 NEWSLETTER
NEWSLETTER
Transformer -based models have significantly advanced natural language processing (NLP), standing out in several tasks. However, they struggle with reasoning in long contexts, inference of several steps and numerical reasoning. These challenges arise from their quadratic complexity in self -impact, which makes them inefficient for extended sequences and their lack of explicit memory, which limits their ability to synthesize dispersed information effectively. Existing solutions, such as recurring memory transformers (RMT) and aquatic recovery generation (RAG), offer partial improvements, but often sacrifice efficiency or generalization.
Introduction of the large memory model (LM2)
Convergence Labs presents the large memory model (LM2), an improved decoder transformative architecture with an auxiliary memory module to address the deficiencies of conventional models in the reasoning of long context. Unlike standard transformers, which depend solely on care mechanisms, LM2 incorporates a structured memory system that interacts with input inception through cross attention. Model memory updates are regulated by activation mechanisms, which allows you to selectively retain relevant information while preserving generalization capabilities. This design allows LM2 to maintain coherence in long sequences, facilitating improved relational reasoning and inference.
Technical description and benefits
LM2 is based on the architecture of the standard transformer by introducing three key innovations:
- Memory Aquatic Transformer: A dedicated memory bank acts as an explicit long -term storage system, recovering relevant information through cross attention.
- Hybrid memory: Unlike the previous models that modify the central structure of the transformer, LM2 maintains the original information flow by integrating an auxiliary memory route.
- Dynamic memory updates: The memory module selectively updates its stored information using entry, forgetting and learning output doors, ensuring long -term retention without an unnecessary accumulation of irrelevant data.
These improvements allow LM2 to process long sequences more effectively while maintaining computational efficiency. By selectively incorporating the relevant memory content, the model mitigates the gradual decrease in performance often observed in traditional architectures on extended contexts.
Experimental results and ideas
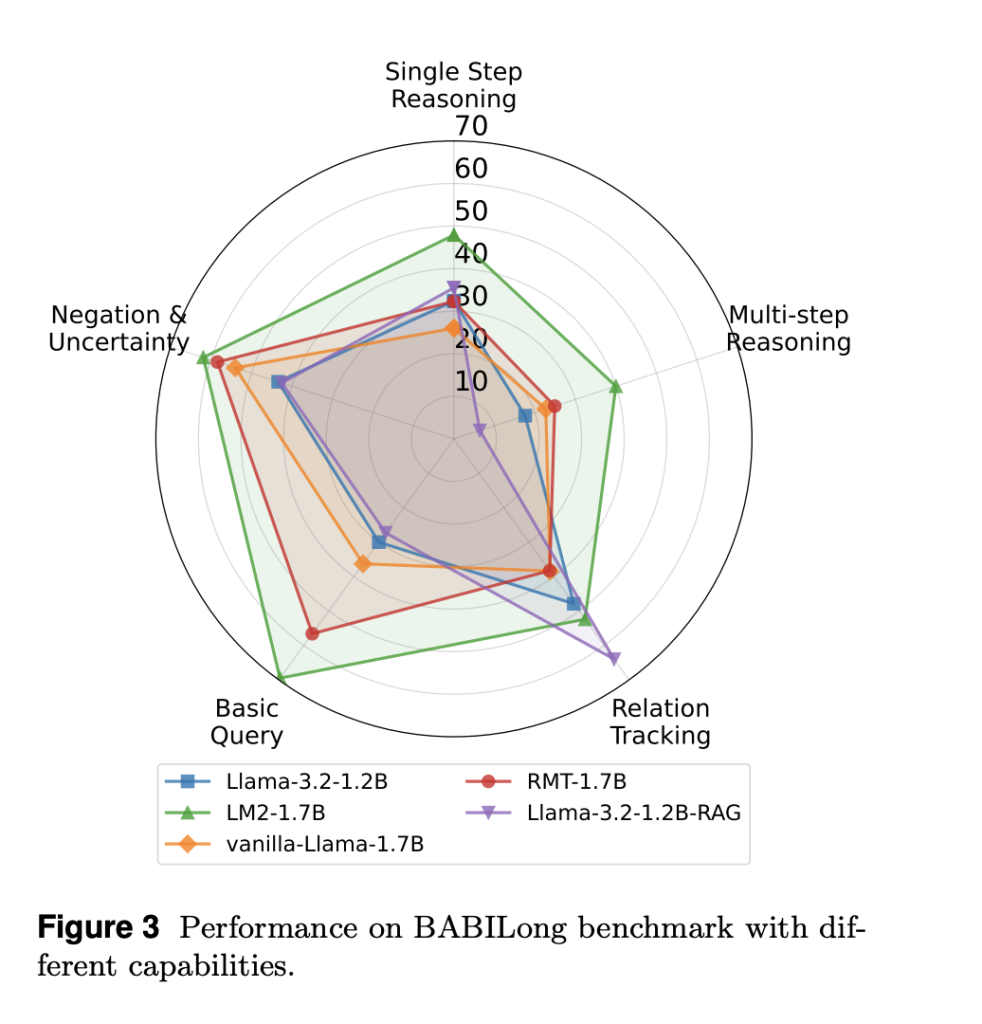
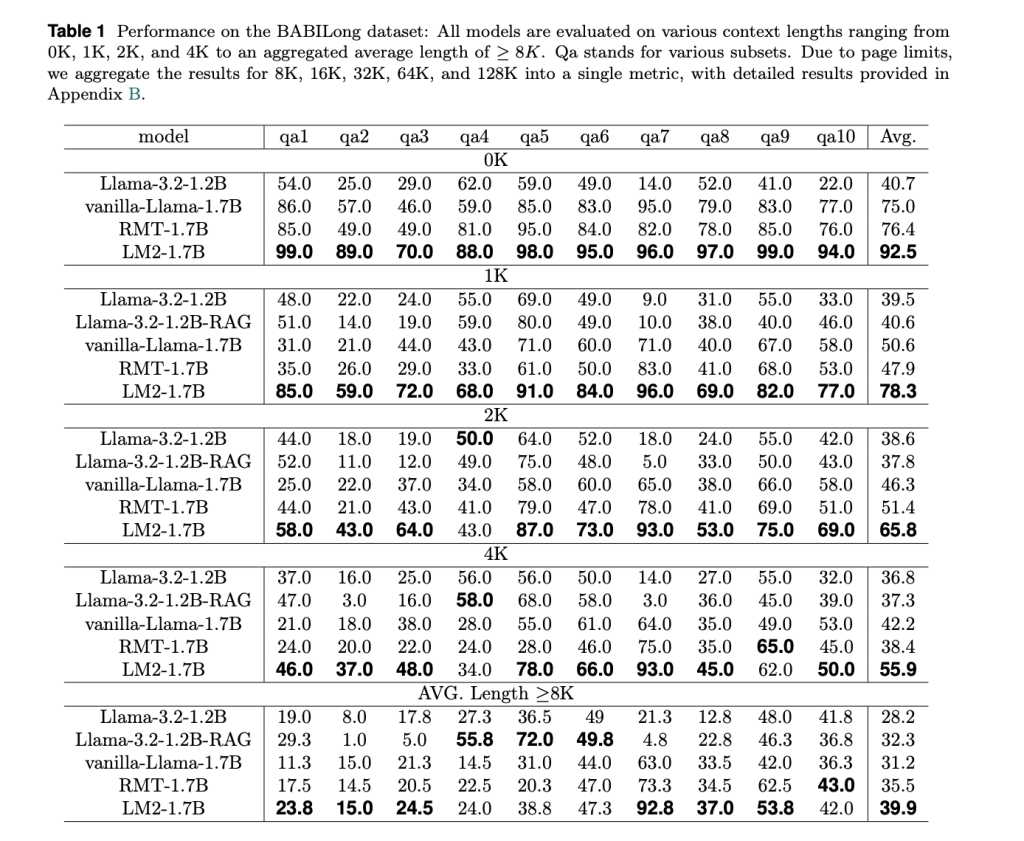
To evaluate the effectiveness of LM2, it was tested in the Babylong data set, designed to evaluate intensive memory capacity. The results indicate substantial improvements:
- Short context yield (0k context length): LM2 achieves a precision of 92.5%surpassing RMT (76.4%) and Vanilla call-3.2 (40.7%).
- Long context yield (1k-4k context length): As the context length increases, all models experience some degradation, but LM2 maintains greater precision. In Context length 4kLM2 achieves 55.9%compared to 48.4% for RMT and 36.8% for call-3.2.
- Extreme Long Context Performance (≥8k Context length): While all models decrease in precision, LM2 is still more stable, overcoming RMT in multiple steps inference and relational argumentation.
Beyond the specific reference points of the memory, LM2 was tested in the MMLU data set, which covers a wide range of academic issues. The model demonstrated a 5.0% improvement on a previously trained vanilla transformerParticularly protruding in humanities and social sciences, where contextual reasoning is crucial. These results indicate that the LM2 memory module improves reasoning capabilities without compromising the general performance of the task.
Conclusion
The introduction of LM2 offers a reflexive approach to address the limitations of standard transformers in long context reasoning. By integrating an explicit memory module, LM2 improves multiple steps inference, relational argumentation and numerical reasoning while maintaining efficiency and adaptability. Experimental results demonstrate their advantages over existing architectures, particularly in tasks that require extended context retention. In addition, LM2 works well at the general reasoning reference points, suggesting that the integration of memory does not hinder versatility. As memory aquatic models continue to evolve, LM2 represents a step towards a more effective long context reasoning in language models.
Verify he Paper. All credit for this investigation goes to the researchers of this project. In addition, feel free to follow us <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter And don't forget to join our 75K+ ml of submen.
Recommended open source ai platform: 'Intellagent is a framework of multiple open source agents to evaluate the conversational the complex system' (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, Asif undertakes to take advantage of the potential of artificial intelligence for the social good. Its most recent effort is the launch of an artificial intelligence media platform, Marktechpost, which stands out for its deep coverage of automatic learning and deep learning news that is technically solid and easily understandable by a broad audience. The platform has more than 2 million monthly views, illustrating its popularity among the public.






{kind=link}