 NEWSLETTER
NEWSLETTER
Large language models (LLMs) have revolutionized software development by enabling code completion, generation of functional code from instructions, and complex code modifications to fix bugs and implement features. While these models excel at generating code from natural language instructions, significant challenges remain in evaluating the quality of code generated by LLM. Critical aspects that require evaluation include code correctness, efficiency, security vulnerabilities, compliance with best practices, and alignment with developer preferences. The evaluation process becomes particularly complex when balancing these multiple dimensions of quality simultaneously. The systematic study of code preferences and the development of effective preference models remain to be explored despite their crucial role in optimizing LLM performance and ensuring that the generated code meets real-world development standards.
Preference optimization has become a crucial step in aligning LLMs with desired outcomes, employing both offline and online algorithms to improve model performance. Previous approaches have primarily relied on collecting preference data through paired comparisons of preferred and rejected responses. These methods typically collect data through human annotations, LLM comments, code execution results, or existing preference models. While some techniques have explored training LLM systems as a judge, these approaches have largely focused on natural language generation rather than specialized code generation. Existing methods face particular challenges in the code domain, where preference principles are more specialized and complex, involving technical aspects such as efficiency and security that are significantly more difficult to evaluate than general language preferences. The code preference labeling process presents unique challenges that existing approaches have not adequately addressed.
Researchers at the University of Illinois Urbana-Champaign and AWS ai Labs have developed CODEFAVORa robust framework for training code preference models, along with CODEPREFBENCH, a comprehensive evaluation benchmark. CODEFAVOR implements a pairwise modeling approach to predict preferences between code pairs based on user-specified criteria. The framework introduces two innovative synthetic data generation methods: Commit-Instruct, which transforms pre- and post-commit code fragments into preference pairs, and Critic-Evol, which generates preference data by enhancing faulty code samples using an LLM. critical. The evaluation framework, CODE BANKIt comprises 1,364 carefully selected preference tasks that evaluate various aspects, including code correctness, efficiency, security, and general developer preferences. This dual approach addresses both the technical challenge of building effective preference models and the empirical question of understanding how human annotators and LLMs align on their code preferences.
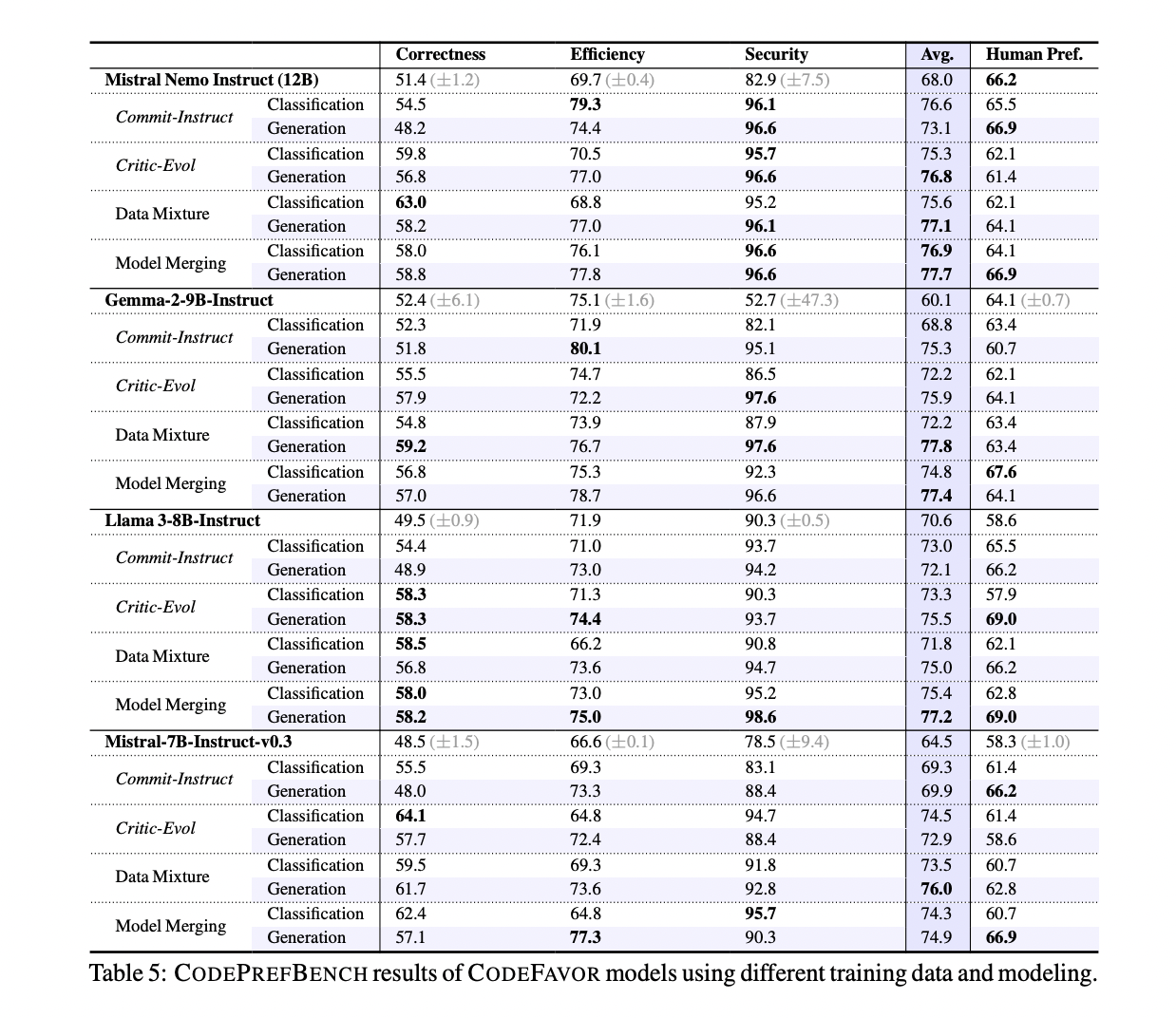
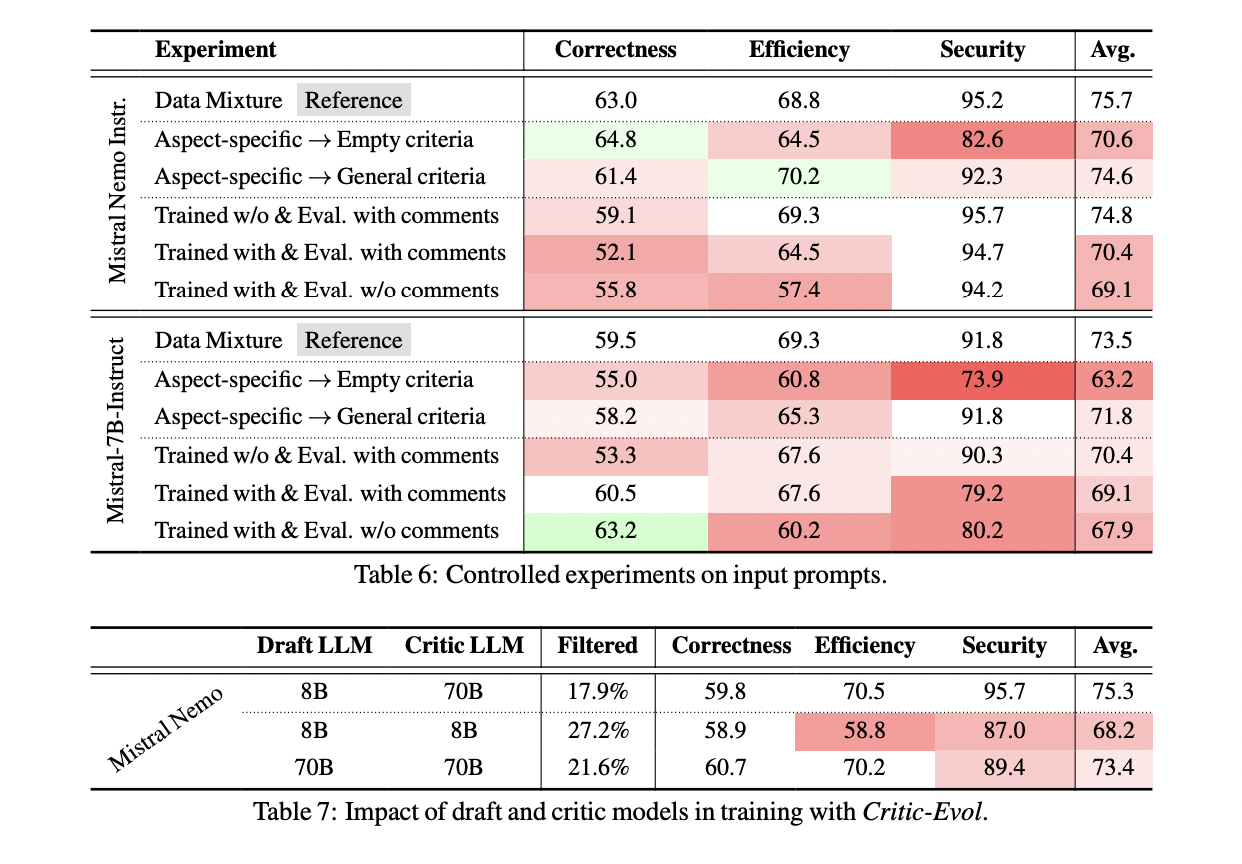
The CODEFAVOR framework implements a sophisticated pairwise modeling approach using decoder-based transformers to learn code preferences. The model processes inputs comprising an instruction, two candidate codes, and a specific criterion formatted into a structured message. The framework offers two distinct output designs: a classification approach that makes binary predictions through a probability comparison of the next unique token, and a generative approach that provides natural language explanations for preference decisions. The architecture incorporates two innovative synthetic data generation methods: Commit-Instruct, which processes raw code commits through a three-step process of reasoning, filtering, and reformulating, and Critic-Evol, which generates preference data through of a three-stage failure process. sampling, filtering reviews and code review. In the Commit-Instruct process, a critical LLM analyzes commitments to transform them into training samples, while Critic-Evol uses the interaction between a weaker draft model and a stronger critical model to generate synthetic preference pairs.
Researchers have conducted a comprehensive evaluation of code preference models, including information from human developers' annotations, as well as comparisons between existing LLMs and the proposed CODEFAVOR framework.
Human annotation efforts reveal several key insights. The developer team is made up of experienced programmers, two-thirds of whom have computer science degrees and 95% of whom have more than two years of coding experience. Developers show great confidence in their annotations, particularly in the correctness of the code, although they have more difficulty evaluating efficiency and security aspects. The annotation process is time-consuming, with each task requiring an average of 7.8 minutes per developer.
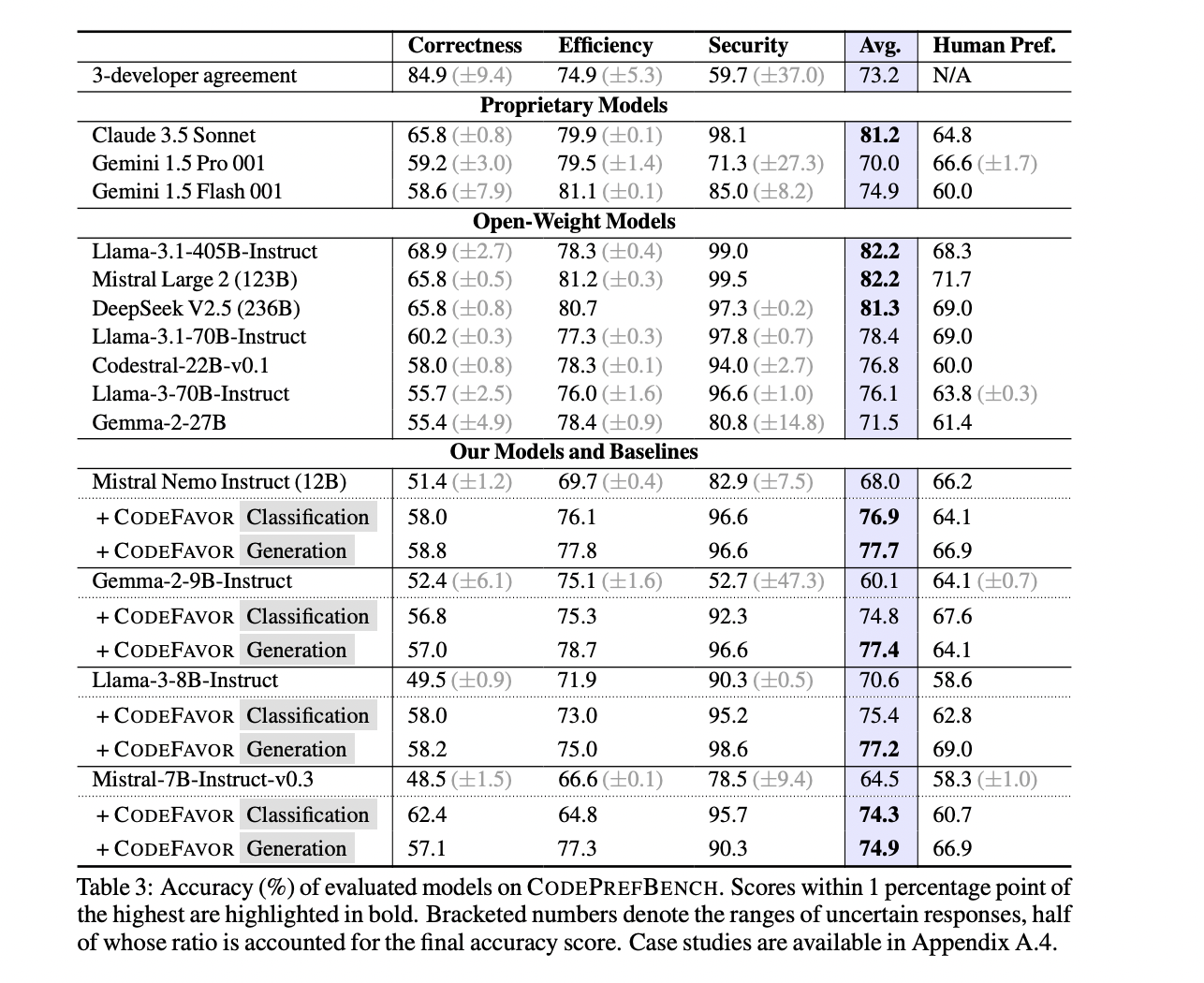
In terms of accuracy, human developers excel at identifying the correct code, achieving a resolution rate of 84.9%. However, their performance drops in efficiency (74.9%) and is weaker in security (59.7%), as they have difficulty accurately evaluating properties of non-functional code that may require specialized expertise. .
The researchers then evaluate a variety of existing LLMs, including large-scale models like Llama-3.1-405B-Instruct and smaller models like Gemma-2-9B-Instruct. While larger models generally outperform smaller ones, the CODEFAVOR framework can significantly improve the performance of smaller models, in some cases even outperforming larger critical models.
Specifically, CODEFAVOR improves the overall performance of the smaller 7-12B models by 9.3% to 28.8% relative to their base performance. In terms of code correctness, CODEFAVOR improves smaller models by 8.8 to 28.7%, allowing them to outperform the critical model (Llama-3-70B-Instruct) by up to 12%. Similar improvements are seen in efficiency and safety preferences.
Importantly, CODEFAVOR models not only demonstrate strong performance but also offer significant cost advantages. While human annotation costs about $6.1 per task, the CODEFAVOR classification model fine-tuned in Mistral Nemo Instruct is five orders of magnitude cheaper, 34 times less expensive than the critical Llama-3-70B-Instruct model, while still achieving results comparable or better. preference results.
Researchers have introduced CODEFAVOR, a robust framework for training pairwise code preference models using synthetic data generated from code commits and LLM critiques. They selected CODEPREFBENCH, a benchmark of 1364 code preference tasks, to investigate the alignment between human and LLM preferences in terms of correctness, efficiency, and security. CODEFAVOR significantly increases the ability of smaller instruction-following models to learn code preferences, achieving performance equivalent to larger models at a fraction of the cost. The study offers insights into the challenges of aligning code generation preferences across multiple dimensions.
look at the Paper and amazon-science/llm-code-preference” target=”_blank” rel=”noreferrer noopener”>GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(Trend) LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLM) for Intel PCs
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}