 NEWSLETTER
NEWSLETTER
In today's world, Multimodal Large Language Models (MLLM) are advanced systems that process and understand multiple forms of input, such as text and images. By interpreting these various inputs, your goal is to reason through the tasks and generate accurate results. However, MLLM They often fail at complex tasks because they lack structured processes for breaking problems down into smaller steps and instead provide direct answers without clear intermediate reasoning. These limitations reduce the success and efficiency of MLLMs in solving complex problems.
Traditional methods of reasoning in multimodal large language models (MLLM) have many problems. Cue-based methods, such as chain of thought, Uses established steps to copy human reasoning, but has difficulty with difficult tasks. Plant-based methods, such as Tree either Thinking ChartThey try to find ways of reasoning but they are not flexible or reliable. Learning-based methods, such as Monte Carlo Tree Search (MCTS), are slow and do not help with deep thinking. Most MLLM Rely on “direct prediction,” giving short answers without clear steps. Although MCTS works well in games and robotics, it is not suitable for MLLM and collective learning does not generate robust step-by-step reasoning. These problems make it difficult for MLLMs to solve complex problems.
To mitigate these problems, a team of researchers from Nanyang Technological University, Tsinghua University, Baidu and Sun Yat-sen University proposed CommitteesA framework for improving pathfinding reasoning in tree search tasks. Instead of relying on one model, it combines multiple pre-trained models to expand and evaluate candidate paths. This approach differs from traditional methods because it uses a more efficient strategy: multiple models work together, allowing for better performance and reducing errors during the reasoning process.
It consisted of four key steps: Expansion, simulation, backpropagation, and Selection. In the Expansion stage, several models searched for different solutions simultaneously, increasing the variety of possible answers. In the Simulation step, incorrect or less effective routes were eliminated, facilitating the search. During the backpropagation step, the models improved by learning from their past errors and using that knowledge to make better predictions. The last step used a statistical method to choose the best action to take for the model. Reflective reasoning in this process helped the model learn from previous mistakes to make better decisions on similar tasks.
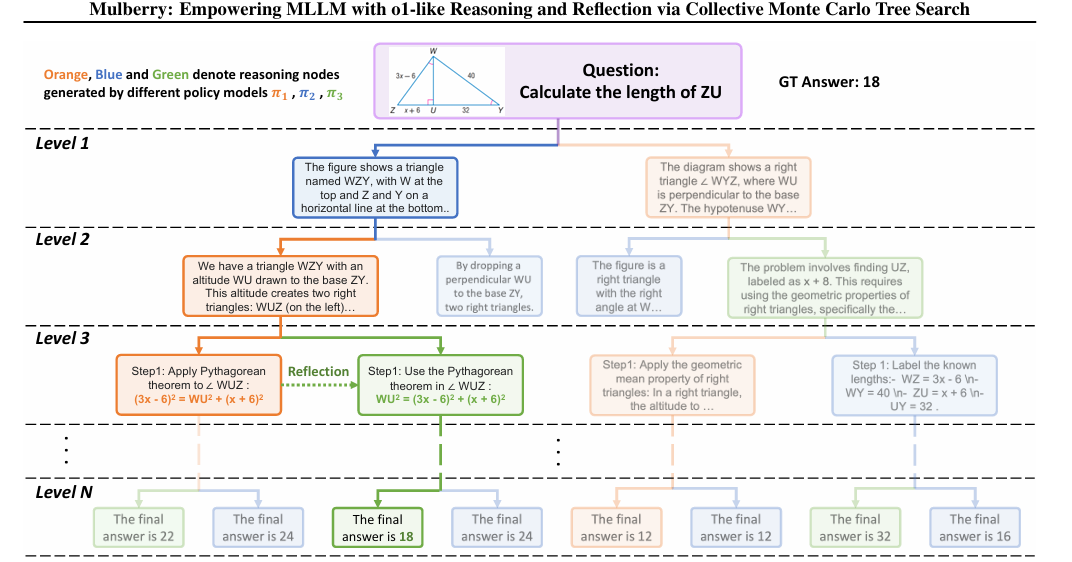
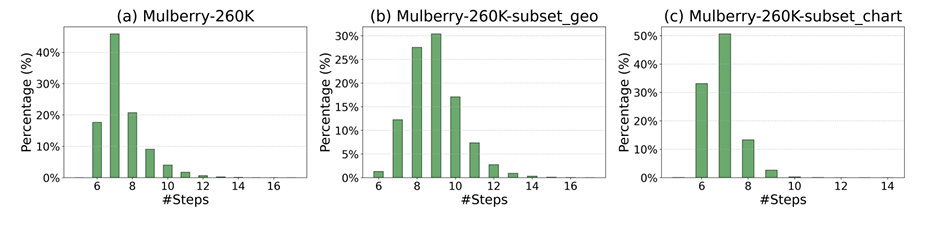
The researchers created the Mulberry-260K data set, which included 260,000 multimodal entry questions, combining text instructions and images from various domains, including general multimodal understanding, mathematics, science, and medical imaging understanding. The data set was constructed using Committees with training limited to 15K samples to avoid overabundance. The reasoning tasks required an average of 7.5 steps, and most tasks fall within the 6 to 8 steps range. CoMCTS was implemented using four models: GPT4o, Qwen2-VL-7B, LLaMA-3.2-11B-Vision-Instruct, and Qwen2-VL-72B. The training process involved a batch size of 128 and a learning rate 1e-5 during two periods.
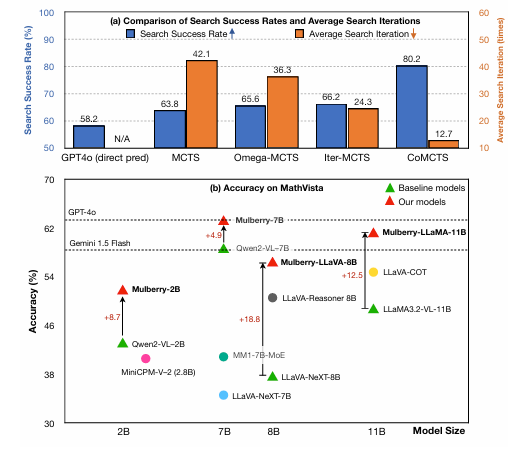
The results demonstrated significant improvements in performance over the reference models, with gains of +4.2% and +7.5% for Qwen2-VL-7B and LLaMA-3.2-11B-Vision-Instruct, respectively. Additionally, the Mulberry dataset outperformed reasoning models such as LLaVA-Reason-8B and Insight-V-8Bshowing superior performance on several benchmarks. After the evaluation, Committees improved its performance by 63.8%. Involving reflective reasoning data led to slight improvements in model performance. This reveals the effects of Mulberry-260K and CoMCTS in improving reasoning accuracy and flexibility.
In conclusion, the proposal Committees proves to be an approach that improves reasoning in multimodal large language models (MLLM) by incorporating collective learning into tree search methods. This framework improved the efficiency of searching for a reasoning path, as demonstrated by the Mulberry-260K data set and the Mulberry model, which outperforms traditional models on complex reasoning tasks. The proposed methods provide valuable information for future research, can serve as a basis for the advancement of MLLMs, and can act as a basis for developing more efficient models capable of handling increasingly complex tasks.
Verify he Paper and GitHub page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
Trending: LG ai Research launches EXAONE 3.5 – three frontier-level bilingual open-source ai models that deliver unmatched instruction following and broad context understanding for global leadership in generative ai excellence….
Divyesh is a Consulting Intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of technology Kharagpur. He is a data science and machine learning enthusiast who wants to integrate these leading technologies in agriculture and solve challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}