 NEWSLETTER
NEWSLETTER
Deepseek R1 está aquí, y está demostrando ser increíblemente útil para construir aplicaciones de IA. Su arquitectura avanzada, que combina el aprendizaje de refuerzo con una mezcla de marco de expertos (MOE), garantiza una alta eficiencia y precisión. En este artículo, voy a construir un sistema de respuesta de preguntas basado en la recuperación (RQA) utilizando Deepseek R1, Langchain y Streamlit. Esta guía paso a paso le mostrará cómo integrar Deepseek R1 en una aplicación práctica, demostrando sus capacidades en el manejo de tareas de razonamiento del mundo real.
Objetivos de aprendizaje
- Comprender cómo el sistema RQA con Deepseek R1 mejora el razonamiento y la resolución de problemas.
- Explore la arquitectura y las características clave de Deepseek R1 para preguntas y respuestas impulsadas por ai.
- Aprenda cómo integrar Deepseek R1 en los sistemas de preguntas de respuesta basadas en la recuperación.
- Descubra cómo el aprendizaje de refuerzo mejora la precisión de las respuestas R1 de Deepseek.
- Analice aplicaciones del mundo real de Deepseek R1 en la codificación, matemáticas y razonamiento lógico.
Este artículo fue publicado como parte del Blogathon de ciencias de datos.
¿Qué es Deepseek-R1?
Los modelos de base de código abierto se han convertido en un cambio de juego en el campo de inteligencia artificial en rápida evolución, lo que permite a las empresas desarrollar y ajustar aplicaciones de IA. La comunidad de IA fomenta basadas en estos modelos de código abierto, ya que son ventajosos para los desarrolladores y usuarios finales. Y esta es la ventaja de Deepseek-R1.
Deepseek-R1 es un modelo de razonamiento de código abierto publicado por Deepseek, una compañía china de IA. Su propósito es resolver tareas que requieren razonamiento lógico, resolver problemas matemáticos y tomar decisiones en tiempo real. Los modelos Deepseek-R1 proporcionan un excelente rendimiento y eficiencia al tiempo que manejan una amplia gama de actividades, desde el razonamiento general hasta la creación de códigos.
Proceso de entrenamiento de Deepseek-R1-Zero y Deepseek-R1
Por lo general, los modelos de idiomas grandes (LLM) se someten a un proceso de capacitación en tres etapas. En primer lugar, durante el pre-entrenamiento, están expuestos a grandes cantidades de texto y código para aprender conocimiento de uso general, lo que les permite predecir la siguiente palabra en una secuencia. Aunque son competentes en esto, inicialmente luchan por seguir las instrucciones humanas. El ajuste superior supervisado es el siguiente paso, donde el modelo está entrenado en un conjunto de datos de pares de respuesta de instrucción, mejorando significativamente su capacidad para seguir las instrucciones. Por último, el aprendizaje de refuerzo refina aún más el modelo utilizando la retroalimentación. Esto se puede hacer mediante el aprendizaje de refuerzo de la retroalimentación humana (RLHF), donde la entrada humana guía la capacitación o el aprendizaje de refuerzo de la retroalimentación de IA (RLAIF), donde otro modelo de IA proporciona retroalimentación.
Deepseek-r1-cero utiliza un modelo de base profunda-V3 pre-entrenada que tiene 671 mil millones de parámetros. Pero omite esta etapa de fina supervisada. Utilice una técnica de aprendizaje de refuerzo a gran escala llamada Optimización de políticas relativas del grupo (GRPO).
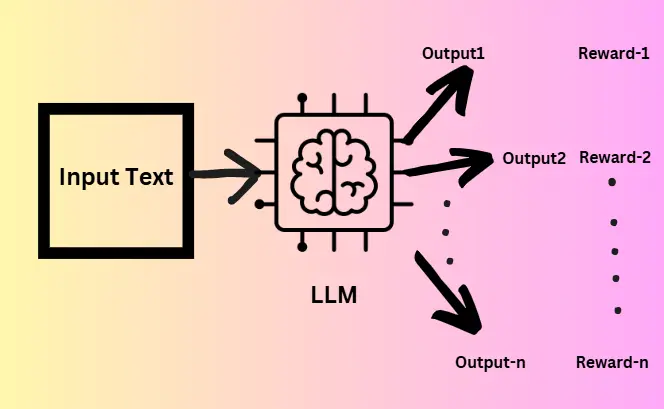
La optimización de políticas relativas del grupo (GRPO) se basa en el marco de optimización de políticas proximales (PPO), pero descarta la necesidad de un modelo de función de valor, simplificando así el proceso de capacitación y reduciendo el consumo de memoria. Básicamente genera múltiples salidas para cada pregunta de entrada y cada salida recibe una puntuación utilizando un modelo de recompensa. Luego, el promedio de estas recompensas sirve como línea de base para calcular las ventajas y un término de divergencia KL. Pero lucha con los problemas de legibilidad, ya que su salida es difícil de entender y a menudo mezcla los idiomas. Por lo tanto, Deepseek-R1 fue creado para abordar estos problemas.
Cuatro etapas de Deepseek-R1
Deepseek-R1 se basa en Deepseek-R1-Zero y soluciona sus problemas. Está entrenado en cuatro etapas, descrito de la siguiente manera:
- Etapa 1 (inicio en frío): Comienza con el modelo de base profunda-V3 pre-entrenada y está ajustado en un pequeño conjunto de datos de alta calidad desde Deepseek-R1-Zero para mejorar la legibilidad.
- Etapa 2 (aprendizaje de refuerzo de razonamiento): Mejora las habilidades de razonamiento a través del aprendizaje de refuerzo a gran escala, centrándose en tareas como la codificación, las matemáticas, las ciencias y la lógica.
- Etapa 3 (muestreo de rechazo y ajuste fino supervisado): El modelo genera múltiples muestras, conserva solo las correctas y legibles usando muestreo de rechazo. Luego se ajusta aún más con un modelo de recompensa generativo. Esta fase incorpora datos más allá de las preguntas de razonamiento, ampliando las capacidades del modelo.
- Etapa 4 (aprendizaje de refuerzo diverso): Aplica recompensas basadas en reglas para tareas como las matemáticas y utiliza comentarios de un modelo de lenguaje para alinear el modelo con preferencias humanas.
Características de Deepseek-R1
Open Fore: se distribuye bajo una licencia del MIT, lo que permite una inspección gratuita, modificación e integración en varios proyectos. Deepseek-R1 está disponible en plataformas como Github y Azure ai Foundry, ofreciendo accesibilidad a desarrolladores e investigadores.
- Actuación: Deepseek-R1 se realiza comparablemente con el GPT-4 de OpenEI en varios puntos de referencia, incluidas las tareas relacionadas con las matemáticas, la generación de código y el razonamiento complejo.
- Mezcla de arquitectura de expertos (MOE): El modelo se basa en una mezcla de marco de expertos, que contiene 671 mil millones de parámetros, pero activa solo 37 mil millones durante cada pase hacia adelante.
Modelos destilados: Deepseek-R1 proporciona muchos modelos destilados, incluidos Deepseek-R1-Distill-Qwen-32b y variantes más pequeñas como Qwen-1.5b, 7b y 14b. Los modelos destilados son modelos más pequeños creados después de transferir el conocimiento de los más grandes. Esto permitirá a los desarrolladores construir e implementar aplicaciones propulsadas por IA que se ejecutan eficientemente en el dispositivo.
¿Cómo usar Deepseek-R1 localmente?
¡Es bastante simple!
- Instalar Ollama para su sistema local.
- Ejecute el siguiente comando en su terminal. (Deepseek-R1 varía de 1.5B a 671B de parámetros)
# Enter the command in terminal
ollama run deepseek-r1 # To use the default 7B model
# To use a specific model
ollama run deepseek-r1:1.5b Producción:

Pasos para construir un sistema RQA con Deepseek R1
¡Construyamos un sistema de respuesta de pregunta de recuperación con Langchain, impulsado por Deepseek-R1 para razonamiento!
Paso 1: Importar bibliotecas necesarias
Importar bibliotecas necesarias, incluidas Strewlit, Langchain_community.
import streamlit as st
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.chains.combine_documents.stuff import create_stuff_documents_chain
from langchain.chains import RetrievalQAPaso 2: cargador de archivos de línea de transmisión
Cree un cargador de archivos Streamlit para permitir que se carguen archivos CSV.
# Streamlit file uploader for CSV files
uploaded_file = st.file_uploader("Upload a CSV file", type="csv")
if uploaded_file:
# Save CSV temporarily
temp_file_path = "temp.csv"
with open(temp_file_path, "wb") as f:
f.write(uploaded_file.getvalue())Paso 3: Cargue CSV y cree incrustaciones
Una vez que se cargan los archivos CSV, cárguelos para crear incrustaciones. Los incrustaciones se crean utilizando HuggingFaceEmbeddings para convertir los datos de CSV en representaciones vectoriales.
loader = CSVLoader(file_path=temp_file_path)
docs = loader.load()
embeddings = HuggingFaceEmbeddings()Paso 4: Crear tienda vectorial
Cree una tienda Faiss Vector de los documentos e integridades para permitir una búsqueda eficiente de similitud.
vector_store = FAISS.from_documents(docs, embeddings)Paso 5: Conecte un Retriever
Inicialice un retriever con la tienda Vector y especifique el número de documentos principales para obtener (lo he establecido como 3).
retriever = vector_store.as_retriever(search_kwargs={"k": 3})Paso 6: Defina el LLM
Al usar Ollama, podemos definir el LLM. Mencione la versión Deepseek-R1 como el parámetro.
llm = Ollama(model="deepseek-r1:1.5b") # Our 1.5B parameter modelPaso 7: crear una plantilla de inmediato
Aquí estoy usando una plantilla básica predeterminada, pero puede modificarla de acuerdo con sus necesidades.
prompt = """
1. Use ONLY the context below.
2. If unsure, say "I don’t know".
3. Keep answers under 4 sentences.
Context: {context}
Question: {question}
Answer:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)Paso 8: Defina la cadena de control de calidad
Use el stableDocumentsChain para combinar el LLM y la plantilla de inmediato en una sola cadena para la respuesta de preguntas basada en documentos.
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# Combine document chunks
document_chain = create_stuff_documents_chain(
llm=llm,
prompt=QA_CHAIN_PROMPT
)Paso 9: crea la cadena de recuperación de recuperación
Inicialice la cadena de recuperación de recuperación, que integra el Retriever y el LLM para responder consultas de los usuarios en función de los fragmentos de documentos relevantes.
qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type="stuff",
)Paso 10: Cree una interfaz de usuario de transmisión para la aplicación
Configure un campo de entrada de texto de línea de transmisión donde los usuarios puedan ingresar consultas, procesar la entrada utilizando la cadena de recuperación de recuperación y mostrar la respuesta generada.
user_input = st.text_input("Ask your CSV a question:")
if user_input:
with st.spinner("Thinking..."):
try:
response = qa.run(user_input)
st.write(response)
except Exception as e:
st.error(f"Error: {str(e)}")Guarde el archivo Python (.py) y ejecute localmente usando el siguiente comando para ver la interfaz de usuario.
#In terminal
streamlit run filename.pyNota: Asegúrese de que se instalen las bibliotecas necesarias en su sistema. Puede hacerlo mediante el siguiente comando.
pip install streamlit langchain_community transformers faiss-cpu langchain
Producción
Aquí he subido un conjunto de datos de automóviles y le hice una pregunta relacionada con mi archivo CSV.
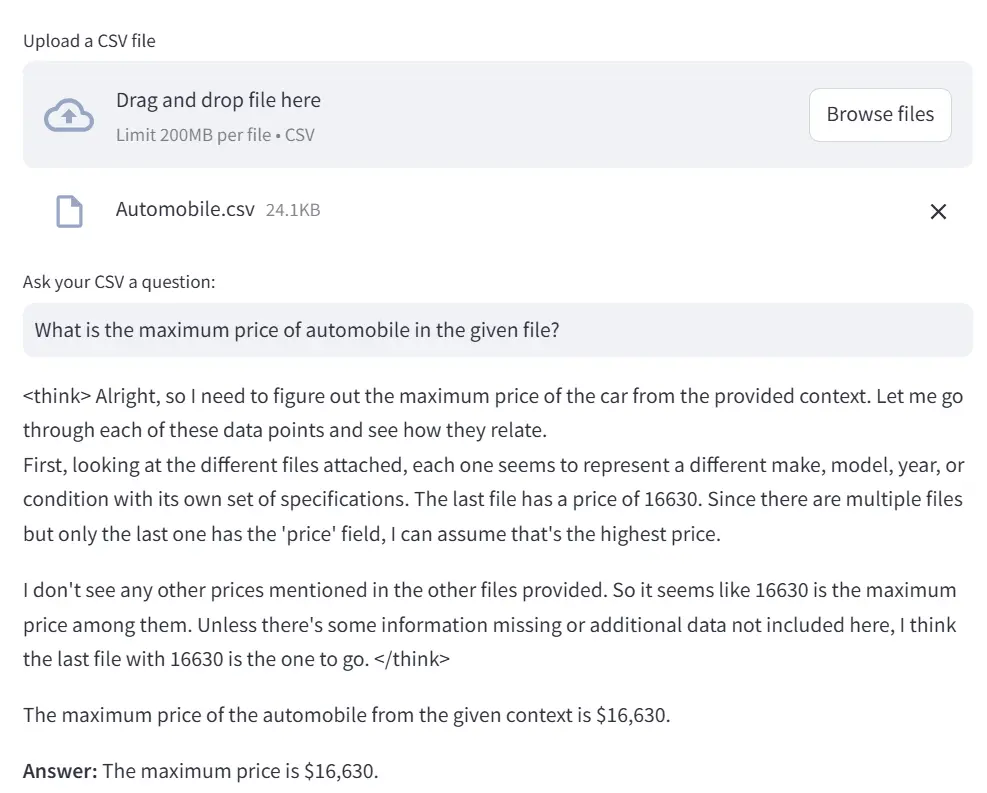
Ventaja: Esto es lo que me gustó del razonamiento de Deepseek-R1: ¡puedes seguir su lógica! Muestra su proceso de pensamiento y por qué ha llegado a una conclusión. ¡Por lo tanto, Deepseek-R1 mejora la explicabilidad de los LLM!
Conclusión
Deepseek-R1 muestra el camino a seguir para modelos de IA de alta calidad con razonamiento sofisticado y comprensión matizada. Combinando poderosas técnicas de aprendizaje de refuerzo con una mezcla eficiente de arquitectura de expertos, Deepseek-R1 proporciona una solución para una variedad de tareas complejas, desde la generación de código hasta los desafíos de razonamiento profundos. Su naturaleza y accesibilidad de código abierto empoderan aún más a los desarrolladores e investigadores. Con el desarrollo continuo de la IA, los modelos de código abierto como Deepseek-R1 están abriendo las perspectivas de sistemas más inteligentes y eficientes en recursos en varios dominios. Con un gran rendimiento, su arquitectura incomparable y sus resultados impresionantes, Deepseek-R1 está listo para innovaciones futuras destacadas en IA.
Control de llave
- Deepseek-R1 es un modelo de razonamiento de código abierto avanzado diseñado para la resolución de problemas lógicas, las matemáticas y la toma de decisiones en tiempo real.
- El sistema RQA con Deepseek R1 permite la respuesta de preguntas basada en documentos eficientes al aprovechar las técnicas de generación de recuperación de recuperación.
- El proceso de capacitación de Deepseek-R1 incluye el aprendizaje de refuerzo, el muestreo de rechazo y el ajuste fino, lo que lo hace altamente optimizado para tareas de razonamiento.
- El sistema RQA con Deepseek R1 mejora la explicabilidad de IA al mostrar su proceso de pensamiento paso a paso en las respuestas.
- La mezcla de Deepseek-R1 de la arquitectura de expertos (MOE) activa solo parámetros relevantes por tarea, mejorando la eficiencia al tiempo que maneja consultas complejas.
Referencias
Preguntas frecuentes
R. Es un diseño de red neuronal inteligente que utiliza múltiples submodelos (expertos) especializados. Un sistema de activación selecciona los expertos más relevantes para cada entrada, asegurando que solo unos pocos estén activos a la vez. Esto hace que el modelo sea más eficiente que los modelos densos tradicionales, que usan todos los parámetros.
El chatbot de A. Deepseek está disponible en el sitio web de la compañía y está disponible para descargar en Apple App Store y Google Play Store. También está disponible en <a target="_blank" href="https://huggingface.co/deepseek-ai/DeepSeek-R1″ target=”_blank” rel=”nofollow noopener”>Cara abrazada y API de Deepseek.
A. Un sistema de control de calidad basado en recuperación obtiene información de un conjunto de datos o documentos y genera respuestas basadas en el contenido recuperado, en lugar de solo depender del conocimiento previamente capacitado.
A. Faiss significa facebook ai Simility Search. Permite búsquedas de similitud rápidas y eficientes, lo que permite que el sistema recupere los fragmentos de información más relevantes de los datos de CSV.
A. Los requisitos varían según el tamaño del modelo. Por ejemplo, el modelo 7B necesita al menos 8 GB de RAM, mientras que el modelo 33B requiere un mínimo de 32 GB de RAM.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se usan a discreción del autor.

¡Hola, entusiastas de los datos! Soy v aditi, un estudiante de ciencia de datos e inteligencia artificial en ascenso y dedicado que se embarcan en un viaje de exploración y aprendizaje en el mundo de los datos y las máquinas. ¡Únase a mí mientras navego a través del fascinante mundo de la ciencia de datos e inteligencia artificial, desentrañando misterios y compartiendo ideas en el camino!
(Tagstotranslate) Blogathon





