NEWSLETTER
NEWSLETTER
Retrieval-Augmented Generation is a technique that enhances the capabilities of large language models by integrating information retrieval processes into their operation. This approach allows LLMs to pull in relevant data from external knowledge bases, ensuring that the responses generated are more accurate, up-to-date, and contextually relevant. Corrective RAG (CRAG) is an advanced strategy within the Retrieval-Augmented Generation (RAG) framework that focuses on improving the accuracy and relevance of generated responses by incorporating mechanisms for self-reflection and self-grading of retrieved documents.
Learning Objectives
- Understand the core mechanism of Corrective Retrieval-Augmented Generation (CRAG) and its integration with web search.
- Learn how CRAG evaluates and improves the relevance of retrieved documents using binary scoring and question rewriting.
- Explore the key differences between Corrective RAG and traditional RAG frameworks.
- Gain hands-on experience in implementing CRAG using Python, LangChain, and Tavily.
- Develop practical skills in setting up evaluators, query rewriters, and web search tools to enhance retrieval and response accuracy.
This article was published as a part of the Data Science Blogathon.
Mechanism Behind Corrective RAG (CRAG)
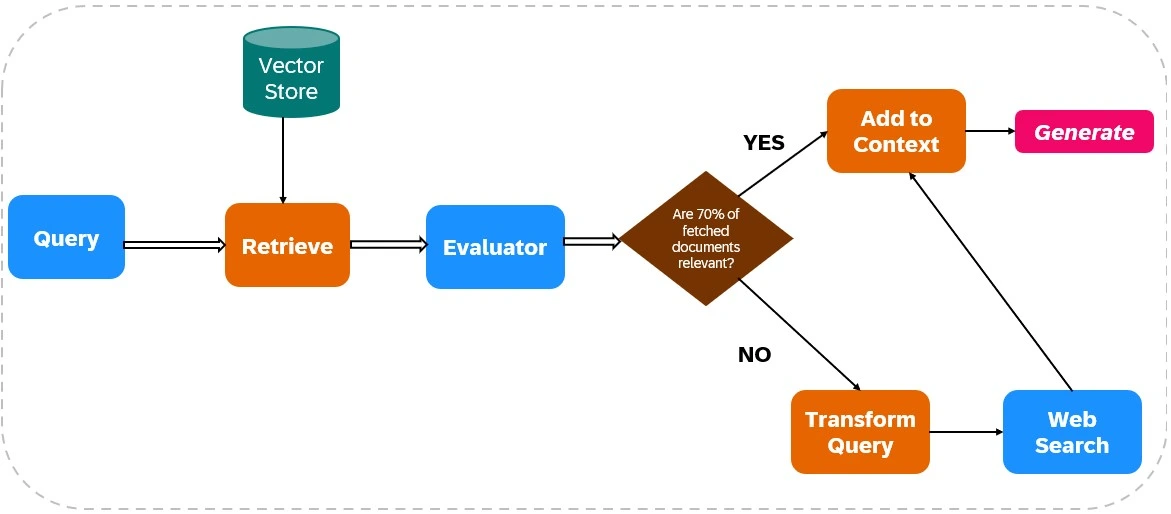
Corrective Retrieval Augmented Generation (Corrective RAG or CRAG) is an advanced framework that enhances the reliability of language model outputs by integrating web search capabilities into its retrieval and generation processes. Here’s a breakdown of its mechanism, as illustrated in Figure 1.
Retrieval of Relevant Documents
- Data Ingestion: The process begins with loading relevant data into an index, setting up the necessary tools for web searches, such as Tavily ai, to facilitate real-time information retrieval.
- Initial Retrieval: The system retrieves documents based on the user’s query from a static knowledge base.
Relevance Evaluation
An evaluator assesses the relevance of the retrieved documents. This evaluation is crucial as it determines the next steps based on the quality of the retrieved information:
- If for instance,more than 70% of the documents are deemed irrelevant , corrective actions are triggered. Else reponse generation takes place from the retrieved relevant documents.
Supplementing with Web Search
If the evaluator finds that the retrieved documents are insufficient (i.e., below the relevance threshold), CRAG employs web search to supplement the initial retrieval. This step involves:
- Query Transformation: The original query may be transformed to better align with web search parameters, enhancing the chances of retrieving relevant information.
- Web Search Execution: Utilizing web search tools like Tavily ai, CRAG fetches additional data from broader sources, ensuring access to up-to-date and diverse information.
Response Generation
After gathering relevant data from both initial retrieval and web searches, CRAG synthesizes this information to generate a coherent and contextually accurate response.
How is Corrective RAG different from Traditional RAG?
Corrective RAG incorporates active error-checking and refinement processes. It evaluates the relevance and accuracy of retrieved documents before they are used in generation, reducing the likelihood of generating incorrect or misleading information. Traditional RAG relies on retrieved documents to assist in text generation but does not actively verify or correct the information.
Corrective RAG often integrates real-time web search capabilities, allowing it to fetch the most current and relevant information dynamically during the retrieval phase. Traditional RAG typically relies on a static knowledge base which can result in outdated information being used for response generation.
Corrective RAG is therefore particularly beneficial for applications requiring high accuracy and real-time data integration, such as customer support systems, legal compliance, and financial analytics.
Hands-on Implementation of Corrective RAG
Now we will dive into the practical steps of implementing Corrective RAG, where we leverage advanced tools and frameworks to enhance the reliability and accuracy of ai-generated responses through real-time retrieval and self-correction mechanisms.
Step1: Installing the Necessary Libraries
Prepare your workspace by installing the necessary tools and libraries for efficient model development and execution.
!pip install tiktoken langchain-openai langchainhub chromadb langchain langgraph tavily-python
!pip install -qU pypdf langchain_communityStep2: Defining the API Keys
Generate and securely define your API keys to enable seamless communication between your application and external services.
import os
os.environ("TAVILY_API_KEY") = ""
os.environ("OPENAI_API_KEY") = ""Step3: Importing the Necessary Libraries
Import the required libraries to access essential functions and modules needed for your project’s implementation.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List
from typing_extensions import TypedDict
from langchain.schema import Document
from langgraph.graph import END, StateGraph, STARTStep4: Chunking the Document and Creating the Retriever
Divide the document into manageable chunks and set up a retriever to efficiently retrieve relevant information from the chunks.
Firstly load the PDF document in the current working folder. We are using this document here.
file_path = "Brochure_Basic-Creative-coffee-recipes.pdf"
loader = PyPDFLoader(file_path)
docs = loader.load()
docs_list = (item for sublist in docs for item in sublist)
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()- PDF Loading: The PyPDFLoader extracts text from the PDF file (Brochure_Basic-Creative-coffee-recipes.pdf).
- Flattening Documents: The text from the PDF is loaded into a list, and any nested lists are flattened.
- Text Splitting: The RecursiveCharacterTextSplitter splits the documents into smaller chunks, with or without overlap.
- Vector Store Creation: OpenAI’s model transforms the text chunks into vector embeddings and stores them in a vector database (Chroma).
- Retriever: We create a retriever that allows us to query the vector store for semantically similar documents.
Step5: Setting Up the RAG Chain
Configure the RAG chain to link the document retrieval process with the generative model for accurate and contextually relevant responses.
# Prompt
rag_prompt = hub.pull("rlm/rag-prompt")
# LLM
rag_llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
# Chain
rag_chain = rag_prompt | rag_llm | StrOutputParser()
print(rag_prompt.messages(0).prompt.template)- rag_prompt: The system pulls a predefined prompt template related to retrieval-augmented generation (RAG) from the hub. This prompt will instruct the language model to evaluate retrieved documents and generate a response based on the documents.
- rag_llm: An instance of OpenAI’s GPT-4 model is created with deterministic output (temperature=0).
- rag_chain: The chain connects the rag_prompt, the rag_llm, and the StrOutputParser. This chain will process the input (retrieved documents and user questions) and generate a formatted output.
The following is the output of the prompt template:
You are an assistant for question-answering tasks. Use the following pieces of
retrieved context to answer the question. If you don't know the answer, just say
that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
Step6: Setting Up an Evaluator
Integrate an evaluator to assess the quality of generated responses, ensuring they meet the desired standards of accuracy and relevance.
### Retrieval Evaluator
class Evaluator(BaseModel):
"""Classify retrieved documents based on its relevance to the question."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM with function call
evaluator_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
output_llm_evaluator = evaluator_llm.with_structured_output(Evaluator)
# Prompt
system = """You are tasked with evaluating the relevance of a retrieved document to a user's question. \n If the document contains keywords or semantic content related to the question, mark it as relevant. \n Output a binary score: 'yes' if the document is relevant, or 'no' if it is not"""
retrieval_evaluator_prompt = ChatPromptTemplate.from_messages(
(
("system", system),
("human", "Retrieved document: \\n\\n {document} \\n\\n User question: {question}"),
)
)
retrieval_grader = retrieval_evaluator_prompt | output_llm_evaluator The class Evaluator defines a binary_score field (either ‘yes’ or ‘no’) to indicate whether a retrieved document is relevant to a user’s question.
The system initializes a GPT model (gpt-4o-mini) with zero temperature to ensure deterministic output.
The system configures the model to return structured output that matches the Evaluator class.
A system prompt is created to guide the model. It asks the model to evaluate a document’s relevance based on whether it contains keywords or semantic content related to the user’s question, and to output a binary score (‘yes’ or ‘no’). A human prompt provides the context: a retrieved document and a user question.
The system prompt combines with the evaluator model to form a complete process (retrieval_grader) that evaluates the document’s relevance.
Step7: Setting Up A Query Rewriter
Configure a query rewriter to optimize and refine user queries, enhancing the effectiveness of information retrieval in the RAG system.
question_rewriter_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Prompt
system = """You are a question rewriter who improves input questions to make them more effective for web search. \n Analyze the question and focus on the underlying semantic intent to craft a better version."""
re_write_prompt = ChatPromptTemplate.from_messages(
(
("system", system),
(
"human",
"Here is the initial question: \\n\\n {question} \\n Formulate an improved question.",
),
)
)
question_rewriter = re_write_prompt | question_rewriter_llm | StrOutputParser()A GPT model (gpt-4o-mini) is initialized with a temperature of 0 for deterministic (non-random) output.
A system prompt is created to instruct the model. It asks the model to improve an input question by focusing on the underlying semantic intent to make it more effective for web search.
A human prompt provides the actual question to be rewritten, asking the model to formulate an improved version.
The system and human prompts rewrite the input question by chaining with the GPT model and the output parser (StrOutputParser) to form a complete process (question_rewriter).
Step8: Setting Up Web Search
Integrate a web search capability to expand the knowledge base, allowing the RAG system to fetch real-time, relevant information from the internet.
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=3)The web search tool is set up here using Tavily.
Step9: Setting Up the Graph State for LangGraph
Initialize and configure the graph state for LangGraph to manage complex relationships and enable efficient retrieval and processing of data within the RAG system.
class GraphState(TypedDict):
question: str
generation: str
web_search: str
documents: List(str)The system designs a GraphState to store data as it transitions between nodes in the workflow. This state will contain all relevant variables, including the user’s question, retrieved documents, and generated answers.
Step10: Setting Up the Function Nodes
Define and configure the individual function nodes, each representing a specific task or operation in the RAG pipeline, ensuring they align with the overall workflow.
Function for Retrieving Relevant Documents
def retrieve(state):
question = state("question")
# Retrieval
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}Generating Answers From the Retrieved Documents
def generate(state):
question = state("question")
documents = state("documents")
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}Function for Evaluating the Retrieved Documents
def evaluate_documents(state):
question = state("question")
documents_all = state("documents")
# Score each doc
docs_filtered = ()
web_search = "No"
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
docs_filtered .append(d)
else:
continue
if len(docs_filtered) / len(documents_all) <= 0.7:
web_search = "Yes"
return {"documents": docs_filtered, "question": question, "web_search": web_search}The function takes in a state dictionary, which includes the user’s question and a list of documents.
It loops through each document and scores its relevance using the retrieval_grader function. We add a document to the docs_filtered list if we deem it relevant (with a “yes” score).
If less than or equal to 70% of the documents are relevant, the web_search flag is set to “Yes”.
The function returns a dictionary containing the filtered documents, the original question, and the web_search decision (“Yes” or “No”).
Function for Transforming the User Query For Better Retrieval
def transform_query(state):
question = state("question")
documents_all = state("documents")
# Re-write question
transformed_question = question_rewriter.invoke({"question": question})
return {"documents": documents_all , "question": transformed_question }The transform_query function rewrites the user’s question using a question rewriter. It returns the original documents along with the transformed question
Function for Web Searching
def web_search(state):
question = state("question")
documents_all = state("documents")
# Web search
docs = web_search_tool.invoke({"query": question})
#Fetch results from web
web_results = "\\n".join((d("content") for d in docs))
web_results = Document(page_content=web_results)
#Append the results from the web to the documents
documents_all.append(web_results)
return {"documents": documents_all, "question": question}The web_search function performs a web search based on the user’s question and fetches the results. It appends the web search results to the original documents and returns the updated documents along with the question.
Function for Deciding Next Step
Whether to generate or transforming the query for web search.
def decide_next_step(state):
web_search = state("web_search")
if web_search == "Yes":
return "transform_query"
else:
return "generate"The decide_next_step function checks if a web search is needed. If the web_search variable is yes, it returns “transform_query”; otherwise, it returns “generate”.
Step11: Connecting all the Function Nodes & Adding Edges
Establish connections between all function nodes and add edges to create a cohesive flow of data and operations, ensuring smooth interaction within the RAG system.
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", evaluate_documents) # evaluate documents
workflow.add_node("generate", generate) # generate
workflow.add_node("transform_query", transform_query) # transform_query
workflow.add_node("web_search_node", web_search) # web search
# Adding the Edges
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_next_step,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "web_search_node")
workflow.add_edge("web_search_node", "generate")
workflow.add_edge("generate", END)
# Compile
app = workflow.compile()A StateGraph object named workflow is created using GraphState.
We add five nodes to the workflow, with each representing a specific function.
- retrieve: Retrieves data or documents.
- grade_documents: Evaluates the retrieved documents.
- generate: Generates output based on previous steps.
- transform_query: Transforms input queries for further processing.
- web_search_node: Conducts web searches.
Edge Creation
We add edges to define the sequence and conditions under which the nodes execute.
- The workflow starts from a predefined START node and moves to the “retrieve” node.
- After retrieving, it proceeds to “grade_documents”.
- Conditional edges are established from “grade_documents” to either “transform_query” or “generate”, based on the outcome of the decide_next_step function.
- The flow continues from “transform_query” to “web_search_node”, then to “generate”, and finally ends at an END node.
The workflow is compiled into an application object named app.
Step12: Output using Corrective RAG
from pprint import pprint
inputs = {"question": "What is the difference between Flat white and cappuccino?"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
pprint(value, indent=2, width=80, depth=None)
pprint("\\n---\\n")
# Final generation
pprint(value("generation"))This code streams the results of the workflow (app) processing the input question. It displays the output at each node, transforming the input step by step, and finally presents the generated answer after processing the entire workflow.
Final Output from Corrective RAG
The key differences between a flat white and a cappuccino lie in their milk '
'texture and proportions. A flat white features microfoam milk with a '
'stronger coffee flavor and less foam, while a cappuccino has a thick layer '
'of foam, resulting in a lighter, frothier drink. Additionally, the ratio of '
'espresso to milk differs, with a cappuccino having a 1:1 ratio compared to '
'the 1:3 ratio in a flat white.
The output from Corrective RAG shows that the system fetched the exact answer from the web after the LLM evaluator determined all documents from the PDF to be irrelevant.
Let us now check what a traditional RAG would have given as response to the same question.
question = "How is Flat white different from cappuccino?"
generation = rag_chain.invoke({"context": docs, "question": question})
print("Final answer: %s" % generation)Final Output from Traditional RAG
Final answer: A flat white is prepared by adding coffee first, followed by warm
milk, with the milk foam lying under the crema, which gives it a smooth texture. In
contrast, a cappuccino is made by preparing the milk first, then adding the coffee,
resulting in a thick layer of milk foam on top. This difference in preparation
methods affects the texture and flavor profile of each drink.
The traditional RAG fetches the information from the document, but it does not provide the correct response. In scenarios like these, Corrective RAG is immensely helpful as it improves the accuracy of the responses.
Challenges of Corrective RAG
A key challenge lies in the dependence on the effectiveness of the retrieval evaluator. This component plays a crucial role in determining the relevance and accuracy of the documents retrieved. If the evaluator is weak or poorly designed, it can cause substantial errors during the correction process. For example, a subpar evaluator might miss critical contextual details or fail to spot significant discrepancies between the retrieved information and the user’s query. This can lead to the propagation of errors, ultimately compromising the CRAG system’s reliability.
Furthermore, relying on automated evaluators raises issues related to scalability and adaptability. As language models evolve and new types of content emerge, these evaluators need constant updates and training to effectively manage diverse and changing data sources.
Another limitation is CRAG’s reliance on web searches to replace or correct documents that are inaccurate or ambiguous. Although this approach can offer up-to-date and varied information, it also carries the risk of introducing biased or unreliable content. Given the vastness of the internet, not all information is of equal quality; some sources may spread misinformation, while others might reflect particular ideological biases. As a result, CRAG systems must implement advanced filtering methods to differentiate between credible and untrustworthy sources.
Conclusion
Corrective Retrieval Augmented Generation (CRAG) represents a significant advancement in the reliability and accuracy of language model outputs by incorporating evaluators, dynamic web search capabilities alongside traditional document retrieval. Its ability to evaluate the relevance of retrieved documents and supplement them with real-time web data makes it particularly useful for applications demanding high precision and current information.
However, the system’s effectiveness hinges on the quality of its evaluators and the challenges associated with filtering reliable data from the vast expanse of the web. As language models evolve, continual refinement of the CRAG framework will be essential to overcome these hurdles and ensure its reliability.
Key Takeaways
- Corrective RAG (CRAG) enhances language model outputs by incorporating web search capabilities to retrieve up-to-date, relevant information, improving the accuracy of responses.
- The evaluator examines the quality of retrieved documents and triggers corrective actions if over 70% are irrelevant, ensuring the use of high-quality information in response generation.
- To improve retrieval accuracy, CRAG transforms user queries before executing web searches, increasing the chances of obtaining relevant results.
- CRAG dynamically integrates real-time information from web searches, allowing it to access broader and more diverse data sources compared to traditional RAG systems, which rely on static knowledge bases.
- Unlike traditional RAG, CRAG actively checks the relevance and accuracy of retrieved documents before generating responses, reducing the risk of generating misleading or incorrect information.
- CRAG is particularly beneficial in domains requiring high accuracy and real-time data, such as customer support, legal compliance, and financial analytics.
Frequently Asked Questions
A. Corrective RAG is an advanced framework that enhances language model outputs by integrating web search capabilities into its retrieval and generation processes to improve the accuracy and reliability of generated responses.
A. Unlike Traditional RAG, Corrective RAG actively checks and refines the retrieved documents for accuracy before using them for response generation, reducing the risk of errors.
A. The relevance evaluator assesses retrieved documents to determine if they require corrective actions or if the response generation can proceed as is.
A. If the initial retrieval lacks sufficient documents, CRAG supplements it by executing a web search to gather more relevant data.
A. CRAG must implement advanced filtering methods to identify credible sources and avoid introducing biased or unreliable information, as web searches may provide sources with misinformation or ideological biases.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.

Nibedita completed her master’s in Chemical Engineering from IIT Kharagpur in 2014 and is currently working as a Senior Data Scientist. In her current capacity, she works on building intelligent ML-based solutions to improve business processes.