 NEWSLETTER
NEWSLETTER
Bienvenido a la Parte 2 de mi LLM Deep Dive. Si no ha leído la Parte 1, le recomiendo que lo revise primero.
Anteriormente, cubrimos las dos primeras etapas principales de entrenamiento y LLM:
- Pre-capacitación: aprendizaje de conjuntos de datos masivos para formar un modelo base.
- Autorización fino (SFT) supervisado: refinar el modelo con ejemplos curados para hacerlo útil.
Ahora, nos estamos sumergiendo en la próxima etapa principal: Aprendizaje de refuerzo (RL). Si bien el pre-entrenamiento y el SFT están bien establecidos, RL sigue evolucionando pero se ha convertido en una parte crítica de la tubería de entrenamiento.
He tomado referencia de Andrej Karpathy es el popular YouTube de 3.5 horas. Andrej es miembro fundador de OpenAi, sus ideas son de oro: se entiende la idea.
Vamos
¿Cuál es el propósito del aprendizaje de refuerzo (RL)?
Los humanos y LLM procesan la información de manera diferente. Lo que es intuitivo para nosotros, como la aritmética básica, puede no ser para un LLM, que solo ve el texto como secuencias de tokens. Por el contrario, un LLM puede generar respuestas a nivel de experto en temas complejos simplemente porque ha visto suficientes ejemplos durante el entrenamiento.
Esta diferencia en la cognición hace que sea difícil para los anotadores humanos proporcionar el conjunto de etiquetas “perfectas” que guían constantemente una LLM hacia la respuesta correcta.
Rl une esta brecha al permitir que el modelo aprender de su propia experiencia.
En lugar de confiar únicamente en etiquetas explícitas, el modelo explora diferentes secuencias de tokens y recibe comentarios, señales de recompensa, en las que las salidas son más útiles. Con el tiempo, aprende a alinearse mejor con la intención humana.
Intuición detrás de RL
Los LLM son estocásticos, lo que significa que sus respuestas no están fijas. Incluso con el mismo aviso, la salida varía porque se muestrean desde una distribución de probabilidad.
Podemos aprovechar esta aleatoriedad generando miles o incluso millones de respuestas posibles en paralelo. Piense en ello como el modelo que explora diferentes caminos, algunos buenos, otros malos. Nuestro objetivo es alentarlo a tomar los mejores caminos con más frecuencia.
Para hacer esto, entrenamos el modelo en las secuencias de tokens que conducen a mejores resultados. A diferencia de los ajustes finos supervisados, donde los expertos humanos proporcionan datos etiquetados, El aprendizaje de refuerzo permite que el modelo aprender de sí mismo.
El modelo descubre qué respuestas funcionan mejor, y después de cada paso de entrenamiento, actualizamos sus parámetros. Con el tiempo, esto hace que el modelo sea más probable que produzca respuestas de alta calidad cuando reciban indicaciones similares en el futuro.
Pero, ¿cómo determinamos qué respuestas son las mejores? ¿Y cuánto RL deberíamos hacer? Los detalles son complicados, y hacerlos bien no es trivial.
RL no es “nuevo”: puede superar la experiencia humana (Alphago, 2016)
Un gran ejemplo del poder de RL es Alphago de Deepmind, la primera IA en derrotar a un jugador profesional de Go y luego superar el juego a nivel humano.
En el Documento natural de 2016 (Gráfico a continuación), cuando un modelo fue entrenado puramente por SFT (dando al modelo toneladas de buenos ejemplos para imitar), el modelo pudo alcanzar el rendimiento a nivel humano, Pero nunca lo supere.
La línea punteada representa el rendimiento de Lee Sedol, el mejor jugador Go del mundo.
Esto se debe a que SFT se trata de replicación, no de innovación, no permite que el modelo descubra nuevas estrategias más allá del conocimiento humano.
Sin embargo, RL permitió a Alphago jugar contra sí mismo, refinar sus estrategias y, en última instancia, exceder la experiencia humana (Línea azul).
RL representa una frontera emocionante en la IA, donde los modelos pueden explorar estrategias más allá de la imaginación humana cuando la entrenamos en un grupo de problemas diversos y desafiantes para refinar sus estrategias de pensamiento.
Resumen de fundaciones de RL
Recapitulemos rápidamente los componentes clave de una configuración RL típica:
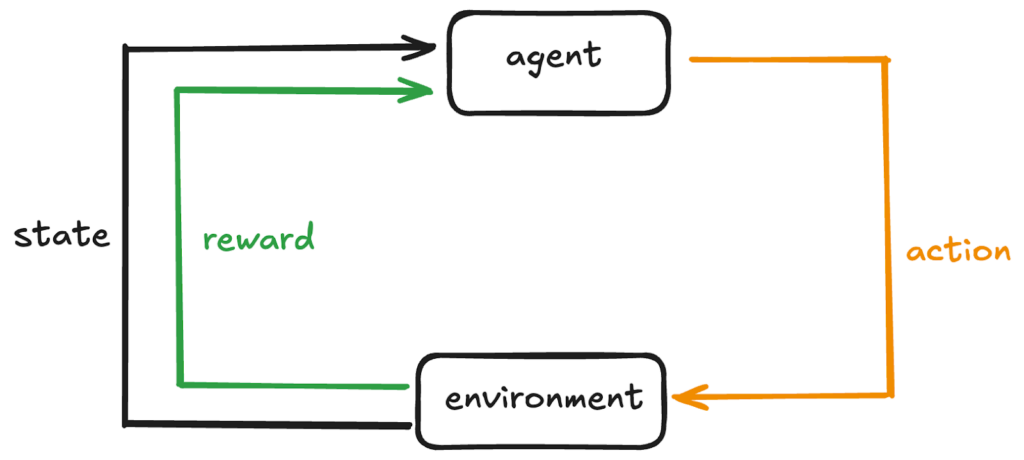
- Agente – El alumno o el tomador de decisiones. Observa la situación actual (estado), elige una acción y luego actualiza su comportamiento en función del resultado (premio).
- Ambiente– El sistema externo en el que opera el agente.
- Estado – Una instantánea del entorno en un paso dado T.
En cada marca de tiempo, el agente realiza un acción en el entorno que cambiará el estado del entorno a uno nuevo. El agente también recibirá comentarios que indican cuán buena o mala fue la acción.
Esta retroalimentación se llama premioy está representado en una forma numérica. Una recompensa positiva alienta ese comportamiento, y una recompensa negativa lo desalienta.
Al utilizar la retroalimentación de diferentes estados y acciones, el agente aprende gradualmente la estrategia óptima para Maximizar la recompensa total con el tiempo.
Política
La política es la estrategia del agente. Si el agente sigue una buena política, constantemente tomará buenas decisiones, lo que llevará a mayores recompensas en muchos pasos.
En términos matemáticos, es una función que determina la probabilidad de diferentes salidas para un estado dado,(Ph (a | s)).
Función de valor
Una estimación de lo bueno que es ser en cierto estado, considerando la recompensa esperada a largo plazo. Para un LLM, la recompensa puede provenir de la retroalimentación humana o un modelo de recompensa.
Arquitectura del actor-crítico
Es una configuración RL popular que combina dos componentes:
- Actor – aprende y actualiza el política (πθ), decidiendo qué acción tomar en cada estado.
- Crítico – evalúa el función de valor (V (s)) para dar retroalimentación al actor sobre si sus acciones elegidas están conduciendo a buenos resultados.
Cómo funciona:
- El actorElige una acción basada en su política actual.
- El críticoEvalúa el resultado (recompensa + siguiente estado) y actualiza su estimación de valor.
- Los comentarios del crítico ayuda al actor a refinar su política para que las acciones futuras conduzcan a mayores recompensas.
Poniéndolo todo para LLMS
El estado puede ser el texto actual (aviso o conversación), y la acción puede ser el siguiente token para generar. Un modelo de recompensa (por ejemplo, comentarios humanos) le dice al modelo cuán bueno o malo es el texto generado.
La política es la estrategia del modelo para elegir el siguiente token, mientras que la función de valor estima cuán beneficioso es el contexto del texto actual, en términos de producir respuestas de alta calidad.
Deepseek-r1 (publicado el 22 de enero de 2025)
Para resaltar la importancia de RL, exploremos Deepseek-R1, un modelo de razonamiento que logra un rendimiento de primer nivel mientras queda de código abierto. El documento introdujo dos modelos: Deepseek-r1-cero y Deepseek-r1.
- Deepseek-r1-cero fue entrenado únicamente a través de RL a gran escala, saltando ajustados supervisados (SFT).
- Deepseek-R1 se basa en ello, abordando desafíos encontrados.
<figure class="wp-block-embed is-type-rich is-provider-twitter wp-block-embed-twitter“>
Vamos a sumergirnos en algunos de estos puntos clave.
1. RL Algo: Optimización de políticas relativas del grupo (GRPO)
Un algoritmo RL que cambia el juego clave es la optimización de políticas relativas del grupo (GRPO), una variante de la optimización de políticas proximal (PPO) ampliamente popular. Grpo se introdujo en el artículo de Deepseekmath en febrero de 2024.
¿Por qué Grpo sobre PPO?
PPO lucha con tareas de razonamiento debido a:
- Dependencia de un modelo crítico.
PPO necesita un modelo de crítico separado, duplicando efectivamente la memoria y el cálculo.
Entrenar al crítico puede ser complejo para tareas matizadas o subjetivas. - Alto costo computacional como tuberías RL exigen recursos sustanciales para evaluar y optimizar las respuestas.
- Evaluaciones de recompensa absoluta
Cuando confía en una recompensa absoluta, lo que significa que hay un solo estándar o métrica para juzgar si una respuesta es “buena” o “mala”, puede ser difícil capturar los matices de tareas abiertas y diversas en diferentes dominios de razonamiento.
Cómo Grpo abordó estos desafíos:
GRPO elimina el modelo crítico utilizando evaluación relativa– Las respuestas se comparan dentro de un grupo en lugar de juzgarse por un estándar fijo.
Imagina a los estudiantes que resuelven un problema. En lugar de que un maestro los califique individualmente, comparan respuestas, aprendiendo unos de otros. Con el tiempo, el rendimiento converge hacia una mayor calidad.
¿Cómo encaja GRPO en todo el proceso de entrenamiento?
GRPO modifica cómo se calcula la pérdida mientras mantiene otros pasos de entrenamiento sin cambios:
- Recopilar datos (consultas + respuestas)
– Para LLMS, las consultas son como preguntas
– La antigua política (instantánea más antigua del modelo) genera varias respuestas candidatas para cada consulta - Asignar recompensas– Cada respuesta en el grupo se califica (la “recompensa”).
- Calcule la pérdida de GRPO
Tradicionalmente, calcularás una pérdida, que muestra la desviación entre la predicción del modelo y la etiqueta verdadera.
En Grpo, sin embargo, mides:
a) ¿Qué tan probable es que la nueva política produzca respuestas pasadas?
b) ¿Son esas respuestas relativamente mejores o peores?
c) Aplicar recorte para evitar actualizaciones extremas.
Esto produce una pérdida escalar. - Propagación de retroceso + descenso de gradiente
– La propagación de la espalda calcula cómo cada parámetro contribuyó a la pérdida
– El descenso de gradiente actualiza esos parámetros para reducir la pérdida
– En muchas iteraciones, esto cambia gradualmente la nueva política para preferir respuestas de recompensa más altas - Actualice la antigua política ocasionalmente para que coincida con la nueva política.
Esto refresca la línea de base para la próxima ronda de comparaciones.
2. Cadena de pensamiento (cuna)
El entrenamiento tradicional de LLM sigue previamente al entrenamiento → SFT → RL. Sin embargo, Deepseek-R1-Zero omitido sftpermitiendo que el modelo explore directamente el razonamiento de la cuna.
Al igual que los humanos que piensan en una pregunta difícil, COT permite que los modelos dividan problemas en pasos intermedios, lo que aumenta las capacidades de razonamiento complejos. El modelo O1 de OpenAI también aprovecha esto, como se señaló en su informe de septiembre de 2024: El rendimiento de O1 mejora con más RL (cálculo de tiempo de tren) y más tiempo de razonamiento (cálculo de tiempo de prueba).
Deepseek-r1-cero exhibió tendencias reflexivas, refinando de forma autónoma su razonamiento.
Un gráfico clave (a continuación) en el documento mostró un mayor pensamiento durante el entrenamiento, lo que llevó a respuestas más largas (más tokens), más detalladas y mejores.
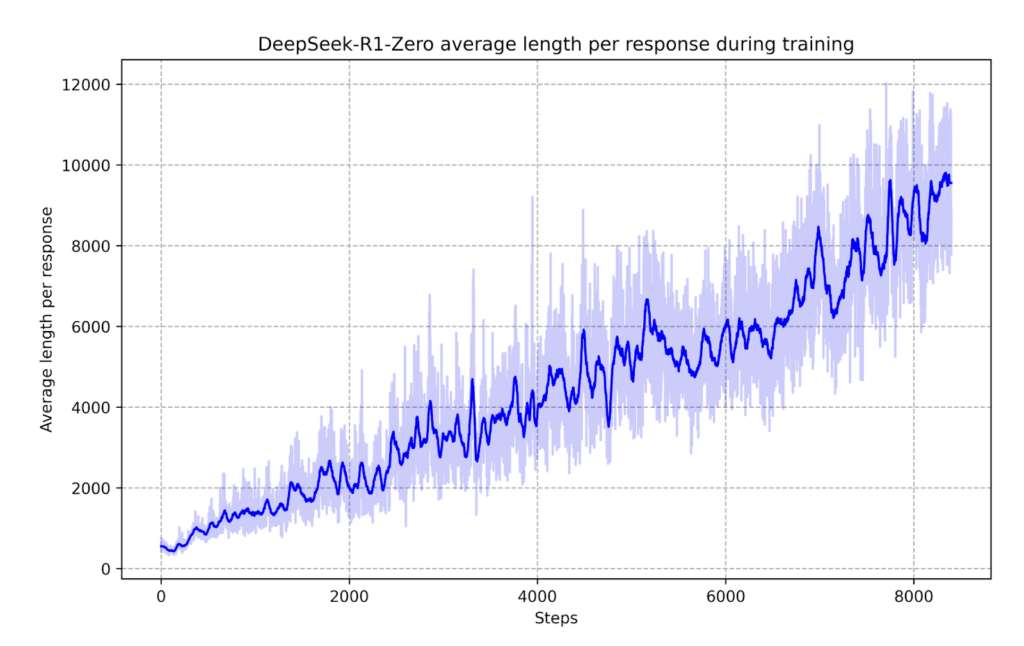
Sin una programación explícita, comenzó a volver a visitar pasos de razonamiento pasados, mejorando la precisión. Esto destaca el razonamiento de la cadena de pensamiento como una propiedad emergente de la capacitación RL.
El modelo también tuvo un “momento AHA” (abajo), un ejemplo fascinante de cómo RL puede conducir a resultados inesperados y sofisticados.

Nota: A diferencia de Deepseek-R1, OpenAI no muestra cadenas de pensamiento de razonamiento exacto en O1, ya que les preocupa un riesgo de destilación, donde alguien entra e intenta imitar esos rastros de razonamiento y recuperar gran parte del rendimiento de razonamiento simplemente imitando. En cambio, O1 solo resúmenes de estas cadenas de pensamientos.
Aprendizaje de refuerzo con comentarios humanos (RLHF)
Para las tareas con salidas verificables (por ejemplo, problemas matemáticos, preguntas y respuestas objetivas), las respuestas de IA se pueden evaluar fácilmente. Pero, ¿qué pasa con áreas como resumen o escritura creativa, donde no hay una sola respuesta “correcta”?
Aquí es donde entra la retroalimentación humana, pero los enfoques de RL ingenuos son indescriptibles.

Veamos el enfoque ingenuo con algunos números arbitrarios.

¡Eso es mil millones de evaluaciones humanas necesarias! Esto es demasiado costoso, lento e indescriptible. Por lo tanto, una solución más inteligente es entrenar un “modelo de recompensa” de IA para aprender preferencias humanas, reduciendo drásticamente el esfuerzo humano.
Las respuestas de clasificación también son más fáciles y más intuitivas que la puntuación absoluta.

Ascendentes de RLHF
- Se puede aplicar a cualquier dominio, incluida la escritura creativa, la poesía, el resumen y otras tareas abiertas.
- La clasificación de salidas es mucho más fácil para los labeladores humanos que la generación de salidas creativas.
Desventajas de RLHF
- El modelo de recompensa es una aproximación: puede no reflejar perfectamente las preferencias humanas.
- RL es bueno para jugar el modelo de recompensa: si se ejecuta durante demasiado tiempo, el modelo podría explotar las lagunas, generando resultados no sensibles que aún obtienen puntajes altos.
Tenga en cuenta que RLHF no es lo mismo que el RL tradicional.
Para dominios empíricos y verificables (por ejemplo, Matemáticas, Codificación), RL puede funcionar indefinidamente y descubrir estrategias novedosas. RLHF, por otro lado, es más como un paso ajustado para alinear los modelos con las preferencias humanas.
Conclusión
¡Y eso es una envoltura! Espero que hayas disfrutado la Parte 2 si aún no has leído la Parte 1, échale un vistazo aquí.
¿Tienes preguntas o ideas para lo que debo cubrir a continuación? Déjelos en los comentarios: me encantaría escuchar sus pensamientos. ¡Nos vemos en el próximo artículo!
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″> (TagStotranslate) Deepseek





{kind=link}