 NEWSLETTER
NEWSLETTER
AWS offers services that meet customers’ artificial intelligence (AI) and machine learning (ML) needs with services ranging from custom hardware like AWS Trainium and AWS Inferentia to basic generative AI (FM) models on Amazon Bedrock. In February 2022, AWS and Hugging Face announced a collaboration to make generative AI more accessible and cost-effective.
Generative AI has grown at a rapid pace from the largest pretrained model in 2019 with 330 million parameters to over 500 billion parameters today. The performance and quality of the models also improved dramatically with the number of parameters. These models cover tasks like text to text, text to image, text to embed, and more. You can use large language models (LLMs), more specifically, for tasks that include summaries, metadata extraction, and answering questions.
Amazon SageMaker JumpStart is an ML hub that can help you accelerate your ML journey. With JumpStart, you can access pretrained models and base models from the Foundations Model Hub to perform tasks such as article summaries and image generation. Pretrained models are fully customizable for your use cases and can be easily deployed to production with the UI or SDK. Most importantly, none of your data is used to train the underlying models. Because all data is encrypted and doesn’t leave the Virtual Private Cloud (VPC), you can trust that your data will stay private and confidential.
This post focuses on creating a serverless meeting summary using Amazon Transcribe to transcribe meeting audio and Custard-T5-XL Hugging Face model (available on JumpStart) to summarize.
Solution Overview
Meeting Notes Generator Solution creates a serverless automated pipeline using AWS Lambda to transcribe and summarize audio and video recordings of meetings. The solution can be implemented with other FMs available in JumpStart.
The solution includes the following components:
- A shell script to create a custom Lambda layer
- A configurable AWS CloudFormation template to implement the solution
- Lambda function code to start Amazon Transcribe transcription jobs
- Lambda function code to invoke a SageMaker real-time endpoint hosting the Flan T5 XL model
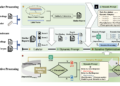
The following diagram illustrates this architecture.
As shown in the architecture diagram, meeting recordings, transcripts, and notes are stored in their respective Amazon Simple Storage Service (Amazon S3) buckets. The solution takes an event-based approach to transcribe and summarize S3 upload events. The events trigger Lambda functions to make API calls to Amazon Transcribe and invoke the real-time endpoint that hosts the Flan T5 XL model.
The CloudFormation template and instructions for implementing the solution can be found in the GitHub repository.
Real-time inference with SageMaker
Real-time inference in SageMaker is designed for workloads with low latency requirements. SageMaker endpoints are fully managed and support multiple hosting and autoscaling options. Once created, the endpoint can be invoked with the InvokeEndpoint API. The provided CloudFormation template creates a real-time endpoint with the default instance count of 1, but this can be adjusted based on the expected load on the endpoint and as allowed by the service quota for the instance type. You can request service quota increases on the Service Quotas page of the AWS Management Console.
The following CloudFormation template snippet defines the SageMaker model, endpoint configuration, and endpoint using the ModelData and ImageURI of the JumpStart T5 XL Flan. You can explore more FM in Getting Started with Amazon SageMaker JumpStart. To implement the solution with a different model, replace the ModelData and ImageURI parameters in the CloudFormation template with the S3 artifact and container image URI of the desired model, respectively. review the sample notebook on GitHub for sample code on how to retrieve the latest JumpStart model artifact in Amazon S3 and the corresponding public container image provided by SageMaker.
Deploy the solution
For detailed steps on implementing the solution, follow the Implementation with CloudFormation section of the GitHub repository.
If you want to use a different instance type or more instances for your endpoint, submit a quota increase request for the desired instance type on the AWS Service Quotas panel.
To use a different FM for the end point, replace the ImageURI and ModelData parameters in the CloudFormation template for the corresponding FM.
try the solution
After implementing the solution using the Lambda layering script and the CloudFormation template, you can test the architecture by uploading an audio or video meeting recording in any of the media formats supported by Amazon Transcribe. Complete the following steps:
- In the Amazon S3 console, choose cubes in the navigation pane.
- From the list of S3 buckets, choose the S3 bucket created by the CloudFormation template named
meeting-note-generator-demo-bucket-<aws-account-id>. - Choose Create folder.
- For folder nameenter the S3 prefix specified in the
S3RecordingsPrefixCloudFormation template parameter (recordingsdefault). - Choose Create folder.
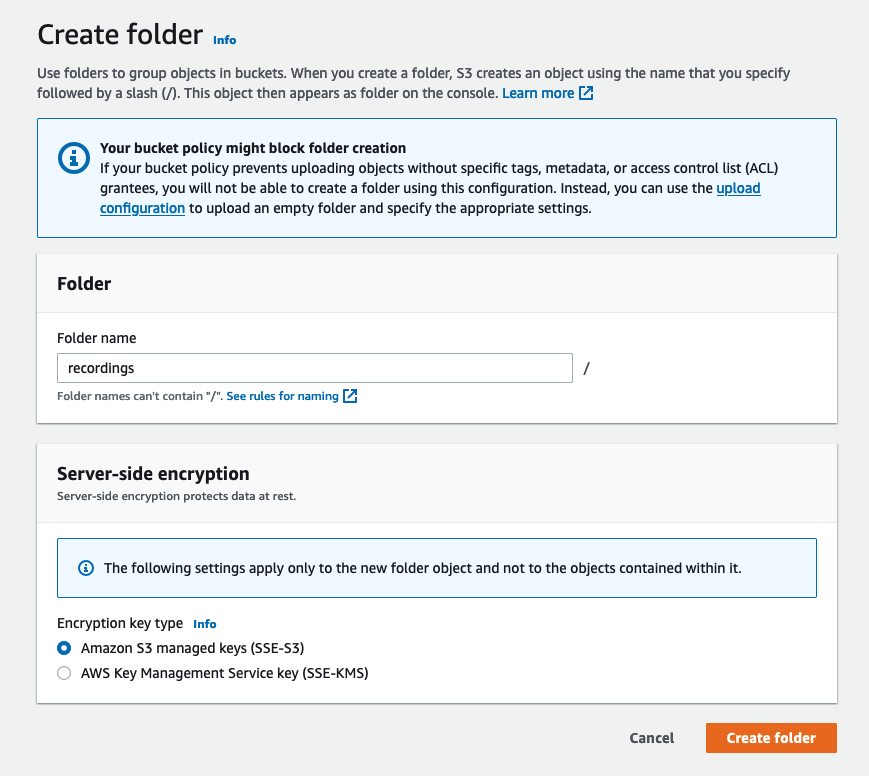
- In the newly created folder, choose Increase.
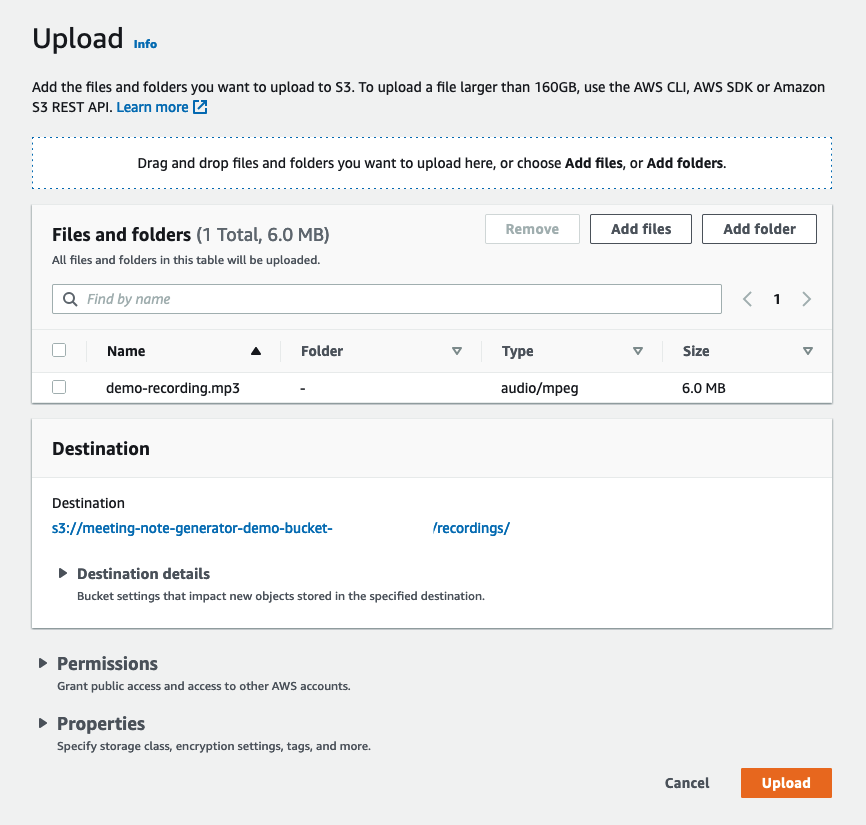
- Choose add files and choose the meeting recording file to upload.
- Choose Increase.
Now we can check if the transcription was successful.
- In the Amazon Transcribe console, choose transcription jobs in the navigation pane.
- Verify that a transcription job with a name corresponding to the uploaded meeting recording has the status In progress either Complete.
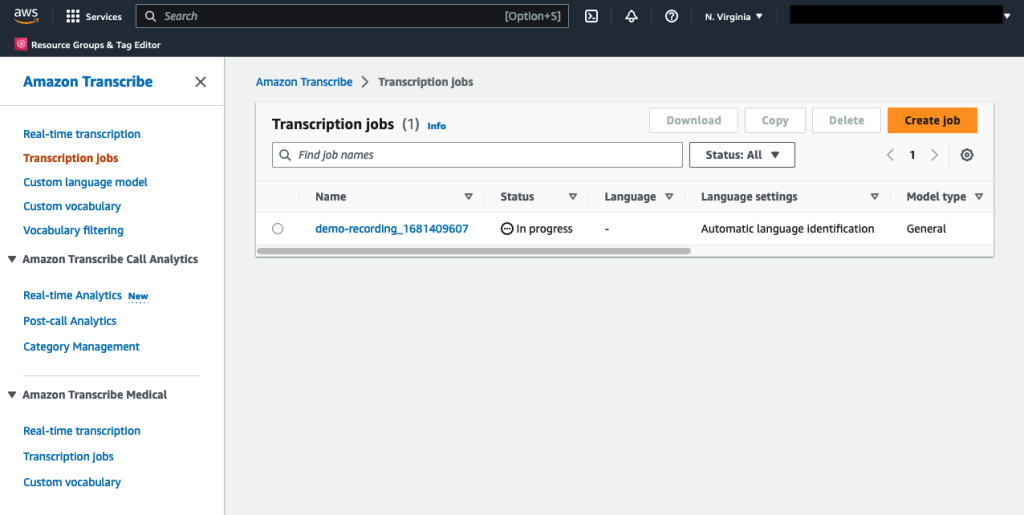
- When the state is CompleteGo back to the Amazon S3 console and open the demo bucket.
- In the S3 bucket, open the
transcripts/file. - Download the generated text file to view the transcript.
We can also consult the generated summary.
- In the S3 bucket, open the
notes/file. - Download the generated text file to view the generated summary.
rapid engineering
Although LLMs have improved in recent years, the models can only support finite inputs; therefore, inserting a full transcript of a meeting may exceed the model limit and cause the call to fail. To design around this challenge, we can break the context into manageable pieces by limiting the number of tokens in each invocation context. In this sample solution, the transcript is split into smaller chunks with a maximum limit on the number of tokens per chunk. Each transcript fragment is then summarized using the Flan T5 XL model. Finally, the snippet summaries are combined to form the context of the final combined summary, as shown in the following diagram.

The following code of the GenerateMeetingNotes The lambda function uses the Natural Language Toolkit (NLTK) library to tokenize the transcript, then split the transcript into sections, each containing up to a certain number of tokens:
Finally, the following code snippet combines the snippet summaries as context to generate a final summary:
the full GenerateMeetingNotes The Lambda function can be found in the GitHub repository.
Clean
To clean up the solution, complete the following steps:
- Delete all objects in the demo S3 bucket and the log S3 bucket.
- Delete the CloudFormation stack.
- Delete the Lambda layer.
Conclusion
This post demonstrated how to use FM in JumpStart to quickly build a serverless meeting note generator architecture with AWS CloudFormation. Combined with AWS AI services like Amazon Transcribe and serverless technologies like Lambda, you can use FM on JumpStart and Amazon Bedrock to build applications for various generative AI use cases.
For additional posts on ML on AWS, visit the AWS ML Blog.
About the Author
 eric kim is a Solution Architect (SA) at Amazon Web Services. Work with game developers and publishers to build scalable games and support services on AWS. It mainly focuses on artificial intelligence and machine learning applications.
eric kim is a Solution Architect (SA) at Amazon Web Services. Work with game developers and publishers to build scalable games and support services on AWS. It mainly focuses on artificial intelligence and machine learning applications.





{kind=link}