 NEWSLETTER
NEWSLETTER
Sentence transformers are powerful deep learning models that convert sentences into high-quality, fixed-length embeddings, capturing their semantic meaning. These embeddings are useful for various natural language processing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval.
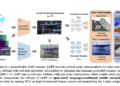
In this post, we show how to tune a sentence transformer specifically to classify an amazon product into its product category (such as toys or sporting goods). We show two different sentence transformers, paraphrase-MiniLM-L6-v2 and an amazon proprietary large language model (LLM) called M5_ASIN_SMALL_V2.0and compare their results. M5 LLMS are BERT-based LLMs tailored to amazon's internal product catalog data using product title, bullets, description, and more. They are currently used for use cases such as automated product ranking and similar product recommendations. Our hypothesis is that M5_ASIN_SMALL_V2.0 will work best for amazon's product category classification use case because it's fine-tuned with amazon's product data. We test this hypothesis in the following experiment illustrated in this post.
Solution Overview
In this post, we demonstrate how to tune a sentence transformer with amazon product data and how to use the resulting sentence transformer to improve the classification accuracy of product categories using an XGBoost decision tree. For this demo, we use a public dataset of amazon products called amazon-product-dataset-2020?resource=download” target=”_blank” rel=”noopener”>amazon Product Dataset 2020 of a kaggle competition. This data set contains the following attributes and fields:
- Domain name – amazon.com
- Date range – January 1, 2020, until January 31, 2020
- File extension –CSV
- Available fields – Uniq ID, Product Name, Brand Name, ASIN, Category, UPC Ean Code, List Price, Selling Price, Quantity, Model Number, About Product, Product Specification, Technical Details, Shipping Weight, product dimensions, image, variants, SKU, product URL, stock, product details, dimensions, color, ingredients, direction of use, amazon seller, size, quantity, variant and product description
- Label field – Category
Prerequisites
Before you begin, install the following packages. You can do this on an amazon SageMaker laptop or on your local Jupyter laptop by running the following commands:
!pip install sentencepiece --quiet
!pip install sentence_transformers --quiet
!pip install xgboost –-quiet
!pip install scikit-learn –-quiet/
Preprocess the data
The first step required to tune a sentence transformer is to preprocess the amazon product data so that the sentence transformer can consume the data and fit it effectively. It involves normalizing the text data, defining the main product category by extracting the first category from the Category field, and selecting the most important fields in the data set that contribute to accurately classifying the main product category. We use the following code for preprocessing:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
data = pd.read_csv('marketing_sample_for_amazon_com-ecommerce__20200101_20200131__10k_data.csv')
data.columns = data.columns.str.lower().str.replace(' ', '_')
data('main_category') = data('category').str.split("|").str(0)
data("all_text") = data.apply(
lambda r: " ".join(
(
str(r("product_name")) if pd.notnull(r("product_name")) else "",
str(r("about_product")) if pd.notnull(r("about_product")) else "",
str(r("product_specification")) if pd.notnull(r("product_specification")) else "",
str(r("technical_details")) if pd.notnull(r("technical_details")) else ""
)
),
axis=1
)
label_encoder = LabelEncoder()
labels_transform = label_encoder.fit_transform(data('main_category'))
data('label')=labels_transform
data(('all_text','label'))
The following screenshot shows an example of what our data set looks like after it has been preprocessed.

Fine-tune Sentence Transformer Paraphrase-MiniLM-L6-v2
The first sentence transformer we tuned is called paraphrase-MiniLM-L6-v2. Use the popular BERT model as its underlying architecture to transform the product description text into a dense 384-dimensional vector embedding that will be consumed by our XGBoost classifier for product category classification. We use the following code to wrap paraphrase-MiniLM-L6-v2 using the preprocessed amazon product data:
from sentence_transformers import SentenceTransformer
model_name="paraphrase-MiniLM-L6-v2"
model = SentenceTransformer(model_name)
The first step is to define a classification header that represents the 24 product categories that an amazon product can be classified into. This classification header will be used to train the sentence transformer specifically to be more effective in transforming product descriptions according to the 24 product categories. The idea is that all product descriptions that are within the same category should be transformed into a vector embedding that is closer compared to product descriptions that belong to different categories.
The following code is to adjust the sentence transformer 1:
import torch.nn as nn
# Define classification head
class ClassificationHead(nn.Module):
def __init__(self, embedding_dim, num_classes):
super(ClassificationHead, self).__init__()
self.linear = nn.Linear(embedding_dim, num_classes)
def forward(self, features):
x = features('sentence_embedding')
x = self.linear(x)
return x
# Define the number of classes for a classification task.
num_classes = 24
print('class number:', num_classes)
classification_head = ClassificationHead(model.get_sentence_embedding_dimension(), num_classes)
# Combine SentenceTransformer model and classification head."
class SentenceTransformerWithHead(nn.Module):
def __init__(self, transformer, head):
super(SentenceTransformerWithHead, self).__init__()
self.transformer = transformer
self.head = head
def forward(self, input):
features = self.transformer(input)
logits = self.head(features)
return logits
model_with_head = SentenceTransformerWithHead(model, classification_head)
Then we configure the fine-tuning parameters. For this post, we train in five epochs, optimize for cross entropy lossand use the AdamW Optimization method. We chose epoch 5 because, after testing various epoch values, we observed that the loss was minimized at epoch 5. This made it the optimal number of training iterations to achieve the best classification results.
The following code is to adjust sentence transformer 2:
import os
os.environ("TORCH_USE_CUDA_DSA") = "1"
os.environ("CUDA_LAUNCH_BLOCKING") = "1"
from sentence_transformers import SentenceTransformer, InputExample, LoggingHandler
import torch
from torch.utils.data import DataLoader
from transformers import AdamW, get_linear_schedule_with_warmup
train_sentences = data('all_text')
train_labels = data('label')
# training parameters
num_epochs = 5
batch_size = 2
learning_rate = 2e-5
# Convert the dataset to PyTorch tensors.
train_examples = (InputExample(texts=(s), label=l) for s, l in zip(train_sentences, train_labels))
# Customize collate_fn to convert InputExample objects into tensors.
def collate_fn(batch):
texts = (example.texts(0) for example in batch)
labels = torch.tensor((example.label for example in batch))
return texts, labels
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=batch_size, collate_fn=collate_fn)
# Define the loss function, optimizer, and learning rate scheduler.
criterion = nn.CrossEntropyLoss()
optimizer = AdamW(model_with_head.parameters(), lr=learning_rate)
total_steps = len(train_dataloader) * num_epochs
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps)
# Training loop
loss_list=()
for epoch in range(num_epochs):
model_with_head.train()
for step, (texts, labels) in enumerate(train_dataloader):
labels = labels.to(model.device)
optimizer.zero_grad()
# Encode text and pass through classification head.
inputs = model.tokenize(texts)
input_ids = inputs('input_ids').to(model.device)
input_attention_mask = inputs('attention_mask').to(model.device)
inputs_final = {'input_ids': input_ids, 'attention_mask': input_attention_mask}
# move model_with_head to the same device
model_with_head = model_with_head.to(model.device)
logits = model_with_head(inputs_final)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
scheduler.step()
if step % 100 == 0:
print(f"Epoch {epoch}, Step {step}, Loss: {loss.item()}")
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}')
model_save_path = f'./intermediate-output/epoch-{epoch}'
model.save(model_save_path)
loss_list.append(loss.item())
# Save the final model
model_final_save_path="st_ft_epoch_5"
model.save(model_final_save_path)
To observe whether our resulting fine-tuned sentence transformer improves the accuracy of our product category classification, we use it as our text embedder in the XGBoost classifier in the next step.
XGBoost Ranking
XGBoost (Extreme Gradient Boosting) Classification is a machine learning technique used for classification tasks. It is an implementation of the gradient boosting framework designed to be efficient, flexible and portable. For this post, we have XGBoost consume the product description text embedding the output of our sentence transformers and observe the accuracy of the product category classification. We use the following code to use the standard. paraphrase-MiniLM-L6-v2 Sentence Transformer before it was perfected to classify amazon products into their respective categories:
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.metrics import accuracy_score
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
data('text_embedding') = data('all_text').apply(lambda x: model.encode(str(x)))
text_embeddings = pd.DataFrame(data('text_embedding').tolist(), index=data.index, dtype=float)
# Convert numeric columns stored as strings to floats
numeric_columns = ('selling_price', 'shipping_weight', 'product_dimensions') # Add more columns as needed
for col in numeric_columns:
data(col) = pd.to_numeric(data(col), errors="coerce")
# Convert categorical columns to category type
categorical_columns = ('model_number', 'is_amazon_seller') # Add more columns as needed
for col in categorical_columns:
data(col) = data(col).astype('category')
X_0 = data(('selling_price','model_number','is_amazon_seller'))
x = pd.concat((X_0, text_embeddings), axis=1)
label_encoder = LabelEncoder()
data('main_category_encoded') = label_encoder.fit_transform(data('main_category'))
y = data('main_category_encoded')
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# Re-encode the labels to ensure they are consecutive integers starting from 0
unique_labels = sorted(set(y_train) | set(y_test))
label_mapping = {label: idx for idx, label in enumerate(unique_labels)}
y_train = y_train.map(label_mapping)
y_test = y_test.map(label_mapping)
# Enable categorical support for XGBoost
dtrain = xgb.DMatrix(X_train, label=y_train, enable_categorical=True)
dtest = xgb.DMatrix(X_test, label=y_test, enable_categorical=True)
param = {
'max_depth': 6,
'eta': 0.3,
'objective': 'multi:softmax',
'num_class': len(label_mapping),
'eval_metric': 'mlogloss'
}
num_round = 100
bst = xgb.train(param, dtrain, num_round)
# Evaluate the model
y_pred = bst.predict(dtest)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
Accuracy: 0.78
We observed an accuracy of 78% using the action. paraphrase-MiniLM-L6-v2 sentence transformer. To observe the adjustment results paraphrase-MiniLM-L6-v2 Sentence Transformer, we need to update the beginning of the code as follows. The rest of the code remains the same.
model = SentenceTransformer('st_ft_epoch_5')
data('text_embedding_miniLM_ft10') = data('all_text').apply(lambda x: model.encode(str(x)))
text_embeddings = pd.DataFrame(data('text_embedding_finetuned').tolist(), index=data.index, dtype=float)
X_pa_finetuned = pd.concat((X_0, text_embeddings), axis=1)
X_train, X_test, y_train, y_test = train_test_split(X_pa_finetuned, y, test_size=0.2, random_state=42)
# Re-encode the labels to ensure they are consecutive integers starting from 0
unique_labels = sorted(set(y_train) | set(y_test))
label_mapping = {label: idx for idx, label in enumerate(unique_labels)}
y_train = y_train.map(label_mapping)
y_test = y_test.map(label_mapping)
# Build and train the XGBoost model
# Enable categorical support for XGBoost
dtrain = xgb.DMatrix(X_train, label=y_train, enable_categorical=True)
dtest = xgb.DMatrix(X_test, label=y_test, enable_categorical=True)
param = {
'max_depth': 6,
'eta': 0.3,
'objective': 'multi:softmax',
'num_class': len(label_mapping),
'eval_metric': 'mlogloss'
}
num_round = 100
bst = xgb.train(param, dtrain, num_round)
y_pred = bst.predict(dtest)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
# Optionally, convert the predicted labels back to the original category labels
inverse_label_mapping = {idx: label for label, idx in label_mapping.items()}
y_pred_labels = pd.Series(y_pred).map(inverse_label_mapping)
Accuracy: 0.94
With the tuning paraphrase-MiniLM-L6-v2 sentence transformer, we observed 94% accuracy, a 16% increase from the baseline of 78% accuracy. From this observation, we conclude that fine tuning paraphrase-MiniLM-L6-v2 It is effective in classifying amazon product data into product categories.
Tune the M5_ASIN_SMALL_V20 statement transformer
Now we create a sentence transformer from a BERT-based model called M5_ASIN_SMALL_V2.0. It is a 40 million parameter BERT-based model trained on M5, an internal amazon team that specializes in fine-tuning LLMs using amazon product data. It was distilled from a larger teaching model (approximately 5 billion parameters), which was pre-trained on a large amount of unlabeled ASIN data and pre-tuned on a set of amazon-supervised learning tasks (predefined multitasking). tuning). It is a multi-task, multi-lingual, multi-local and multi-modal BERT-based encoder model trained on text input and structured data. The architectural details of its neural network are as follows:
Model spine:
Hidden size: 384
Number of hidden layers: 24
Number of care heads: 16
Intermediate size: 1536
Vocabulary size: 256,035
Number of backbone parameters: 42,587,904
Number of word embedding parameters (bert.embedding.*): 98,517,504
Total number of parameters: 141,259,023
Because M5_ASIN_SMALL_V20 was pre-trained specifically on amazon product data, we hypothesize that constructing a sentence transformer from them will increase the accuracy of product category classification. We complete the following steps to construct a sentence transformer from M5_ASIN_SMALL_V20fine-tune it and feed it into an XGBoost classifier to see the impact on accuracy:
- Load a pre-trained M5 model that you want to use as the base encoder.
- Use the M5 model inside the
SentenceTransformerframework to create a sentence transformer. - Add a pooling layer to create fixed-size sentence embeddings from the variable-length output of the BERT model.
- Combine the M5 model and the pooling layer into a single model.
- Fit the model on a relevant data set.
See the following code for steps 1 to 3:
from sentence_transformers import models
from transformers import AutoTokenizer
# Step 1: Load Pre-trained M5 Model
model_path="M5_ASIN_SMALL_V20" # or your custom model path
transformer_model = models.Transformer(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# Step 2: Define Pooling Layer
pooling_model = models.Pooling(transformer_model.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True)
# Step 3: Create SentenceTransformer Model
model_mean_m5_base = SentenceTransformer(modules=(transformer_model, pooling_model))
The rest of the code remains the same as fine tuning for the paraphrase-MiniLM-L6-v2 sentence transformer, except we use the adjusted M5 sentence transformer instead to create embeddings for the texts in the data set:
loaded_model = SentenceTransformer('m5_ft_epoch_5_mean')
data('text_embedding_m5') = data('all_text').apply(lambda x: loaded_model.encode(str(x)))
Result
We observe results similar to paraphrase-MiniLM-L6-v2 When looking at the accuracy before fine-tuning, an accuracy of 78% is observed for M5_ASIN_SMALL_V20. However, we observe that the fine tuning M5_ASIN_SMALL_V20 The sentence transformer works better than the fine-tuned paraphrase-MiniLM-L6-v2. Its accuracy is 98%, compared to 94% for fine tuning. paraphrase-MiniLM-L6-v2. We tuned the sentence transformers for 5 epochs, because experiments showed that this was the optimal number to minimize the loss. The following graph summarizes our fine-tuned precision improvement observations for 5 epochs in a single comparison chart.
![]()
Clean
We recommend using GPU to tune sentence transformers, for example ml.g5.4xlarge or ml.g4dn.16xlarge. Be sure to clean up resources to avoid incurring additional costs.
If you are using a SageMaker notebook instance, see Clean up your amazon SageMaker notebook instance resources. If you use amazon SageMaker Studio, see Delete or stop running Studio instances, applications, and spaces.
Conclusion
In this post, we explore sentence transformers and how to use them effectively for text classification tasks. We take a deep dive into the phrase transformer. paraphrase-MiniLM-L6-v2demonstrated how to use a BERT-based model like M5_ASIN_SMALL_V20 To create a sentence transformer, he showed how to tune sentence transformers and showed the precision effects of tuning sentence transformers.
Tuning sentence transformers has proven to be very effective in classifying product descriptions into categories, significantly improving prediction accuracy. As a next step, we encourage you to explore different Hugging Face phrase transformers.
Lastly, if you want to explore M5, please note that it is owned by amazon and can only be accessed as an amazon Partner or Customer at the time of this post. Connect with your amazon point of contact if you are an amazon partner or customer looking to use M5, and they will guide you through what M5 offers and how it can be used for your use case.
About the authors
![]() Kara Yang is a data scientist at AWS Professional Services in the San Francisco Bay area, with extensive experience in ai/ML. He specializes in leveraging cloud computing, machine learning, and generative ai to help clients address complex business challenges across diverse industries. Kara is passionate about innovation and continuous learning.
Kara Yang is a data scientist at AWS Professional Services in the San Francisco Bay area, with extensive experience in ai/ML. He specializes in leveraging cloud computing, machine learning, and generative ai to help clients address complex business challenges across diverse industries. Kara is passionate about innovation and continuous learning.
![]() Farshad Harirchi is a Principal Data Scientist at AWS Professional Services. It helps clients across industries, from retail to industrial and financial services, with the design and development of generative artificial intelligence and machine learning solutions. Farshad brings extensive experience across machine learning and the MLOps stack. Outside of work, he enjoys traveling, playing outdoor sports, and exploring board games.
Farshad Harirchi is a Principal Data Scientist at AWS Professional Services. It helps clients across industries, from retail to industrial and financial services, with the design and development of generative artificial intelligence and machine learning solutions. Farshad brings extensive experience across machine learning and the MLOps stack. Outside of work, he enjoys traveling, playing outdoor sports, and exploring board games.
![]() James Poquiz is a data scientist at AWS Professional Services based in Orange County, California. He has a bachelor's degree in Computer Science from the University of California, Irvine and several years of experience working in the data domain having held many different roles. Today he works on implementing and deploying scalable machine learning solutions to achieve business results for AWS customers.
James Poquiz is a data scientist at AWS Professional Services based in Orange County, California. He has a bachelor's degree in Computer Science from the University of California, Irvine and several years of experience working in the data domain having held many different roles. Today he works on implementing and deploying scalable machine learning solutions to achieve business results for AWS customers.




{kind=link}