 NEWSLETTER
NEWSLETTER
Introducción
Nvidia lanzó el último Small Language Model (SLM) llamado Nemotron-Mini-4B-Instruct. SLM es la versión simplificada, cuantificada y optimizada del modelo base más grande. SLM está desarrollado principalmente para la velocidad y la implementación en el dispositivo. Nemotron-mini-4B es una versión optimizada de Nvidia Minitron-4B-Base, que era una versión simplificada y optimizada de Nemotron-4 15B. Este modelo de instrucción optimiza el juego de roles, el control de calidad de RAG y la llamada de funciones en inglés. Entrenado entre febrero de 2024 y agosto de 2024, incorpora los últimos eventos y desarrollos en todo el mundo.
En este artículo, analizamos Nemotron-Mini-4B-Instruct de Nvidia, un modelo de lenguaje pequeño (SLM). Analizaremos su evolución a partir del modelo más grande Nemotron-4 15B, centrándonos en su naturaleza simplificada y optimizada para la velocidad y la implementación en el dispositivo. Además, destacamos su período de capacitación de febrero a agosto de 2024, mostrando cómo incorpora los últimos desarrollos globales, lo que lo convierte en una herramienta poderosa en aplicaciones de IA en tiempo real.
Resultados del aprendizaje
- Comprenda la arquitectura y las técnicas de optimización detrás de los modelos de lenguaje pequeño (SLM) como Nemotron-Mini-4B-Instruct de Nvidia.
- Aprenda a configurar un entorno de desarrollo para implementar SLM utilizando Conda e instalar bibliotecas esenciales.
- Obtenga experiencia práctica en la codificación de un chatbot que utiliza el modelo Nemotron-Mini-4B-Instruct para conversaciones interactivas.
- Explore aplicaciones reales de SLM en juegos y otras industrias, destacando sus ventajas sobre modelos más grandes.
- Descubra la diferencia entre SLM y LLM, incluida su eficiencia de recursos y su adaptabilidad para tareas específicas.
Este artículo fue publicado como parte de la Blogatón sobre ciencia de datos.
¿Qué son los modelos de lenguaje pequeños (SLM)?
Los modelos de lenguaje pequeños (SLM) son versiones compactas de los modelos de lenguaje grandes, diseñados para realizar tareas de procesamiento del lenguaje natural (PLN) utilizando recursos computacionales reducidos. Optimizan la eficiencia y la velocidad, y suelen ofrecer un buen rendimiento en tareas específicas con menos parámetros. Estas características los hacen ideales para dispositivos de borde o computación en dispositivos con memoria y capacidad de procesamiento limitadas. Estas categorías de modelos son menos potentes que los LLM, pero pueden hacer un mejor trabajo para tareas centradas en el dominio.
Técnicas de entrenamiento para modelos de lenguaje pequeños
Normalmente, los desarrolladores entrenan o ajustan modelos de lenguaje pequeños (SLM) a partir de modelos de lenguaje grandes (LLM) utilizando diversas técnicas que reducen el tamaño del modelo manteniendo un nivel razonable de rendimiento.

- Destilación del conocimiento: El LLM se utiliza para entrenar al modelo más pequeño, donde el LLM funciona como instructor y el SLM como tren. El modelo pequeño aprende a imitar el resultado del instructor, capturando el conocimiento esencial y reduciendo la complejidad.
- Poda de parámetros: El proceso de entrenamiento elimina parámetros redundantes o menos importantes del LLM, reduciendo el tamaño del modelo sin afectar drásticamente el rendimiento.
- Cuantización: Los pesos del modelo se convierten de formatos de mayor precisión, como 32 bits, a formatos de menor precisión, como 8 bits o 4 bits, lo que reduce el uso de memoria y acelera los cálculos.
- Torneado fino específico para cada tarea: Un LLM pre-entrenado previamente se somete a un ajuste fino en una tarea específica utilizando un conjunto de datos más pequeño, optimizando el modelo más pequeño para tareas específicas como juegos de roles y chat de control de calidad.
Éstas son algunas de las técnicas de vanguardia utilizadas para ajustar el SLM.
<h2 class="wp-block-heading" id="h-significance-of-slms-in-today-s-ai-landscape”>Importancia de los SLM en el panorama actual de la IA
Los modelos de lenguaje pequeños (SLM) desempeñan un papel crucial en el panorama actual de la IA debido a su eficiencia, escalabilidad y accesibilidad. A continuación, se indican algunos de los más importantes:
- Eficiencia de recursos: Los SLM requieren significativamente menos potencia computacional, memoria y almacenamiento, lo que los hace ideales para aplicaciones móviles en dispositivos.
- Inferencia más rápida: Su tamaño más pequeño permite tiempos de inferencia más rápidos, lo que es esencial para aplicaciones en tiempo real como chatbots, asistentes de voz y dispositivos IoT.
- Rentable: La capacitación y la implementación de modelos de lenguaje grandes pueden ser costosos, los SLM ofrecen una solución más rentable para empresas y desarrolladores, democratizando el acceso a la IA.
- Sostenibilidad: Debido a su tamaño, los usuarios pueden ajustar los SLM más fácilmente para tareas específicas o aplicaciones específicas, lo que permite una mayor adaptabilidad en una amplia gama de industrias, incluida la atención médica y el comercio minorista.
Aplicaciones reales del Nemotron-Mini-4B
NVIDIA anunció en Gamescom 2024 el primer SLM en el dispositivo para mejorar las habilidades de conversación de los personajes del juego. El juego Mecha BREAK de Amazing Seasun Games utiliza la suite NVIDIA ACE, que son tecnologías humanas digitales que brindan voz, inteligencia y animación impulsadas por IA generativa.
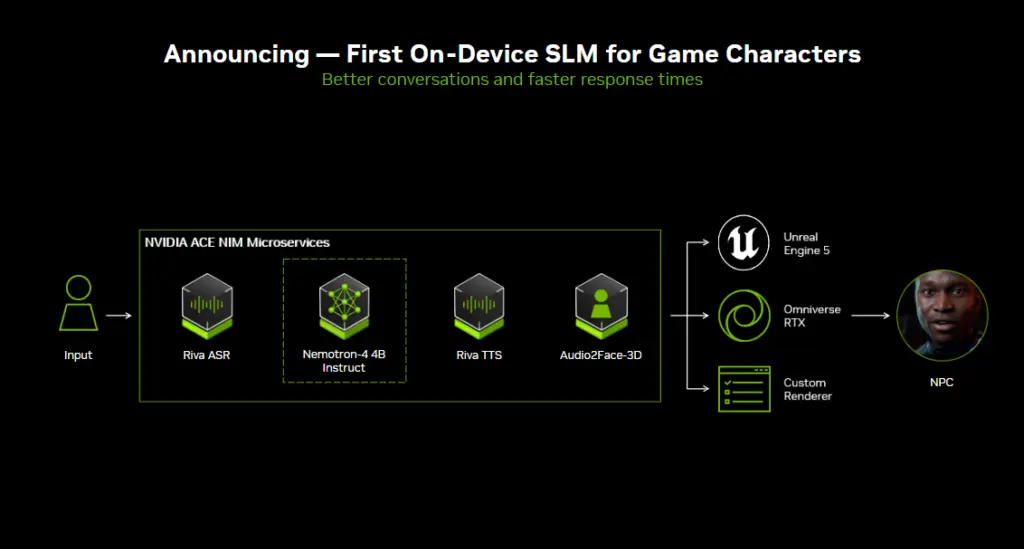
Configuración de su entorno de desarrollo
La creación de un entorno de desarrollo sólido es esencial para el éxito del desarrollo de su chatbot. Este paso implica configurar las herramientas, bibliotecas y marcos necesarios que le permitirán escribir, probar y refinar su código de manera eficiente.
Paso 1: Crear un entorno Conda
Primero, crea un entorno anaconda ( Anaconda). Coloque el siguiente comando en su terminal.
# Create conda env
$ conda create -n nemotron python=3.11Creará un entorno Python 3.11 llamado nemotron.
Paso 2: Activación del entorno de desarrollo
Configurar un entorno de desarrollo es un paso crucial en la creación de su chatbot, ya que proporciona las herramientas y los marcos necesarios para codificar y probar. Lo guiaremos a través del proceso de activación de su entorno de desarrollo, asegurándonos de que tenga todo lo que necesita para que su chatbot cobre vida sin problemas.
# Create a deve folder and activate the anaconda env
$ mkdir nemotron-dev
$ cd nemotron-dev
# Activaing nemotron conda env
$ conda activate nemotronPaso 3: Instalación de bibliotecas esenciales
Primero, instala PyTorch según tu sistema operativo para configurar tu entorno de desarrollo. Luego, instala Transformers y Langchain usando PIP.
# Install Pytorch (Windows) for GPU
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Install PyTorch (Windows) CPU
pip install torch torchvision torchaudioEn segundo lugar, instale transformadores y langchain.
# Install transformers, Langchain
pip install transformers, langchainImplementación de código para un chatbot simple
¿Alguna vez te preguntaste cómo crear un chatbot que pueda mantener una conversación? En esta sección, te guiaremos a través de la implementación del código de un chatbot simple. Aprenderás sobre los componentes clave, los lenguajes de programación y las bibliotecas involucradas en la creación de un agente conversacional funcional, lo que te permitirá diseñar una experiencia de usuario atractiva e interactiva.
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("nvidia/Nemotron-Mini-4B-Instruct")
model = AutoModelForCausalLM.from_pretrained("nvidia/Nemotron-Mini-4B-Instruct")
# Use the prompt template
messages = (
{
"role": "system",
"content": "You are friendly chatbot, reply on style of a Professor",
},
{"role": "user", "content": "What is Quantum Entanglement?"},
)
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(tokenized_chat, max_new_tokens=128)
print(tokenizer.decode(outputs(0)))Aquí, descargamos Nemotron-Mini-4B-Instruct(Nemo) desde Hugginface Hub a través de los transformadores AutoModelForCausalLM y el tokenizador usando AutoTokenizer.
Crear plantilla de mensaje
Crea una plantilla de mensaje para un chatbot de profesor y haz la pregunta “¿Qué es el entrelazamiento cuántico?”
Veamos cómo responde Nemo a esa pregunta.

Vaya, respondió bastante bien. Ahora crearemos un chatbot más fácil de usar para chatear con él continuamente.
Construyendo un Chatbot Avanzado y Fácil de Usar
Exploraremos el proceso de creación de un chatbot avanzado y fácil de usar que no solo satisfaga las necesidades de los usuarios, sino que también mejore su experiencia de interacción. Analizaremos los componentes esenciales, los principios de diseño y las tecnologías involucradas en la creación de un chatbot que sea intuitivo, receptivo y capaz de comprender la intención del usuario, cerrando en última instancia la brecha entre la tecnología y la satisfacción del usuario.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, TextIteratorStreamer
from threading import Thread
import time
class PirateBot:
def __init__(self, model_name="nvidia/Nemotron-Mini-4B-Instruct"):
print("Ahoy! Yer pirate bot be loadin' the model. Stand by, ye scurvy dog!")
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
# Move model to GPU if available
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model.to(self.device)
print(f"Arrr! The model be ready on {self.device}!")
self.messages = (
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
}
)
def generate_response(self, user_input, max_new_tokens=1024):
self.messages.append({"role": "user", "content": user_input})
tokenized_chat = self.tokenizer.apply_chat_template(
self.messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
).to(self.device)
streamer = TextIteratorStreamer(self.tokenizer, timeout=10., skip_prompt=True, skip_special_tokens=True)
generation_kwargs = dict(
inputs=tokenized_chat,
max_new_tokens=max_new_tokens,
streamer=streamer,
do_sample=True,
top_p=0.95,
top_k=50,
temperature=0.7,
num_beams=1,
)
thread = Thread(target=self.model.generate, kwargs=generation_kwargs)
thread.start()
print("Pirate's response: ", end="", flush=True)
generated_text = ""
for new_text in streamer:
print(new_text, end="", flush=True)
generated_text += new_text
time.sleep(0.05) # Add a small delay for a more natural feel
print("\n")
self.messages.append({"role": "assistant", "content": generated_text.strip()})
return generated_text.strip()
def chat(self):
print("Ahoy, matey! I be yer pirate chatbot. What treasure of knowledge ye be seekin'?")
while True:
user_input = input("You: ")
if user_input.lower() in ('exit', 'quit', 'goodbye'):
print("Farewell, ye landlubber! May fair winds find ye!")
break
try:
self.generate_response(user_input)
except Exception as e:
print(f"Blimey! We've hit rough seas: {str(e)}")
if __name__ == "__main__":
bot = PirateBot()
bot.chat()El código anterior consta de tres funciones:
- Función __init__
- generar_respuesta
- charlar
La función init se explica por sí sola, tiene un tokenizador, un modelo, un dispositivo y una plantilla de respuesta para nuestro bot pirata.
La función Generar respuesta tiene dos entradas user_input y max_new_tokens. La entrada del usuario se agregará a una lista llamada mensaje y el rol será el usuario. El “self.message” rastreará el historial de conversaciones entre el usuario y el asistente. TextIteratorStreamer crea un objeto streamer que maneja la transmisión en vivo de la respuesta del modelo, lo que nos permite imprimir la salida a medida que se genera y crea una sensación de conversación más natural.
Para generar la respuesta, se utiliza un nuevo hilo para ejecutar la función de generación desde el modelo, que genera la respuesta del asistente. El transmisor comienza a generar el texto a medida que lo genera el modelo en tiempo real.
La respuesta se imprime pieza por pieza a medida que se genera, simulando un efecto de tipeo. Un pequeño retraso (time.sleep(0.05)) agrega una pausa entre las salidas para una sensación más natural.
Poniendo a prueba el chatbot: explorando sus capacidades de conocimiento
Ahora profundizaremos en la fase de prueba de nuestro chatbot, centrándonos en sus capacidades de conocimiento y capacidad de respuesta. Al interactuar con el bot a través de varias consultas, pretendemos evaluar su capacidad para proporcionar información precisa y relevante, destacando la eficacia del Small Language Model (SLM) subyacente para ofrecer interacciones significativas.
Mirando la interfaz de este chatbot

Le haremos a Nemo diferentes tipos de preguntas para explorar sus capacidades de conocimiento.
¿Qué es la teletransportación cuántica?
Producción:

¿Qué es la violación de género?
Producción:

Explicar el algoritmo del viajante de comercio (TSM)
El algoritmo del viajante de comercio encuentra el camino más corto entre dos puntos, como por ejemplo desde el restaurante hasta el lugar de entrega. Todos los servicios de mapas utilizan este algoritmo para proporcionar rutas de navegación para conducir, y los proveedores de servicios de Internet lo utilizan para ofrecer respuestas a las consultas.
Producción:

Implementar Travelling Sale Man en Python
Producción:
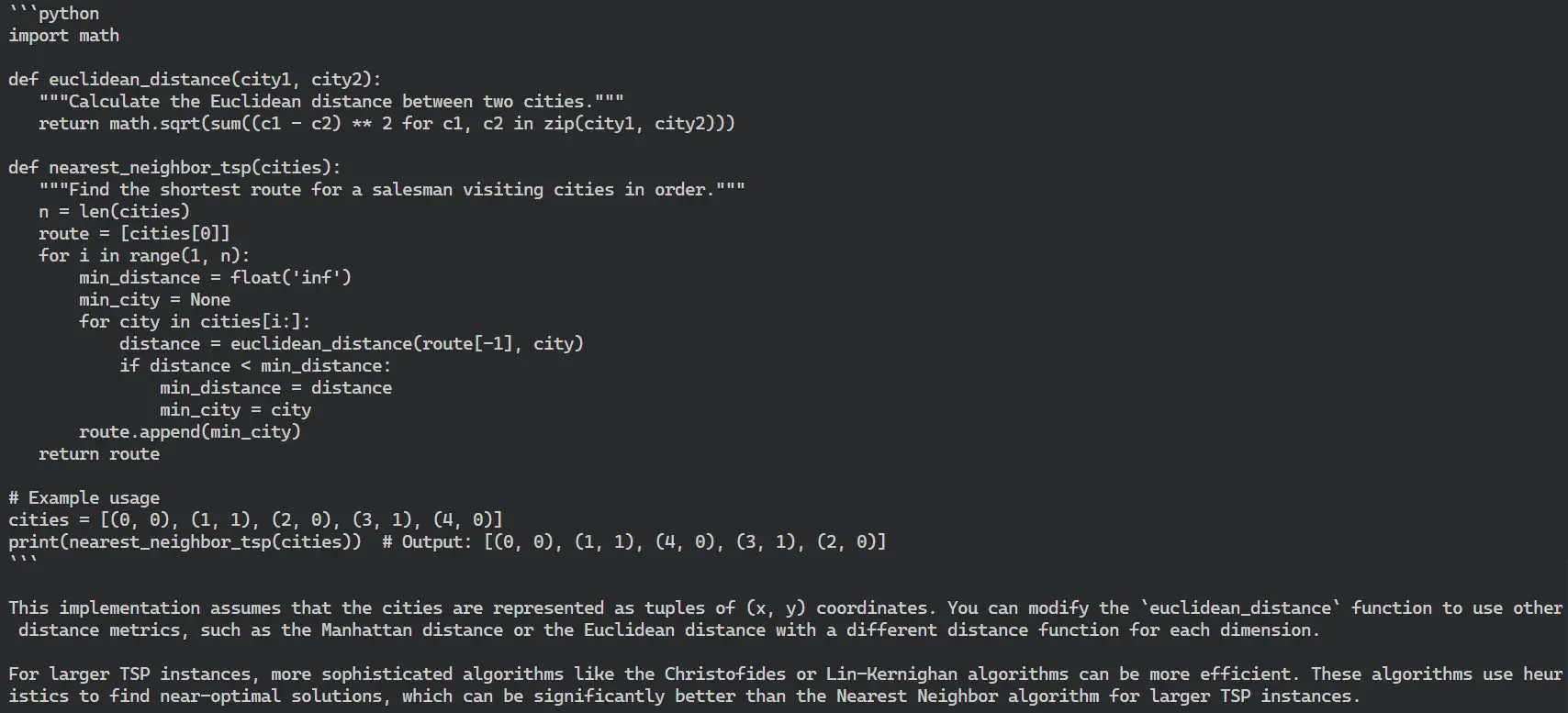
Vemos que el modelo funciona algo mejor en todas las preguntas. Hemos pedido distintos tipos de preguntas de distintas áreas de las asignaturas.
Conclusión
Nemotron Mini 4B es un modelo muy capaz para aplicaciones empresariales. Ya lo utiliza una empresa de juegos con la suite Nvidia ACE. Nemotron Mini 4B es solo el comienzo de la aplicación de vanguardia de los modelos de IA generativa en las industrias de los juegos, que estarán directamente en la computadora del jugador y mejorarán su experiencia de juego. Es la punta del iceberg; en los próximos días exploraremos más ideas en torno al modelo SLM.
Puntos clave
- Los SLM utilizan menos recursos y ofrecen una inferencia más rápida, lo que los hace adecuados para aplicaciones en tiempo real.
- Nemotron-Mini-4B-Instruct es un modelo listo para la industria, ya utilizado en juegos a través de NVIDIA ACE.
- El modelo está ajustado a partir del modelo base Nemotron-4.
- Nemotron-Mini se destaca en aplicaciones diseñadas para juegos de roles, respuesta de preguntas de documentos y llamada de funciones.
Preguntas frecuentes
A. Los SLM son más eficientes en cuanto al uso de recursos que los LLM. Están diseñados específicamente para dispositivos en el dispositivo, IoT y dispositivos de borde.
A. Sí, puedes ajustar los SLM para tareas específicas, como clasificación de texto, chatbots, generación de facturas por servicios de atención médica, atención al cliente y diálogos y personajes del juego.
A. Sí, puedes empezar a usar Nemotron-Mini-4B-Instruct directamente a través de Ollama. Solo tienes que instalar Ollama y escribir Ollama run nemotron-mini-4b-instruct. Eso es todo. Puedes empezar a hacer preguntas directamente en la línea de comandos.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.

Soy autodidacta y aprendiz orientado a proyectos. Me encanta trabajar en proyectos complejos sobre aprendizaje profundo, visión artificial y procesamiento del lenguaje natural. Siempre trato de comprender en profundidad el tema, que puede ser de cualquier campo, como aprendizaje profundo, aprendizaje automático o física. Me encanta crear contenido sobre mi aprendizaje. Intento compartir mi comprensión con el mundo.





