
The design of neuromorphic sensory processing units (NSPUs) based on temporal neural networks (TNNs) is a very challenging task due to the dependence on manual and laborious hardware development processes. TNNs have been identified as holding great promise for cutting-edge real-time ai applications, primarily because they are energy efficient and bioinspired. However, the available methodologies lack automation and are not very accessible. Consequently, the design process becomes complex, requires a lot of time and specialized knowledge. It is by overcoming these challenges that the full potential of TNNs for efficient and scalable processing of sensory signals can be unlocked.
Current approaches to TNN development are fragmented workflows, as software simulations and hardware designs are handled separately. Advances like the ASAP7 and TNN7 libraries made some aspects of the hardware efficient, but they are still proprietary tools that require significant expertise. Process fragmentation restricts usability, prevents easier exploration of design configurations with greater computational overhead, and cannot be used for more application-specific rapid prototyping or large-scale deployment purposes.
Researchers at Carnegie Mellon University present TNNGen, a unified and automated framework for designing TNN-based NSPUs. The innovation lies in the integration of software-based functional simulation with hardware generation in a single optimized workflow. It combines a PyTorch-based simulator, which models spike timing dynamics and evaluates application-specific metrics, with a hardware generator that automates RTL generation and layout design using PyVerilog. By utilizing custom TNN7 macros and integrating a variety of libraries, this framework achieves significant improvements in simulation speed and physical design. Additionally, its predictive capabilities facilitate accurate forecasting of silicon metrics, thereby decreasing reliance on computationally demanding EDA tools.
TNNGen is organized around two main elements. The functional simulator, built with PyTorch, supports adaptive TNN configurations, allowing rapid examination of various model architectures. It has GPU acceleration and precise peak timing modeling, ensuring high simulation speed and accuracy. The hardware generator converts PyTorch models into optimized physical and RTL designs. Using libraries such as TNN7 and custom TCL scripts, it automates synthesis and placement and routing processes while supporting multiple technology nodes such as FreePDK45 and ASAP7.
TNNGen achieves excellent performance in both clustering accuracy and hardware efficiency. TNN designs for time series clustering tasks show competitive performance with the best deep learning techniques while dramatically reducing computational resource utilization. The approach brings significant improvements in energy efficiency, achieving a reduction in die area and leakage power compared to conventional approaches. Additionally, design execution time is dramatically reduced, especially for larger designs, which benefit more from optimized workflows. Additionally, the comprehensive forecasting instrument provides accurate estimates of hardware parameters, allowing researchers to evaluate design feasibility without the need to engage in physical hardware procedures. Together, these findings position TNNGen as a viable approach to optimize and accelerate the creation of energy-efficient neuromorphic systems.
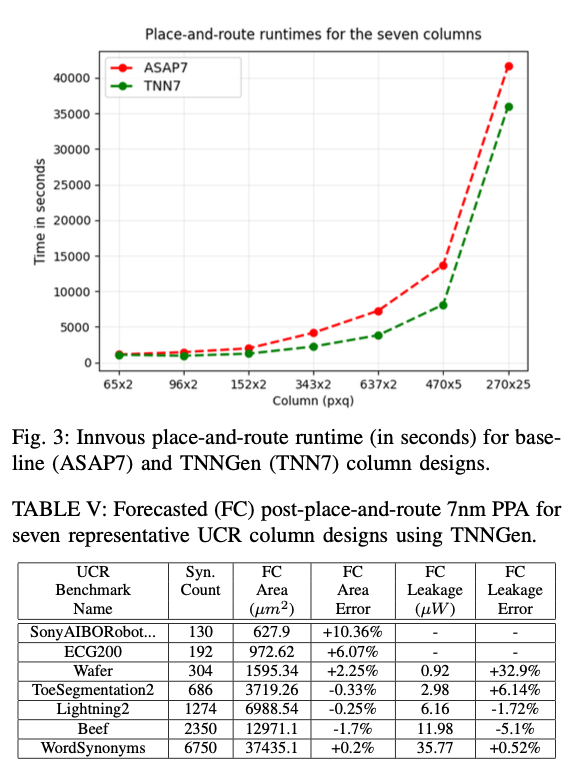
TNNGen is the next step in the fully automated development of TNN-based NSPUs by unifying simulation and hardware generation into an accessible and efficient framework. The approach addressed key challenges in the manual design process and made this tool much more scalable and usable for cutting-edge ai applications. Future work would involve expanding its capabilities towards supporting more complex TNN architectures and a much broader range of applications to become a critical enabler of sustainable neuromorphic computing.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
Trending: LG ai Research launches EXAONE 3.5 – three frontier-level bilingual open-source ai models that deliver unmatched instruction following and broad context understanding for global leadership in generative ai excellence….
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. He is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}