 NEWSLETTER
NEWSLETTER
Seamless integration of customer experience, collaboration tools, and relevant data is the foundation for delivering knowledge-based productivity gains. In this post, we show you how to integrate the popular Slack messaging service with AWS generative ai services to build a natural language assistant where business users can ask questions of an unstructured dataset.
To demonstrate, we create a generative ai-enabled Slack assistant with an integration to amazon Bedrock Knowledge Bases that can expose the combined knowledge of the AWS Well-Architected Framework while implementing safeguards and responsible ai using amazon Bedrock Guardrails.
amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading ai companies like AI21 labs, Anthropic, Cohere, Meta, Stability ai and amazon through a single API.
amazon Bedrock Knowledge Bases provides a fully managed Retrieval Augmented Generation (RAG) workflow, a technique that fetches data from company data sources and enriches the prompt to provide more relevant and accurate responses to natural language queries. This makes amazon Bedrock Knowledge Bases an attractive option to incorporate advanced generative ai capabilities into products and services without the need for extensive machine learning expertise.
amazon Bedrock Guardrails enables you to implement safeguards to build and customize safety, privacy, and truthfulness protections for your generative ai applications to align with responsible ai policies. Guardrails can help prevent undesirable content, block prompt injections, and remove sensitive information for privacy, protecting your company’s brand and reputation.
This content builds on posts such as Deploy a Slack gateway for amazon Bedrock by adding integrations to amazon Bedrock Knowledge Bases and amazon Bedrock Guardrails, and the Bolt for Python library to simplify Slack message acknowledgement and authentication requirements.
Solution overview
The code in the accompanying GitHub repo provided in this solution enables an automated deployment of amazon Bedrock Knowledge Bases, amazon Bedrock Guardrails, and the required resources to integrate the amazon Bedrock Knowledge Bases API with a Slack slash command assistant using the Bolt for Python library.
In this example, we ingest the documentation of the amazon Well-Architected Framework into the knowledge base. Then we use the integration to the amazon Bedrock Knowledge Bases API to provide a Slack assistant that can answer user questions on AWS architecture best practices. You can substitute the example documentation for your enterprise dataset, such as your corporate, HR, IT, or security policies, or equipment user or maintenance guides.
The following diagram illustrates the high-level solution architecture.
In the following sections, we discuss the key components in more detail.
Slack integration
The Slack integration is provided through the Slack Bolt Library for Python running in the Request Processor AWS Lambda function. The Slack Bolt Library handles authentication and permissions to the Slack application we build, and comes with built-in support for asynchronous request handling. Slack Bolt provides a dedicated user guide to deploy and run the library in a Lambda function.
Retrieval Augmented Generation
amazon Bedrock Knowledge Bases gives FMs contextual information from your private data sources for RAG to deliver more relevant, accurate, and customized responses.
The RAG workflow consists of two key components: data ingestion and text generation.
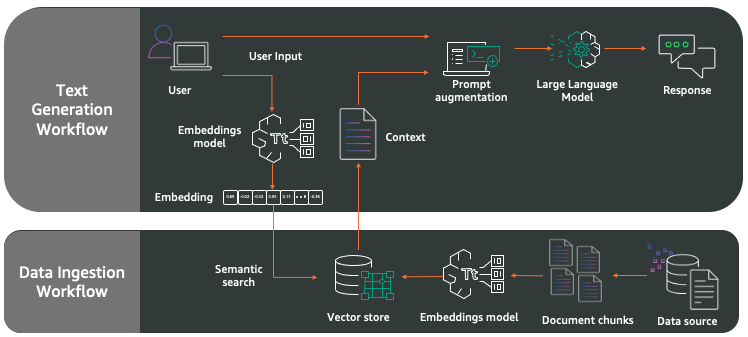
- Data ingestion workflow – During data ingestion, unstructured data from the data source is separated into chunks. Chunks are short series of text from each source document separated by a fixed word count, paragraphs, or a single thought. Chunks are vectorized and stored in a vector database. amazon Bedrock Knowledge Bases supports a number of vector databases, such as amazon OpenSearch Serverless, amazon Aurora, Pinecone, Redis Enterprise Cloud, and Mongo DB Atlas. In this example, we use the default option of OpenSearch Serverless.
- Text generation workflow – After the source data is ingested into the vector database, we can perform a semantic search to find chunks of data that are relevant to the user query based on contextualized meaning instead of just literal string matching. To complete the process, both the user query and the relevant data chunks are presented to the selected large language model (LLM) to create a natural language response.
amazon Bedrock Knowledge Bases APIs
amazon Bedrock Knowledge Bases provides a fully managed RAG workflow that is exposed using two main APIs:
- Retrieve – This API retrieves the relevant data chunks using semantic search, which you can then process further in application logic
- RetrieveAndGenerate – This API completes a full RAG text generation workflow to return a natural language response to a human query of the given dataset
The solution in this post calls the RetrieveAndGenerate API to return the natural language response to the Slack Bolt integration library.
amazon Bedrock Guardrails
amazon Bedrock Guardrails provides additional customizable safeguards on top of built-in protections offered by FMs, delivering safety features that are among the best in the industry.
In this solution, we configure amazon Bedrock Guardrails with content filters, sensitive information filters, and word filters.
Content filters help detect and filter harmful user inputs and model-generated outputs across six categories: prompt injections, misconduct, insults, hate, violence, and sexually explicit content. In this solution, we use all six content filter categories.
Sensitive information filters detect sensitive information such as personally identifiable information (PII) data in a prompt or model responses. To align with your specific case, you can use custom sensitive information filters by defining them with regular expressions (regex).
In this solution, we configure sensitive information filters as follows:
Emailwith an action ofAnonymizePhonewith an action ofAnonymizeNamewith an action ofAnonymizeCredit_Debit_Card_Numberwith an action ofBlock
Word filters are used to block words and phrases in input prompts and model responses. In this solution, we have enabled the AWS provided profanity filter. To align with your use case, you can create custom word filters.
Solution walkthrough
Slack interfaces with a simple REST API, configured with Lambda proxy integration that in turn interacts with amazon Bedrock Knowledge Bases APIs.
The solution is deployed with the following high-level steps:
- Create a new Slack application.
- Enable third-party model access in amazon Bedrock.
- Deploy the Slack to amazon Bedrock integration using the AWS Cloud Development Kit (AWS CDK).
- Ingest the AWS Well-Architected Framework documents to the knowledge base.
Prerequisites
To implement this solution, you need the following prerequisites:
- A Slack workspace where you have permissions to create a Slack app (if you don’t have a Slack workspace, sign up for a workspace on Slack.com)
- An AWS account
- Access to following AWS services:
This post assumes a working knowledge of the listed AWS services. Some understanding of vector databases, vectorization, and RAG would be advantageous, but not necessary.
Create a new Slack application
After you have logged in to your Slack workspace, complete the following steps:
- Navigate to your Slack apps and create a new application.

- Choose From scratch when prompted.
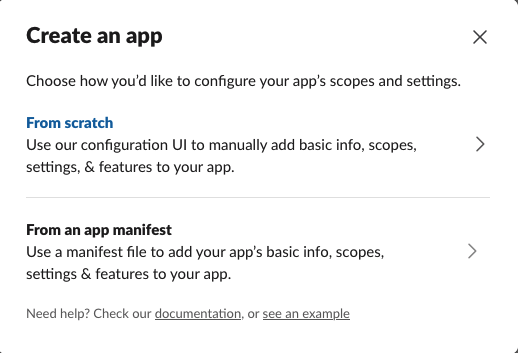
- Provide an application name. For this post, we use the name
aws-war-bot. - Choose your workspace and choose Create App.
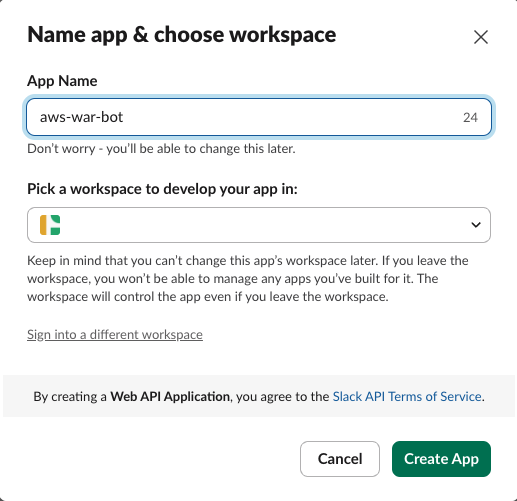
- To provide permissions for your Slack application, choose OAuth & Permissions in your Slack application navigation pane.
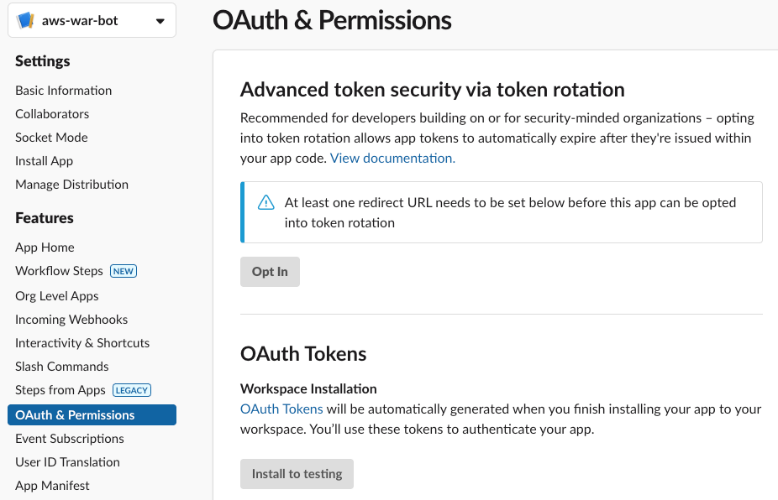
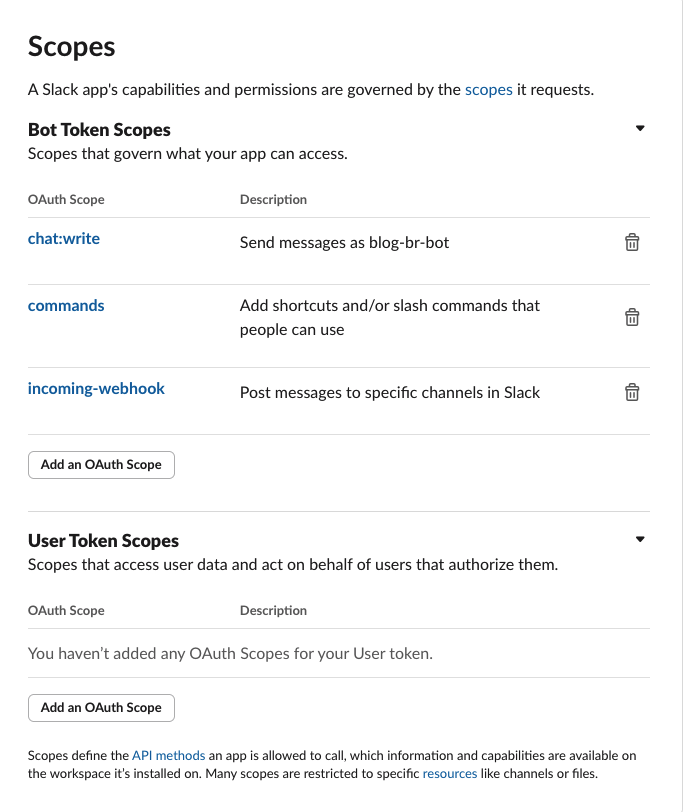
- In the Scopes section, under Bot Token Scopes, add the following permissions:
calls:writecommandsincoming-webhook
- Under OAuth Tokens for Your Workspace, choose Install to (workspace name).
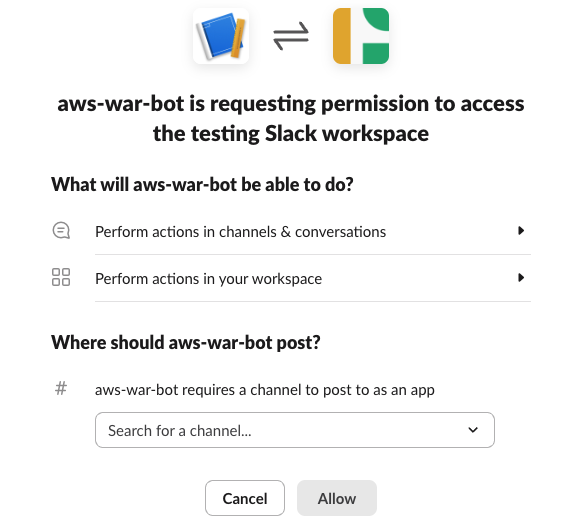
- Choose a channel that the Slack application will be accessed from. You may want to first create a dedicated channel in Slack for this purpose.
- Choose Allow.
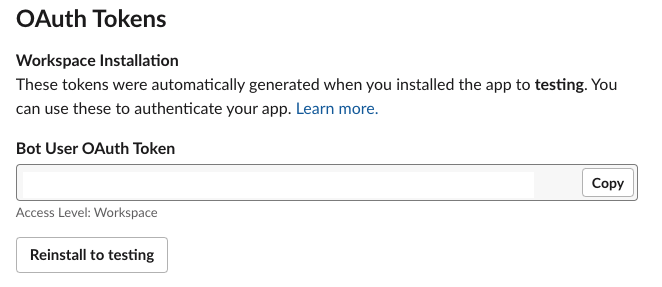
- When the Slack application install is complete, copy the token value generated for Bot User OAuth Token to use in a later step.
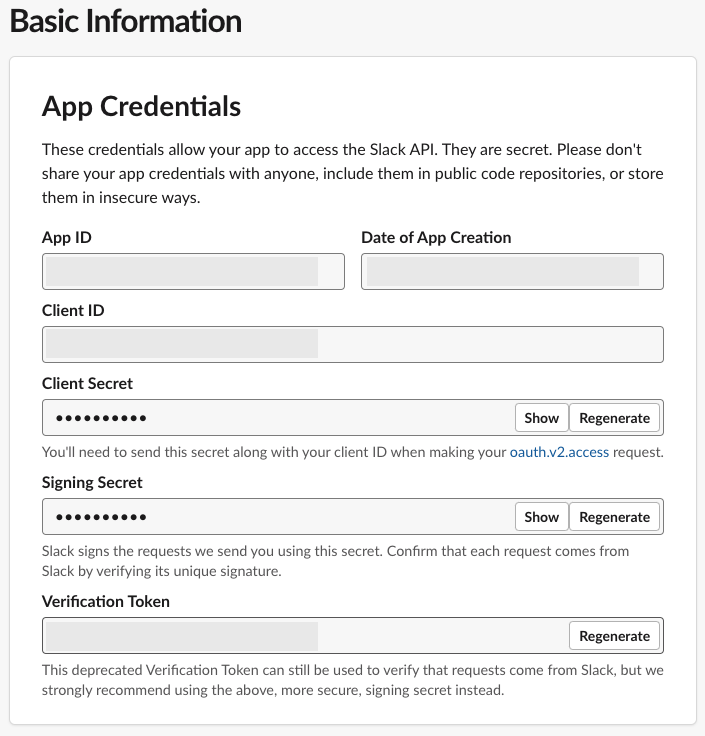
- Under Settings in the navigation pane, choose Basic Information.
- In the App Credentials section, copy the value for Signing Secret and save this to use later.
Enable model access in amazon Bedrock
Complete the following steps to enable model access in amazon Bedrock:
- On the amazon Bedrock console, choose Model access in the navigation pane.
- Choose Modify model Access or Enable specific models (if this is the first time using amazon Bedrock in your account).
- Select the models you want to use for the embeddings and RAG query response models. In this post, we use amazon Titan Text Embeddings V2 as the embeddings model and Anthropic’s Claude Sonnet 3 for the RAG query models in the
US-EAST-1AWS Region. - Choose Next.
- Review the model selection and choose Submit.
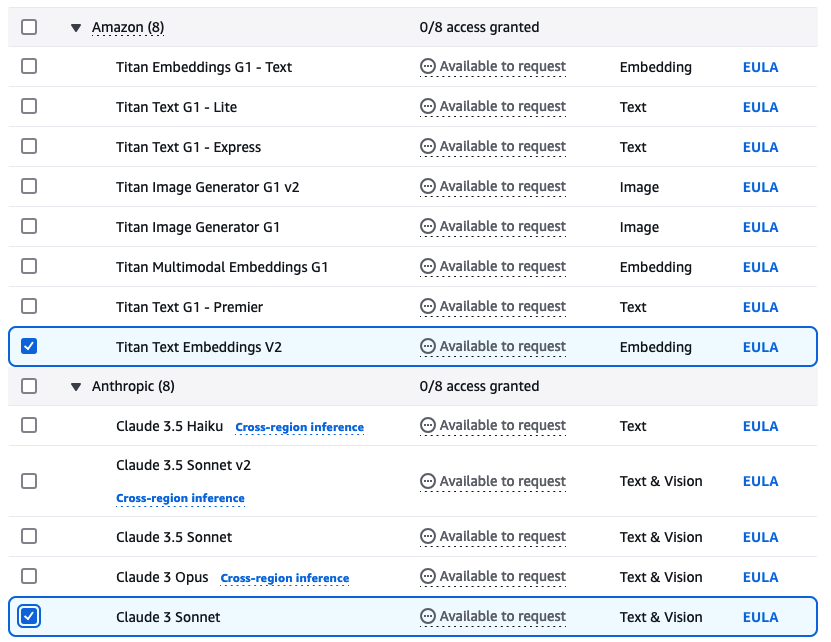
If you’re not using the US-EAST-1 Region, the models available to request may differ.
When the access request is complete, you will see the model’s status shown as Access granted for the selected models.
Deploy the Slack to amazon Bedrock integration
In this section, you deploy the companion code to this post to your AWS account, which will deploy an API on API Gateway, a Lambda function, and an amazon Bedrock knowledge base with OpenSearch Serverless as the vector database.
This section requires AWS CDK and TypeScript to be installed in your local integrated development environment (IDE) and for an AWS account to be bootstrapped. If this has not been done, refer to Getting started with the AWS CDK.
- Clone the code from the <a target="_blank" href="https://github.com/aws-samples/amazon-bedrock-knowledgebase-slackbot” target=”_blank” rel=”noopener”>GitHub repository:
- Open the
amazon-bedrock-knowledgebase-slackbotdirectory in your preferred IDE and open thelib/amazon-bedrock-knowledgebase-slackbot-stack.tsfile. - Update the variables if needed (depending on model access and Regional support) for the RAG query and embeddings models:
- Save the changes after all updates are complete.
- From the root of your repository, run the command
npm install. - Run the command
cdk synthto perform basic validation of AWS CDK code. This generates a CloudFormation template from the AWS CDK stack, which can be reviewed in thecdk.outdirectory created in the root of the repository. - To deploy the application stack, run the following command, replacing the values with the token and the signing secret you created earlier:
The AWS CDK will deploy the stack as a CloudFormation template. You can monitor the progress of the deployment on the AWS CloudFormation console.
Additionally, AWS CDK will attempt to deploy the application stack to the default account and Region using the default credentials file profile. To change profiles, add the profile flag. For example:
When the deployment is complete, you will see an output similar to the following screenshot, which details the API endpoint that has just been deployed.
- Copy the API endpoint URL for later use.

You can also retrieve this URL on the Outputs tab of the CloudFormation stack AmazonBedrockKnowledgebaseSlackbotStack that was run to deploy this solution.
- Switch back to the Slack API page.
- Under the Slack application you created, choose Slash Commands in the navigation pane and then choose Create New Command.
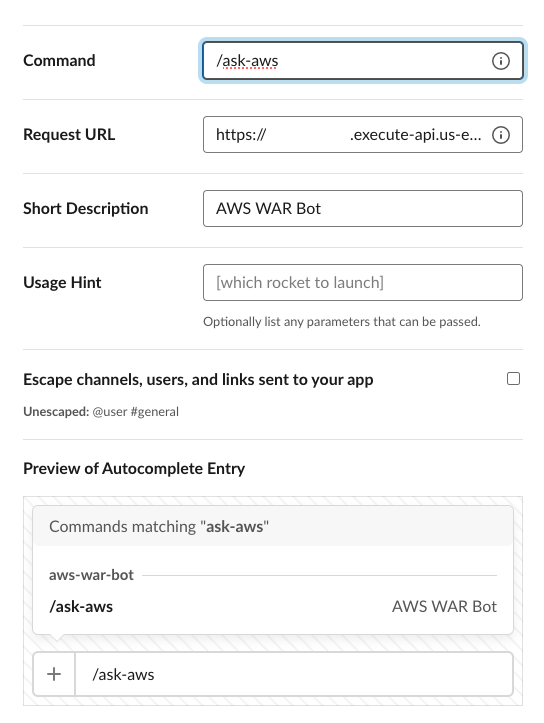
- Provide the following information (make sure to include the Region and API ID that has been deployed):
- For Command, enter
/ask-aws. - For Request URL, enter
https://(AWS-URL)/slack/(command). For example,https://ab12cd3efg.execute-api.us-east-1.amazonaws.com/prod/slack/ask-aws. - For Short Description, enter a description (for example,
AWS WAR Bot).
- For Command, enter
- Choose Save.
- Reinstall the Slack application to your workspace in the Install App section by choosing Reinstall next to the workspace name.
- Choose the channel where the Slack app will be deployed and choose Allow.
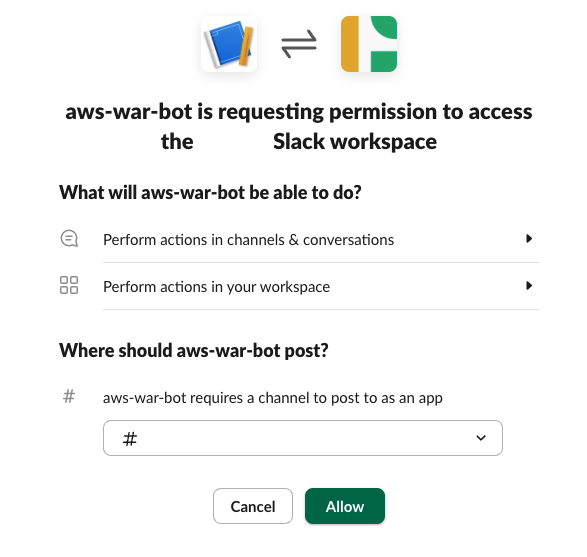
In the Slack channel, you will see a message like the one in the following screenshot, indicating that an integration with the channel has been added.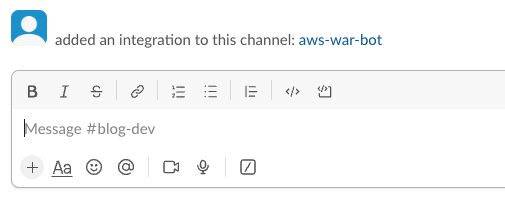
Populate the amazon Bedrock knowledge base
Complete the following steps to populate the amazon Bedrock knowledge base with the combined information of the AWS Well-Architected Framework:
- Download the following AWS Well-Architected Framework documents:
You can also include any Well-Architected Lenses that are relevant to your organization by downloading from AWS Whitepapers and Guides.
- On the amazon Bedrock console, choose Knowledge bases in the navigation pane.
- Choose the knowledge base you deployed (
slack-bedrock-kb).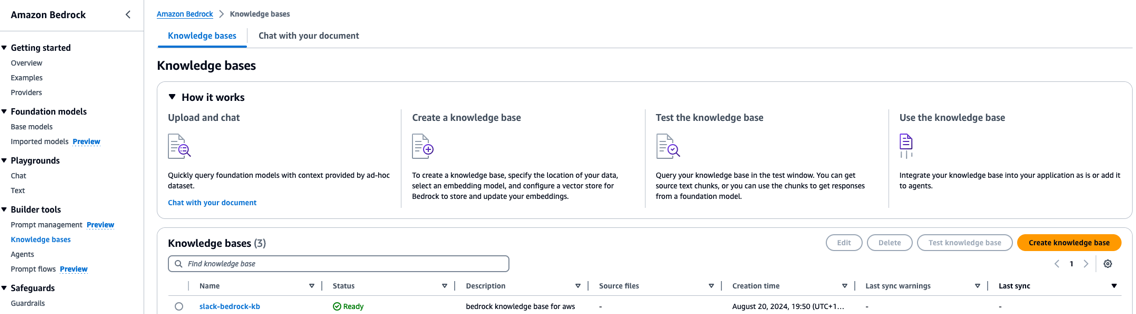
- In the Data source section under Source link, choose the S3 bucket link that is displayed.
This will open the S3 bucket that is being used by the amazon Bedrock knowledge base as the data source.

- In the S3 bucket, choose Upload then Add files, and select all of the downloaded AWS Well-Architected documents from the previous step.
- When the documents have completed uploading, switch back to the Knowledge bases page on the amazon Bedrock console.
- Select the data source name and choose Sync.
This will sync the documents from the S3 bucket to the OpenSearch Serverless vector database. The process can take over 10 minutes.
When the sync is complete, the data source will show a Status of Available.

Test the Slack application integration with amazon Bedrock
Complete the following steps to test the integration:
- Open the Slack channel selected in the previous steps and enter
/ask-aws.
The Slack application will be displayed.
- Choose the Slack application and enter your prompt. For this test, we use the prompt “Tell me about the AWS Well Architected Framework.”
The Slack application will respond with Processing Request and a copy of the entered prompt. The application will then provide a response to the prompt.

- To test that the guardrails are working as required, write a prompt that will invoke a guardrail intervention.
When an intervention occurs, you will receive the following predefined message as your response.

Clean up
Complete the following steps to clean up your resources:
- From your terminal, run the following command, replacing the values with the token and the signing secret created earlier:
- When prompted, enter y to confirm the deletion of the deployed stack.

Conclusion
In this post, we implemented a solution that integrates an amazon Bedrock knowledge base with a Slack chat channel to allow business users to ask natural language questions of an unstructured dataset from a familiar interface. You can use this solution for multiple use cases by configuring it to different Slack applications and populating the knowledge base with the relevant dataset.
To get started, clone the <a target="_blank" href="https://github.com/aws-samples/amazon-bedrock-knowledgebase-slackbot” target=”_blank” rel=”noopener”>GitHub repo and enhance your customers’ interactions with amazon Bedrock. For more information about amazon Bedrock, see Getting started with amazon Bedrock.
About the Authors

Barry Conway is an Enterprise Solutions Architect at AWS with 20 years of experience in the technology industry, bridging the gap between business and technology. Barry has helped banking, manufacturing, logistics, and retail organizations realize their business goals.
 Dean Colcott is an AWS Senior GenAI/ML Specialist Solution Architect and SME for amazon Bedrock. He has areas of depth in integrating generative ai outcomes into enterprise applications, full stack development, video analytics, and computer vision and enterprise data platforms.
Dean Colcott is an AWS Senior GenAI/ML Specialist Solution Architect and SME for amazon Bedrock. He has areas of depth in integrating generative ai outcomes into enterprise applications, full stack development, video analytics, and computer vision and enterprise data platforms.





{kind=link}