
La IA generativa es un tipo de inteligencia artificial (IA) que se puede utilizar para crear contenido nuevo, incluidas conversaciones, historias, imágenes, videos y música. Como toda IA, la IA generativa funciona mediante el uso de modelos de aprendizaje automático: modelos muy grandes que están previamente entrenados con grandes cantidades de datos llamados modelos básicos (FM). Los FM están capacitados en un amplio espectro de datos generalizados y sin etiquetar. Son capaces de realizar una amplia variedad de tareas generales con un alto grado de precisión basándose en indicaciones de entrada. Los modelos de lenguaje grande (LLM) son una clase de FM. Los LLM se centran específicamente en tareas basadas en el lenguaje, como resúmenes, generación de texto, clasificación, conversaciones abiertas y extracción de información.
Los FM y LLM, aunque estén previamente capacitados, pueden continuar aprendiendo a partir de entradas de datos o indicaciones durante la inferencia. Esto significa que puede desarrollar resultados integrales a través de indicaciones cuidadosamente seleccionadas. Un mensaje es la información que se pasa a un LLM para obtener una respuesta. Esto incluye el contexto de la tarea, los datos que pasa al modelo, el historial de conversaciones y acciones, instrucciones e incluso ejemplos. El proceso de diseñar y perfeccionar indicaciones para obtener respuestas específicas de estos modelos se denomina ingeniería de indicaciones.
Si bien los LLM son buenos para seguir las instrucciones del mensaje, a medida que una tarea se vuelve compleja, se sabe que abandonan tareas o las realizan sin la precisión deseada. Los LLM pueden manejar mejor tareas complejas cuando las dividen en subtareas más pequeñas. Esta técnica de dividir una tarea compleja en subtareas se llama encadenamiento rápido. Con el encadenamiento de indicaciones, usted construye un conjunto de subtareas más pequeñas como indicaciones individuales. Juntas, estas subtareas conforman la compleja tarea general. Para realizar la tarea general, su aplicación envía cada subtarea al LLM en un orden predefinido o de acuerdo con un conjunto de reglas.
Si bien la IA generativa puede crear contenido muy realista, incluidos texto, imágenes y videos, también puede generar resultados que parecen plausibles pero que son verificablemente incorrectos. Incorporar el juicio humano es crucial, especialmente en escenarios de toma de decisiones complejos y de alto riesgo. Esto implica construir un proceso humano en el que los humanos desempeñen un papel activo en la toma de decisiones junto con el sistema de inteligencia artificial.
En esta publicación de blog, aprenderá sobre el encadenamiento de indicaciones, cómo dividir una tarea compleja en varias tareas para usar el encadenamiento de indicaciones con un LLM en un orden específico y cómo involucrar a un humano para que revise la respuesta generada por el LLM.
Resumen de ejemplo
Para ilustrar este ejemplo, considere una empresa minorista que permite a los compradores publicar reseñas de productos en su sitio web. Al responder con prontitud a esas revisiones, la empresa demuestra su compromiso con los clientes y fortalece las relaciones con ellos.
Figura 1: Opinión y respuesta del cliente
La aplicación de ejemplo de esta publicación automatiza el proceso de respuesta a las opiniones de los clientes. Para la mayoría de las revisiones, el sistema genera automáticamente una respuesta mediante un LLM. Sin embargo, si la revisión o la respuesta generada por el LLM contiene incertidumbre sobre la toxicidad o el tono, el sistema la marca para que la revise un revisor humano. Luego, el revisor humano evalúa el contenido marcado para tomar la decisión final sobre la toxicidad o el tono.
La aplicación utiliza una arquitectura basada en eventos (EDA), un potente patrón de diseño de software que puede utilizar para crear sistemas desacoplados comunicándose a través de eventos. Tan pronto como se crea la reseña del producto, el sistema de recepción de reseñas utiliza amazon EventBridge para enviar un evento de publicación de una reseña del producto, junto con el contenido de la reseña real. El evento inicia un flujo de trabajo de AWS Step Functions. El flujo de trabajo pasa por una serie de pasos que incluyen la generación de contenido mediante un LLM y la participación de la toma de decisiones humana.
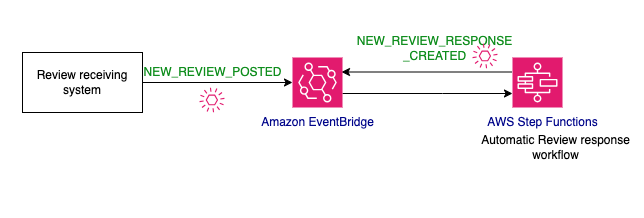
Figura 2: Revisar el flujo de trabajo
El proceso de generar una respuesta a una reseña incluye evaluar la toxicidad del contenido de la reseña, identificar el sentimiento, generar una respuesta e involucrar a un aprobador humano. Naturalmente, esto encaja en un tipo de aplicación de flujo de trabajo porque es un proceso único que contiene múltiples pasos secuenciales junto con la necesidad de administrar el estado entre pasos. Por lo tanto, el ejemplo utiliza Step Functions para la orquestación del flujo de trabajo. Estos son los pasos del flujo de trabajo de respuesta a reseñas.
- Detecte si el contenido de la reseña tiene información dañina mediante la API amazon Comprehend DetectToxicContent. El API responde con la puntuación de toxicidad que representa la puntuación de confianza general de la detección entre 0 y 1, donde una puntuación más cercana a 1 indica una alta toxicidad.
- Si la toxicidad de la revisión está en el rango de 0,4 a 0,6, envíe la revisión a un revisor humano para que tome la decisión.
- Si la toxicidad de la reseña es superior a 0,6 o el revisor considera que la reseña es perjudicial, publíquela.
HARMFUL_CONTENT_DETECTEDmensaje. - Si la toxicidad de la reseña es inferior a 0,4 o el revisor aprueba la reseña, busque primero el sentimiento de la reseña y luego genere la respuesta al comentario de la reseña. Ambas tareas se logran utilizando un modelo de IA generativa.
- Repita la detección de toxicidad a través de Comprehend API para la respuesta generada por LLM.
- Si la toxicidad de la respuesta generada por LLM está en el rango de 0,4 a 0,6, envíe la respuesta generada por LLM a un revisor humano.
- Si se determina que la respuesta generada por LLM no es tóxica, publíquela
NEW_REVIEW_RESPONSE_CREATEDevento. - Si se descubre que la respuesta generada por LLM es tóxica, publíquela
RESPONSE_GENERATION_FAILEDevento.
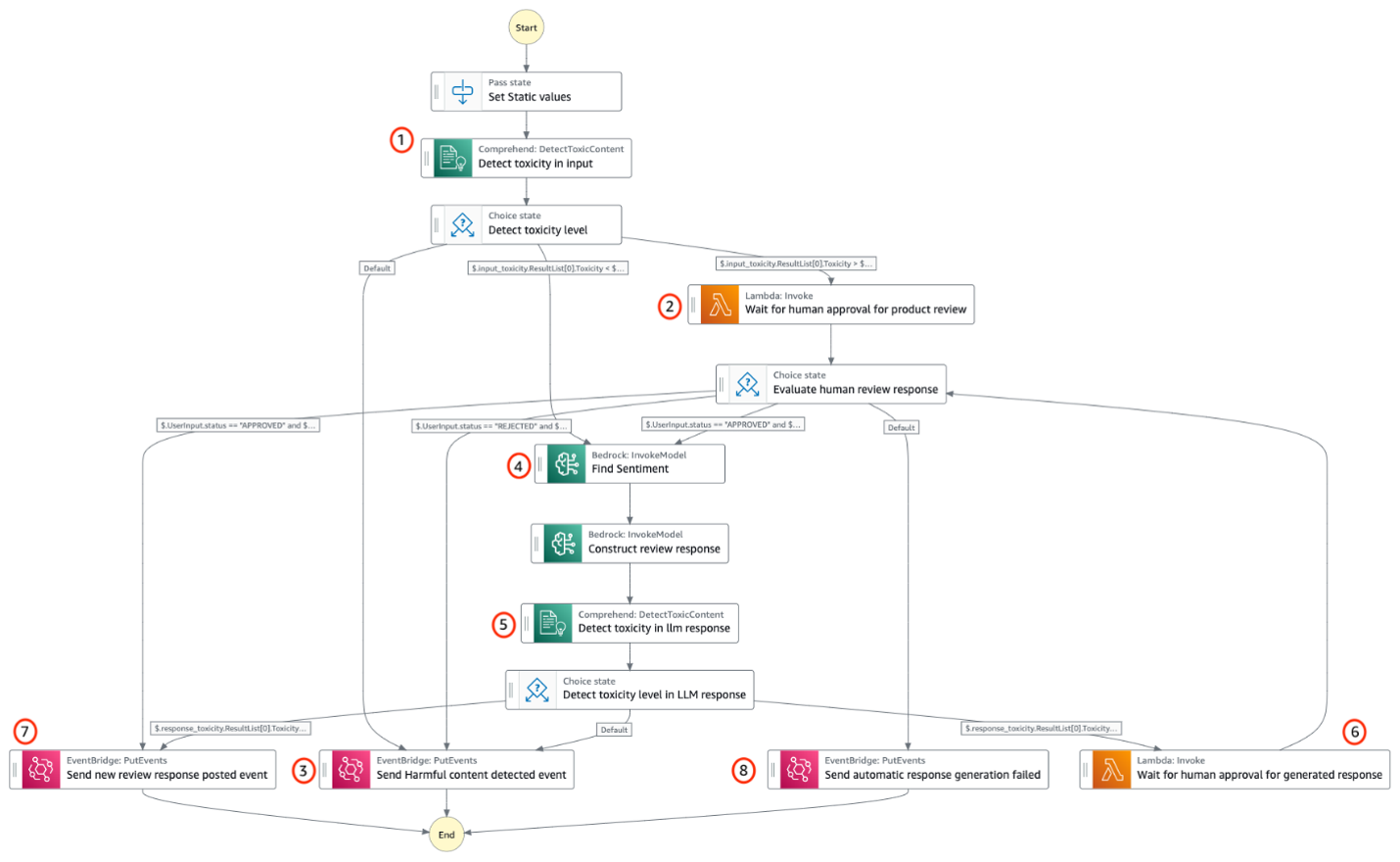
Figura 3: flujo de trabajo de respuesta y evaluación de revisión de productos
Empezando
Utilice las instrucciones del repositorio de GitHub para implementar y ejecutar la aplicación.
Encadenamiento rápido
El encadenamiento rápido simplifica el problema para el LLM al dividir tareas únicas, detalladas y monolíticas en tareas más pequeñas y manejables. Algunos LLM, pero no todos, son buenos para seguir todas las instrucciones en una sola indicación. La simplificación da como resultado la redacción de indicaciones enfocadas para el LLM, lo que lleva a una respuesta más consistente y precisa. El siguiente es un ejemplo de mensaje único ineficaz.
Lea la reseña del cliente a continuación, filtre el contenido dañino y proporcione su opinión sobre el sentimiento general en formato JSON. Luego, cree una respuesta de correo electrónico basada en el sentimiento que determine y adjunte el correo electrónico en formato JSON. Según el sentimiento, escriba un informe sobre cómo se puede mejorar el producto.
Para hacerlo más efectivo, puede dividir el mensaje en varias subtareas:
- Filtrar contenido dañino
- Obtenga el sentimiento
- Generar la respuesta al correo electrónico
- Escribe un reporte
Incluso puedes ejecutar algunas de las tareas en paralelo. Al dividirse en indicaciones específicas, se obtienen los siguientes beneficios:
- Aceleras todo el proceso. Puede manejar tareas en paralelo, utilizar diferentes modelos para diferentes tareas y enviar una respuesta al usuario en lugar de esperar a que el modelo procese un mensaje más grande durante un tiempo considerablemente más largo.
- Mejores indicaciones proporcionan mejores resultados. Con indicaciones enfocadas, puede diseñar las indicaciones agregando contexto relevante adicional, mejorando así la confiabilidad general de la salida.
- Pasas menos tiempo desarrollándote. La ingeniería rápida es un proceso iterativo. Tanto la depuración de llamadas de LLM para solicitudes detalladas como el perfeccionamiento de solicitudes más amplias para lograr precisión requieren mucho tiempo y esfuerzo. Las tareas más pequeñas le permiten experimentar y perfeccionar mediante iteraciones sucesivas.
Step Functions es una opción natural para crear encadenamiento de mensajes porque ofrece múltiples formas diferentes de encadenar mensajes: secuencialmente, en paralelo e iterativamente pasando los datos de estado de un estado a otro. Considere la situación en la que ha creado el flujo de trabajo de encadenamiento de solicitudes de respuesta a reseñas de productos y ahora desea evaluar las respuestas de diferentes LLM para encontrar la mejor opción mediante un conjunto de pruebas de evaluación. El conjunto de pruebas de evaluación consta de cientos de revisiones de productos de prueba, una respuesta de referencia a la revisión y un conjunto de reglas para evaluar la respuesta de LLM frente a la respuesta de referencia. Puede automatizar la actividad de evaluación utilizando un flujo de trabajo de Step Functions. La primera tarea del flujo de trabajo le pide al LLM que genere una respuesta de revisión para la revisión del producto. Luego, la segunda tarea le pide al LLM que compare la respuesta generada con la respuesta de referencia utilizando las reglas y genere una puntuación de evaluación. Según la puntuación de evaluación de cada revisión, puede decidir si el LLM supera sus criterios de evaluación o no. Puede utilizar el estado del mapa en Step Functions para ejecutar las evaluaciones de cada revisión en su conjunto de pruebas de evaluación en paralelo. Mira esto amazon-bedrock-serverless-prompt-chaining” target=”_blank” rel=”noopener”>repositorio para obtener ejemplos de encadenamiento más rápidos.
Humano en el circuito
Involucrar la toma de decisiones humana en el ejemplo le permite mejorar la precisión del sistema cuando no se puede determinar si la toxicidad del contenido es segura o dañina. Puede implementar la revisión humana dentro del flujo de trabajo de Step Functions usando Esperar una devolución de llamada con la integración del token de tarea. Cuando utiliza esta integración con cualquier API del SDK de AWS compatible, la tarea de flujo de trabajo genera un token único y luego se detiene hasta que se devuelve el token. Puede utilizar esta integración para incluir la toma de decisiones humana, llamar a un sistema local heredado, esperar a que se completen tareas de larga duración, etc.
En la aplicación de muestra, la tarea de enviar correo electrónico para aprobación incluye una espera por el token de devolución de llamada. Invoca una función de AWS Lambda con un token y espera el token. La función Lambda crea un mensaje de correo electrónico junto con el enlace a una URL de amazon API Gateway. Luego, Lambda utiliza amazon Simple Notification Service (amazon SNS) para enviar un correo electrónico a un revisor humano. El revisor revisa el contenido y acepta o rechaza el mensaje seleccionando el enlace apropiado en el correo electrónico. Esta acción invoca la API SendTaskSuccess de Step Functions. La API devuelve el token de tarea y un mensaje de estado sobre si se acepta o rechaza la revisión. Step Functions recibe el token, reanuda la tarea de envío de correo electrónico para aprobación y luego pasa el control al estado de elección. El estado de elección decide si se acepta o rechaza la revisión según el mensaje de estado.
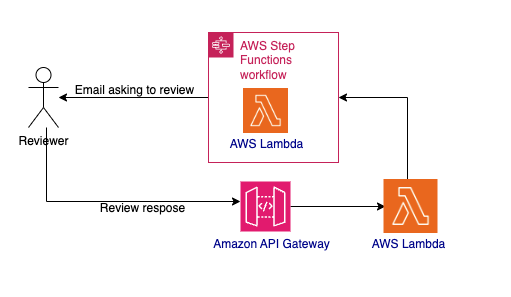
Figura 4: Flujo de trabajo humano-in-the-loop
Arquitectura basada en eventos
EDA permite construir arquitecturas extensibles. Puede agregar consumidores en cualquier momento suscribiéndose al evento. Por ejemplo, considere moderar imágenes y videos adjuntos a la reseña de un producto además del contenido del texto. También debe escribir código para eliminar las imágenes y los videos si se consideran dañinos. Puede agregar un consumidor, el sistema de moderación de imágenes, al NEW_REVIEW_POSTED evento sin realizar ningún cambio de código en los consumidores o productores de eventos existentes. El desarrollo del sistema de moderación de imágenes y el sistema de respuesta a revisiones para eliminar imágenes dañinas puede realizarse en paralelo, lo que a su vez mejora la velocidad de desarrollo.
Cuando el flujo de trabajo de moderación de imágenes encuentra contenido tóxico, publica un HARMFULL_CONTENT_DETECTED evento. El evento puede ser procesado por un sistema de respuesta a revisión que decide qué hacer con el evento. Al desacoplar sistemas a través de eventos, se obtienen muchas ventajas, incluida una velocidad de desarrollo mejorada, escalamiento variable y tolerancia a fallas.
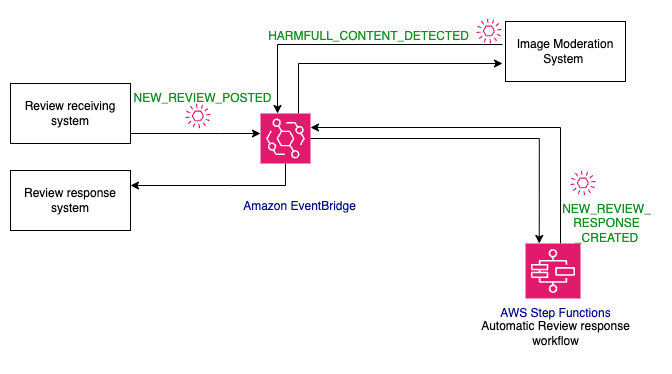
Figura 5: Flujo de trabajo basado en eventos
Limpiar
Utilice las instrucciones del repositorio de GitHub para eliminar la aplicación de muestra.
Conclusión
En esta publicación de blog, aprendió cómo crear una aplicación de IA generativa con encadenamiento rápido y un proceso de revisión humana. Aprendiste cómo ambas técnicas mejoran la precisión y seguridad de una aplicación de IA generativa. También aprendió cómo las arquitecturas basadas en eventos junto con los flujos de trabajo pueden integrar aplicaciones existentes con aplicaciones de IA generativa.
Visita Tierra sin servidor para obtener más flujos de trabajo de Step Functions.
Sobre los autores
 Veda Raman es un arquitecto senior de soluciones especializado en inteligencia artificial generativa y aprendizaje automático con sede en AWS. Veda trabaja con los clientes para ayudarlos a diseñar aplicaciones de aprendizaje automático eficientes, seguras y escalables. Veda se especializa en servicios de inteligencia artificial generativa como amazon Bedrock y amazon Sagemaker.
Veda Raman es un arquitecto senior de soluciones especializado en inteligencia artificial generativa y aprendizaje automático con sede en AWS. Veda trabaja con los clientes para ayudarlos a diseñar aplicaciones de aprendizaje automático eficientes, seguras y escalables. Veda se especializa en servicios de inteligencia artificial generativa como amazon Bedrock y amazon Sagemaker.
 Uma Ramadoss es Arquitecto Principal de Soluciones en amazon Web Services, enfocado en los Servicios Serverless y de Integración. Es responsable de ayudar a los clientes a diseñar y operar aplicaciones nativas de la nube basadas en eventos utilizando servicios como Lambda, API Gateway, EventBridge, Step Functions y SQS. Uma tiene experiencia práctica en la dirección de proyectos de entrega sin servidor a escala empresarial y posee un sólido conocimiento práctico de la arquitectura de nube, microservicios y basada en eventos.
Uma Ramadoss es Arquitecto Principal de Soluciones en amazon Web Services, enfocado en los Servicios Serverless y de Integración. Es responsable de ayudar a los clientes a diseñar y operar aplicaciones nativas de la nube basadas en eventos utilizando servicios como Lambda, API Gateway, EventBridge, Step Functions y SQS. Uma tiene experiencia práctica en la dirección de proyectos de entrega sin servidor a escala empresarial y posee un sólido conocimiento práctico de la arquitectura de nube, microservicios y basada en eventos.






{kind=link}