 NEWSLETTER
NEWSLETTER
A pesar de la exageración de la IA, muchas compañías tecnológicas aún dependen en gran medida del aprendizaje automático hasta aplicaciones críticas, desde recomendaciones personalizadas hasta la detección de fraude.
He visto de primera mano cómo las derivaciones no detectadas pueden resultar en costos significativos: detección de fraude perdida, ingresos perdidos y resultados comerciales subóptimos, solo por nombrar algunos. Por lo tanto, es crucial tener un monitoreo sólido si su empresa ha implementado o planea implementar modelos de aprendizaje automático en producción.
La deriva del modelo no detectado puede conducir a pérdidas financieras significativas, ineficiencias operativas e incluso daños a la reputación de una empresa. Para mitigar estos riesgos, es importante tener un monitoreo de modelo efectivo, lo que implica:
- Rendimiento del modelo de seguimiento
- Monitoreo de distribuciones de características
- Detección de derivaciones univariadas y multivariadas
Un sistema de monitoreo bien implementado puede ayudar a identificar problemas temprano, ahorrando tiempo, dinero y recursos considerables.
En esta guía integral, proporcionaré un marco sobre cómo pensar e implementar un monitoreo de modelos efectivo, ayudándole a mantenerse a la vanguardia de posibles problemas y garantizar la estabilidad y la confiabilidad de sus modelos en la producción.
¿Cuál es la diferencia entre la deriva de características y la deriva de puntaje?
La deriva de la puntuación se refiere a un cambio gradual en la distribución de las puntuaciones del modelo. Si no se controla, esto podría conducir a un disminución del rendimiento del modelohacer que el modelo sea menos preciso con el tiempo.
Por otro lado, la deriva de características ocurre cuando una o más características experimentan cambios en la distribución. Estos cambios en los valores de características pueden afectar las relaciones subyacentes que el modelo ha aprendido y, en última instancia, conducir a predicciones del modelo inexactos.
Simulando turnos de puntaje
Para modelar desafíos de detección de fraude en el mundo real, creé un conjunto de datos sintético con cinco características de transacción financiera.
El conjunto de datos de referencia representa la distribución original, mientras que el conjunto de datos de producción introduce cambios para simular un aumento en Transacciones de alto valor sin verificación de PIN en cuentas más nuevas, indicando un aumento en el fraude.
Cada característica tiene diferentes distribuciones subyacentes:
- Cantidad de transacción: Distribución logarítmica normal (sesgo derecho con una cola larga)
- Edad de la cuenta (meses): Distribución normal recortada entre 0 y 60 (suponiendo una empresa de 5 años)
- Tiempo desde la última transacción: Distribución exponencial
- Recuento de transacciones: Distribución de Poisson
- Pin entrado: Distribución binomial.
Para aproximar las puntuaciones del modelo, asigné pesos al azar a estas características y apliqué una función sigmoidea para restringir las predicciones entre 0 a 1. Esto imita cómo un modelo de fraude de regresión logística genera puntuaciones de riesgo.
Como se muestra en la traza a continuación:
- Características a la deriva: Monto de transacción, edad de cuenta, recuento de transacciones y PIN ingresado Todos los cambios experimentados en la distribución, escala o relaciones.
- Característica estable: Tiempo desde la última transacción permaneció sin cambios.
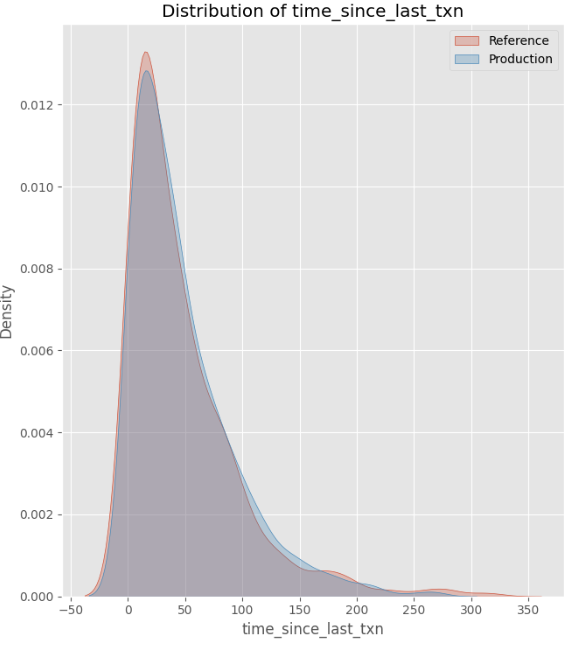
- Puntajes a la deriva: Como resultado de las características a la deriva, la distribución en las puntuaciones del modelo también ha cambiado.
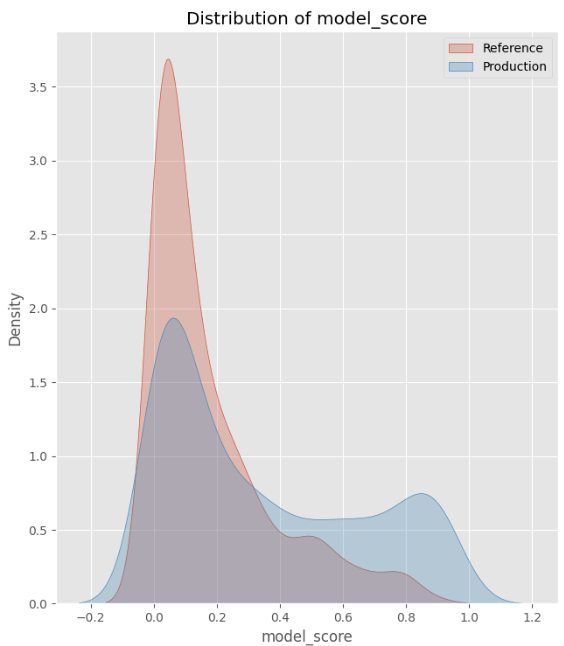
Esta configuración nos permite analizar cómo la deriva de la función impacta los puntajes del modelo en la producción.
Detección de la deriva de puntaje del modelo usando PSI
Para monitorear las puntuaciones del modelo, utilicé el Índice de Estabilidad de la Población (PSI) para medir la cantidad de distribución de puntaje del modelo que ha cambiado con el tiempo.
PSI funciona agrupando las puntuaciones del modelo continuo y comparando la proporción de puntajes en cada bin entre los conjuntos de datos de referencia y producción. Compara las diferencias en las proporciones y sus proporciones logarítmicas para calcular una sola estadística de resumen para cuantificar la deriva.
Implementación de Python:
# Define function to calculate PSI given two datasets
def calculate_psi(reference, production, bins=10):
# Discretize scores into bins
min_val, max_val = 0, 1
bin_edges = np.linspace(min_val, max_val, bins + 1)
# Calculate proportions in each bin
ref_counts, _ = np.histogram(reference, bins=bin_edges)
prod_counts, _ = np.histogram(production, bins=bin_edges)
ref_proportions = ref_counts / len(reference)
prod_proportions = prod_counts / len(production)
# Avoid division by zero
ref_proportions = np.clip(ref_proportions, 1e-8, 1)
prod_proportions = np.clip(prod_proportions, 1e-8, 1)
# Calculate PSI for each bin
psi = np.sum((ref_proportions - prod_proportions) * np.log(ref_proportions / prod_proportions))
return psi
# Calculate PSI
psi_value = calculate_psi(ref_data('model_score'), prod_data('model_score'), bins=10)
print(f"PSI Value: {psi_value}")A continuación se muestra un resumen de cómo interpretar los valores de PSI:
- Psi <0.1: Sin deriva, o una deriva muy menor (las distribuciones son casi idénticas).
- 0.1 ≤ psi <0.25: Algunas derivadas. Las distribuciones son algo diferentes.
- 0.25 ≤ psi <0.5: Drift moderada. Un cambio notable entre las distribuciones de referencia y producción.
- Psi ≥ 0.5: Drift significativa. Hay un gran cambio, lo que indica que la distribución en la producción ha cambiado sustancialmente a partir de los datos de referencia.
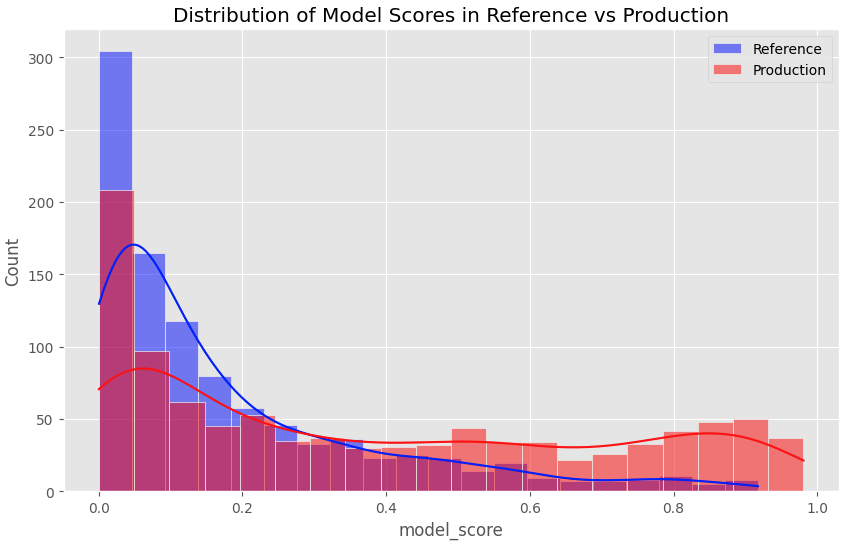
El Valor psi de 0.6374 sugiere una deriva significativa entre nuestros conjuntos de datos de referencia y producción. Esto se alinea con el histograma de las distribuciones de puntaje del modelo, que confirma visualmente el cambio hacia puntajes más altos en la producción, indicando un aumento en las transacciones riesgosas.
Detectar la deriva de características
Prueba de Kolmogorov-Smirnov para características numéricas
La prueba de Kolmogorov-Smirnov (KS) es mi método preferido para detectar la deriva en características numéricas, porque es no paramétrico, lo que significa que no asume una distribución normal.
La prueba compara la distribución de una característica en los conjuntos de datos de referencia y producción midiendo la máxima diferencia entre las funciones de distribución acumulativa empírica (ECDF). La estadística KS resultante varía de 0 a 1:
- 0 indica que no hay diferencia entre las dos distribuciones.
- Los valores más cercanos a 1 sugieren un cambio mayor.
Implementación de Python:
# Create an empty dataframe
ks_results = pd.DataFrame(columns=('Feature', 'KS Statistic', 'p-value', 'Drift Detected'))
# Loop through all features and perform the K-S test
for col in numeric_cols:
ks_stat, p_value = ks_2samp(ref_data(col), prod_data(col))
drift_detected = p_value < 0.05
# Store results in the dataframe
ks_results = pd.concat((
ks_results,
pd.DataFrame({
'Feature': (col),
'KS Statistic': (ks_stat),
'p-value': (p_value),
'Drift Detected': (drift_detected)
})
), ignore_index=True)
A continuación se presentan los gráficos de ECDF de las cuatro características numéricas en nuestro conjunto de datos:
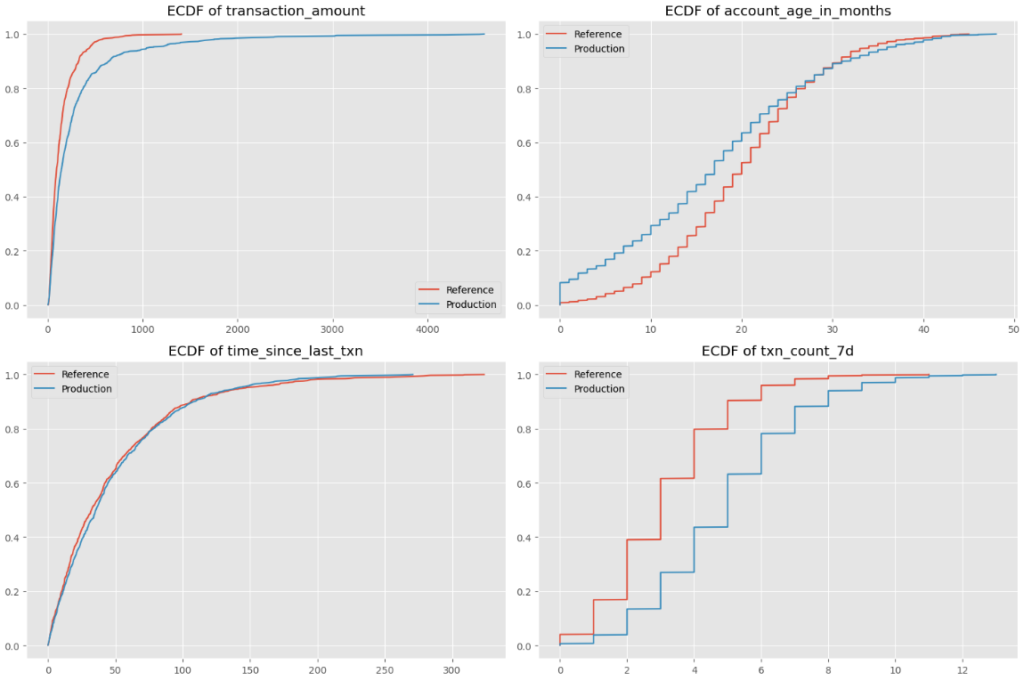
Veamos la función de edad de la cuenta como un ejemplo: el eje x representa la edad de la cuenta (0-50 meses), mientras que el eje Y muestra el ECDF para conjuntos de datos de referencia y producción. El conjunto de datos de producción se sesga hacia cuentas más nuevas, ya que tiene una mayor proporción de observaciones con edades más bajas de la cuenta.
Prueba de chi-cuadrado para características categóricas
Para detectar cambios en las características categóricas y booleanas, me gusta usar la prueba de chi-cuadrado.
Esta prueba compara la distribución de frecuencia de una característica categórica en los conjuntos de datos de referencia y producción, y devuelve dos valores:
- Estadística de chi-cuadrado: Un valor más alto indica un mayor cambio entre los conjuntos de datos de referencia y producción.
- Valor p: Un valor p por debajo de 0.05 sugiere que la diferencia entre los conjuntos de datos de referencia y producción es estadísticamente significativa, lo que indica la posible deriva de características.
Implementación de Python:
# Create empty dataframe with corresponding column names
chi2_results = pd.DataFrame(columns=('Feature', 'Chi-Square Statistic', 'p-value', 'Drift Detected'))
for col in categorical_cols:
# Get normalized value counts for both reference and production datasets
ref_counts = ref_data(col).value_counts(normalize=True)
prod_counts = prod_data(col).value_counts(normalize=True)
# Ensure all categories are represented in both
all_categories = set(ref_counts.index).union(set(prod_counts.index))
ref_counts = ref_counts.reindex(all_categories, fill_value=0)
prod_counts = prod_counts.reindex(all_categories, fill_value=0)
# Create contingency table
contingency_table = np.array((ref_counts * len(ref_data), prod_counts * len(prod_data)))
# Perform Chi-Square test
chi2_stat, p_value, _, _ = chi2_contingency(contingency_table)
drift_detected = p_value < 0.05
# Store results in chi2_results dataframe
chi2_results = pd.concat((
chi2_results,
pd.DataFrame({
'Feature': (col),
'Chi-Square Statistic': (chi2_stat),
'p-value': (p_value),
'Drift Detected': (drift_detected)
})
), ignore_index=True)La estadística de chi-cuadrado de 57.31 con un valor p de 3.72e-14 confirma un gran cambio en nuestra característica categórica, Entered PIN. Este hallazgo se alinea con el histograma a continuación, que ilustra visualmente el cambio:
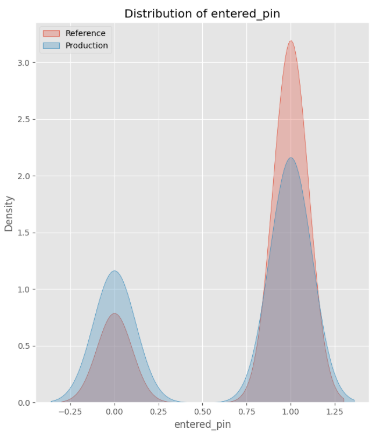
Detectar cambios multivariados
Correlación de Spearman para los cambios en las interacciones por pares
Además de monitorear los cambios de características individuales, es importante rastrear cambios en las relaciones o interacciones entre las característicasconocido como cambios multivariados. Incluso si las distribuciones de las características individuales permanecen estables, los cambios multivariados pueden indicar diferencias significativas en los datos.
Por defecto, pandas ' .corr() La función calcula la correlación de Pearson, que solo captura relaciones lineales entre variables. Sin embargo, Las relaciones entre las características a menudo no son lineales Sin embargo, aún sigue una tendencia consistente.
Para capturar esto, usamos Correlación de Spearman para medir relaciones monotónicas entre características. Captura si las características cambiar En una dirección consistente, incluso si su relación no es estrictamente lineal.
Para evaluar los cambios en las relaciones de características, comparamos:
- Correlación de referencia (
ref_corr): Captura relaciones históricas de características en el conjunto de datos de referencia. - Correlación de producción (
prod_corr): Captura nuevas relaciones de características en la producción. - Diferencia absoluta en la correlación: Mide cuánto han cambiado las relaciones de características entre los conjuntos de datos de referencia y producción. Los valores más altos indican cambios más significativos.
Implementación de Python:
# Calculate correlation matrices
ref_corr = ref_data.corr(method='spearman')
prod_corr = prod_data.corr(method='spearman')
# Calculate correlation difference
corr_diff = abs(ref_corr - prod_corr)Ejemplo: cambio en la correlación
Ahora, veamos la correlación entre transaction_amount y account_age_in_months:
- En
ref_corrla correlación es de 0.00095, lo que indica una relación débil entre las dos características. - En
prod_corrla correlación es -0.0325, lo que indica una correlación negativa débil. - La diferencia absoluta en la correlación de Spearman es 0.0335, que es un cambio pequeño pero notable.
La diferencia absoluta en la correlación indica un cambio en la relación entre transaction_amount y account_age_in_months.
Solía no haber una relación entre estas dos características, pero el conjunto de datos de producción indica que ahora hay una correlación negativa débil, lo que significa que las cuentas más nuevas tienen cantidades de transacciones más altas. ¡Esto es perfecto!
Autoencoder para cambios multivariados complejos y de alta dimensión
Además de monitorear las interacciones por pares, también podemos buscar cambios en más dimensiones en los datos.
Los autoencoders son herramientas poderosas para detectar cambios multivariados de alta dimensióndonde múltiples características cambian colectivamente de formas que pueden no ser evidentes al mirar las distribuciones de características individuales o las correlaciones por pares.
Un autoencoder es una red neuronal que aprende una representación comprimida de datos a través de dos componentes:
- Codificador: Comprime datos de entrada en una representación de dimensión inferior.
- Descifrador: Reconstruye la entrada original de la representación comprimida.
Para detectar cambios, comparamos el salida reconstruida hacia entrada original y calcular el pérdida de reconstrucción.
- Baja pérdida de reconstrucción → El autoencoder reconstruye con éxito los datos, lo que significa que las nuevas observaciones son similares a lo que ha visto y aprendido.
- Alta pérdida de reconstrucción → Los datos de producción se desvían significativamente de los patrones aprendidos, lo que indica una deriva potencial.
A diferencia de las métricas de deriva tradicionales que se centran en Características individuales o relaciones por paresCarscoders Capture dependencias complejas no lineales a través de múltiples variables simultáneamente.
Implementación de Python:
ref_features = ref_data(numeric_cols + categorical_cols)
prod_features = prod_data(numeric_cols + categorical_cols)
# Normalize the data
scaler = StandardScaler()
ref_scaled = scaler.fit_transform(ref_features)
prod_scaled = scaler.transform(prod_features)
# Split reference data into train and validation
np.random.shuffle(ref_scaled)
train_size = int(0.8 * len(ref_scaled))
train_data = ref_scaled(:train_size)
val_data = ref_scaled(train_size:)
# Build autoencoder
input_dim = ref_features.shape(1)
encoding_dim = 3
# Input layer
input_layer = Input(shape=(input_dim, ))
# Encoder
encoded = Dense(8, activation="relu")(input_layer)
encoded = Dense(encoding_dim, activation="relu")(encoded)
# Decoder
decoded = Dense(8, activation="relu")(encoded)
decoded = Dense(input_dim, activation="linear")(decoded)
# Autoencoder
autoencoder = Model(input_layer, decoded)
autoencoder.compile(optimizer="adam", loss="mse")
# Train autoencoder
history = autoencoder.fit(
train_data, train_data,
epochs=50,
batch_size=64,
shuffle=True,
validation_data=(val_data, val_data),
verbose=0
)
# Calculate reconstruction error
ref_pred = autoencoder.predict(ref_scaled, verbose=0)
prod_pred = autoencoder.predict(prod_scaled, verbose=0)
ref_mse = np.mean(np.power(ref_scaled - ref_pred, 2), axis=1)
prod_mse = np.mean(np.power(prod_scaled - prod_pred, 2), axis=1)Los cuadros a continuación muestran la distribución de la pérdida de reconstrucción entre ambos conjuntos de datos.
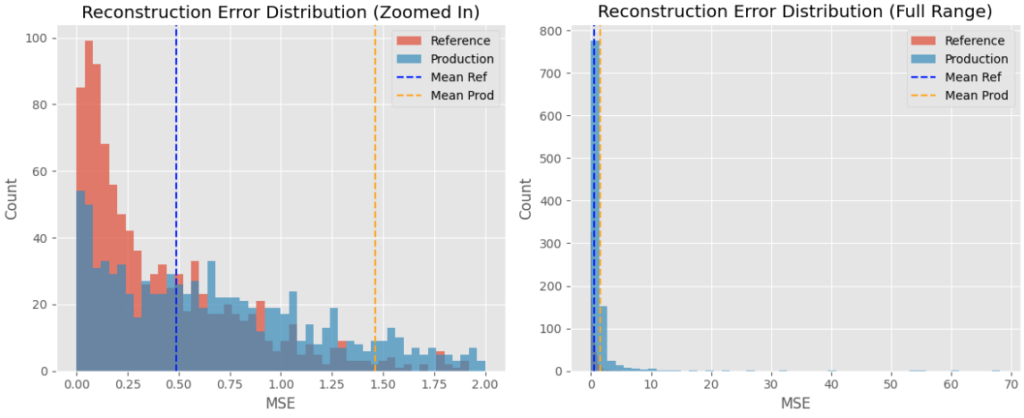
El conjunto de datos de producción tiene un error de reconstrucción medio más alto que el del conjunto de datos de referencia, lo que indica un cambio en los datos generales. Esto se alinea con los cambios en el conjunto de datos de producción con un mayor número de cuentas más nuevas con transacciones de alto valor.
Resumen
El monitoreo del modelo es una responsabilidad esencial, pero a menudo pasada por alto, para los científicos de datos e ingenieros de aprendizaje automático.
Todos los métodos estadísticos llevaron a la misma conclusión, que se alinea con los cambios observados en los datos: detectaron una tendencia en la producción hacia cuentas más nuevas que realizan transacciones de mayor valor. Este cambio resultó en puntajes de modelo más altos, lo que indica un aumento en el fraude potencial.
En esta publicación, cubrí técnicas para detectar la deriva en tres niveles diferentes:
- Drift de puntuación del modelo: Usando Índice de estabilidad de la población (PSI)
- Drift de características individuales: Usando Kolmogorov-Smirnov Test para características numéricas y Prueba de chi-cuadrado Para características categóricas
- Deriva multivariada: Usando Correlación de Spearman para interacciones por pares y Autos para cambios multivariados de alta dimensión.
Estas son solo algunas de las técnicas en las que confío para un monitoreo integral: hay muchos otros métodos estadísticos igualmente válidos que también pueden detectar la deriva de manera efectiva.
Los cambios detectados a menudo apuntan a problemas subyacentes que justifican una mayor investigación. La causa raíz podría ser tan grave como un error de recopilación de datos, o tan menor como un cambio de tiempo como los ajustes de tiempo de ahorro de luz.
También hay fantásticos paquetes de Python, como <a target="_blank" href="http://evidently.ai“>evidentemente .ique automatizan muchas de estas comparaciones. Sin embargo, creo que hay un valor significativo en comprender profundamente las técnicas estadísticas detrás de la detección de deriva, en lugar de depender únicamente de estas herramientas.
¿Cómo es el proceso de monitoreo del modelo en los lugares que ha trabajado?
¿Quieres construir tus habilidades de IA?
Corro el Tienes un semanario y Escriba publicaciones semanales de blog sobre ciencia de datos, proyectos de fin de semana de IA, asesoramiento profesional para profesionales en datos.
Recursos
(Tagstotranslate) Drift del modelo






{kind=link}