
Contrastive learning typically relates pairs of related views among a series of unrelated negative views.
Views can be generated (for example, by magnification) or observed. We investigate matching when there are more than two related views, which we call multi-view tasks, and derive new representation learning objectives using information maximization and sufficient statistics.
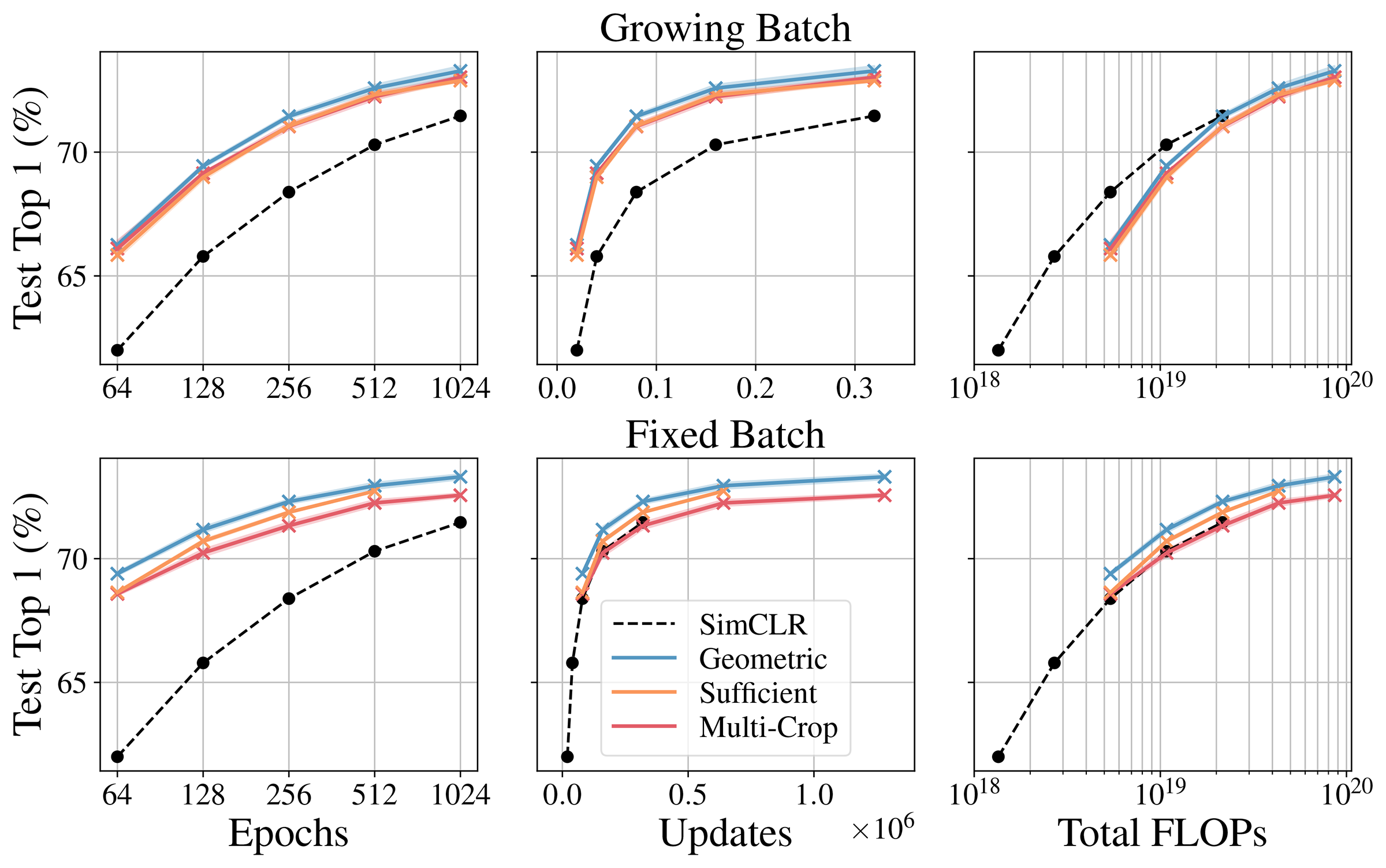
We show that with an unlimited computation, the number of related views should be maximized, and with a fixed computation budget, it is beneficial to decrease the number of unique samples while increasing the number of views of those samples.
In particular, multi-view contrastive models trained for 128 epochs with a batch size of 256 outperform SimCLR trained for 1024 epochs with a batch size of 4096 on ImageNet1k, challenging the belief that contrastive models require large batch sizes. and many times of training.



{kind=link}