 NEWSLETTER
NEWSLETTER
Author's image | Canva
In this tutorial, we will learn about Prefect, a modern workflow orchestration tool. We will start by creating a data pipeline with Pandas and then compare it with a Prefect workflow to better understand. In the end, we will deploy our workflow and view the execution logs in the dashboard.
What is Prefect?
Prefect is a workflow management system designed to orchestrate and manage complex data workflows, including machine learning (ML) pipelines. It provides a framework for creating, scheduling, and monitoring workflows, making it an essential tool for managing ML operations (MLOps).
Prefect offers task and flow management, allowing users to define dependencies and execute workflows efficiently. With features like state management and observability, Prefect provides insights into the status and history of tasks, making debugging and optimization easier. It comes with a highly interactive dashboard that allows you to schedule, monitor, and integrate several other features that will enhance your workflow for the MLOps pipeline. You can even set up notifications and integrate other ML frameworks with a few clicks.
Prefect is available as an open source framework and a managed cloud service, further simplifying your workflow.
Creating a data pipeline with Pandas
We will replicate the data pipeline I used in the previous tutorials (Building Data Science Pipelines Using Pandas—KDnuggets) to give you an idea of how each task in the pipeline works and how to combine them. I mention it here so that you can clearly compare how perfect data pipelines differ from normal pipelines.
import pandas as pd
def load_data(path):
return pd.read_csv(path)
def data_cleaning(data):
data = data.drop_duplicates()
data = data.dropna()
data = data.reset_index(drop=True)
return data
def convert_dtypes(data, types_dict=None):
data = data.astype(dtype=types_dict)
## convert the date column to datetime
data("Date") = pd.to_datetime(data("Date"))
return data
def data_analysis(data):
data("month") = data("Date").dt.month
new_df = data.groupby("month")("Units Sold").mean()
return new_df
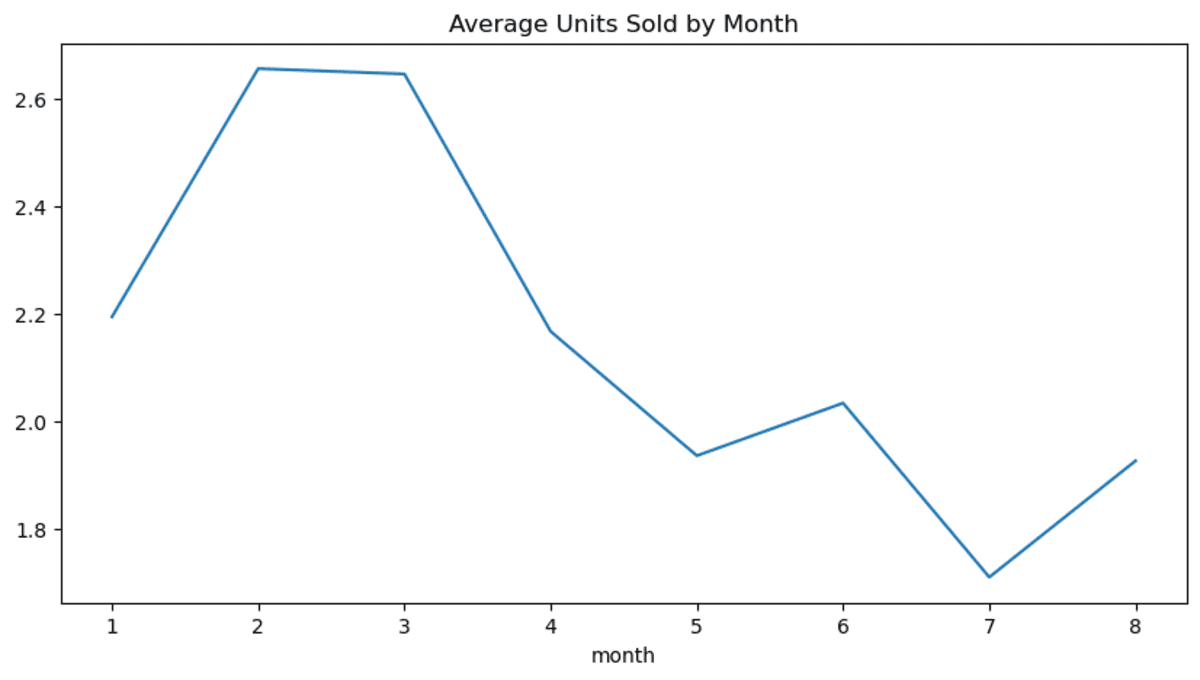
def data_visualization(new_df, vis_type="bar"):
new_df.plot(kind=vis_type, figsize=(10, 5), title="Average Units Sold by Month")
return new_df
path = "Online Sales Data.csv"
df = (
pd.DataFrame()
.pipe(lambda x: load_data(path))
.pipe(data_cleaning)
.pipe(convert_dtypes, {"Product Category": "str", "Product Name": "str"})
.pipe(data_analysis)
.pipe(data_visualization, "line")
)When we run the above code, each task will run sequentially and generate the data visualization. Apart from that, it does nothing else. We can schedule it, view the execution logs, or even integrate third-party tools for notifications or monitoring.
Creating a data channel with Prefect
Now we will build the same pipeline with the same dataset. Online Sales Dataset: Popular Markets Data But with Prefect, we will first install the Prefect library using the PIP command.
If you look at the code below, you'll notice that nothing has really changed. The functions are the same, but with the addition of Python decorators. Each step in the sequence has the `@task` decorator, and the sequence that combines these steps has the `@flow` decorator. In addition, we are also saving the generated figure.
import pandas as pd
import matplotlib.pyplot as plt
from prefect import task, flow
@task
def load_data(path):
return pd.read_csv(path)
@task
def data_cleaning(data):
data = data.drop_duplicates()
data = data.dropna()
data = data.reset_index(drop=True)
return data
@task
def convert_dtypes(data, types_dict=None):
data = data.astype(dtype=types_dict)
data("Date") = pd.to_datetime(data("Date"))
return data
@task
def data_analysis(data):
data("month") = data("Date").dt.month
new_df = data.groupby("month")("Units Sold").mean()
return new_df
@task
def data_visualization(new_df, vis_type="bar"):
new_df.plot(kind=vis_type, figsize=(10, 5), title="Average Units Sold by Month")
plt.savefig("average_units_sold_by_month.png")
return new_df
@flow(name="Data Pipeline")
def data_pipeline(path: str):
df = load_data(path)
df_cleaned = data_cleaning(df)
df_converted = convert_dtypes(
df_cleaned, {"Product Category": "str", "Product Name": "str"}
)
analysis_result = data_analysis(df_converted)
new_df = data_visualization(analysis_result, "line")
return new_df
# Run the flow!
if __name__ == "__main__":
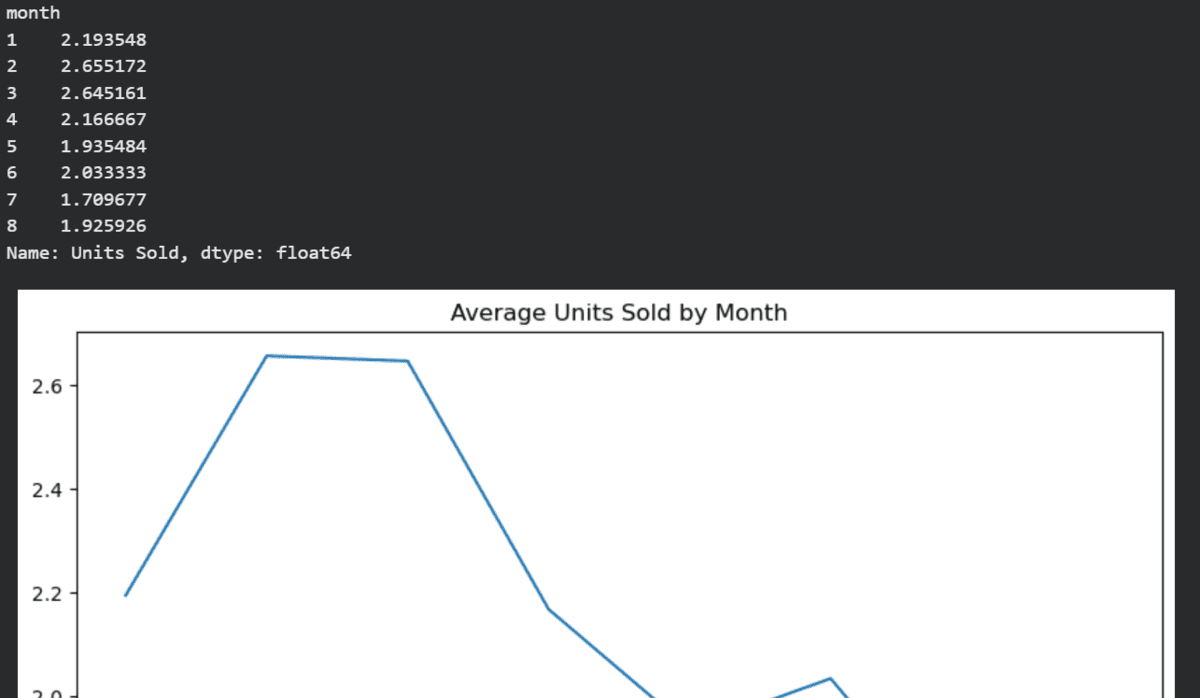
new_df = data_pipeline("Online Sales Data.csv")
print(new_df)We will execute our data sequence by providing the location of the CSV file. It will perform all the steps in sequence and generate logs with the execution statuses.
14:18:48.649 | INFO | prefect.engine - Created flow run 'enlightened-dingo' for flow 'Data Pipeline'
14:18:48.816 | INFO | Flow run 'enlightened-dingo' - Created task run 'load_data-0' for task 'load_data'
14:18:48.822 | INFO | Flow run 'enlightened-dingo' - Executing 'load_data-0' immediately...
14:18:48.990 | INFO | Task run 'load_data-0' - Finished in state Completed()
14:18:49.052 | INFO | Flow run 'enlightened-dingo' - Created task run 'data_cleaning-0' for task 'data_cleaning'
14:18:49.053 | INFO | Flow run 'enlightened-dingo' - Executing 'data_cleaning-0' immediately...
14:18:49.226 | INFO | Task run 'data_cleaning-0' - Finished in state Completed()
14:18:49.283 | INFO | Flow run 'enlightened-dingo' - Created task run 'convert_dtypes-0' for task 'convert_dtypes'
14:18:49.288 | INFO | Flow run 'enlightened-dingo' - Executing 'convert_dtypes-0' immediately...
14:18:49.441 | INFO | Task run 'convert_dtypes-0' - Finished in state Completed()
14:18:49.506 | INFO | Flow run 'enlightened-dingo' - Created task run 'data_analysis-0' for task 'data_analysis'
14:18:49.510 | INFO | Flow run 'enlightened-dingo' - Executing 'data_analysis-0' immediately...
14:18:49.684 | INFO | Task run 'data_analysis-0' - Finished in state Completed()
14:18:49.753 | INFO | Flow run 'enlightened-dingo' - Created task run 'data_visualization-0' for task 'data_visualization'
14:18:49.760 | INFO | Flow run 'enlightened-dingo' - Executing 'data_visualization-0' immediately...
14:18:50.087 | INFO | Task run 'data_visualization-0' - Finished in state Completed()
14:18:50.144 | INFO | Flow run 'enlightened-dingo' - Finished in state Completed()In the end, you will get the transformed data frame and visualizations.
Implementing the Prefect pipeline
To implement the Prefect pipeline, we need to start by moving our codebase into the Python file `data_pipe.py`. After that, we will modify the way we run our pipeline. We will use the `.server` function to implement the pipeline and pass the CSV file as an argument to the function.
data_pipe.py:
import pandas as pd
import matplotlib.pyplot as plt
from prefect import task, flow
@task
def load_data(path: str) -> pd.DataFrame:
return pd.read_csv(path)
@task
def data_cleaning(data: pd.DataFrame) -> pd.DataFrame:
data = data.drop_duplicates()
data = data.dropna()
data = data.reset_index(drop=True)
return data
@task
def convert_dtypes(data: pd.DataFrame, types_dict: dict = None) -> pd.DataFrame:
data = data.astype(dtype=types_dict)
data("Date") = pd.to_datetime(data("Date"))
return data
@task
def data_analysis(data: pd.DataFrame) -> pd.DataFrame:
data("month") = data("Date").dt.month
new_df = data.groupby("month")("Units Sold").mean()
return new_df
@task
def data_visualization(new_df: pd.DataFrame, vis_type: str = "bar") -> pd.DataFrame:
new_df.plot(kind=vis_type, figsize=(10, 5), title="Average Units Sold by Month")
plt.savefig("average_units_sold_by_month.png")
return new_df
@task
def save_to_csv(df: pd.DataFrame, filename: str):
df.to_csv(filename, index=False)
return filename
@flow(name="Data Pipeline")
def run_pipeline(path: str):
df = load_data(path)
df_cleaned = data_cleaning(df)
df_converted = convert_dtypes(
df_cleaned, {"Product Category": "str", "Product Name": "str"}
)
analysis_result = data_analysis(df_converted)
data_visualization(analysis_result, "line")
save_to_csv(analysis_result, "average_units_sold_by_month.csv")
# Run the flow
if __name__ == "__main__":
run_pipeline.serve(
name="pass-params-deployment",
parameters=dict(path="Online Sales Data.csv"),
)When we run the Python file, we will receive the message saying that to run the implemented pipeline, we must use the following command:

Open a new Terminal window and type the command to trigger the execution of this flow.
$ prefect deployment run 'Data Pipeline/pass-params-deployment'As we can see, the flow executions have started, which means the pipeline is running in the background. We can always go back to the first terminal window to view the logs.

To view the logs in the dashboard, we need to start the Prefect dashboard by typing the following command:
Click the dashboard link to launch it in your web browser.
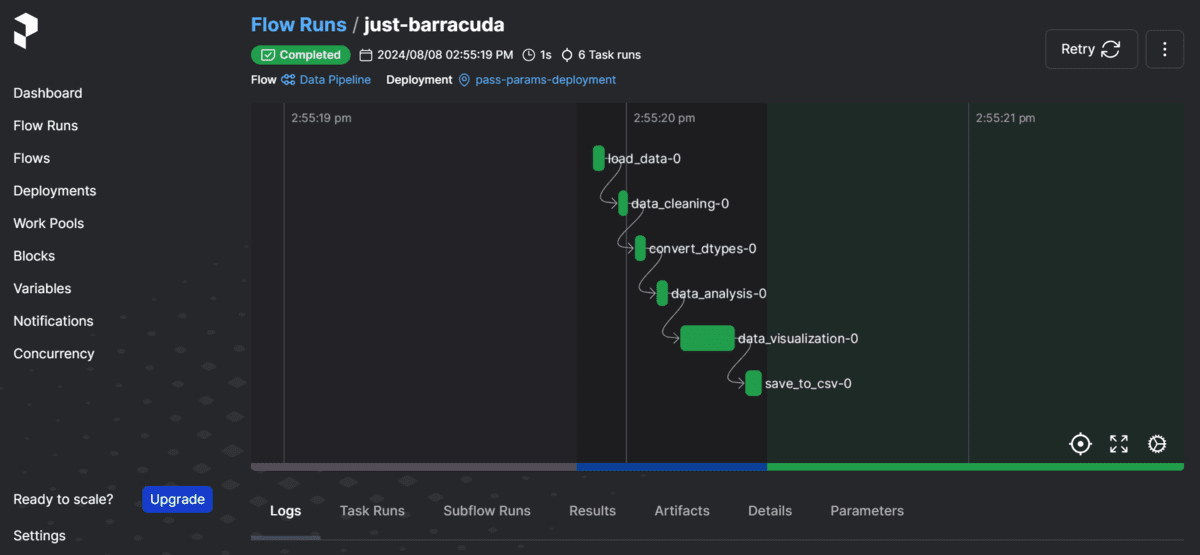
The dashboard consists of several tabs and information related to your workflow, workflows, and runs. To view the current run, navigate to the “Flow Runs” tab and select the most recent flow run.
All source code, data and information are available at Kingabzpro/data pipeline with Prefect GitHub repository. Don't forget to star it.
Conclusion
To scale your data workflow and avoid unnecessary setbacks, you need to build a pipeline with the right tools. With Prefect, you can schedule your runs, debug the pipeline, and integrate it with multiple third-party tools you’re already using. It’s easy to use and comes with tons of features you’ll love. If you’re new to Prefect, I highly recommend checking out Prefect Cloud. They offer free hours for users to experience the cloud platform and get familiar with the workflow management system.
Abid Ali Awan (@1abidaliawan) is a certified data scientist who loves building machine learning models. Currently, he focuses on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in technology Management and a Bachelor's degree in Telecommunication Engineering. His vision is to create an ai product using a graph neural network for students struggling with mental illness.






{kind=link}