 NEWSLETTER
NEWSLETTER
Introducción
Los agentes LLM desempeñan un papel cada vez más importante en el panorama generativo como motores de razonamiento. Pero la mayoría de los agentes tienen las deficiencias de fallar o sufrir alucinaciones. Sin embargo, los agentes enfrentan desafíos formidables dentro de los modelos de lenguaje grande (LLM), incluida la comprensión del contexto, el mantenimiento de la coherencia y la adaptabilidad dinámica. LangGraph, una sofisticada representación del lenguaje basada en gráficos, ayuda a los agentes a navegar y comprender estructuras lingüísticas complejas, fomentando una comprensión semántica más profunda. Las técnicas RAG avanzadas, como RAG adaptativo, RAG correctivo y Self RAG, ayudan a mitigar estos problemas con los agentes LLM.
Este artículo utilizará técnicas RAG para crear agentes LLM confiables y a prueba de fallas utilizando LangGraph de LangChain y Cohere LLM.

Objetivos de aprendizaje
- Aprender a construir un agente LLM bien fundamentado
- Comprender e implementar técnicas RAG avanzadas como RAG adaptativo, correctivo y propio.
- Para entender qué son los agentes LLM
- Comprender las diferencias entre Langchain Agent y LangGraph y las ventajas de Lang Graph sobre Langchain ReAct Agents
- Para conocer la función Lang Graph.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
¿Qué es un agente?
El principio esencial subyacente a los agentes es utilizar un modelo de lenguaje para elegir una serie de acciones. Esta secuencia está codificada en el código cuando se usa en cadenas. Por el contrario, los agentes utilizan un modelo de lenguaje como motor de razonamiento para elegir qué acciones realizar y en qué orden.
Se compone de 3 componentes:
- Planificación: dividir las tareas en submetas más pequeñas
- memoria: a corto plazo (historial de chat) / a largo plazo (almacenamiento de vectores)
- Uso de herramientas: puede utilizar diferentes herramientas para ampliar sus capacidades, como búsqueda en Internet, recuperador de consultas SQL.
Los agentes se pueden crear utilizando el concepto ReAct con Langchain o LangGraph.
Diferencia entre Langchain Agent y LangGraph
1. Fiabilidad: ReAct/Langchain Agent es menos confiable ya que LLM tiene que tomar la decisión correcta en cada paso, mientras que LangGraph es más confiable ya que se establece el flujo de control. LLM realiza un trabajo específico en cada nodo del gráfico.
2. Flexibilidad: ReAct/Langchain Agent es más flexible ya que LLM puede elegir cualquier secuencia de pasos de acción, mientras que LangGraph es menos flexible ya que las acciones están restringidas al configurar el flujo de control en cada nodo.
3. Compatibilidad con LLM más pequeños: ReAct / Langchain Agent no son muy compatibles con LLM más pequeños, mientras que LangGraph es mejor compatible con LLM más pequeños.
¿Qué es LangGraph?
LangGraph es un paquete que amplía LangChain al permitir la computación circular en aplicaciones LLM. LangGraph permite la inclusión de ciclos, mientras que LangChain anterior permitía la definición de cadenas de cálculo (gráficos acíclicos dirigidos o DAG). Esto permite comportamientos más complejos, similares a los de un agente, en los que se puede llamar a un LLM en un bucle para decidir la siguiente acción a ejecutar.
Conceptos clave de LangGraph
1. Gráfico con estado: LangGraph gira en torno a un gráfico con estado, donde cada nodo representa un paso en su cálculo. El gráfico mantiene un estado que se transmite y actualiza a medida que avanza el cálculo.
2. Nodos: Los nodos son los componentes básicos de su LangGraph. Cada nodo representa una función o un paso de cálculo. Usted define nodos para realizar tareas específicas, como procesar entradas, tomar decisiones o interactuar con API externas.
3. Bordes: Los bordes conectan los nodos en su gráfico, definiendo el flujo de cálculo. LangGraph admite bordes condicionales, lo que le permite determinar dinámicamente el siguiente nodo a ejecutar en función del estado actual del gráfico.
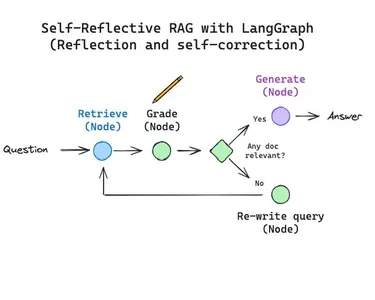
¿Qué es la API de búsqueda de Tavily?
Tavily Search API es un motor de búsqueda optimizado para LLM, cuyo objetivo es obtener resultados de búsqueda eficientes, rápidos y persistentes. A diferencia de otras API de búsqueda como Serp o Google, Tavily optimiza la búsqueda para desarrolladores de IA y agentes de IA autónomos.
¿Qué es Cohere LLM?
Cohere es una plataforma de inteligencia artificial para empresas que se especializa en soluciones basadas en grandes modelos de lenguaje. Su principal servicio es el modelo Command R (y los pesos abiertos de investigación Command R+), que proporciona modelos escalables y de alto rendimiento que compiten con ofertas de firmas como OpenAI y Mistral.
Implementación de código
Flujo de trabajo del agente
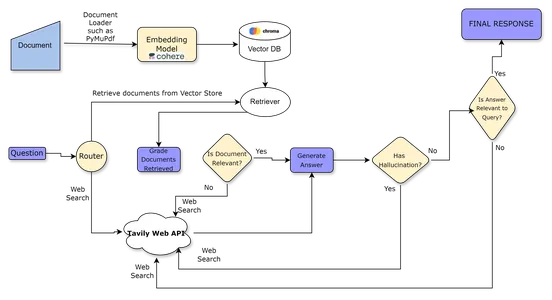
- Según la pregunta, el enrutador decide si dirige la pregunta para recuperar el contexto del almacén de vectores o realiza una búsqueda en la web.
- Si el enrutador decide que la pregunta debe dirigirse a la recuperación del almacén de vectores, entonces los documentos coincidentes se recuperan del almacén de vectores; de lo contrario, realice una búsqueda web utilizando Tavily – Búsqueda API
- Luego, el clasificador de documentos califica los documentos como relevantes o irrelevantes.
- Si el contexto recuperado se califica como relevante, utilice el clasificador de alucinaciones para verificar si hay alucinaciones. Si el evaluador decide que la respuesta carece de alucinación, entonces la respuesta es la respuesta final para el usuario.
- Si el contexto se considera irrelevante, realice una búsqueda web para recuperar el contenido.
- Después de la recuperación, el clasificador de documentos califica el contenido generado a partir de la búsqueda web. Si es relevante, la respuesta se sintetiza usando LLM y luego se presenta.
- Esta respuesta generada por la web luego pasa a través de un verificador de alucinaciones, que verifica si la alucinación está presente y toma la ruta adecuada según el resultado, como se muestra en el diagrama de flujo de trabajo.
<h4 class="wp-block-heading" id="h-technology-stack-used”>Pila de tecnología utilizada
- Modelo de incrustación: Cohere Embed
- LLM: Cohere Comando R plus
- Tienda de vectores: Chroma
- Gráfico/Agente: LangGraph
- API de búsqueda web: API de búsqueda de Tavily
Paso 1: generar la clave API de Cohere
Necesitamos generar la clave API gratuita para utilizar Cohere LLM. Visite el sitio web e inicie sesión con una cuenta de Google o una cuenta de GitHub. Una vez que haya iniciado sesión, accederá a una página del panel de Cohere, como se muestra a continuación.
Clickea en el Claves API opción. Verás un Se genera la clave API de prueba gratuita.
Paso 2: generar la clave API de búsqueda de Tavily
Visite la página de inicio de sesión del sitio. aquíinicie sesión con su cuenta de Google y verá que se genera un plan gratuito predeterminado para la clave API llamado plan “Investigación”.
Una vez que inicie sesión con cualquier cuenta, accederá a la página de inicio de su cuenta, que mostrará un plan gratuito predeterminado con una clave API generada, similar a la pantalla a continuación.
Paso 3: instalar bibliotecas
Ahora, una vez que se generan las claves API, debemos instalar las necesarias
bibliotecas como se muestra a continuación. Se pueden utilizar cuadernos de colab para el desarrollo.
!pip install --quiet langchain langchain_cohere tiktoken chromadb pymupdfPaso 4: configurar claves API
Establecer las claves API como variables de entorno
### Set API Keys
import os
os.environ("COHERE_API_KEY") = "Cohere API Key"
os.environ("TAVILY_API_KEY") = "Tavily API Key"Paso 5: construcción del índice de vectores
Cree un índice vectorial encima del pdf usando Cohere Embeddings.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_cohere import CohereEmbeddings
#from langchain_community.document_loaders import WebBaseLoader
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.vectorstores import Chroma
# Set embeddings
embd = CohereEmbeddings()
# Load Docs to Index
loader = PyMuPDFLoader('/content/cleartax-in-s-income-tax-slabs.pdf')
data = loader.load()
#print(data(10))
# Split
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(data)
# Add to vectorstore
vectorstore = Chroma.from_documents(persist_directory='/content/vector',
documents=doc_splits,
embedding=embd,
)
vectorstore_retriever = vectorstore.as_retriever()Paso 6: instalar el segundo conjunto de bibliotecas
Instale este segundo conjunto de bibliotecas. No instale todas las bibliotecas juntas; de lo contrario, arrojará un error de dependencia.
!pip install langchain-openai langchainhub chromadb langgraph --quietPaso 7: construir enrutador
Ahora, crearemos un enrutador para enrutar consultas en función de si la consulta está relacionada con el índice del vector. Se basa en la técnica Adaptive Advance RAG, que enruta consultas a nodos adecuados.
### Router
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_cohere import ChatCohere
# Data model
class web_search(BaseModel):
"""
The internet. Use web_search for questions that are related to anything else than agents, prompt engineering, and adversarial attacks.
"""
query: str = Field(description="The query to use when searching the internet.")
class vectorstore(BaseModel):
"""
A vectorstore containing documents related to to Income Tax of India New and Old Regime Rules. Use the vectorstore for questions on these topics.
"""
query: str = Field(description="The query to use when searching the vectorstore.")
# Preamble
preamble = """You are an expert at routing a user question to a vectorstore or web search.
The vectorstore contains documents related to Income Tax of India New and Old Regime Rules.
Use the vectorstore for questions on these topics. Otherwise, use web-search."""
# LLM with tool use and preamble
llm = ChatCohere(model="command-r", temperature=0)
structured_llm_router = llm.bind_tools(
tools=(web_search, vectorstore), preamble=preamble
)
# Prompt
route_prompt = ChatPromptTemplate.from_messages(
(
("human", "{question}"),
)
)
question_router = route_prompt | structured_llm_router
response = question_router.invoke(
{"question": "When will the results of General Elections 2024 of India be declared?"}
)
print(response.response_metadata("tool_calls"))
response = question_router.invoke({"question": "What are the income tax slabs in New Tax Regime?"})
print(response.response_metadata("tool_calls"))
response = question_router.invoke({"question": "Hi how are you?"})
print("tool_calls" in response.response_metadata)Salidas
Podemos ver impresiones de salida de la herramienta a la que se dirige la consulta, como “búsqueda web” o “almacenamiento de vectores”, y su respuesta correspondiente. Cuando hacemos preguntas sobre las elecciones generales, realiza una búsqueda en la web. Cuando realizamos una consulta relacionada con Régimen Fiscal (nuestro pdf), nos dirige a la tienda de vectores.
({'id': '1c86d1f8baa14f3484d1b99c9a53ab3a', 'function': {'name': 'web_search', 'arguments': '{"query": "General Elections 2024 of India results declaration date"}'}, 'type': 'function'})
({'id': 'c1356c914562418b943d50d61c2590ea', 'function': {'name': 'vectorstore', 'arguments': '{"query": "income tax slabs in New Tax Regime"}'}, 'type': 'function'})
FalsePaso 8: construir el nivelador de recuperación
Ahora, crearemos un clasificador binario de recuperación que calificará si los documentos recuperados son relevantes para la consulta o no.
### Retrieval Grader
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# Prompt
preamble = """You are a grader assessing relevance of a retrieved document to a user question. \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
# LLM with function call
llm = ChatCohere(model="command-r", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments, preamble=preamble)
grade_prompt = ChatPromptTemplate.from_messages(
(
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
)
)
retrieval_grader = grade_prompt | structured_llm_grader
question = "Old tax regime slabs"
docs = vectorstore_retriever.invoke(question)
doc_txt = docs(1).page_content
response = retrieval_grader.invoke({"question": question, "document": doc_txt})
print(response)Producción
binary_score="yes"Paso 9: Generador de respuestas
Ahora, construiremos el generador de respuestas, que generará una respuesta basada en la información obtenida del almacén de vectores o de la búsqueda web.
### Generate
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
import langchain
from langchain_core.messages import HumanMessage
# Preamble
preamble = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise."""
# LLM
llm = ChatCohere(model_name="command-r", temperature=0).bind(preamble=preamble)
# Prompt
prompt = lambda x: ChatPromptTemplate.from_messages(
(
HumanMessage(
f"Question: {x('question')} \nAnswer: ",
additional_kwargs={"documents": x("documents")},
)
)
)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"documents": docs, "question": question})
print(generation)Producción
Under the old tax regime in India, there were separate slab rates for different categories of taxpayers. Taxpayers with an income of up to 5 lakhs were eligible for a rebate.
Paso 10: cadena LLM para respaldo
Si la cadena RAG falla, esta cadena LLM será la cadena predeterminada para escenarios alternativos. Tenga en cuenta que aquí en el mensaje no tenemos la variable “documentos”.
### LLM fallback
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
import langchain
from langchain_core.messages import HumanMessage
# Preamble
preamble = """You are an assistant for question-answering tasks. Answer the question based upon your knowledge. Use three sentences maximum and keep the answer concise."""
# LLM
llm = ChatCohere(model_name="command-r", temperature=0).bind(preamble=preamble)
# Prompt
prompt = lambda x: ChatPromptTemplate.from_messages(
(HumanMessage(f"Question: {x('question')} \nAnswer: "))
)
# Chain
llm_chain = prompt | llm | StrOutputParser()
# Run
question = "Hi how are you?"
generation = llm_chain.invoke({"question": question})
print(generation)Producción
I don't have feelings as an ai chatbot, but I'm here to assist you with any questions or tasks you may have. How can I help you today?Paso 11- Construir el comprobador de alucinaciones
Ahora, construiremos un verificador de alucinaciones simple que dará una puntuación binaria de “Sí” o “No” en función de si el contexto recuperado se utiliza para generar una respuesta final libre de alucinaciones y basada en hechos.
### Hallucination Grader
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(
description="Answer is grounded in the facts, 'yes' or 'no'"
)
# Preamble
preamble = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts."""
# LLM with function call
llm = ChatCohere(model="command-r", temperature=0)
structured_llm_grader = llm.with_structured_output(
GradeHallucinations, preamble=preamble
)
# Prompt
hallucination_prompt = ChatPromptTemplate.from_messages(
(
# ("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
)
)
hallucination_grader = hallucination_prompt | structured_llm_grader
hallucination_grader.invoke({"documents": docs, "generation": generation})Paso 12: Construir el calificador de respuestas
Esto se comprobará más a fondo después de que el evaluador de alucinaciones transmita la respuesta a este nodo. Verificará si la respuesta generada es relevante para la pregunta.
### Answer Grader
# Data model
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses question."""
binary_score: str = Field(
description="Answer addresses the question, 'yes' or 'no'"
)
# Preamble
preamble = """You are a grader assessing whether an answer addresses / resolves a question \n
Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question."""
# LLM with function call
llm = ChatCohere(model="command-r", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeAnswer, preamble=preamble)
# Prompt
answer_prompt = ChatPromptTemplate.from_messages(
(
("human", "User question: \n\n {question} \n\n LLM generation: {generation}"),
)
)
answer_grader = answer_prompt | structured_llm_grader
answer_grader.invoke({"question": question, "generation": generation})Paso 13: creación de una herramienta de búsqueda web
Ahora, crearemos la herramienta de búsqueda web utilizando la API de Tavily.
### Search
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults()Paso 14: creación del flujo de trabajo de Graph
Ahora capturaremos el flujo de trabajo de nuestro Agente y definimos la clase para mantener el estado de cada punto de decisión.
Pasos involucrados en la creación de un gráfico usando LangGraph:
- Definir el estado del gráfico: esto representa el estado del gráfico.
- Crea el gráfico.
- Definir los nodos: aquí definimos las diferentes funciones asociadas con cada estado del flujo de trabajo.
- Agregue nodos al gráfico: aquí, agregue nuestros nodos y defina el flujo usando bordes y bordes condicionales.
- Establezca los puntos de entrada y final del gráfico.
from typing_extensions import TypedDict
from typing import List
class GraphState(TypedDict):
"""|
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List(str)Paso 15- Construyendo el gráfico
Ahora definimos los Nodos del gráfico y los bordes del gráfico.
from langchain.schema import Document
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state("question")
# Retrieval
documents = vectorstore_retriever.invoke(question)
return {"documents": documents, "question": question}
def llm_fallback(state):
"""
Generate answer using the LLM w/o vectorstore
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---LLM Fallback---")
question = state("question")
generation = llm_chain.invoke({"question": question})
return {"question": question, "generation": generation}
def generate(state):
"""
Generate answer using the vectorstore
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state("question")
documents = state("documents")
if not isinstance(documents, list):
documents = (documents)
# RAG generation
generation = rag_chain.invoke({"documents": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state("question")
documents = state("documents")
# Score each doc
filtered_docs = ()
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---WEB SEARCH---")
question = state("question")
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join((d("content") for d in docs))
web_results = Document(page_content=web_results)
return {"documents": web_results, "question": question}
### Edges ###
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE QUESTION---")
question = state("question")
source = question_router.invoke({"question": question})
# Fallback to LLM or raise error if no decision
if "tool_calls" not in source.additional_kwargs:
print("---ROUTE QUESTION TO LLM---")
return "llm_fallback"
if len(source.additional_kwargs("tool_calls")) == 0:
raise "Router could not decide source"
# Choose datasource
datasource = source.additional_kwargs("tool_calls")(0)("function")("name")
if datasource == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "web_search"
elif datasource == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
else:
print("---ROUTE QUESTION TO LLM---")
return "vectorstore"
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
question = state("question")
filtered_documents = state("documents")
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, WEB SEARCH---")
return "web_search"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state("question")
documents = state("documents")
generation = state("generation")
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
print("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
Paso 16: construir el gráfico Lang
Agregue los nodos en el flujo de trabajo y los bordes condicionales. Primero, agregue todos los nodos, luego agregue los bordes y defina los bordes con condiciones.
import pprint
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("web_search", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # rag
workflow.add_node("llm_fallback", llm_fallback) # llm
# Build graph
workflow.set_conditional_entry_point(
route_question,
{
"web_search": "web_search",
"vectorstore": "retrieve",
"llm_fallback": "llm_fallback",
},
)
workflow.add_edge("web_search", "generate")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"web_search": "web_search",
"generate": "generate",
},
)
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate", # Hallucinations: re-generate
"not useful": "web_search", # Fails to answer question: fall-back to web-search
"useful": END,
},
)
workflow.add_edge("llm_fallback", END)
# Compile
app = workflow.compile()
Paso 17: instalar bibliotecas para visualizar el gráfico
Ahora instalaremos bibliotecas adicionales para visualizar el gráfico del flujo de trabajo.
!apt-get install python3-dev graphviz libgraphviz-dev pkg-config
!pip install pygraphvizPaso 18: visualizar el gráfico
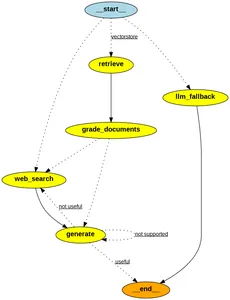
Los bordes discontinuos son bordes condicionales, mientras que los bordes sólidos son bordes directos no condicionales.
from IPython.display import Image
Image(app.get_graph().draw_png())
Paso 19: ejecutar el flujo de trabajo de Lang Graph
Ahora ejecutamos nuestro flujo de trabajo para verificar si proporciona el resultado deseado según el flujo de trabajo definido.
Ejemplo 1: consulta de búsqueda web
# Execute
inputs = {
"question": "Give the dates of different phases of general election 2024 in India?"
}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint.pprint(f"Node '{key}':")
# Optional: print full state at each node
pprint.pprint("\n---\n")
# Final generation
pprint.pprint(value("generation"))Producción
---ROUTE QUESTION---
---ROUTE QUESTION TO RAG---
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, WEB SEARCH---
"Node 'grade_documents':"
'\n---\n'
---WEB SEARCH---
"Node 'web_search':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('The 2024 Indian general election will take place in seven phases, with '
'voting scheduled for: April 19, April 26, May 7, May 13, May 20, May 25, and '
'June 1.')Ejemplo 2: consulta de búsqueda de vectores relevante
# Run
inputs = {"question": "What are the slabs of new tax regime?"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint.pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value("keys"), indent=2, width=80, depth=None)
pprint.pprint("\n---\n")
# Final generation
pprint.pprint(value("generation"))
Producción
---ROUTE QUESTION---
---ROUTE QUESTION TO RAG---
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'grade_documents':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('Here are the slabs of the new tax regime for the given years:\n'
'\n'
'## FY 2022-23 (AY 2023-24)\n'
'- Up to Rs 2,50,000: Nil\n'
'- Rs 2,50,001 to Rs 5,00,000: 5%\n'
'- Rs 5,00,001 to Rs 7,50,000: 10%\n'
'- Rs 7,50,001 to Rs 10,00,000: 15%\n'
'- Rs 10,00,001 to Rs 12,50,000: 20%\n'
'- Rs 12,50,001 to Rs 15,00,000: 25%\n'
'- Rs 15,00,001 and above: 30%\n'
'\n'
'## FY 2023-24 (AY 2024-25)\n'
'- Up to Rs 3,00,000: Nil\n'
'- Rs 3,00,000 to Rs 6,00,000: 5% on income above Rs 3,00,000\n'
'- Rs 6,00,000 to Rs 900,000: Rs. 15,000 + 10% on income above Rs 6,00,000\n'
'- Rs 9,00,000 to Rs 12,00,000: Rs. 45,000 + 15% on income above Rs 9,00,000\n'
'- Rs 12,00,000 to Rs 1500,000: Rs. 90,000 + 20% on income above Rs '
'12,00,000\n'
'- Above Rs 15,00,000: Rs. 150,000 + 30% on income above Rs 15,00,000')Conclusión
LangGraph es una herramienta versátil para desarrollar aplicaciones complejas con estado que emplean LLM. Al comprender sus ideas esenciales y trabajar con ejemplos básicos, los principiantes pueden utilizar sus posibilidades para sus proyectos. Es fundamental concentrarse en mantener los estados, manejar los bordes condicionales y garantizar que el gráfico no tenga nodos sin salida.
Desde mi punto de vista, es más ventajoso que los agentes ReAct ya que podemos establecer un control total del flujo de trabajo en lugar de que el agente tome las decisiones.
Conclusiones clave
- Aprendimos sobre LangGraph y sus implementaciones.
- Aprendimos cómo implementarlo utilizando nuevas herramientas como Cohere LLM, Tavily.
API de búsqueda - Pudimos comprender la diferencia entre ReAct Agent y Lang Graph.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Preguntas frecuentes
R. Sí, Cohere actualmente permite llamadas API gratuitas con tarifa limitada para investigación.
y creación de prototipos aquí.
R. Está más optimizado para búsquedas con RAG y LLM en comparación con
otras API de búsqueda convencionales.
R. LangGraph ofrece compatibilidad con los agentes LangChain existentes, lo que permite a los desarrolladores modificar los componentes internos de AgentExecutor más fácilmente. El estado del gráfico incluye conceptos familiares como entrada, historial_de_chat, pasos_intermedios y resultado_del_agente.1
R. Podemos mejorar aún más esta estrategia RAG adaptativa integrando Self –
Reflexión en RAG, que recupera documentos de forma iterativa con razonamiento propio y
refina la respuesta de forma iterativa.
A. Cohere ofrece muchos modelos diferentes; las versiones iniciales fueron – Command y Command R. Command R Plus es el último modelo multilingüe con una ventana de contexto más grande de 128k. Además de estos modelos LLM, también tiene un modelo de integración: Empotrary otro modelo de clasificación Reclasificar.




