
Image by author
As you delve into the world of data science and machine learning, one of the fundamental skills you will encounter is the art of reading data. If you already have some experience with it, you're probably familiar with JSON (JavaScript Object Notation), a popular format for storing and exchanging data.
Think about how NoSQL databases like MongoDB love to store data in JSON, or how REST APIs often respond in the same format.
However, JSON, while perfect for storage and sharing, is not quite ready for in-depth analysis in its raw form. This is where we transform it into something more analytically friendly: a tabular format.
So whether you're dealing with a single JSON object or a delightful array of them, in Python terms you're basically dealing with a dict or a list of dicts.
Let's explore together how this transformation unfolds, making our data ready for analysis.
Today I will explain a magic command that allows us to easily parse any JSON in tabular format in seconds.
And it is… ps.json_normalize()
So let's see how it works with different types of JSON.
The first type of JSON we can work with is single-level JSON with some keys and values. We define our first simple JSON as follows:
Code by author
So let's simulate the need to work with these JSON. We all know that there is not much to do in your JSON format. We need to transform these JSON into some readable and modifiable format… which means Pandas DataFrames!
1.1 Handling simple JSON structures
First, we need to import the pandas library and then we can use the pd.json_normalize() command, as follows:
import pandas as pd
pd.json_normalize(json_string)Applying this command to a single record JSON we obtain the most basic table. However, when our data is a little more complex and presents a list of JSON, we can still use the same command without further complications and the output will correspond to a table with multiple records.

Image by author
Easy… right?
The next natural question is what happens when some of the values are missing.
1.2 Handling null values
Imagine that some of the values are not reported, such as David's income record is missing. When transforming our JSON into a simple pandas data frame, the corresponding value will appear as NaN.
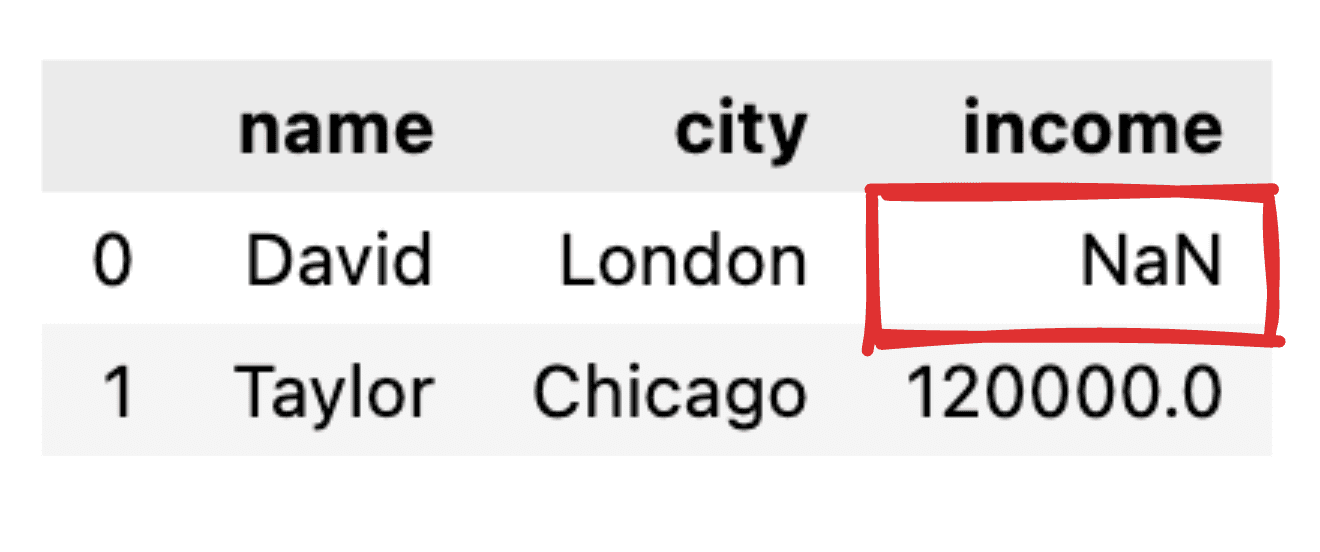
Image by author
And what if I only want to get some of the fields?
1.3 Select only those columns of interest
In case we only want to transform some specific fields into a tabular pandas DataFrame, the json_normalize() command does not allow us to choose which fields to transform.
Therefore, a small preprocessing of the JSON must be performed where we filter only those columns of interest.
# Fields to include
fields = ('name', 'city')
# Filter the JSON data
filtered_json_list = ({key: value for key, value in item.items() if key in fields} for item in simple_json_list)
pd.json_normalize(filtered_json_list)
So let's move on to a more advanced JSON structure.
When we deal with multi-level JSON, we come across JSON nested within different levels. The procedure is the same as before, but in this case we can choose how many levels we want to transform. By default, the command will always expand all levels and generate new columns containing the concatenated name of all nested levels.
So if we normalize the following JSON.
Code by author
We would obtain the following table with 3 columns under the skills field:
- skills.python
- skills.SQL
- skills.GCP
and 4 columns below the field roles
- project manager roles
- roles.data engineer
- data scientist roles
- roles.data analyst

Image by author
However, let's imagine that we only want to transform our top level. We can do this by specifically setting the max_level parameter to 0 (the max_level we want to expand).
pd.json_normalize(mutliple_level_json_list, max_level = 0)The pending values will be kept within JSON within our pandas dataframe.
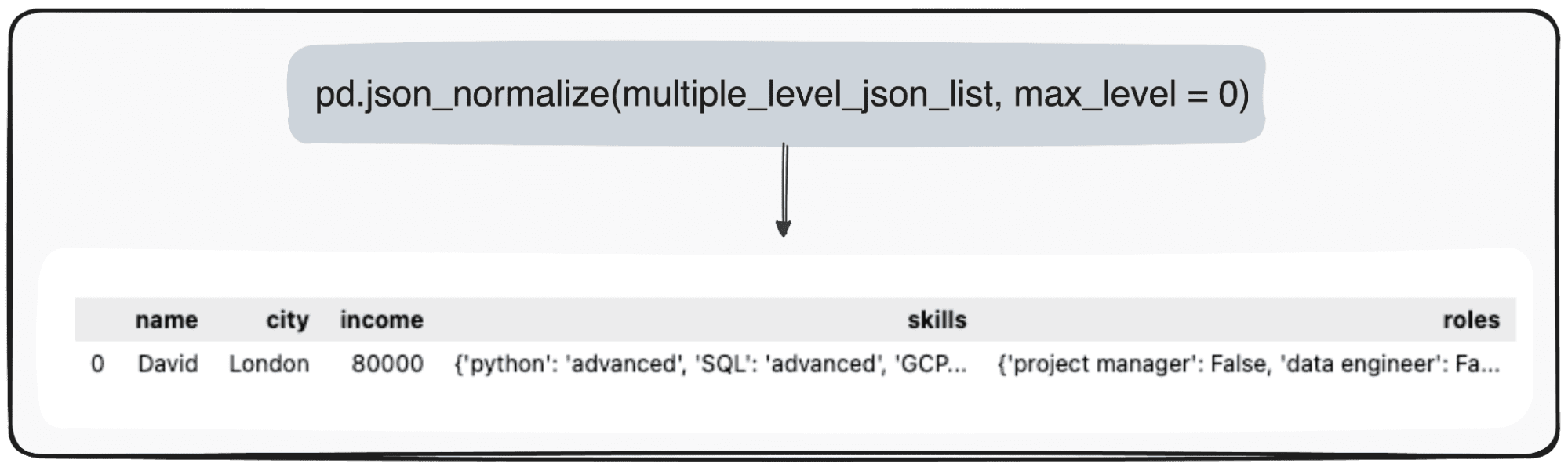
Image by author
The last case that we can find is to have a List nested within a JSON field. So, first we define our JSON to use.
Code by author
We can manage this data efficiently using Pandas in Python. The pd.json_normalize() function is particularly useful in this context. You can flatten JSON data, including nested list, into a structured format suitable for analysis. When this function is applied to our JSON data, it produces a normalized table that incorporates the nested list as part of its fields.
Additionally, Pandas offers the ability to further refine this process. By using the record_path parameter in pd.json_normalize(), we can direct the function to specifically normalize the nested list.
This action results in a table dedicated exclusively to the content of the list. By default, this process will only display the items within the list. However, to enrich this table with additional context, such as retaining an associated ID for each record, we can use the metaparameter.

Image by author
In summary, transforming JSON data into CSV files using Python's Pandas library is easy and efficient.
JSON remains the most common format in modern data storage and exchange, especially in NoSQL databases and REST APIs. However, it presents some significant analytical challenges when dealing with data in its raw format.
The fundamental role of Pandas' pd.json_normalize() arises as a great way to handle such formats and convert our data into Pandas DataFrame.
I hope this guide was helpful and that the next time you work with JSON you can do it in a more effective way.
You can consult the corresponding Jupyter Notebook in the following GitHub repository.
Joseph Ferrer He is an analytical engineer from Barcelona. He graduated in physical engineering and currently works in the field of Data Science applied to human mobility. He is a part-time content creator focused on data science and technology. You can contact him at LinkedIn, Twitter either Half.






{kind=link}