 NEWSLETTER
NEWSLETTER
<a target="_blank" href="https://jupyter-ai.readthedocs.io/en/latest/index.html”>Jupyter ai It brings generative <a target="_blank" href="https://blog.jupyter.org/generative-ai-in-jupyter-3f7174824862″>ai capacities directly in the interface. Having a local ai assistant guarantees privacy, reduces latency and provides out -of -line functionality, which makes it a powerful tool for developers. In this article, we will learn how to configure a local the coding assistant in Jupyterlab wearing Jupyter ai, Ollama and Hugged face. At the end of this article, you will have a fully functional coding assistant in Jupyterlab capable of making the code, solving errors, creating new notebooks from scratch, and much more, as shown in screen capture below.
Jupyter ai is still under great development, so some characteristics can break. When writing this article, I have tried the configuration to confirm that it works, but wait <a target="_blank" href="https://github.com/jupyterlab/jupyter-ai“>Potential changes As the project evolves. In addition, the assistant performance depends on the model you select, so be sure to choose the one that is suitable for your use case.
The first thing is the first: What is Jupyter ai? As the name implies, Jupyter ai is an extension of Jupyterlab for generative ai. This powerful tool transforms its standard Jupyter notebooks or the Jupyterlab environment into a generative ia recreation patio. The best part? It also works without problems in environments such as Collaborative Google and Visual Studio Code. This extension does all heavy work, providing access to a variety of models suppliers (both open source and closed code) within its Jupyter environment.
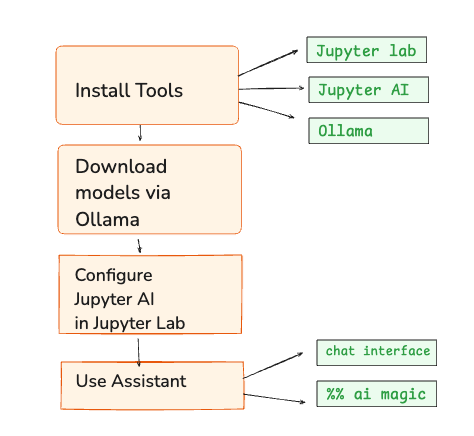
Configure the environment implies three main components:
- Jupyterlab
- Jupyter ai extension
- Ollama (to serve local model)
- (Optional) hugged face (for GGUF models)
Honestly, obtaining the assistant to solve coding errors is the easy part. What is complicated is to ensure that all facilities have been carried out correctly. Therefore, it is essential that you follow the steps correctly.
1. Installation of the Jupyter ai extension
It is recommended to create a New environment Specifically for Jupyter ai to maintain your existing and organized existing environment. Once done, follow the following steps. Jupyter ai requires Jupyterlab 4.x either Notebook Jupyter 7+So be sure to have the latest version of Jupyter Lab installed. You can install/update Jupyterlab with PIP or Conda:
# Install JupyterLab 4 using pip
pip install jupyterlab~=4.0Then install the Jupyter ai extension as follows.
pip install "jupyter-ai(all)"This is the easiest method for the installation, since it includes all the provider's units (so it admits the hugged face, ollama, etc., outside the box). To date, Jupyter ai admits the following <a target="_blank" href="https://jupyter-ai.readthedocs.io/en/latest/users/index.html#model-providers”>Model suppliers :
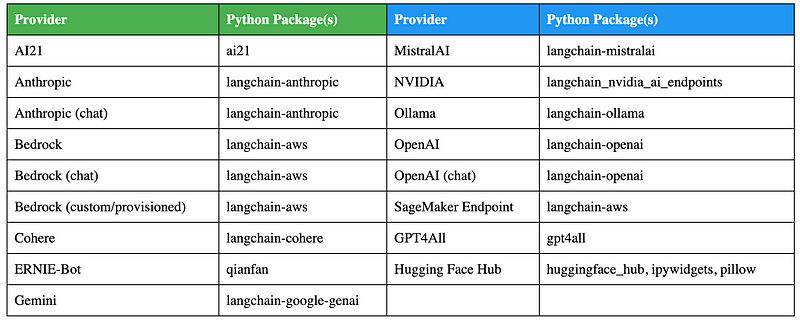
If you find errors during the Jupyter ai installation, install a Jupyter ai using pip without the (all) optional dependency group. In this way, you can control which models are available in your Jupyter ai environment. For example, to install Jupyter ai with only aggregate support for ollama models, use the following:
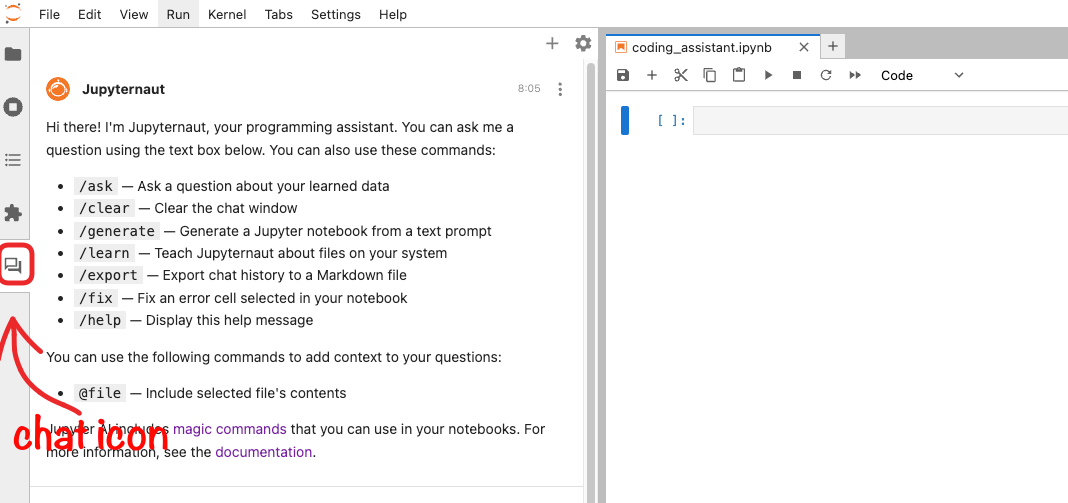
pip install jupyter-ai langchain-ollamaThe dependencies depend on the suppliers of models (see the previous table). Next, restart your Jupyterlab instance. If you see a chat icon in the left sidebar, this means that everything has been perfectly installed. With Jupyter ai, you can chat with models or use online magic commands directly inside your notebooks.
2. Ollama configuration for local models
Now that Jupyter ai is installed, we need to configure it with a model. While Jupyter ai is integrated directly with hug face models, some models <a target="_blank" href="https://github.com/jupyterlab/jupyter-ai/issues/576″>It may not work properly. Instead, Ollama provides a more reliable way to load models locally.
Ollama It is a useful tool to execute large language models locally. Allows you to download pre -configured models from your library. Ollama admits all the main platforms (Macos, Windows, Linux), so choose the method for your operating system and download and install it from the officer website. After installation, verify that you are configured correctly executing:
Ollama --version
------------------------------
ollama version is 0.6.2In addition, make sure your server Ollama has to be executing what you can verify by calling ollama serve In the terminal:
$ ollama serve
Error: listen tcp 127.0.0.1:11434: bind: address already in useIf the server is already active, you will see an error as the above confirming that Ollama is running and in use.
Option 1: Use of preconfigured models
Ollama provides a library of previously trained models that can Download and run locally. To start using a model, download it using the pull domain. For example, to use qwen2.5-coder:1.5brun:
ollama pull qwen2.5-coder:1.5bThis will download the model in its local environment. To confirm if the model has been downloaded, run:
ollama listThis will list all the models that you have downloaded and stored locally in your system using Ollama.
Option 2: Load a custom model
If the model you need is not available in the Ollama Library, you can load a custom model creating a Model Archive specifying the source of the model. For detailed instructions on this process, see the Ollama import documentation.
Option 3: Execution of GGGF models directly from hugging the face
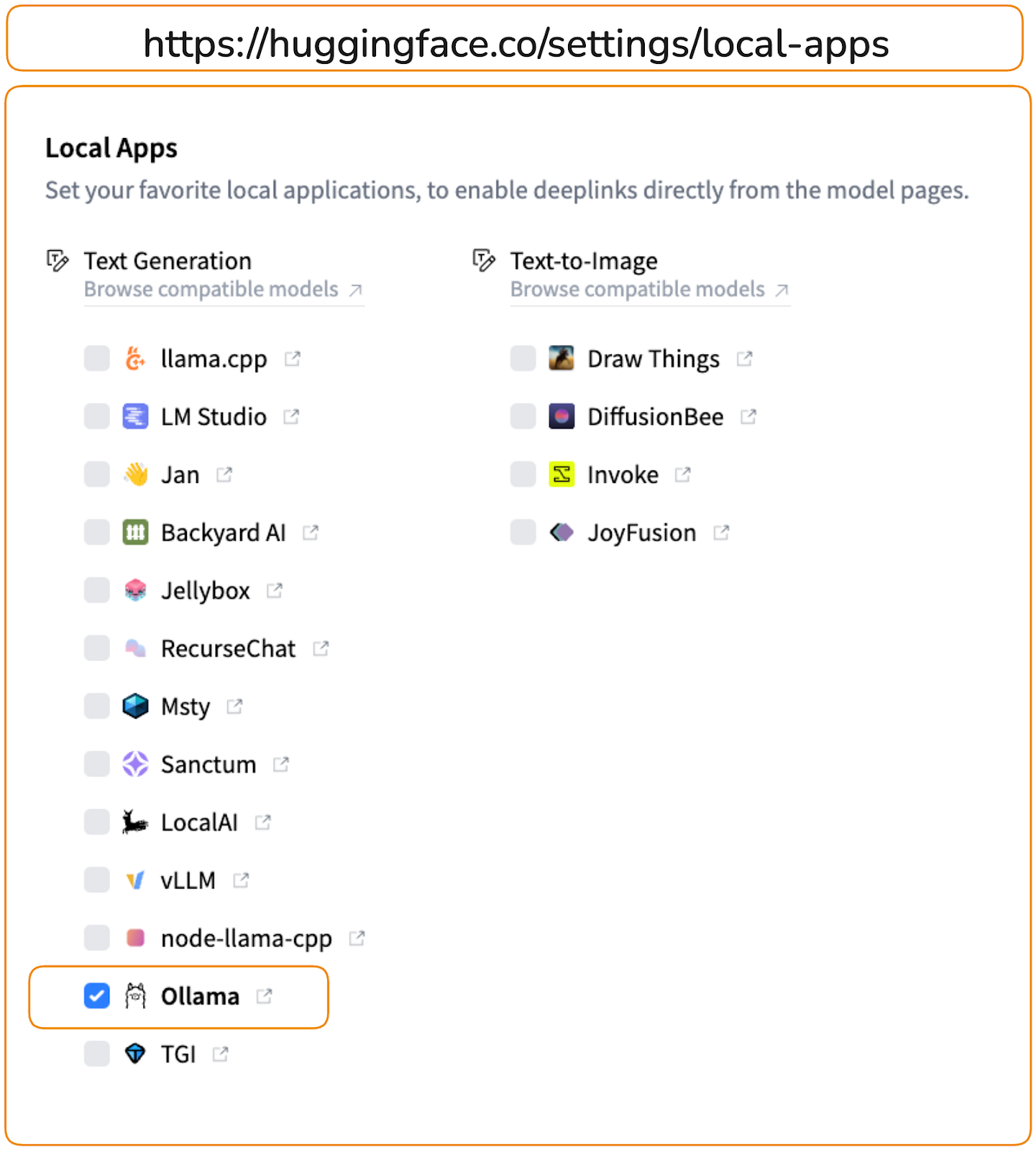
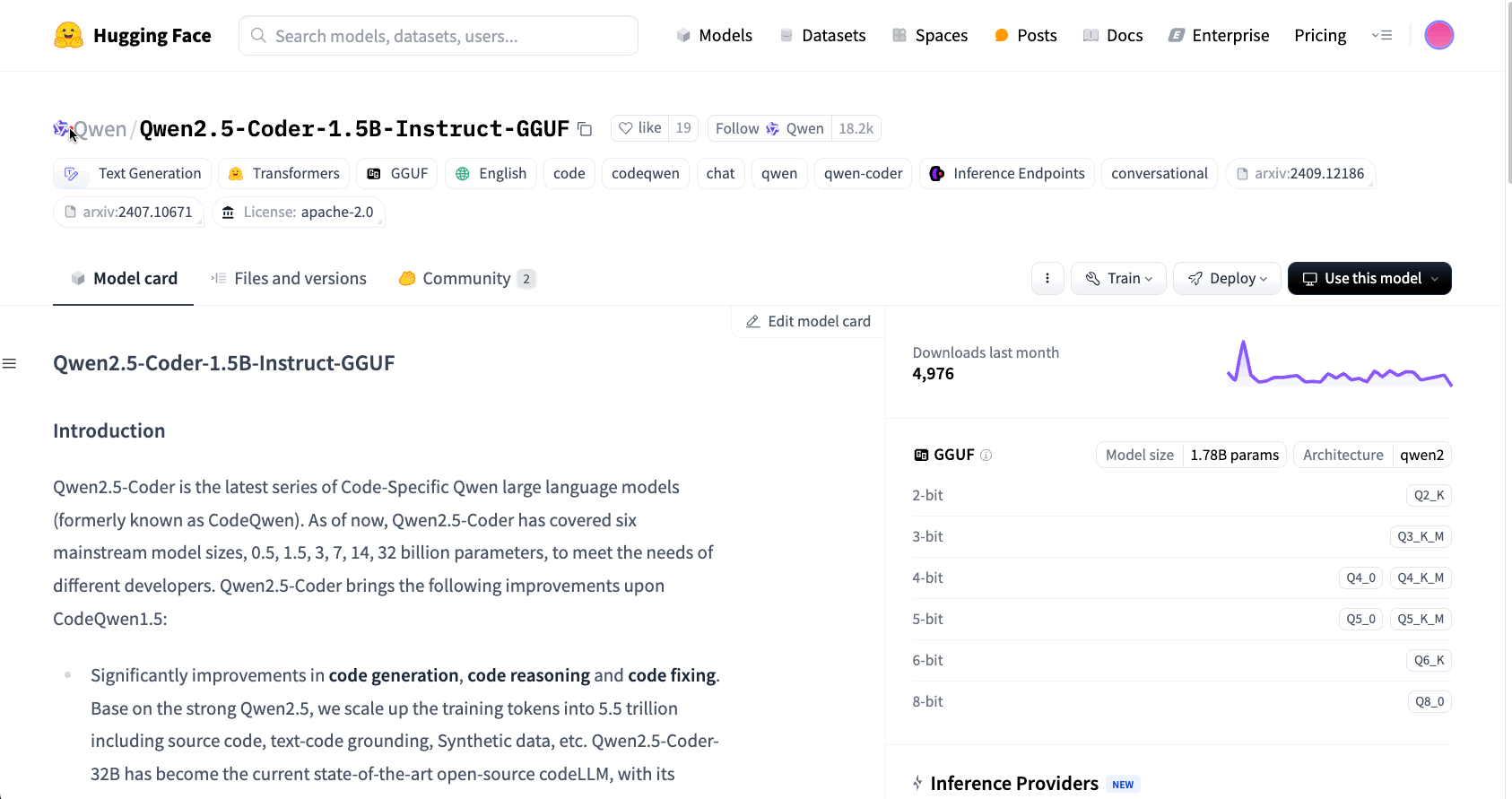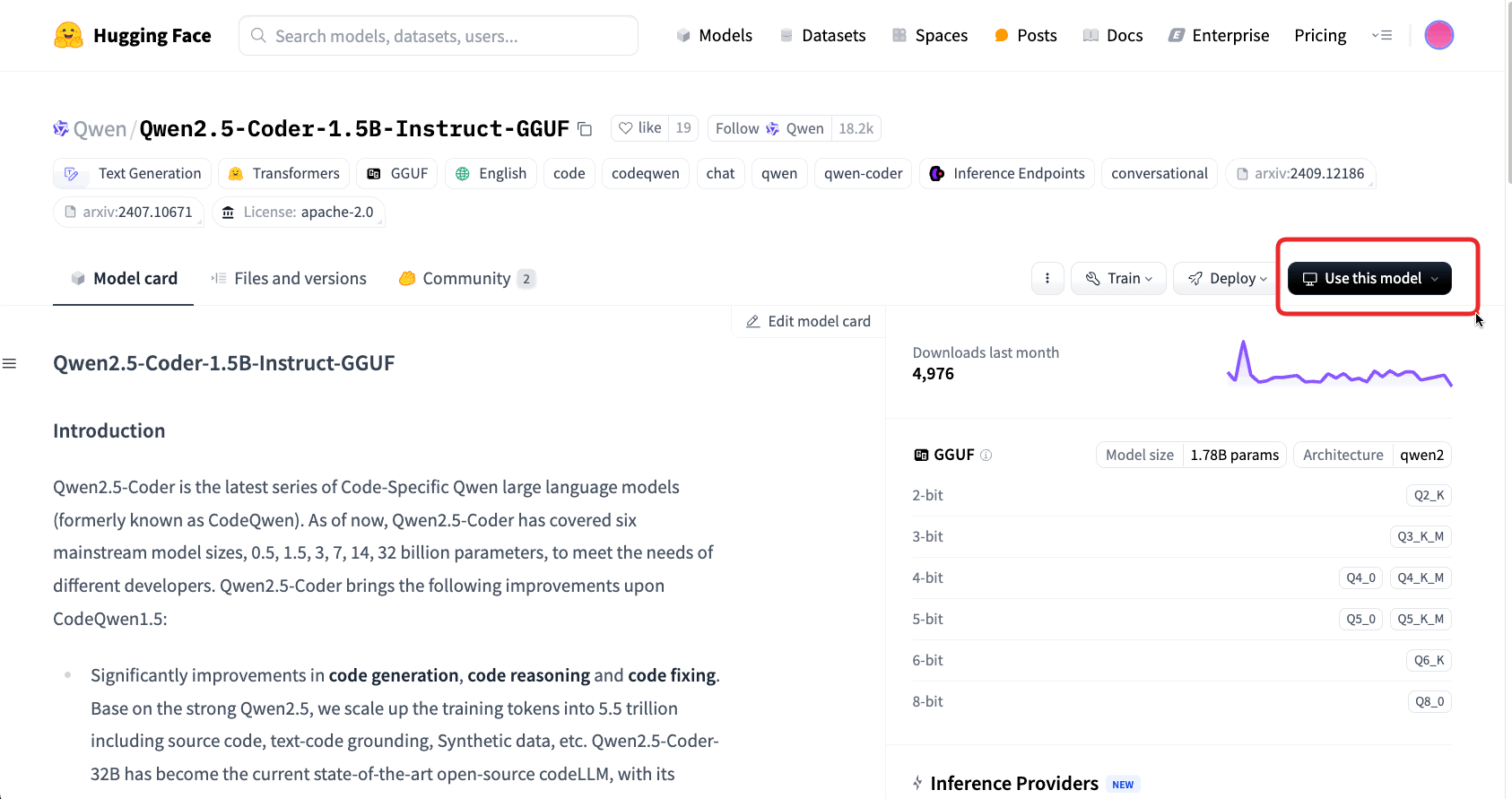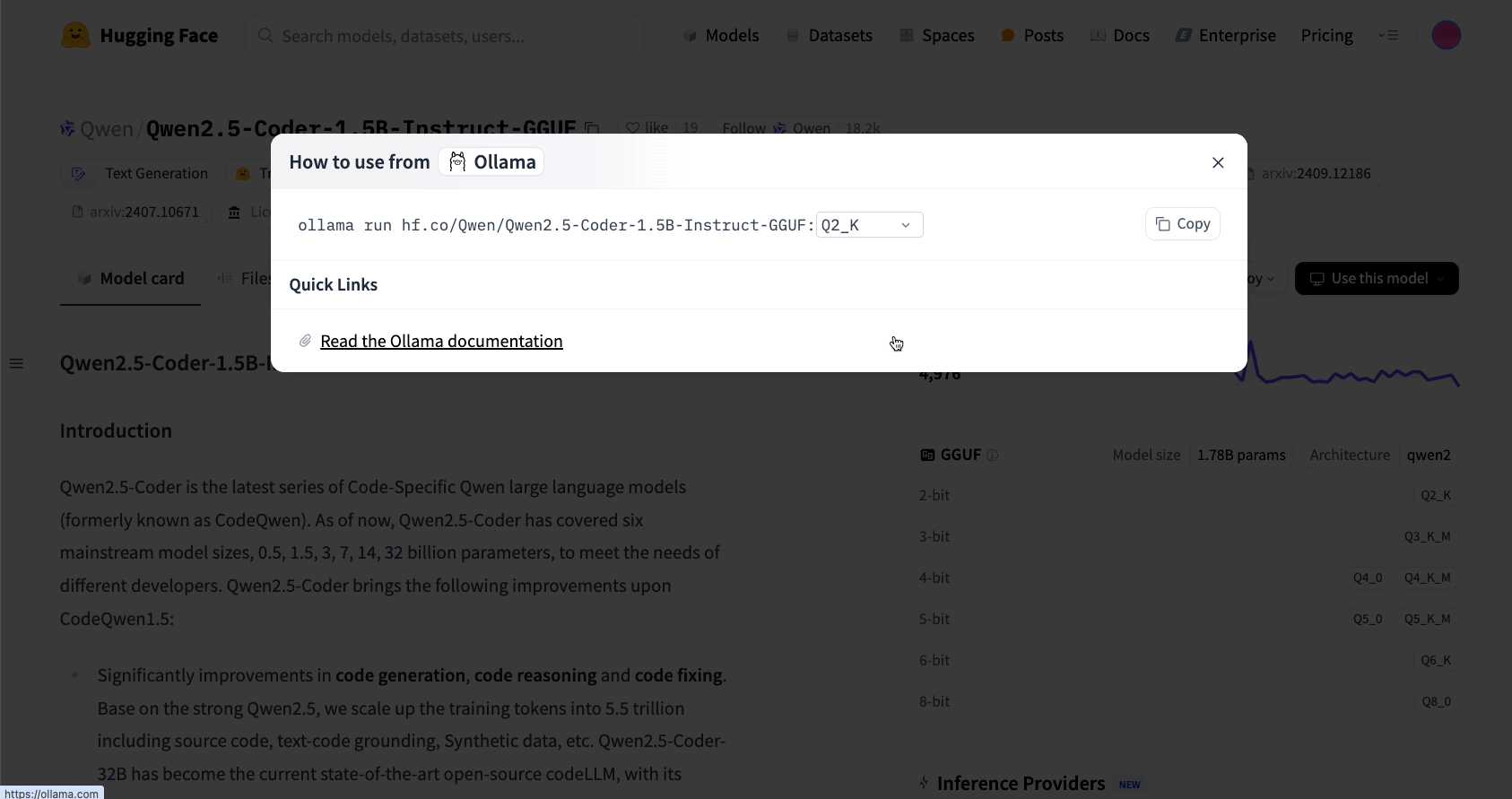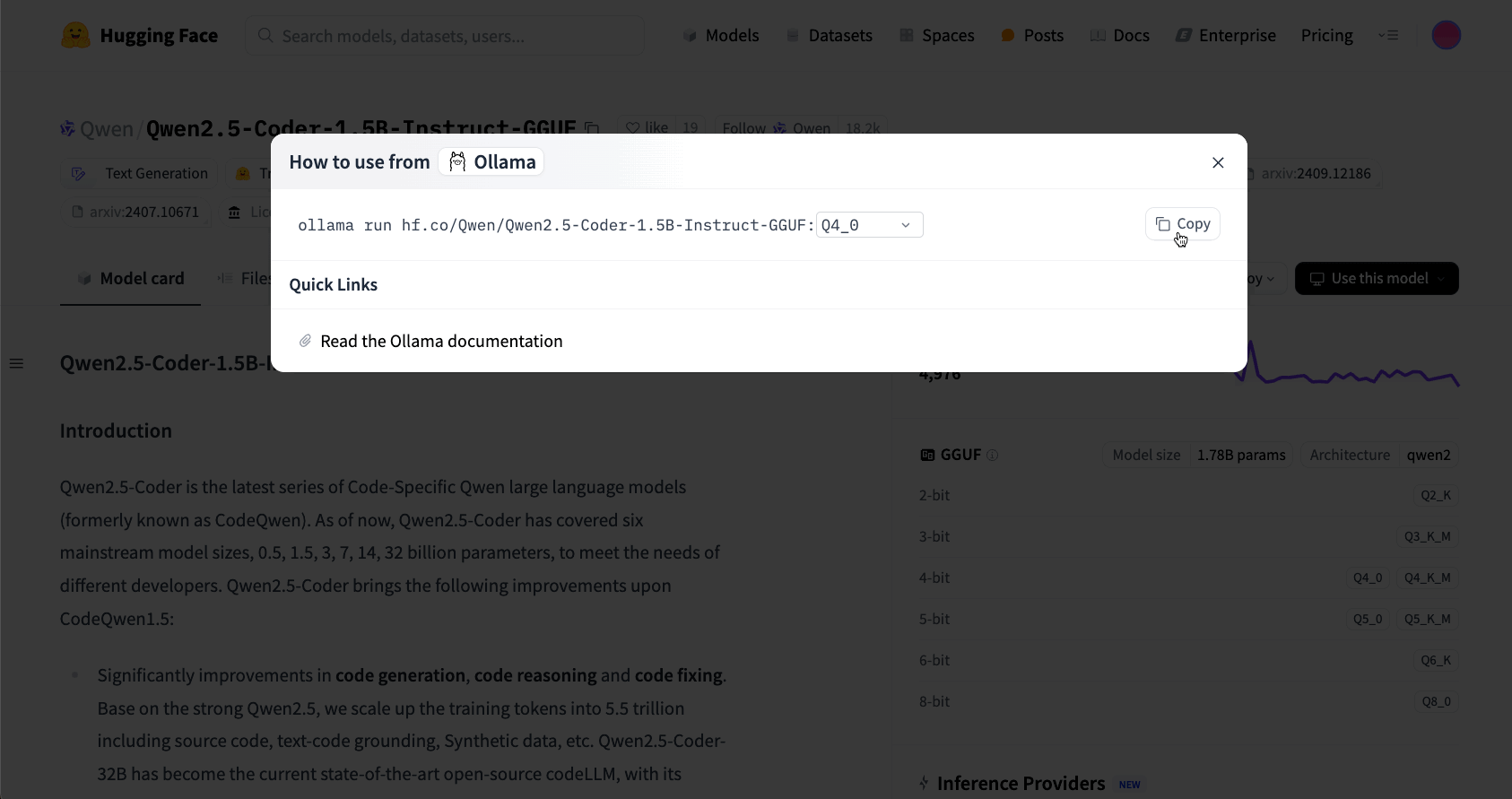
Ollama now supports GGUF models directly from the hug clamp centerincluding public and private models. This means that if you want to use the GGUF model directly from the Face Hub hug, you can do it without requiring a personalized model file as mentioned in option 2 previous.
For example, to load a 4-bit quantized Qwen2.5-Coder-1.5B-Instruct model Of the hugged face:
1. First, enable Ollama under your Local Application Configuration.
2. On the model page, choose Ollama in the drop -down menu Use this model as shown below.
We are almost there. In Jupyterlab, open the Jupyter ai Chat interface in the sidebar. At the top of the chat panel or in its configuration (gear icon), there is a drop -down menu or field to select the Model supplier and ID of the model. Choose Ollama As a supplier, and enter the name of the model exactly as shown in the ollama list in the terminal (for example, qwen2.5-coder:1.5b). Jupyter ai will connect to the local Ollama server and load that model for consultations. No API keys are needed since this is local.
- Establish the language model, the embedding model and the online completion models based on the models of your choice.
- Save the configuration and return to the chat interface.
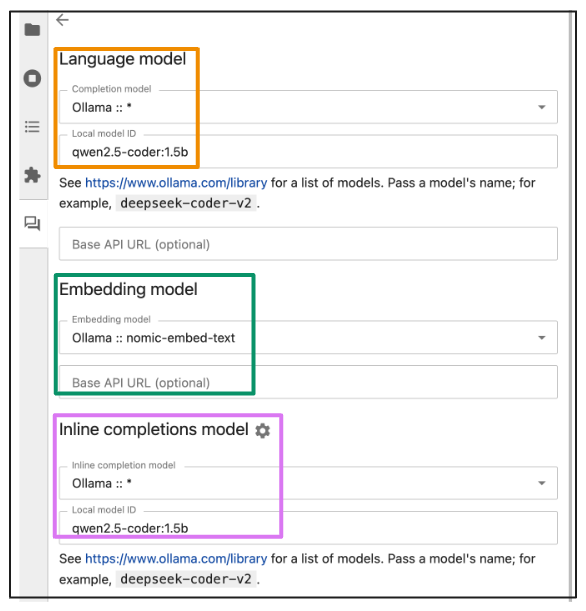
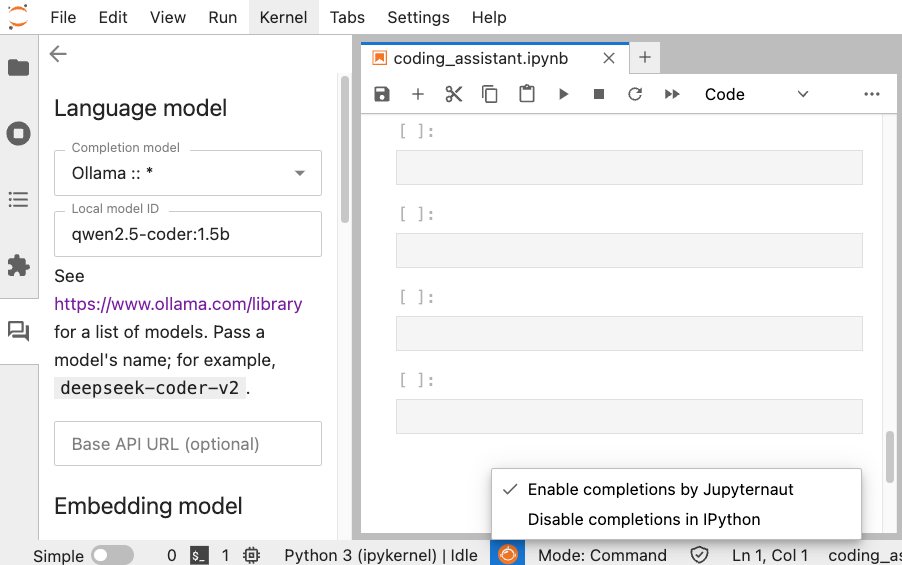
This configuration links Jupyter ai to the local execution model through Ollama. While this process must enable online terminations, if that does not happen, you can manually do it by clicking on the Jupyrtaut icon, which is located in the lower bar of the Jupyterlab interface to the left of the Mode indicator (For example, mode: command). This opens a drop -down menu where you can select Enable completions by Jupyternaut To activate the characteristic.
Once configured, you can use the ai coding wizard for several tasks such as Code Autocompletion, purification help and generate a new code from scratch. It is important to take into account here that you can interact with the assistant, either through the chat sidebar or directly in notebook cells using %%ai magic commands. Let's see both paths.
Coding assistant through the chat interface
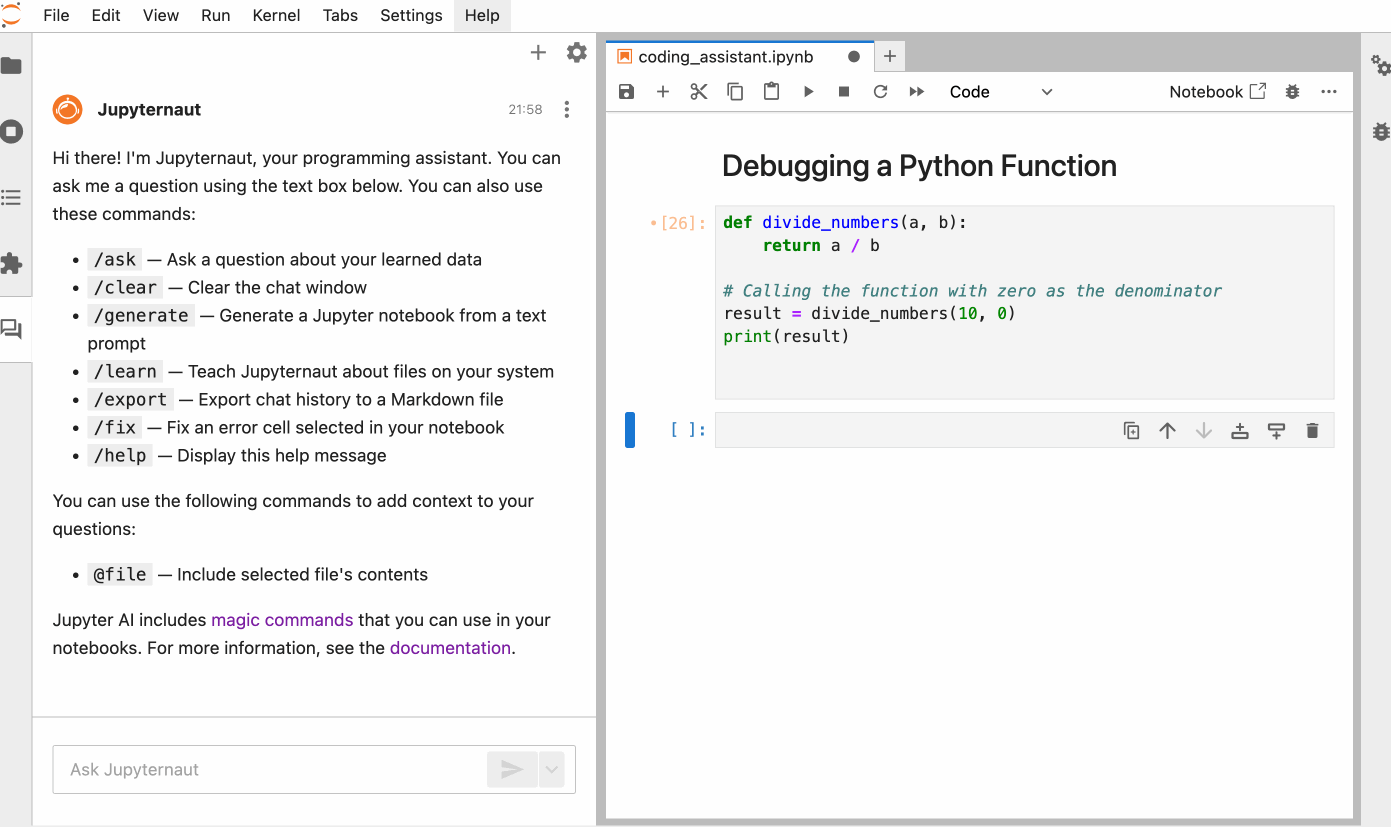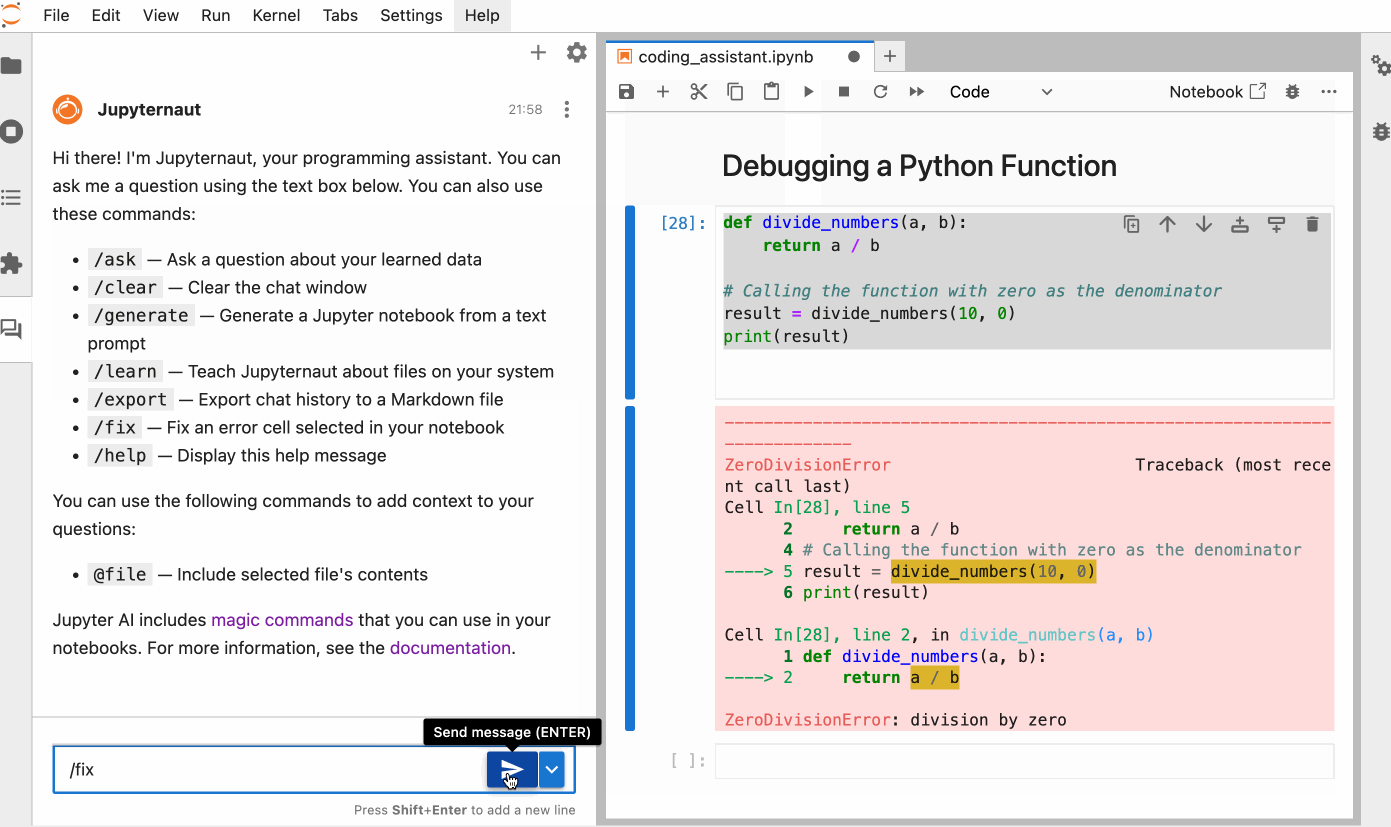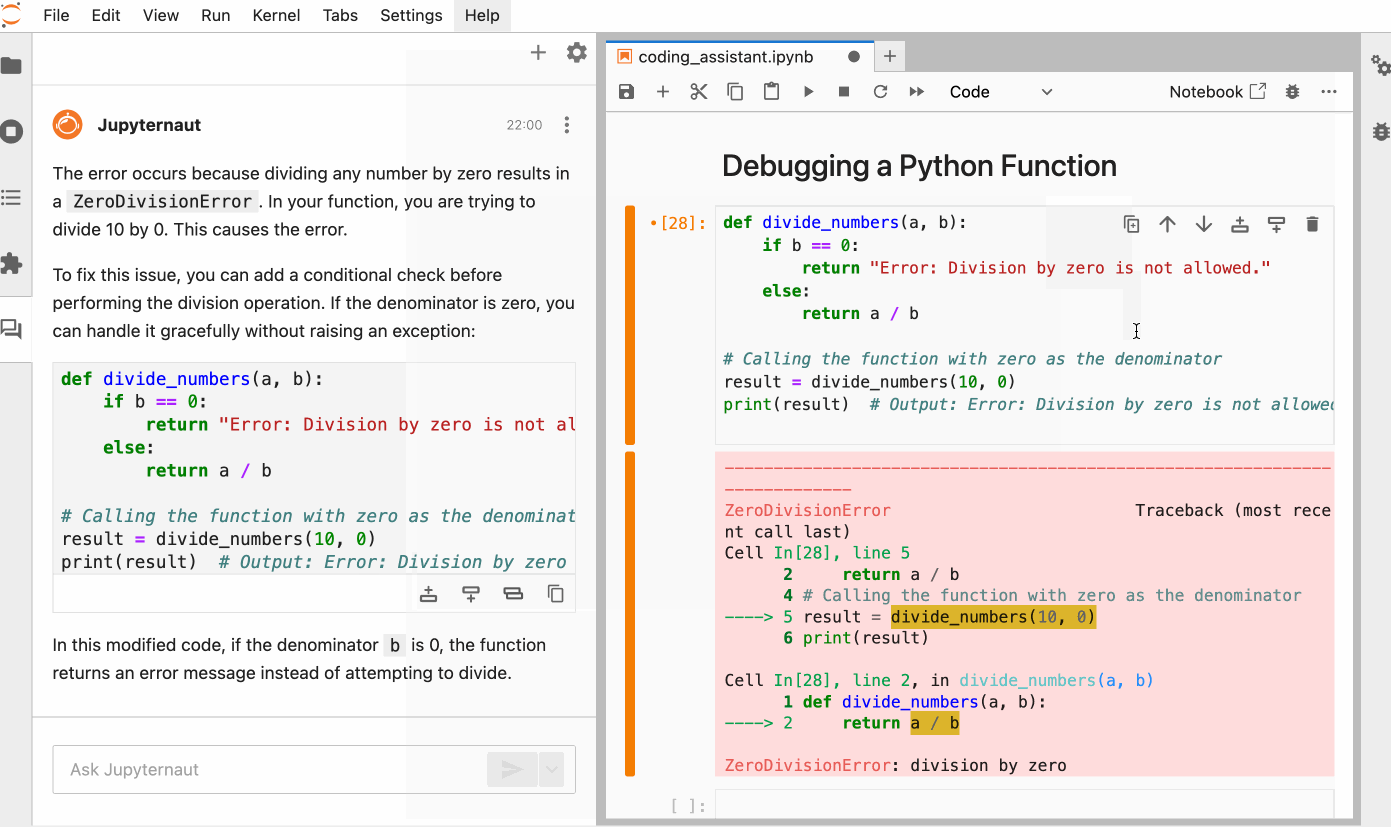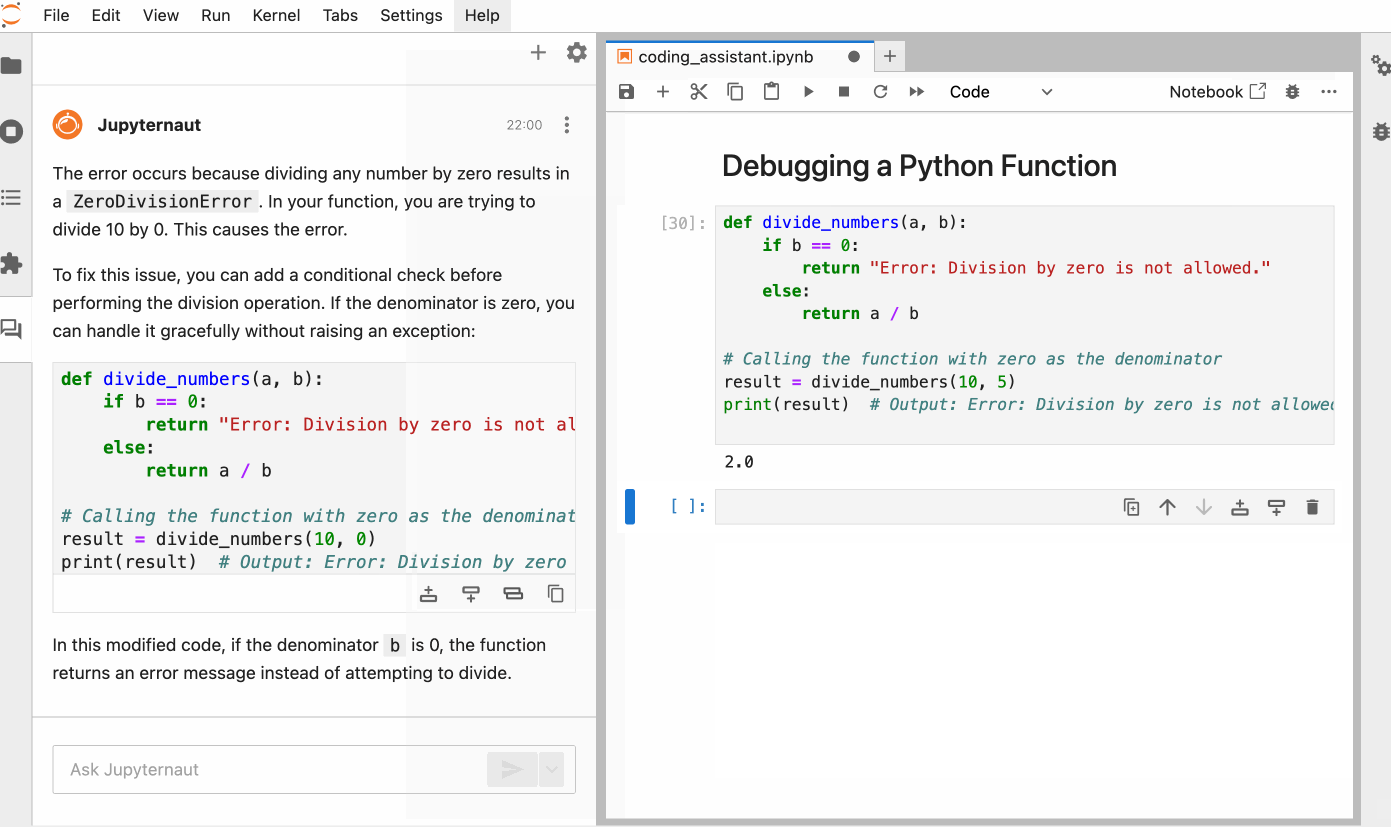
This is quite simple. You can simply chat with the model to perform an action. For example, here is how we can ask the model to explain the error in the code and then solve the error by selecting the code in the notebook.
You can also ask ai to generate code for a task from scratch, simply describing what you need in natural language. Here is a Python function that returns all the prime numbers to a positive integer N, generated by Jupyrtaut.
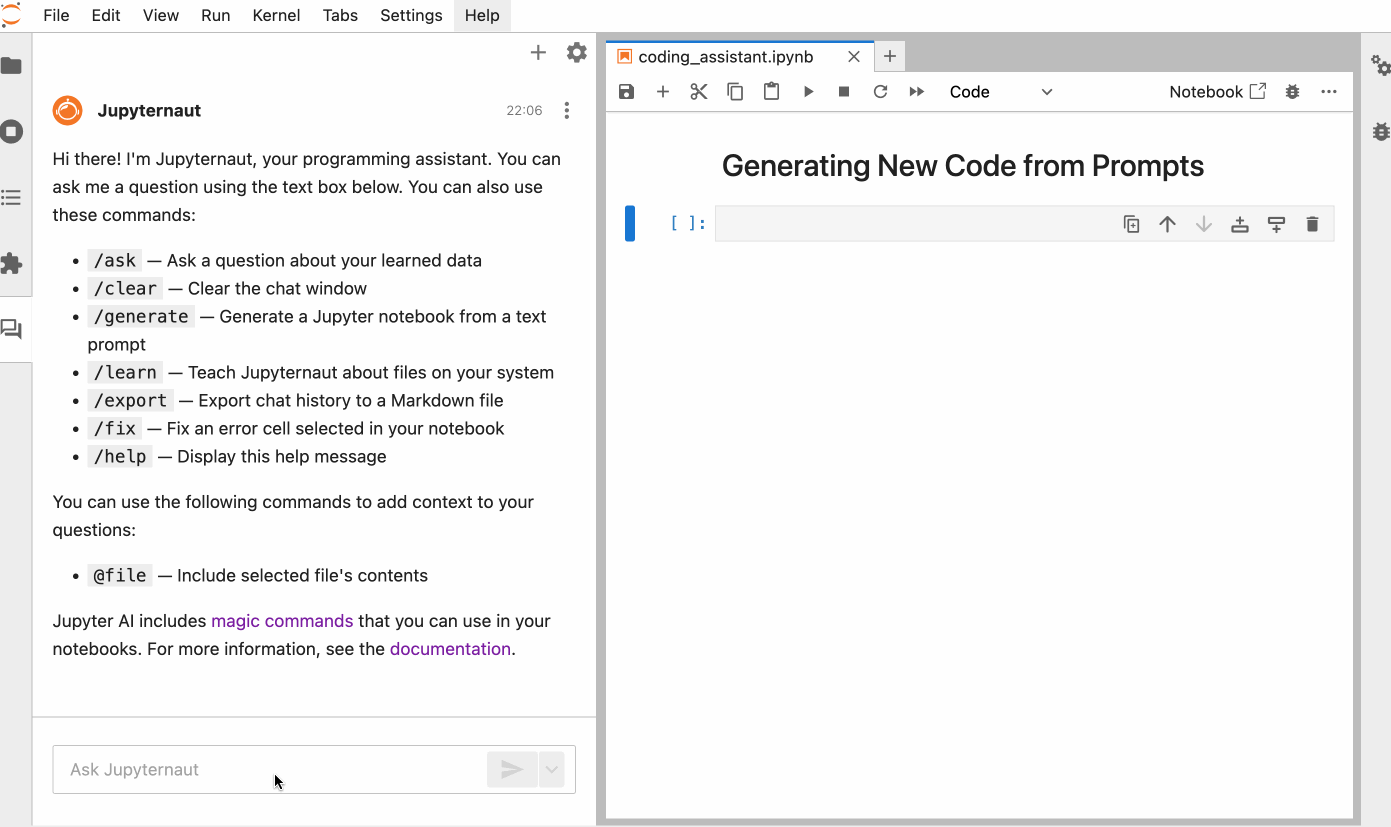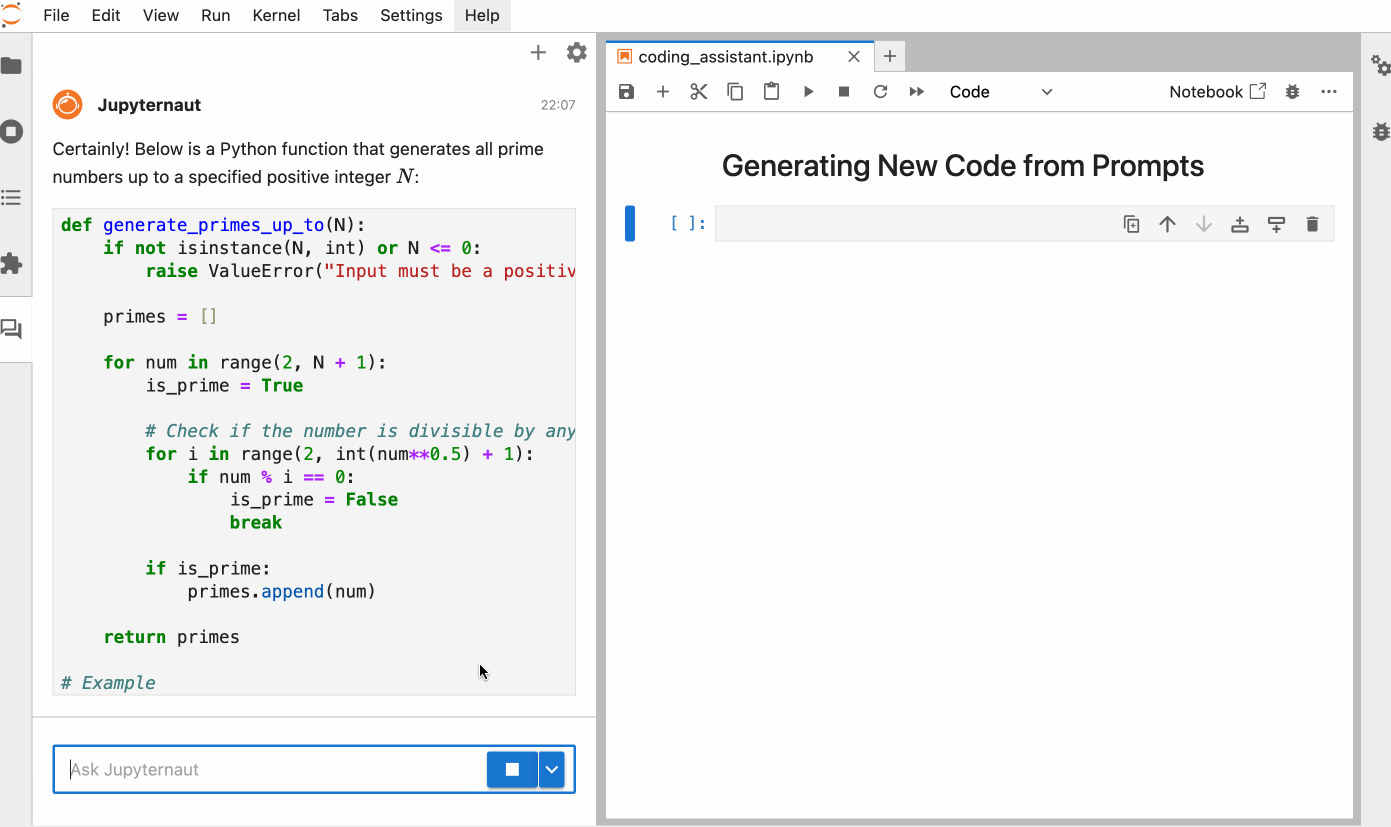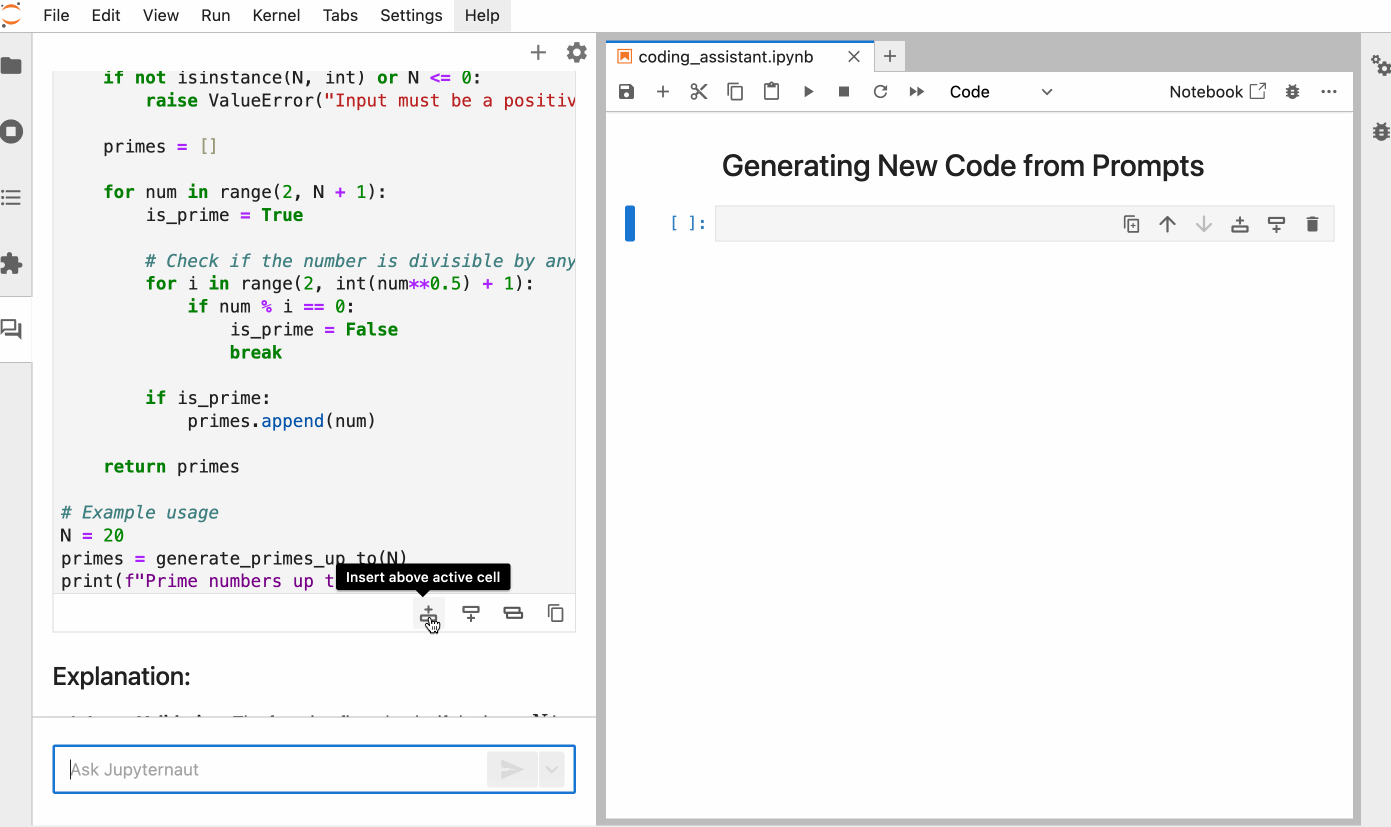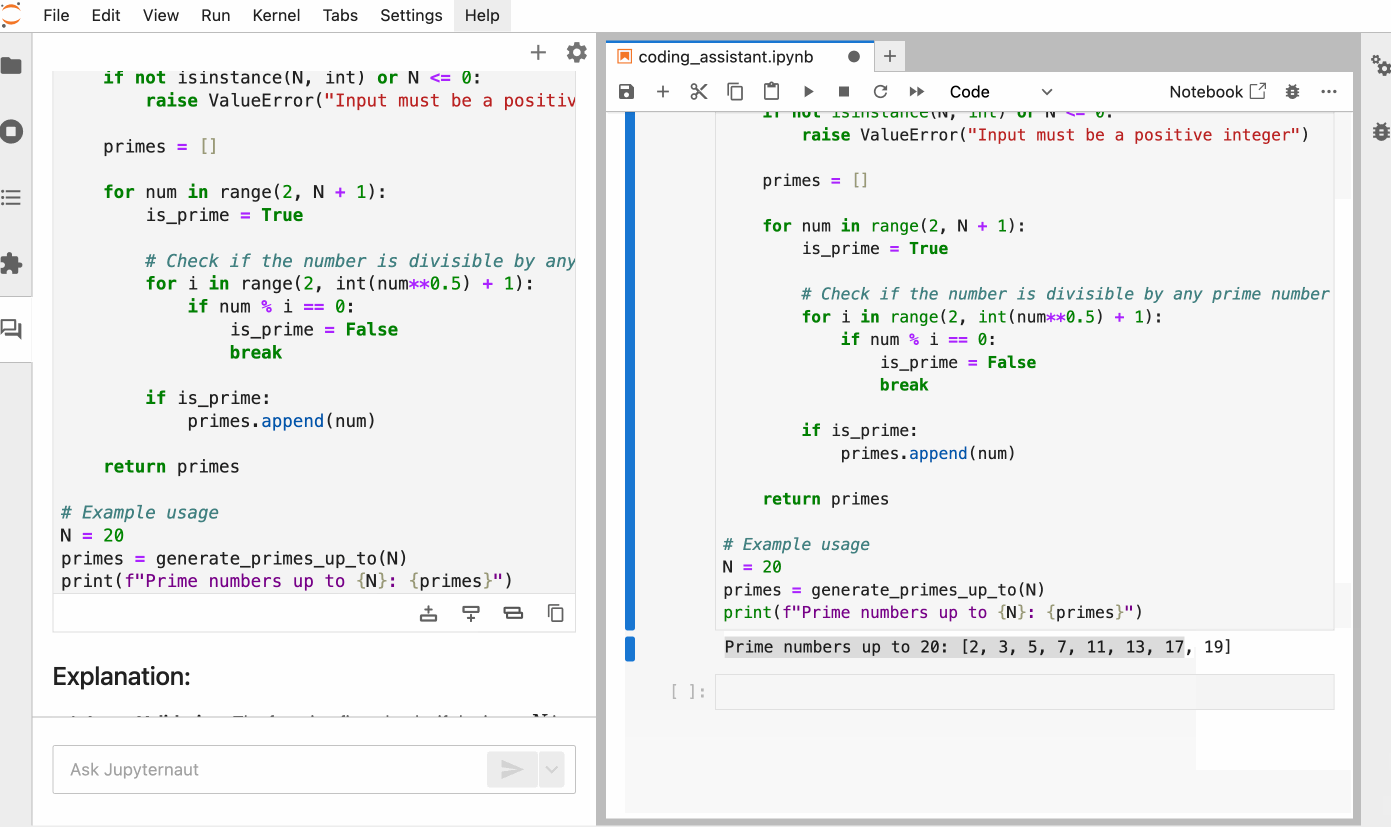
Coding assistant through Notebook Cell or Ipython Shell:
You can also interact with models directly into a Jupyter notebook. First, load the iPython extension:
%load_ext jupyter_ai_magicsNow you can use the %%ai Cell magic to interact with the chosen language model using a specified warning. Let's replicate the previous example, but this time within the cells of the notebook.
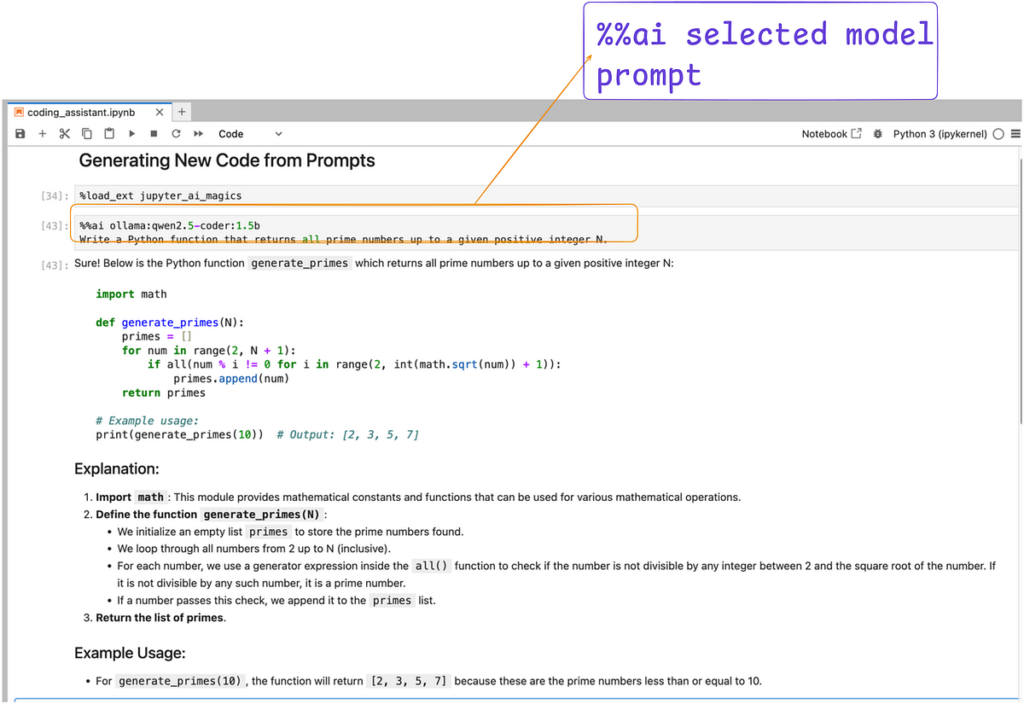
For more details and options, you can consult the officer <a target="_blank" href="https://jupyter-ai.readthedocs.io/en/latest/users/index.html#the-ai-and-ai-magic-commands”>documentation
As you can evaluate of this article, Jupyter ai facilitates the configuration of a coding wizard, provided you have the correct facilities and configuration instead. I used a relatively small model, but you can choose between a variety of models backed by Ollama or hugging the face. The key advantage here is that the use of a local model offers significant benefits: it improves privacy, reduces latency and decreases dependence on patented models. However, run lARGE models locally with Ollama can be intensive in resources, so be sure to have enough RAM. With the fast pace that open source models are improving, you can achieve a performance comparable even with these alternatives.
(Tagstotranslate) artificial intelligence (T) Pick (T) Jupyter Notebook (T) Large language models (T) ollama





{kind=link}