 NEWSLETTER
NEWSLETTER
Large language models (LLMs), initially limited to text-based processing, faced significant challenges in understanding visual data. This limitation led to the development of visual language models (VLMs), which integrate visual understanding with language processing. Early models such as VisualGLM, built on architectures such as BLIP-2 and ChatGLM-6B, represented initial efforts in multimodal integration. However, these models often relied on shallow alignment techniques, which restricted the depth of visual and linguistic integration, highlighting the need for more advanced approaches.
Subsequent advances in VLM architecture, exemplified by models such as CogVLM, focused on achieving a deeper fusion of vision and language features, thereby improving natural language performance. The development of specialized datasets, such as the synthetic OCR dataset, played a crucial role in improving the OCR capabilities of the models, enabling broader applications in document analysis, GUI understanding, and video understanding. These innovations have significantly expanded the potential of LLMs, driving the evolution of visual language models.
This research paper by Zhipu ai and Tsinghua University introduces the CogVLM2 family, a new generation of visual language models designed for better image and video understanding, including models such as CogVLM2, CogVLM2-Video, and GLM-4V. Advancements include a higher-resolution architecture for fine-grained image recognition, exploration of broader modalities such as visual foundation and GUI agents, and innovative techniques such as post-sampling for efficient image processing. The paper also emphasizes the commitment to open source these models, providing valuable resources for further research and development of visual language models.
The CogVLM2 family integrates architectural innovations, including Visual Expert and high-resolution cross-modules, to improve visual and linguistic feature fusion. The training process for CogVLM2-Video involves two stages: Instruction Adjustment, using fine-grained caption data and Q&A datasets with a learning rate of 4e-6, and Temporal Grounding Adjustment on the TQA dataset with a learning rate of 1e-6. Video input processing employs 24 sequential frames, with a convolution layer added to the Vision Transformer model for efficient compression of video features.
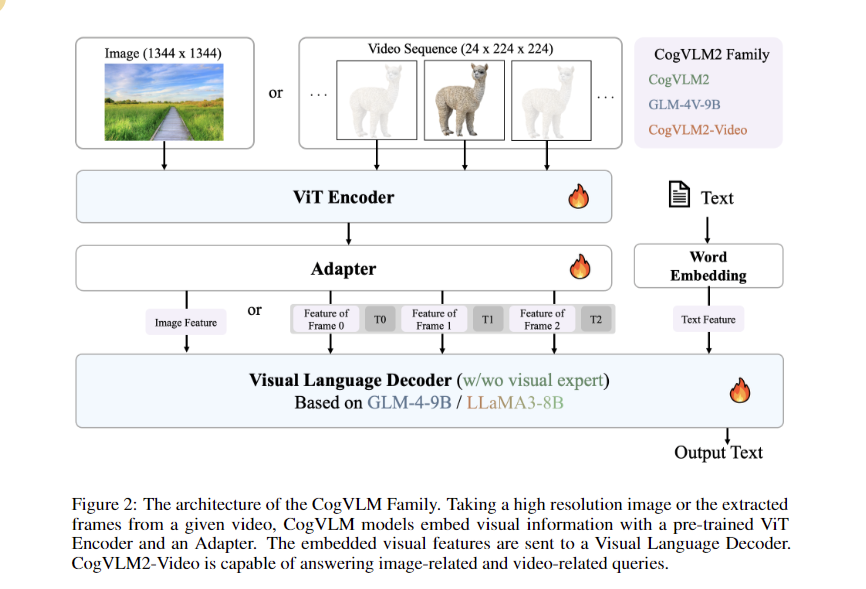
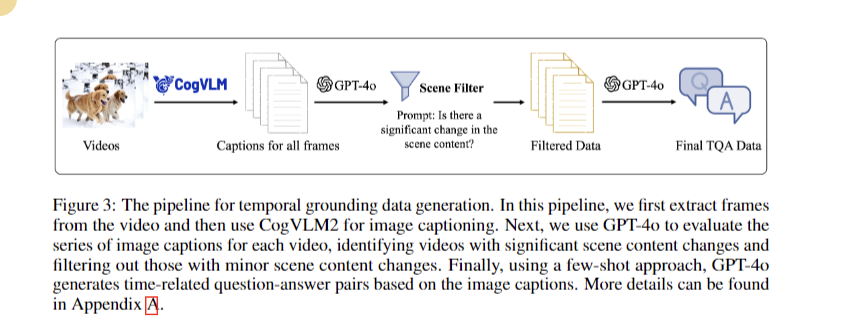
The CogVLM2 methodology utilizes substantial datasets, including 330,000 video samples and an in-house video quality control dataset, to improve temporal understanding. The evaluation process involves generating and evaluating video captions using GPT-4o to filter videos based on changes in scene content. Two variants of the model, cogvlm2-video-llama3-base and cogvlm2-video-llama3-chat, serve different application scenarios, with the latter being optimized for better temporal matching. The training process is carried out on an 8-node NVIDIA A100 cluster and completes in approximately 8 hours.
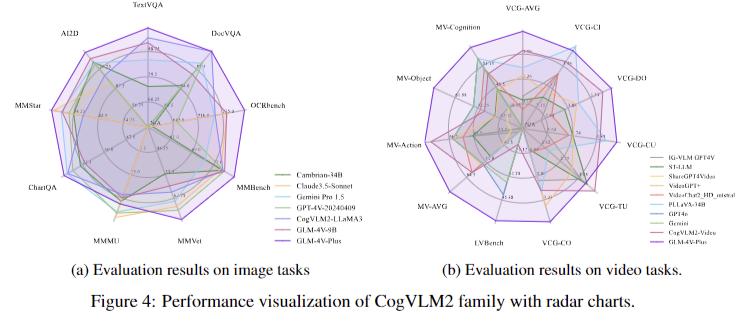
CogVLM2, in particular the CogVLM2-Video model, achieves state-of-the-art performance on multiple video question answering tasks, excelling in benchmarks such as MVBench and VideoChatGPT-Bench. The models also outperform existing models, including larger ones, on image-related tasks, with notable success in OCR understanding, graph and diagram understanding, and general question answering. A thorough evaluation reveals the models’ versatility in tasks such as video generation and summarization, establishing CogVLM2 as a new standard for visual language models in both image and video understanding.
In conclusion, the CogVLM2 family marks a significant advancement in the integration of visual and language modalities, addressing the limitations of traditional text-only-based models. The development of models capable of interpreting and generating content from images and videos expands their application in fields such as document analysis, GUI understanding, and video grounding. Architectural innovations, including Visual Expert and high-resolution cross-modules, improve performance on complex visual language tasks. The CogVLM2 series sets a new benchmark for open-source visual language models, with detailed methodologies for dataset generation supporting their robust capabilities and future research opportunities.
Take a look at the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and LinkedInJoin our Telegram Channel.
If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml

Shoaib Nazir is a Consulting Intern at MarktechPost and has completed his dual M.tech degree from Indian Institute of technology (IIT) Kharagpur. Being passionate about data science, he is particularly interested in the various applications of artificial intelligence in various domains. Shoaib is driven by the desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and solving real-world problems fuels his continuous learning and contribution to the field of ai.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}