 NEWSLETTER
NEWSLETTER
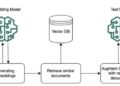
Currently, three tendency issues in ai implementation are LLMS, RAG and databases. These allow us to create adequate and specific systems for our use. This system driven by ai, which combines a vector database and responses generated by ai, has applications in several industries. In customer service, chatbots of ai recover the responses of the knowledge base dynamically. The legal and financial sectors benefit from the summary of documents and the investigation of cases promoted by ai. Health ai attendees help doctors with medical research and drug interactions. Electronic learning platforms provide personalized corporate training. Journalism uses ai for the summary of news and verification of facts. The software development takes advantage of ai for coding and purification assistance. Scientific research benefits from literature reviews promoted by ai. This approach improves knowledge recovery, automates content creation and customizes user interactions in multiple domains.
In this tutorial, we will create an English tutor with ai using a rag. The system integrates a vector database (Chromadb) to store and recover relevant English language materials and text generation with ai (API GROQ) to create structured and attractive lessons. The workflow includes extracting PDFS text, store knowledge in a vector database, recover relevant content and generate detailed lessons from ai. The objective is to build an interactive English tutor that dynamically generates lessons based on topics while taking advantage of knowledge previously stored for greater precision and contextual relevance.
Step 1: Installation of the necessary libraries
!pip install PyPDF2
!pip install groq
!pip install chromadb
!pip install sentence-transformers
!pip install nltk
!pip install fpdf
!pip install torchPyPDF2 extracts PDF file text, which makes it useful to handle information based on documents. Groq is a library that provides access to Groq ai ai, which allows advanced text generation capabilities. Chromadb is a vector database designed to recover the text efficiently. Prayer transformers generate text inlays, which helps store and recover information significantly. NLTK. FPDF is a light library to create and manipulate PDF documents, allowing the lessons generated to be stored in a structured format. Torch is a deep learning frame that is commonly used for automatic learning tasks, including the generation of IA -based text.
Step 2: NLP tokenization data download
import nltk
nltk.download('punkt_tab')The data set punkt_tab is downloaded using the previous code. nltk.download ('Punkt_tab') obtains a set of data required for prayer token. Tokenization is to divide the text into prayers or words, which is crucial to decompose large text bodies into manageable segments for processing and recovery.
Step 3: NLTK data directory configuration
working_directory = os.getcwd()
nltk_data_dir = os.path.join(working_directory, 'nltk_data')
nltk.data.path.append(nltk_data_dir)
nltk.download('punkt_tab', download_dir=nltk_data_dir)We will configure a dedicated directory for NLTK data. The OS.GETCWD () function recovers the current work directory, and a new NLTK_Data directory within it is created to store resources related to NLP. The NLTK.Data.path.append (nltk_data_dir) command guarantees that this directory stores the NLTK data sets. The Punkt_Tab data set, required for sentence token, is downloaded and stored in the specified directory.
Step 4: Import required libraries
import os
import torch
from sentence_transformers import SentenceTransformer
import chromadb
from chromadb.utils import embedding_functions
import numpy as np
import PyPDF2
from fpdf import FPDF
from functools import lru_cache
from groq import Groq
import nltk
from nltk.tokenize import sent_tokenize
import uuid
from dotenv import load_dotenvHere, we import all the necessary libraries used throughout the notebook. The operating system is used for file system operations. Torch is imported to handle tasks related to deep learning. Sentence-Transformers provides an easy way to generate inlays from the text. Chromadb and its Ingreding_Functions module help store and recover the relevant text. Numpy is a mathematical library used to handle matrices and numerical calculations. PYPDF2 is used to extract PDFS text. FPDF allows the generation of PDF documents. Lru_cache is used to storing in cache the outputs of the function for optimization. Groq is an ai service that generates human responses. NLTK provides NLP functionalities, and Sent_Tokenize is specifically imported to divide the text into sentences. Uuid generates unique IDs, and Load_Dotenv loads the environment variables from a .env file.
Step 5: Cargo and API key variables
load_dotenv()
api_key = os.getenv('api_key')
os.environ("GROQ_API_KEY") = api_key
#or manually retrieve key from https://console.groq.com/ and add it hereThrough the previous code, we will load environment variables from an .env file. The Load_Dotenv () function reads environment variables .env and makes them available to the Python environment. The API_Key is recovered using OS.Getenv ('Api_Key'), ensuring the management of safe API keys without coding it in the script. The key is stored in OS.environ (“Groq_api_Key”), which makes it accessible for later calls.
Step 6: Definition of the Database Class Vector
class VectorDatabase:
def __init__(self, collection_name="english_teacher_collection"):
self.client = chromadb.PersistentClient(path="./chroma_db")
self.encoder = SentenceTransformer('all-MiniLM-L6-v2')
self.embedding_function = embedding_functions.SentenceTransformerEmbeddingFunction(model_name="all-MiniLM-L6-v2")
self.collection = self.client.get_or_create_collection(name=collection_name, embedding_function=self.embedding_function)
def add_text(self, text, chunk_size):
sentences = sent_tokenize(text, language="english")
chunks = self._create_chunks(sentences, chunk_size)
ids = (str(uuid.uuid4()) for _ in chunks)
self.collection.add(documents=chunks, ids=ids)
def _create_chunks(self, sentences, chunk_size):
chunks = ()
for i in range(0, len(sentences), chunk_size):
chunk = ' '.join(sentences(i:i+chunk_size))
chunks.append(chunk)
return chunks
def retrieve(self, query, k=3):
results = self.collection.query(query_texts=(query), n_results=k)
return results('documents')(0)This class defines a vectordatabase that interacts with Chromadb to store and recover text -based knowledge. The __init __ () function initializes the database, creating a Chroma_DB persistent directory for long -term storage. The sentencetransformer model (All-Milm-L6-V2) generates text inlays, which convert textual information into numerical representations that can be stored and searched efficiently. The ADD_TEXT () function divides the entry text into sentences and divides them into smaller pieces before storing them in the vector database. The _create_chunks () function ensures that the text is correctly segmented, making the recovery more effective. The remote () function takes a consultation and returns the most relevant stored documents depending on the similarity.
Step 7: Implementation of the generation of ai lessons with Groq
class GroqGenerator:
def __init__(self, model_name="mixtral-8x7b-32768"):
self.model_name = model_name
self.client = Groq()
def generate_lesson(self, topic, retrieved_content):
prompt = f"Create an engaging English lesson about {topic}. Use the following information:n"
prompt += "nn".join(retrieved_content)
prompt += "nnLesson:"
chat_completion = self.client.chat.completions.create(
model=self.model_name,
messages=(
{"role": "system", "content": "You are an ai English teacher designed to create an elaborative and engaging lesson."},
{"role": "user", "content": prompt}
),
max_tokens=1000,
temperature=0.7
)
return chat_completion.choices(0).message.contentThis class, Groqgenerator, is responsible for generating English lessons with ai. Interact with the Groq ai model through an API call. The __init __ () function initializes the generator using the Mixthral-8x7B-32768 model, designed for conversational. The Generate_Lless () function takes a topic and recovered knowledge as an entrance, formats a message and sends it to the API Groq for the generation of lessons. The ai system returns a structured lesson with explanations and examples, which can then be stored or displayed.
Step 8: Combine vector recovery and the generation of ai
class RAGEnglishTeacher:
def __init__(self, vector_db, generator):
self.vector_db = vector_db
self.generator = generator
@lru_cache(maxsize=32)
def teach(self, topic):
relevant_content = self.vector_db.retrieve(topic)
lesson = self.generator.generate_lesson(topic, relevant_content)
return lessonThe previous class, Ragengishteacher, integrates the components Vectordadatabase and Groqgenerator to create a recovery generation (RAG) system (RAG). The Teach () function recovers relevant content of the vector database and passes it to the Groqgenerator to produce a structured lesson. The decorator lru_cache (maxsize = 32) stores in cache up to 32 lessons generated previously to improve efficiency by avoiding repeated calculations.
In conclusion, we successfully created a tutor in English with ai that combines a vector database (Chromadb) and the Groq ai model to implement the generation of aquatic recovery (RAG). The system can extract PDFS text, store relevant knowledge in a structured way, recover contextual information and generate dynamically detailed lessons. This tutor provides attractive lessons, conscious of context and personalized by using sentence integrities for efficient recovery and responses generated by ai for structured learning. This approach guarantees that students receive precise, informative and well -organized English lessons without requiring manual content creation. The system can be extended even more integrating additional learning modules, improving the efficiency of the database or the responses of the adjusted so that the tutoring process is more interactive and intelligent.
Use the Colab notebook here. Besides, don't forget to follow us <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter and join our Telegram channel and LINKEDIN GRsplash. Do not forget to join our 70k+ ml of submen.
Know Intellagent: A framework of multiple open source agents to evaluate a complex conversational system (Promoted)
Sana Hassan, a consulting intern in Marktechpost and double grade student in Iit Madras, passionate to apply technology and ai to address real world challenges. With great interest in solving practical problems, it provides a new perspective to the intersection of ai and real -life solutions.




{kind=link}