorial al completar un índice en una colección vectorial en OpenSearch Serverless. El siguiente diagrama ilustra el flujo de extremo a extremo.
El siguiente diagrama de arquitectura ilustra los distintos componentes de nuestra solución.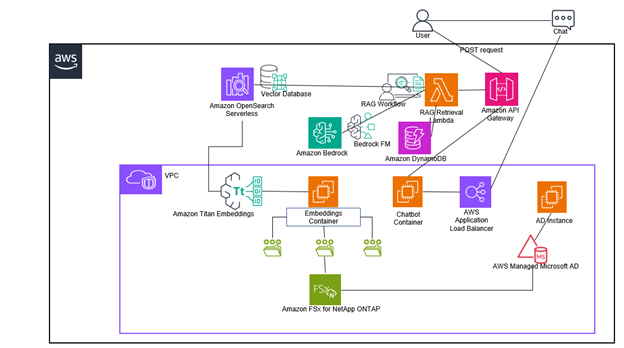
Prerrequisitos
Complete los siguientes pasos previos:
- Asegúrese de tener acceso al modelo en amazon Bedrock. En esta solución, usamos Soneto Claude Antrópico v3 en amazon Bedrock.
- Instalar la interfaz de línea de comandos de AWS (AWS CLI).
- Instalar Docker.
- Instalar Terraform.
Implementar la solución
La solución está disponible para descargar en este Repositorio de GitHubAl clonar el repositorio y usar la plantilla Terraform se proporcionarán todos los componentes con las configuraciones necesarias.
- Clonar el repositorio para esta solución:
- Desde la carpeta Terraform, implemente la solución completa usando Terraform:
Este proceso puede tardar entre 15 y 20 minutos en completarse. Una vez finalizado, el resultado de los comandos de Terraform debería ser similar al siguiente:
Cargar datos y establecer permisos
Para probar la solución, utilizaremos el servidor EC2 de Windows (ad_host) montado como un cliente SMB/CIFS en el volumen FSx for ONTAP para compartir datos de muestra y establecer permisos de usuario que luego se utilizarán para completar el índice de OpenSearch Serverless mediante el componente de contenedor de incrustación de la solución. Realice los siguientes pasos para montar su volumen de datos SVM FSx for ONTAP como una unidad de red, cargar datos en esta unidad de red compartida y establecer permisos según las listas de control de acceso de Windows:
- Obtener el
ad_hostinstancia DNS de la salida de su plantilla Terraform. - Navegue hasta AWS Systems Manager Fleet Manager en su consola de AWS, localice el
ad_hostInstancia y siga las instrucciones aquí para iniciar sesión con Escritorio remoto. Utilice el usuario administrador del dominiobedrock-01\Adminy obtenga la contraseña de AWS Secrets Manager. Puede encontrar la contraseña mediante Secrets Managerfsx-secret-ididentificación secreta de la salida de su plantilla Terraform. - Para montar un volumen de datos de FSx para ONTAP como una unidad de red, en Esta PCseleccione (clic derecho) Red y luego elige Mapa de la unidad de red.
- Elija la letra de la unidad y utilice la ruta compartida de FSx para ONTAP para el montaje
(\\.\c$\):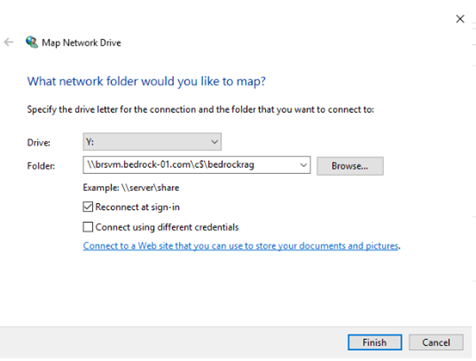
- Cargue la Guía del usuario de amazon Bedrock en la unidad de red compartida y configure los permisos solo para el usuario administrador (asegúrese de deshabilitar la herencia en Avanzado):<img loading="lazy" class="size-full wp-image-86334 alignnone" style="margin: 10px 0px 10px 0px;border: 1px solid #CCCCCC" src="https://technicalterrence.com/wp-content/uploads/2024/09/1726596520_240_Cree-aplicaciones-de-inteligencia-artificial-generativa-basadas-en-RAG-en.png" alt="Cargue la guía del usuario de amazon Bedrock” width=”553″ height=”528″/>
- Cargue la Guía del usuario de amazon FSx para ONTAP en la unidad compartida y asegúrese de que los permisos estén configurados en Todos:<img loading="lazy" class="size-full wp-image-86335 alignnone" style="margin: 10px 0px 10px 0px;border: 1px solid #CCCCCC" src="https://technicalterrence.com/wp-content/uploads/2024/09/1726596521_589_Cree-aplicaciones-de-inteligencia-artificial-generativa-basadas-en-RAG-en.png" alt="Cargue la guía multimedia de amazon FSX OnTap” width=”624″ height=”584″/>
- En el
ad_hostservidor, abra el símbolo del sistema e ingrese el siguiente comando para obtener el SID del usuario administrador:
Pruebe los permisos usando el chatbot
Para probar los permisos usando el chatbot, obtenga la lb-dns-name URL de la salida de su plantilla Terraform y acceda a ella a través de su navegador web:
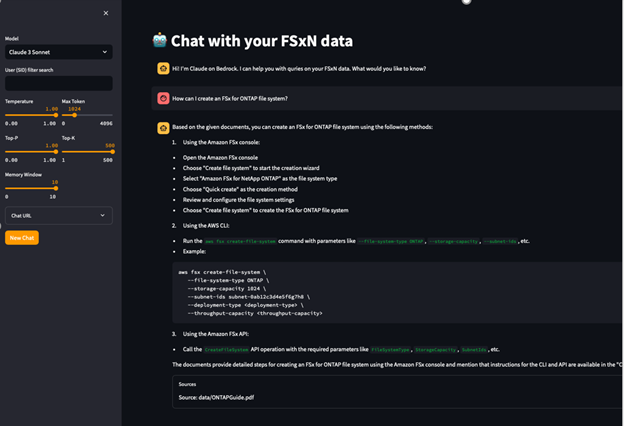
Para la consulta rápida, haga cualquier pregunta general en la guía del usuario de FSx for ONTAP a la que todos pueden acceder. En nuestro escenario, preguntamos “¿Cómo puedo crear un sistema de archivos de FSx for ONTAP?” y el modelo respondió con pasos detallados y atribución de la fuente en la ventana de chat para crear un sistema de archivos de FSx for ONTAP mediante la consola de administración de AWS, la CLI de AWS o la API de FSx:
Ahora, hagamos una pregunta sobre la guía del usuario de amazon Bedrock que está disponible solo para acceso de administrador. En nuestro escenario, preguntamos “¿Cómo uso los modelos básicos con amazon Bedrock?” y el modelo respondió que no tiene suficiente información para brindar una respuesta detallada a la pregunta:
Utilice el SID de administrador en la búsqueda de filtros de usuario (SID) en la interfaz de usuario del chat y haga la misma pregunta en el mensaje. Esta vez, el modelo debe responder con los pasos que detallan cómo usar los FM con amazon Bedrock y proporcionar la atribución de la fuente utilizada por el modelo para la respuesta:
Permisos de prueba mediante API Gateway
También puede consultar el modelo directamente mediante API Gateway. Obtenga el api-invoke-url parámetro de la salida de su plantilla Terraform.
A continuación, invoque la puerta de enlace API con Todos acceso a una consulta relacionada con la guía del usuario de FSx para ONTAP configurando el valor del parámetro de metadatos en NA para indicar Todos acceso:
Limpieza
Para evitar cargos recurrentes, limpie su cuenta después de probar la solución. Desde la carpeta Terraform, elimine la plantilla Terraform para la solución:
Conclusión
En esta publicación, demostramos una solución que utiliza FSx for ONTAP con amazon Bedrock y utiliza el soporte de FSx for ONTAP para la propiedad de archivos y las listas de control de acceso (ACL) para proporcionar acceso basado en permisos en un escenario de RAG para aplicaciones de IA generativa. Nuestra solución le permite crear aplicaciones de IA generativa con amazon Bedrock, donde puede enriquecer el mensaje de IA generativa en amazon Bedrock con los datos de archivos de usuario no estructurados y específicos de su empresa desde un sistema de archivos de FSx for ONTAP. Esta solución le permite brindar respuestas más relevantes, específicas del contexto y precisas, al mismo tiempo que garantiza que solo los usuarios autorizados tengan acceso a esos datos. Por último, la solución demuestra el uso de los servicios sin servidor de AWS con FSx for ONTAP y amazon Bedrock que permiten el escalado automático, el procesamiento basado en eventos y las interfaces API para sus aplicaciones de IA generativa en AWS.
Para obtener más información sobre cómo comenzar a compilar con amazon Bedrock y FSx para ONTAP, consulte los siguientes recursos:
Acerca de los autores
 Kanishk Mahajan Kanishk es director de arquitectura de soluciones en AWS. Lidera la transformación de la nube y la arquitectura de soluciones para clientes y socios ISV en AWS. Kanishk se especializa en contenedores, operaciones en la nube, migraciones y modernizaciones, IA/ML, resiliencia, seguridad y cumplimiento normativo. Es miembro de la Comunidad de campo técnico (TFC) en cada uno de esos dominios en AWS.
Kanishk Mahajan Kanishk es director de arquitectura de soluciones en AWS. Lidera la transformación de la nube y la arquitectura de soluciones para clientes y socios ISV en AWS. Kanishk se especializa en contenedores, operaciones en la nube, migraciones y modernizaciones, IA/ML, resiliencia, seguridad y cumplimiento normativo. Es miembro de la Comunidad de campo técnico (TFC) en cada uno de esos dominios en AWS.
 Michael Shaul es arquitecto principal en la oficina del director de tecnología de NetApp. Tiene más de 20 años de experiencia en la creación de sistemas de gestión de datos, aplicaciones y soluciones de infraestructura. Tiene una perspectiva única y profunda sobre las tecnologías de la nube, los desarrolladores y las soluciones de inteligencia artificial.
Michael Shaul es arquitecto principal en la oficina del director de tecnología de NetApp. Tiene más de 20 años de experiencia en la creación de sistemas de gestión de datos, aplicaciones y soluciones de infraestructura. Tiene una perspectiva única y profunda sobre las tecnologías de la nube, los desarrolladores y las soluciones de inteligencia artificial.
 Sasha Korman es un visionario tecnológico que lidera equipos dinámicos de desarrollo y control de calidad en Israel y la India. Con 14 años de experiencia en NetApp, comenzando como programador, su experiencia práctica y liderazgo han sido fundamentales para dirigir proyectos complejos hacia el éxito, con un enfoque en la innovación, la escalabilidad y la confiabilidad.
Sasha Korman es un visionario tecnológico que lidera equipos dinámicos de desarrollo y control de calidad en Israel y la India. Con 14 años de experiencia en NetApp, comenzando como programador, su experiencia práctica y liderazgo han sido fundamentales para dirigir proyectos complejos hacia el éxito, con un enfoque en la innovación, la escalabilidad y la confiabilidad.





{kind=link}