Retrieval-augmented generation (RAG) systems are transforming ai by enabling large language models (LLMs) to access and integrate information from external vector databases without needing fine-tuning. This approach allows LLMs to deliver accurate, up-to-date responses by dynamically retrieving the latest data, reducing computational costs, and improving real-time decision-making.
For example, companies like JPMorgan Chase use RAG systems to automate the analysis of financial documents, extracting key insights crucial for investment decisions. These systems have allowed financial giants to process thousands of financial statements, contracts, and reports, extracting key financial metrics and insights that are essential for investment decisions. However, a challenge arises when dealing with non-machine-readable formats like scanned PDFs, which require Optical Character Recognition (OCR) for accurate data extraction. Without OCR technology, vital financial data from documents like S-1 filings and K-1 forms cannot be accurately extracted and integrated, limiting the effectiveness of the RAG system in retrieving relevant information.
In this article, we’ll walk you through a step-by-step guide to building a financial RAG system. We’ll also explore effective solutions by Nanonets for handling financial documents that are machine-unreadable, ensuring that your system can process all relevant data efficiently.
Understanding RAG Systems
Building a Retrieval-Augmented Generation (RAG) system involves several key components that work together to enhance the system’s ability to generate relevant and contextually accurate responses by retrieving and utilizing external information. To better understand how RAG systems operate, let’s quickly review the four main steps, starting from when the user enters their query to when the model returns its answer.
How does information flow in a RAG app
1. User Enters Query
The user inputs a query through a user interface, such as a web form, chat window, or voice command. The system processes this input, ensuring it is in a suitable format for further analysis. This might involve basic text preprocessing like normalization or tokenization.
The query is passed to the Large Language Model (LLM), such as Llama 3, which interprets the query and identifies key concepts and terms. The LLM assesses the context and requirements of the query to formulate what information needs to be retrieved from the database.
2. LLM Retrieves Data from the Vector Database
The LLM constructs a search query based on its understanding and sends it to a vector database such as FAISS, which is a library developed by facebookai that provides efficient similarity search and clustering of dense vectors, and is widely used for tasks like nearest neighbor search in large datasets.
The embeddings which is the numerical representations of the textual data that is used in order to capture the semantic meaning of each word in the financial dataset, are stored in a vector database, a system that indexes these embeddings into a high-dimensional space. Moving on, a similarity search is performed which is the process of finding the most similar items based on their vector representations, allowing us to extract data from the most relevant documents.
The database returns a list of the top documents or data snippets that are semantically similar to the query.
3. Up-to-date RAG Data is Returned to the LLM
The LLM receives the retrieved documents or data snippets from the database. This information serves as the context or background knowledge that the LLM uses to generate a comprehensive response.
The LLM integrates this retrieved data into its response-generation process, ensuring that the most current and relevant information is considered.
4. LLM Replies Using the New Known Data and Sends it to the User
Using both the original query and the retrieved data, the LLM generates a detailed and coherent response. This response is crafted to address the user’s query accurately, leveraging the up-to-date information provided by the retrieval process.
The system delivers the response back to the user through the same interface they used to input their query.
Step-by-Step Tutorial: Building the RAG App
How to Build Your Own Rag Workflows?
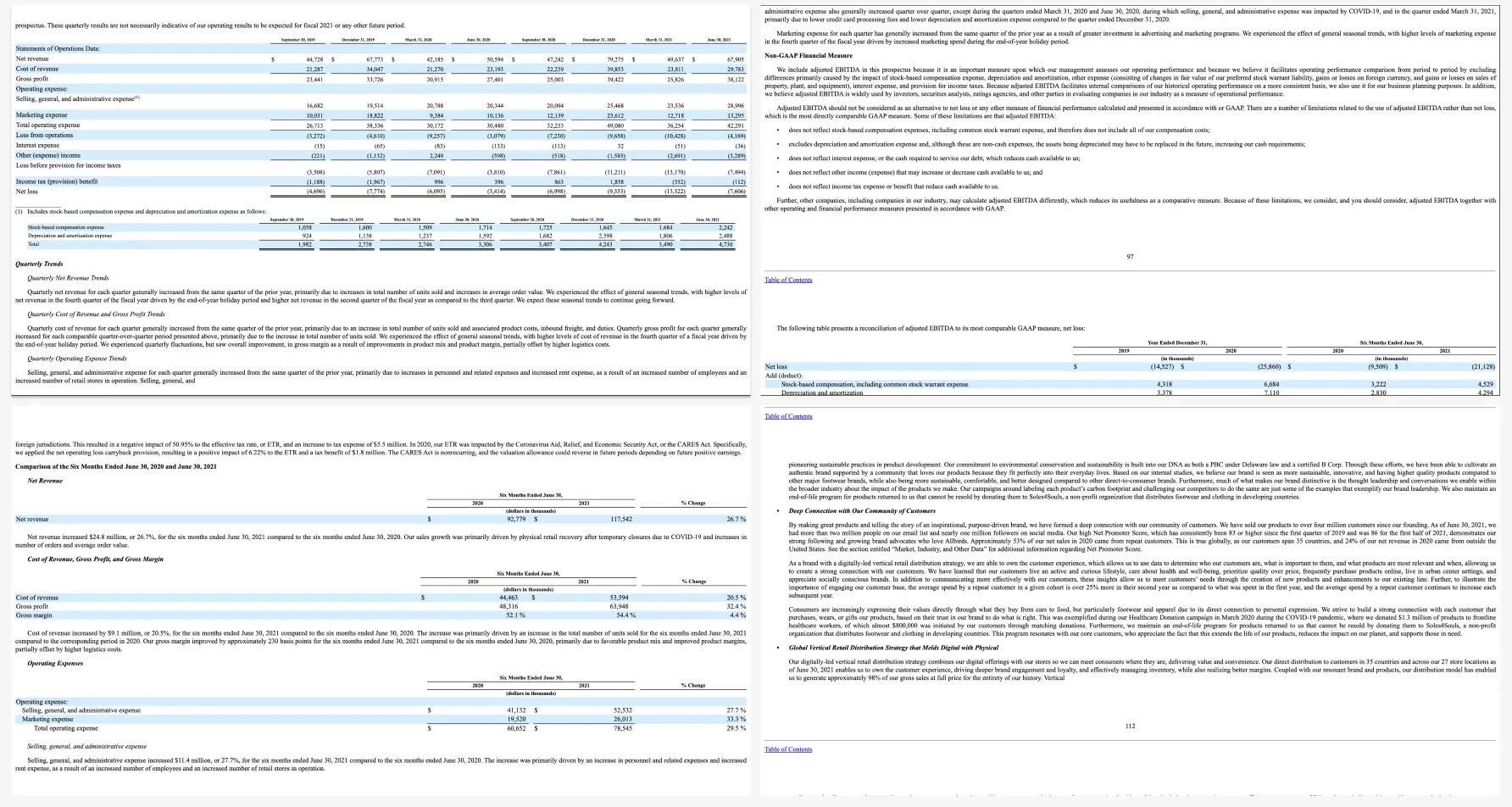
As we stated earlier, RAG systems are highly beneficial in the financial sector for advanced data retrieval and analysis. In this example, we are going to analyze a company known as Allbirds. We are going to transform the Allbirds S-1 document into word embeddings—numerical values that machine learning models can process—we enable the RAG system to interpret and extract relevant information from the document effectively.
This setup allows us to ask Llama LLM models questions that they haven’t been specifically trained on, with the answers being sourced from the vector database. This method leverages the semantic understanding of the embedded S-1 content, providing accurate and contextually relevant responses, thus enhancing financial data analysis and decision-making capabilities.
For our example, we are going to utilize S-1 financial documents which contain vital data about a company’s financial health and operations. These documents are rich in both structured data, such as financial tables, and unstructured data, such as narrative descriptions of business operations, risk factors, and management’s discussion and analysis. This mix of data types makes S-1 filings ideal candidates for integrating them into RAG systems. Having said that, let’s start with our code.
Step 1: Installing the Necessary Packages
First of all, we are going to ensure that all necessary libraries and packages are installed. These libraries include tools for data manipulation (numpy, pandas), machine learning (sci-kit-learn), text processing (langchain, tiktoken), vector databases (faiss-cpu), transformers (transformers, torch), and embeddings (sentence-transformers).
In this section, we will be importing the necessary libraries for data handling, machine learning, and natural language processing.
For instance, the Hugging Face Transformers library provides us with powerful tools for working with LLMs like Llama 3. It allows us to easily load pre-trained models and tokenizers, and to create pipelines for various tasks like text generation. Hugging Face’s flexibility and wide support for different models make it a go-to choice for NLP tasks. The usage of such library depends on the model at hand,you can utilize any library that offers a functioning LLM.
Another important library is FAISS. Which is a highly efficient library for similarity search and clustering of dense vectors. It enables the RAG system to perform rapid searches over large datasets, which is essential for real-time information retrieval. Similar libraries that can perform the same task do include Pinecone.
Other libraries that are used throughout the code include such pandas and numpy which allow for efficient data manipulation and numerical operations, which are essential in processing and analyzing large datasets.
Note: RAG systems offer a great deal of flexibility, allowing you to tailor them to your specific needs. Whether you’re working with a particular LLM, handling various data formats, or choosing a specific vector database, you can select and customize libraries to best suit your goals. This adaptability ensures that your RAG system can be optimized for the task at hand, delivering more accurate and efficient results.
import os
import pandas as pd
import numpy as np
import faiss
from bs4 import BeautifulSoup
from langchain.vectorstores import FAISS
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, pipeline
import torch
from langchain.llms import HuggingFacePipeline
from sentence_transformers import SentenceTransformer
from transformers import AutoModelForCausalLM, AutoTokenizer
Step 3: Defining Our Llama Model
Define the model checkpoint path for your Llama 3 model.
The above section initializes the Llama 3 model and its tokenizer. It loads the model configuration, adjusts the rope_scaling parameters to ensure they are correctly formatted, and then loads the model and tokenizer.
Moving on, we will create a text generation pipeline with mixed precision (fp16).
text_generation_pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
max_length=256, # Further reduce the max length to save memory
device_map="auto",
truncation=True # Ensure sequences are truncated to max_length
)
prompt = """
user
Hello it is nice to meet you!
assistant
"""
output = llm(prompt)
print(output)
This creates a text generation pipeline using the Llama 3 model and verifies its functionality by generating a simple response to a greeting prompt.
Step 4: Defining the Helper Functions
load_and_process_html(file_path) Function
The load_and_process_html function is responsible for loading the HTML content of financial documents and extracting the relevant text from them. Since financial documents may contain a mix of structured and unstructured data, this function tries to extract text from various HTML tags like
,
, and . By doing so, it ensures that all the critical information embedded within different parts of the document is captured.
Without this function, it would be challenging to efficiently parse and extract meaningful content from HTML documents, especially given their complexity. The function also incorporates debugging steps to verify that the correct content is being extracted, making it easier to troubleshoot issues with data extraction.
def load_and_process_html(file_path):
with open(file_path, 'r', encoding='latin-1') as file:
raw_html = file.read()
# Debugging: Print the beginning of the raw HTML content
print(f"Raw HTML content (first 500 characters): {raw_html(:500)}")
soup = BeautifulSoup(raw_html, 'html.parser')
# Try different tags if
doesn't exist
texts = (p.get_text() for p in soup.find_all('p'))
# If no
tags found, try other tags like
if not texts:
texts = (div.get_text() for div in soup.find_all('div'))
# If still no texts found, try or print more of the HTML content
if not texts:
texts = (span.get_text() for span in soup.find_all('span'))
# Final debugging print to ensure texts are populated
print(f"Sample texts after parsing: {texts(:5)}")
return texts
create_and_store_embeddings(texts) Function
The create_and_store_embeddings function converts the extracted texts into embeddings, which are numerical representations of the text. These embeddings are essential because they allow the RAG system to understand and process the textual content semantically. The embeddings are then stored in a vector database using FAISS, enabling efficient similarity search.
def create_and_store_embeddings(texts):
model = SentenceTransformer('all-MiniLM-L6-v2')
if not texts:
raise ValueError("The texts list is empty. Ensure the HTML file is correctly parsed and contains text tags.")
vectors = model.encode(texts, convert_to_tensor=True)
vectors = vectors.cpu().detach().numpy() # Convert tensor to numpy array
# Debugging: Print shapes to ensure they are correct
print(f"Vectors shape: {vectors.shape}")
# Ensure that there is at least one vector and it has the correct dimensions
if vectors.shape(0) == 0 or len(vectors.shape) != 2:
raise ValueError("The vectors array is empty or has incorrect dimensions.")
index = faiss.IndexFlatL2(vectors.shape(1)) # Initialize FAISS index
index.add(vectors) # Add vectors to the index
return index, vectors, texts
retrieve_and_generate(query, index, texts, vectors, k=1) Function
The retrieve function handles the core retrieval process of the RAG system. It takes a user’s query, converts it into an embedding, and then performs a similarity search within the vector database to find the most relevant texts. The function returns the top k most similar documents, which the LLM will use to generate a response. For instance, in our example we will be returning the top five similar documents.
def retrieve_and_generate(query, index, texts, vectors, k=1):
torch.cuda.empty_cache() # Clear the cache
model = SentenceTransformer('all-MiniLM-L6-v2')
query_vector = model.encode((query), convert_to_tensor=True)
query_vector = query_vector.cpu().detach().numpy()
# Debugging: Print shapes to ensure they are correct
print(f"Query vector shape: {query_vector.shape}")
if query_vector.shape(1) != vectors.shape(1):
raise ValueError("Query vector dimension does not match the index vectors dimension.")
D, I = index.search(query_vector, k)
retrieved_texts = (texts(i) for i in I(0)) # Ensure this is correct
# Limit the number of retrieved texts to avoid overwhelming the model
context = " ".join(retrieved_texts(:2)) # Use only the first 2 retrieved texts
# Create a prompt using the context and the original query
prompt = f"Based on the following context:\\n{context}\\n\\nAnswer the question: {query}\\n\\nAnswer:. If you don't know the answer, return that you cannot know."
# Generate the answer using the LLM
generated_response = llm(prompt)
# Return the generated response
return generated_response.strip()
Step 5: Loading and Processing the Data
When it comes to loading and processing data, there are various methods depending on the data type and format. In this tutorial, we focus on processing HTML files containing financial documents. We use the load_and_process_html function that we defined above to read the HTML content and extract the text, which is then transformed into embeddings for efficient search and retrieval. You can find the link to the data we’re using here.
# Load and process the HTML file
file_path = "/kaggle/input/s1-allbirds-document/S-1-allbirds-documents.htm"
texts = load_and_process_html(file_path)
# Create and store embeddings in the vector store
vector_store, vectors, texts = create_and_store_embeddings(texts)
What our data looks like
Step 6: Testing Our Model
In this section, we are going to test our RAG system by using the following example queries:
First example QueryFirst output query
As shown above, the llama 3 model takes in the context retrieved by our retrieval system and using it generates an up to date and a more knowledgeable answer to our query.
Second example QuerySecond output query
Above is another query that the mode was capable of replying to using additional context from our vector database.
Third example queryThird output query
Lastly, when we asked our model the above given query, the model replied that no specific details where given that can assist in it answering the given query. You can find the link to the notebook for your reference here.
What is OCR?
Financial documents like S-1 filings, K-1 forms, and bank statements contain vital data about a company’s financial health and operations. Data extraction from such documents is complex due to the mix of structured and unstructured content, such as tables and narrative text. In cases where S-1 and K-1 documents are in image or non-readable PDF file formats, OCR is essential. It enables the conversion of these formats into text that machines can process, making it possible to integrate them into RAG systems. This ensures that all relevant information, whether structured or unstructured, can be accurately extracted by utilizing these ai and Machine learning algorithms.
How Nanonets Can Be Used to Enhance RAG Systems
Nanonets is a powerful ai-driven platform that not only offers advanced OCR solutions but also enables the creation of custom data extraction models and RAG (Retrieval-Augmented Generation) use cases tailored to your specific needs. Whether dealing with complex financial documents, legal contracts, or any other intricate datasets, Nanonets excels at processing varied layouts with high accuracy.
By integrating Nanonets into your RAG system, you can harness its advanced data extraction capabilities to convert large volumes of data into machine-readable formats like Excel and CSV. This ensures your RAG system has access to the most accurate and up-to-date information, significantly enhancing its ability to generate precise, contextually relevant responses.
Beyond just data extraction, Nanonets can also build complete RAG-based solutions for your organization. With the ability to develop tailored applications, Nanonets empowers you to input queries and receive precise outputs derived from the specific data you’ve fed into the system. This customized approach streamlines workflows, automates data processing, and allows your RAG system to deliver highly relevant insights and answers, all backed by the extensive capabilities of Nanonets’ aitechnology.
OCR for financial documents
The Takeaways
By now, you should have a solid understanding of how to build a Retrieval-Augmented Generation (RAG) system for financial documents using the Llama 3 model. This tutorial demonstrated how to transform an S-1 financial document into word embeddings and use them to generate accurate and contextually relevant responses to complex queries.
Now that you have learned the basics of building a RAG system for financial documents, it's time to put your knowledge into practice. Start by building your own RAG systems and consider using OCR software solutions like the Nanonets API for your document processing needs. By leveraging these powerful tools, you can extract data relevant to your use cases and enhance your analysis capabilities, supporting better decision-making and detailed financial analysis in the financial sector.














{kind=link}