 NEWSLETTER
NEWSLETTER
Understanding video has long presented unique challenges for ai researchers. Unlike static images, videos involve intricate temporal dynamics and spatio-temporal reasoning, making it difficult for models to generate meaningful descriptions or answer context-specific questions. Problems such as hallucinations, where models fabricate details, further compromise the reliability of existing systems. Despite advances with models such as GPT-4o and Gemini-1.5-Pro, achieving human-level video understanding remains a complex task. Accurate perception of events and understanding of sequence, along with reducing hallucinations, are crucial obstacles to overcome.
ByteDance researchers have introduced Tarsier2, a large vision and language model (LVLM) with 7 billion parameters, designed to address the core challenges of video understanding. Tarsier2 excels at generating detailed video descriptions, outperforming models like GPT-4o and Gemini-1.5-Pro. Beyond the video descriptions, it demonstrates strong performance on tasks such as question answering, grounding, and embodied intelligence. With an expanded pre-training dataset of 40 million video-text pairs, detailed temporal alignment, and direct preference optimization (DPO) during training, Tarsier2 achieves notable improvements. For example, on the DREAM-1K data set, it outperforms GPT-4o by 2.8% and Gemini-1.5-Pro by 5.8% in F1 scores.
Technical innovations and benefits
Tarsier2 integrates several technical advances to improve performance. The model architecture includes a vision encoder, a vision adapter, and a large language model, combined into a three-stage training process:
- Pre-workout: A dataset of 40 million video-text pairs, enriched with commentary videos that capture both low-level actions and high-level plot details, provides a solid foundation for learning.
- Supervised Tuning (SFT): Detailed temporal alignment during this stage ensures that the model accurately associates events with corresponding video frames, reducing hallucinations and improving accuracy.
- Direct Preference Optimization (DPO): This phase uses automatically generated preference data to refine the model's decision making and minimize hallucinations.
These advances not only improve the generation of detailed video descriptions, but also improve the overall versatility of the model in video-centric tasks.
Results and insights
Tarsier2 achieves impressive results on multiple benchmarks. Human evaluations reveal an 8.6% performance advantage over GPT-4o and a 24.9% improvement over Gemini-1.5-Pro. On the DREAM-1K benchmark, it becomes the first model to exceed an overall recall score of 40%, highlighting its ability to comprehensively detect and describe dynamic actions. Additionally, it sets new performance records on 15 public benchmarks, including tasks such as video question answering and temporal reasoning. In the ET Bench-Grounding test, Tarsier2 achieves the highest average F1 score of 35.5%, underscoring its capabilities in temporal understanding. Ablation studies further underscore the critical role of the expanded pre-training dataset and DPO phase in improving performance metrics such as F1 scores and accuracy.
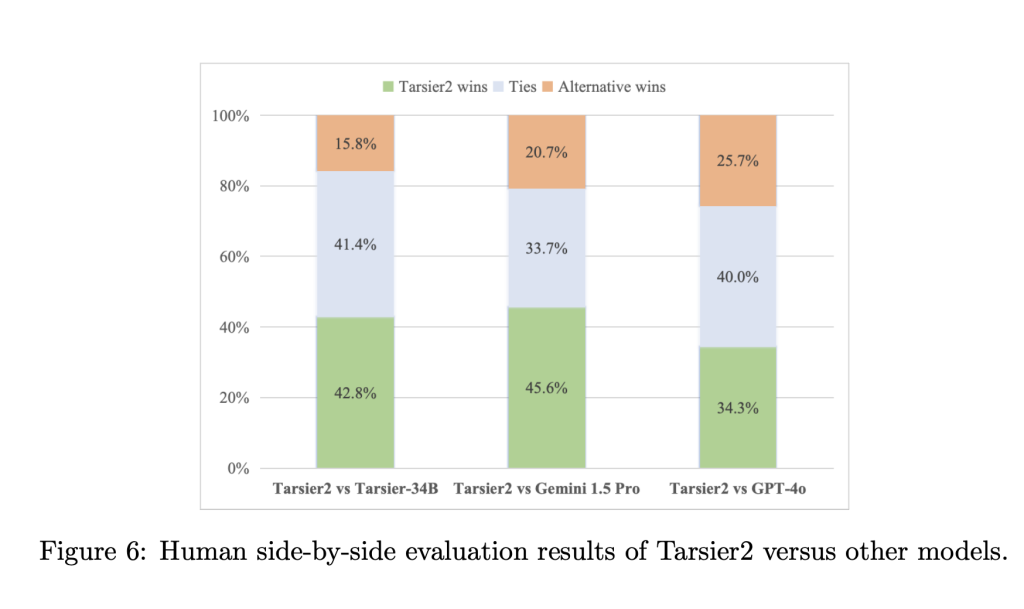
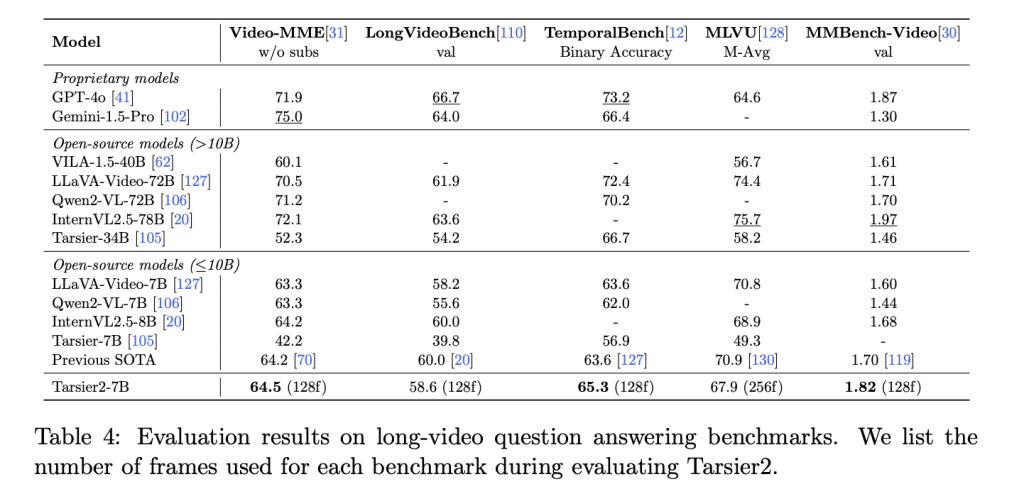
Conclusion
Tarsier2 marks an important step forward in video understanding by addressing key challenges such as temporal alignment, hallucination reduction, and data sparsity. ByteDance researchers have created a model that not only outperforms leading alternatives on key metrics, but also provides a scalable framework for future advancements. As video content continues to dominate digital media, models like Tarsier2 have immense potential for applications ranging from content creation to smart surveillance.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 65,000 ml.
Recommend open source platform: Parlant is a framework that transforms the way ai agents make decisions in customer-facing scenarios. (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. He is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.






{kind=link}