
Introduction
The article introduces Anthropic's latest generative ai large language model, Claude 3.5 Sonnet, which is highly proficient in arithmetic, reasoning, coding, and multilingual activities. It also covers its vision capabilities, real-world uses, safety precautions, and future prospects with models like Haiku and Opus. The article highlights the important contribution of Claude 3.5 Sonnet to the development of ai.
General description
- Understand how Anthropic's Claude 3.5 Sonnet improves performance in reasoning, mathematics, coding, and multilingual tasks.
- Explore Claude 3.5 Sonnet's capabilities in visual reasoning and transcribing text from images.
- Learn practical uses of Claude 3.5 Sonnet in tools such as APIs for natural language processing and data extraction.
- Discover security measures in Claude 3.5 Sonnet that ensure privacy and ASL-2 compliance.
- Anticipates future Claude models like Haiku and Opus, and improvements in memory and new modalities.
What is Claude's sonnet 3.5?
In March 2024, Anthropic introduced its Claude 3 family of models, setting a new standard for performance and profitability. GPT-4o and Gemini 1.5 Pro surpassed Claude 3 within a few months in both areas. Now it is time for Anthropic to return with its Claude 3.5 Sonnet, which is the best model in both performance and profitability.
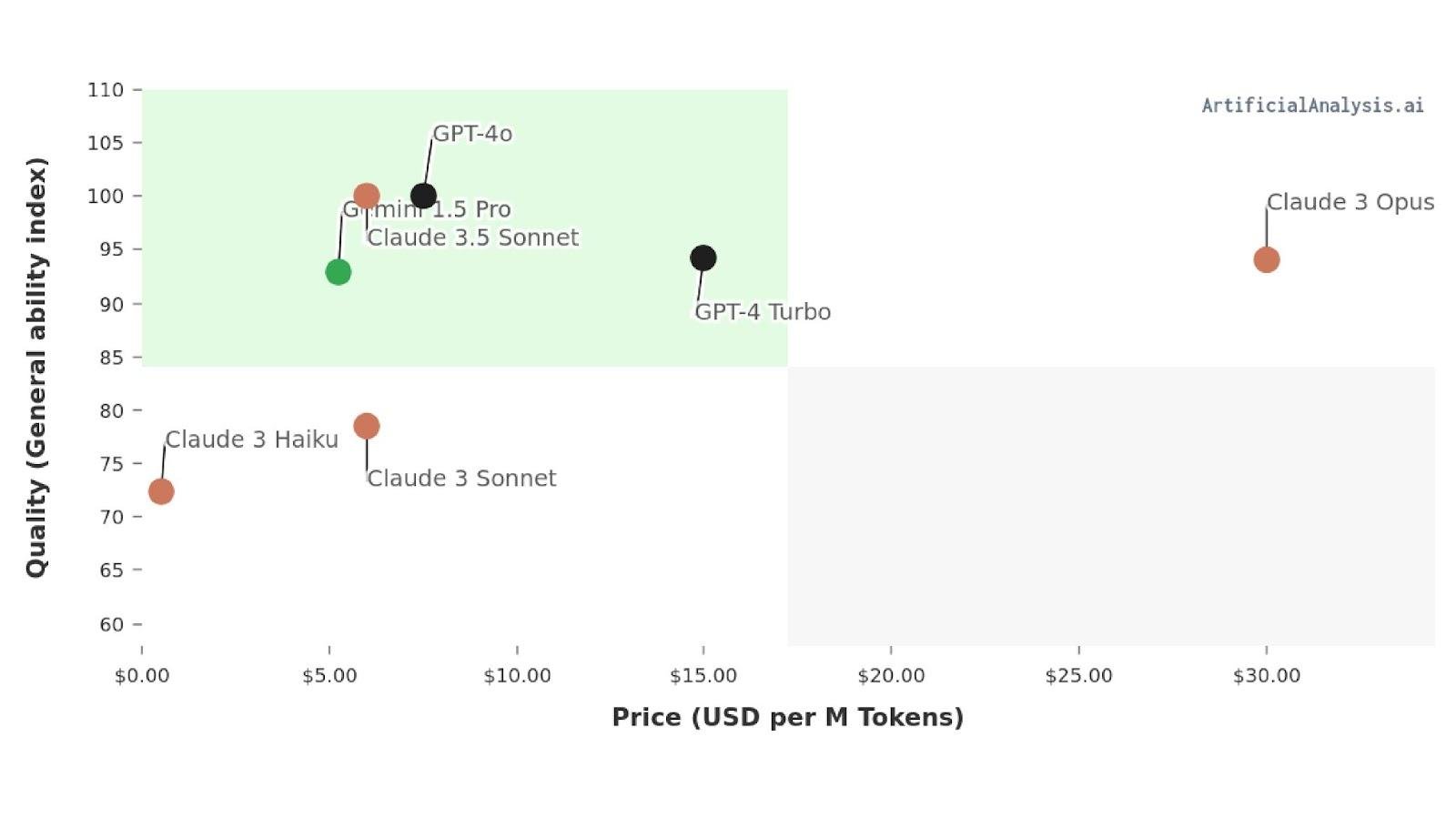
As we can see in the image above, the Claude 3.5 Sonnet has the best quality and is less expensive than the previously better performing GPT-4o model.
Reasoning and answering questions
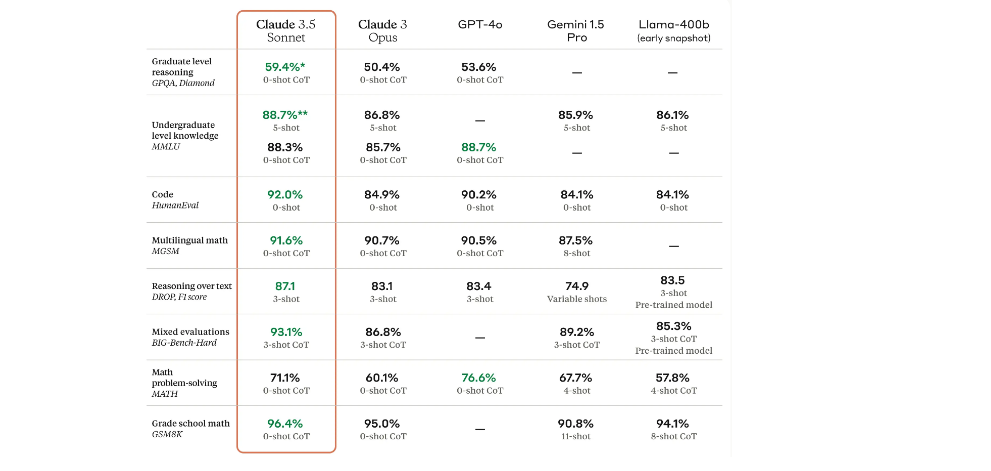
It sets new benchmarks for most industry-standard metrics covering reasoning, reading comprehension, math, science, and coding.
- GPQA (Graduate Level Questions and Answers): Claude 3.5 Sonnet leads with 59.4% (0 shots) and 67.2% (5 shots), outperforming others.
- MMLU (General Reasoning): He scores the highest with 90.4% (5 shots), showing superior reasoning abilities.
- MATHEMATICS (Mathematical problem solving): Claude 3.5 Sonnet achieves 71.1% (0 shots), higher than previous models.
- HumanEval (Python coding): It excels with a score of 92.0%, indicating great mastery of coding.
- MGSM (Multilingual Mathematics): The model obtains a score of 91.6% (0-shot), leading in multilingual mathematics.
- DROP (Reading Comprehension): It reaches 87.1% (F1 Score, 3 shots), showing strong comprehension skills.
- BIG-Bench Hard (mixed evaluations): It scores 93.1% (3 shots), indicating strong performance on mixed tasks.
- GSM8K (Elementary School Mathematics): Claude 3.5 Sonnet leads with 96.4% (0 points), demonstrating excellent math problem-solving skills.
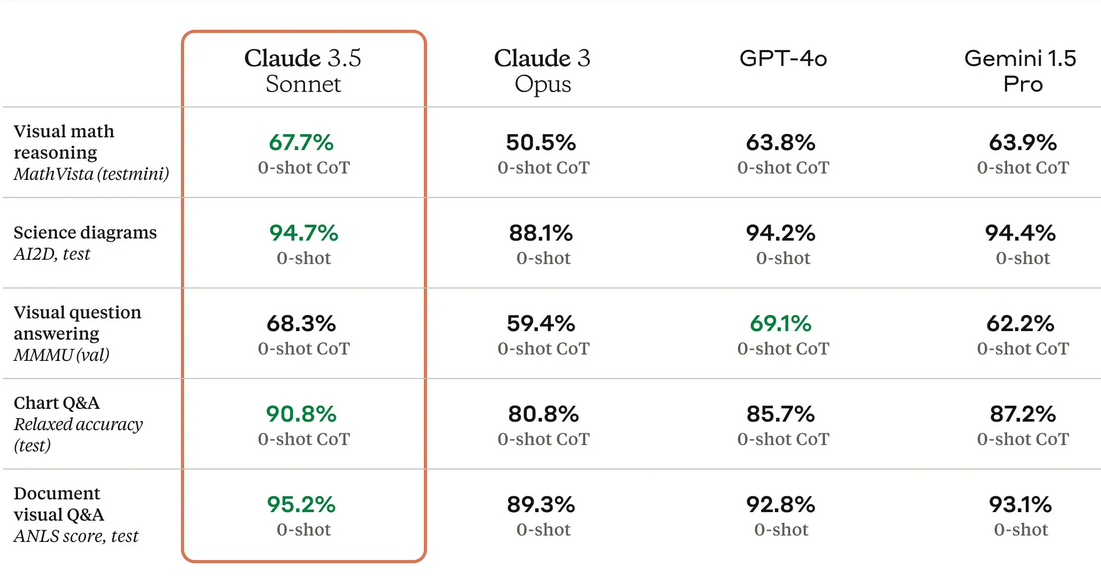
Vision capabilities
Claude 3.5 Sonnet is the most powerful vision model in the standard vision benchmarks. It excels at visual reasoning tasks, such as interpreting charts and graphs, and accurately transcribes text from imperfect images.
You can use external tools depending on the task at hand and perform various tasks like returning API calls with natural language requests, extracting structured data, answering questions by searching databases, etc. We can even learn from Anthropic courses on GitHub itself on how to integrate tools.
Artifacts
Anthropic launched a new feature that revolutionizes user interaction with Claude. When users request content such as code snippets, text documents, or website designs, these artifacts now appear in a dedicated window next to their conversation. This enhancement not only improves usability but also sets a new standard for interactive ai features.
Now let's test the vision capabilities of the model with artifacts.
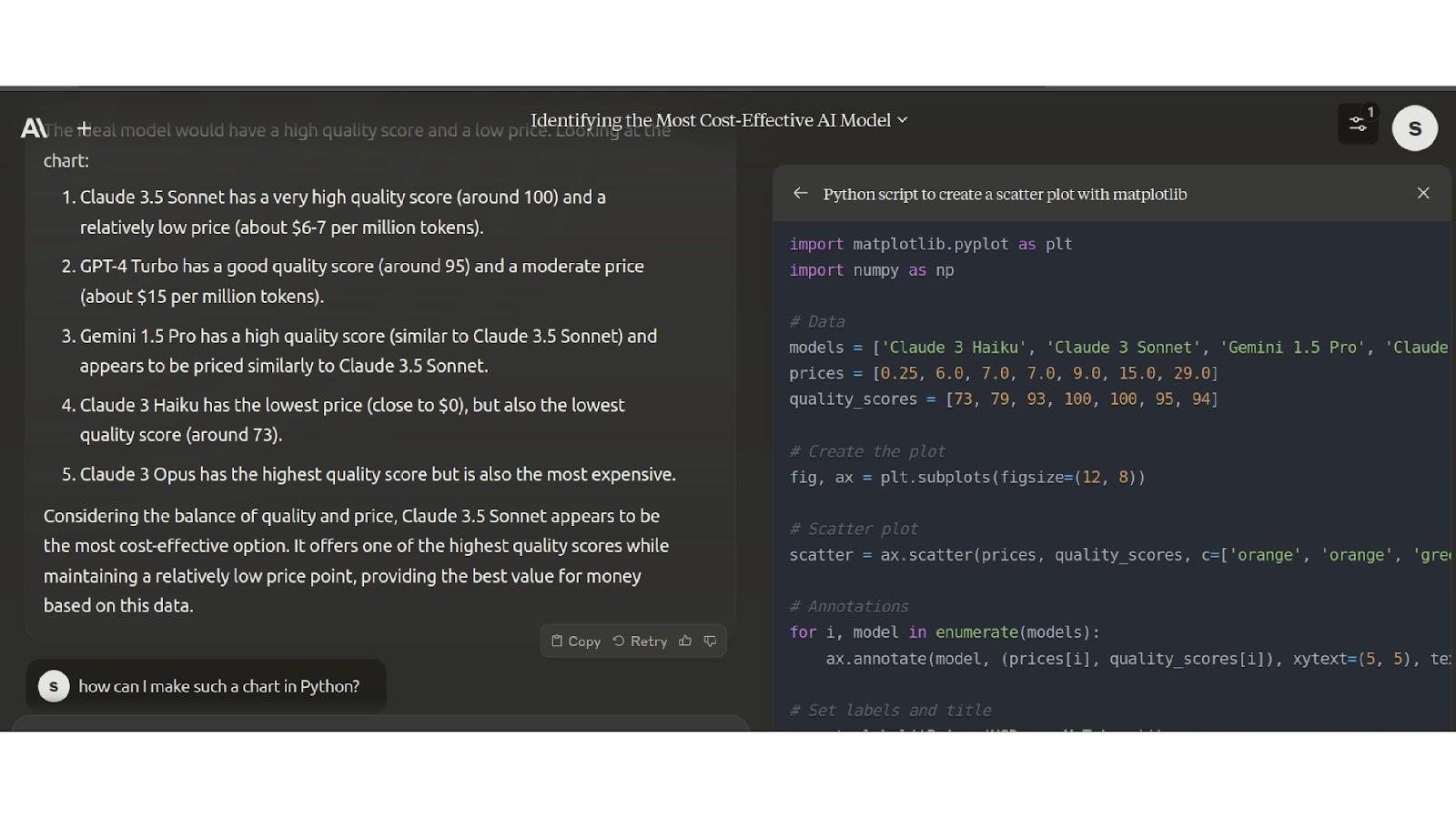
Here, we have given the model the “quality vs price” graph taken from the above and asked “Which model is more profitable based on this graph?”
As we can see in the image, it answers the question correctly.
Then we asked, “How can I make a graph like that in Python?” The model generated the code and displayed it on the side.
We can enable the artifact feature in the 'feature preview' if it is not already enabled.
And Claude 3.5 Sonnet can also recognize that the graph shows that it is the model with the best performance.
How to use?
Claude 3.5 Sonnet is the default model in Claude.ai chat. In the free version, there are limits on the number of messages per day that may vary depending on traffic. If we can upgrade to Pro, we can also get access to the Claude 3 Haiku and Opus models.
We can also access the model through the Anthropic API. It costs $3/1 million tokens and $15/1 million tokens for entry and exit respectively.
Security and privacy
All models undergo extensive testing to minimize misuse. Despite its leap in intelligence, Claude 3.5 Sonnet maintains an ASL-2 security level, verified through rigorous red team assessments. All current LLMs seem to be ASL-2.
Claude 3.5 Sonnet was evaluated by the UK artificial intelligence Security Institute before deployment, and the results were shared with the US artificial intelligence Security Institute.
Feedback from policy experts and organizations like Thorn has been integrated to address emerging abuse trends. These insights have helped refine the classifiers and improve the model's resilience to various abuses.
This model does not use user-submitted data to train generative models unless explicitly permitted by the user, ensuring strong user privacy protection.
Conclusion
Like the Claude 3 family, the Haiku and Opus models will be launched soon. On top of that, features like memory and new modalities are likely to be added. And of course, expect new models from OpenAI and Google as competition increases.
Frequent questions
A. It is Anthropic's latest ai model, which excels in arithmetic, reasoning, coding and multilingual tasks.
A. It leads in various metrics such as GPQA, MMLU, MATH, HumanEval, MGSM, DROP, BIG-Bench Hard and GSM8K.
A. Excels at visual reasoning, interpreting charts and graphs, and transcribing text from imperfect images.






{kind=link}