 NEWSLETTER
NEWSLETTER
In today’s digital age, social media has revolutionized the way brands interact with their consumers, creating a need for dynamic and engaging content that resonates with their target audience. There’s growing competition for consumer attention in this space; content creators and influencers face constant challenges to produce new, engaging, and brand-consistent content. The challenges come from three key factors: the need for rapid content production, the desire for personalized content that is both captivating and visually appealing and reflects the unique interests of the consumer, and the necessity for content that is consistent with a brand’s identity, messaging, aesthetics, and tone.
Traditionally, the content creation process has been a time-consuming task involving multiple steps such as ideation, research, writing, editing, design, and review. This slow cycle of creation does not fit for the rapid pace of social media.
Generative ai offers new possibilities to address this challenge and can be used by content teams and influencers to enhance their creativity and engagement while maintaining brand consistency. More specifically, multimodal capabilities of large language models (LLMs) allow us to create the rich, engaging content spanning text, images, audio, and video formats that are omnipresent in advertising, marketing, and social media content. With recent advancements in vision LLMs, creators can use visual input, such as reference images, to start the content creation process. Image similarity search and text semantic search further enhance the process by quickly retrieving relevant content and context.
In this post, we walk you through a step-by-step process to create a social media content generator app using vision, language, and embedding models (Anthropic’s Claude 3, amazon Titan Image Generator, and amazon Titan Multimodal Embeddings) through amazon Bedrock API and amazon OpenSearch Serverless. amazon Bedrock is a fully managed service that provides access to high-performing foundation models (FMs) from leading ai companies through a single API. OpenSearch Serverless is a fully managed service that makes it easier to store vectors and other data types in an index and allows you to perform sub second query latency when searching billions of vectors and measuring the semantic similarity.
Here’s how the proposed process for content creation works:
- First, the user (content team or marketing team) uploads a product image with a simple background (such as a handbag). Then, they provide natural language descriptions of the scene and enhancements they wish to add to the image as a prompt (such as “Christmas holiday decorations”).
- Next, amazon Titan Image Generator creates the enhanced image based on the provided scenario.
- Then, we generate rich and engaging text that describes the image while aligning with brand guidelines and tone using Claude 3.
- After the draft (text and image) is created, our solution performs multimodal similarity searches against historical posts to find similar posts and gain inspiration and recommendations to enhance the draft post.
- Finally, based on the generated recommendations, the post text is further refined and provided to the user on the webpage. The following diagram illustrates the end-to-end new content creation process.
Solution overview
In this solution, we start with data preparation, where the raw datasets can be stored in an amazon Simple Storage Service (amazon S3) bucket. We provide a Jupyter notebook to preprocess the raw data and use the amazon Titan Multimodal Embeddings model to convert the image and text into embedding vectors. These vectors are then saved on OpenSearch Serverless as collections, as shown in the following figure.
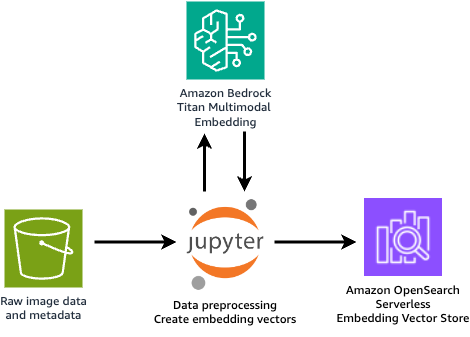
Next is the content generation. The GUI webpage is hosted using a Streamlit application, where the user can provide an initial product image and a brief description of how they expect the enriched image to look. From the application, the user can also select the brand (which will link to a specific brand template later), choose the image style (such as photographic or cinematic), and select the tone for the post text (such as formal or casual).
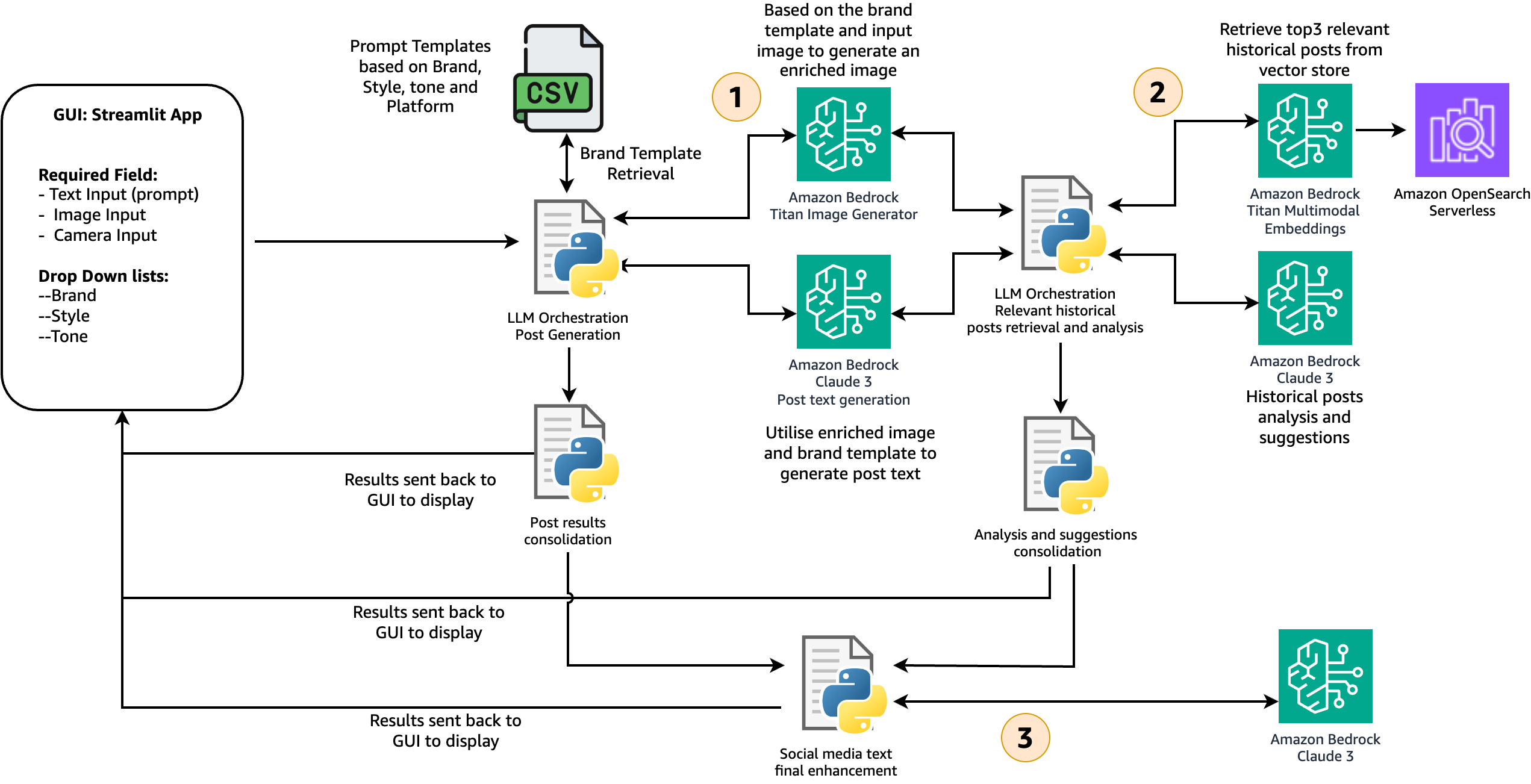
After all the configurations are provided, the content creation process, shown in the following figure, is launched.
In stage 1, the solution retrieves the brand-specific template and guidelines from a CSV file. In a production environment, you could maintain the brand template table in amazon DynamoDB for scalability, reliability, and maintenance. The user input is used to generate the enriched image with the amazon Titan Image Generator. Together with all the other information, it’s fed into the Claude 3 model, which has vision capability, to generate the initial post text that closely aligns with the brand guidelines and the enriched image. At the end of this stage, the enriched image and initial post text are created and sent back to the GUI to display to users.
In stage 2, we combine the post text and image and use the amazon Titan Multimodal Embeddings model to generate the embedding vector. Multimodal embedding models integrate information from different data types, such as text and images, into a unified representation. This enables searching for images using text descriptions, identifying similar images based on visual content, or combining both text and image inputs to refine search results. In this solution, the multimodal embedding vector is used to search and retrieve the top three similar historical posts from the OpenSearch vector store. The retrieved results are fed into the Anthropic’s Claude 3 model to generate a caption, provide insights on why these historical posts are engaging, and offer recommendations on how the user can improve their post.
In stage 3, based on the recommendations from stage 2, the solution automatically refines the post text and provides a final version to the user. The user has the flexibility to select the version they like and make changes before publishing. For the end-to-end content generation process, steps are orchestrated with the Streamlit application.
The whole process is shown in the following image:
Implementation steps
This solution has been tested in AWS Region us-east-1. However, it can also work in other Regions where the following services are available. Make sure you have the following set up before moving forward:
We use amazon SageMaker Studio to generate historical post embeddings and save those embedding vectors to OpenSearch Serverless. Additionally, you will run the Streamlit app from the SageMaker Studio terminal to visualize and test the solution. Testing the Streamlit app in a SageMaker environment is intended for a temporary demo. For production, we recommend deploying the Streamlit app on amazon Elastic Compute Cloud (amazon EC2) or amazon Elastic Container Service (amazon ECS) services with proper security measures such as authentication and authorization.
We use the following models from amazon Bedrock in the solution. Please see Model support by AWS Region and select the Region that supports all three models:
Set up a JupyterLab space on SageMaker Studio
JupyterLab space is a private or shared space within Sagemaker Studio that manages the storage and compute resources needed to run the JupyterLab application.
To set up a JupyterLab space
- Sign in to your AWS account and open the AWS Management Console. Go to SageMaker Studio.
- Select your user profile and choose Open Studio.
- From Applications in the top left, choose JupyterLab.
- If you already have a JupyterLab space, choose Run. If you do not, choose Create JupyterLab Space to create one. Enter a name and choose Create Space.
- Change the instance to t3.large and choose Run Space.
- Within a minute, you should see that the JupyterLab space is ready. Choose Open JupyterLab.
- In the JupyterLab launcher window, choose Terminal.
- Run the following command on the terminal to download the sample code from Github:
Generate sample posts and compute multimodal embeddings
In the code repository, we provide some sample product images (bag, car, perfume, and candle) that were created using the amazon Titan Image Generator model. Next, you can generate some synthetic social media posts using the notebook: synthetic-data-generation.ipynb by using the following steps. The generated posts’ texts are saved in the metadata.jsonl file (if you prepared your own product images and post texts, you can skip this step). Then, compute multimodal embeddings for the pairs of images and generated texts. Finally, ingest the multimodal embeddings into a vector store on amazon OpenSearch Serverless.
To generate sample posts
- In JupyterLab, choose File Browser and navigate to the folder
social-media-generator/embedding-generation. - Open the notebook
synthetic-data-generation.ipynb. - Choose the default Python 3 kernel and Data Science 3.0 image, then follow the instructions in the notebook.
- At this stage, you will have sample posts that are created and available in
data_mapping.csv. - Open the notebook
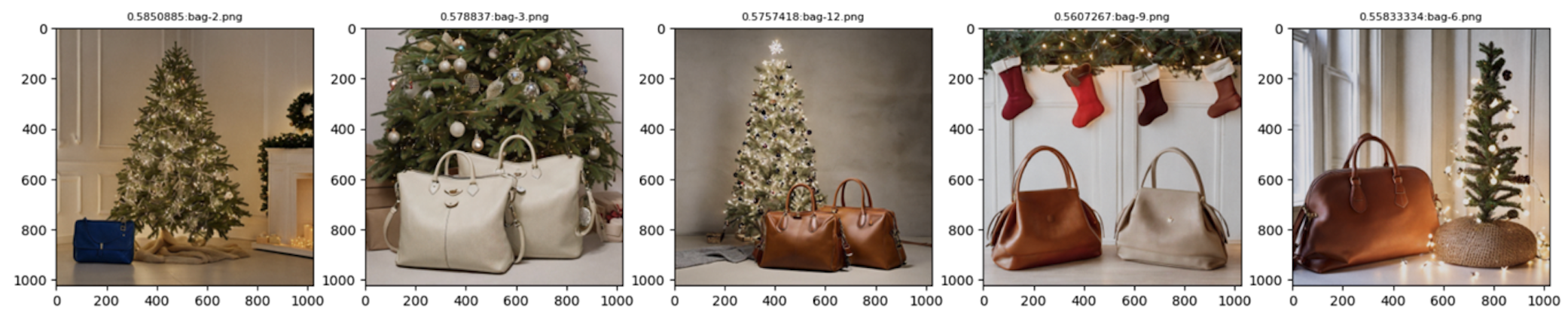
multimodal_embedding_generation.ipynb. The notebook first creates the multimodal embeddings for the post-image pair. It then ingests the computed embeddings into a vector store on amazon OpenSearch Serverless. - At the end of the notebook, you should be able to perform a simple query to the collection as shown in the following example:
The preparation steps are complete. If you want to try out the solution directly, you can skip to Run the solution with Streamlit App to quickly test the solution in your SageMaker environment. However, if you want a more detailed understanding of each step’s code and explanations, continue reading.
Generate a social media post (image and text) using FMs
In this solution, we use FMs through amazon Bedrock for content creation. We start by enhancing the input product image using the amazon Titan Image Generator model, which adds a dynamically relevant background around the target product.
The get_titan_ai_request_body function creates a JSON request body for the Titan Image Generator model, using its Outpainting feature. It accepts four parameters: outpaint_prompt (for example, “Christmas tree, holiday decoration” or “Mother’s Day, flowers, warm lights”), negative_prompt (elements to exclude from the generated image), mask_prompt (specifies areas to retain, such as “bag” or “car”), and image_str (the input image encoded as a base64 string).
The generate_image function requires model_id and body (the request body from get_titan_ai_request_body). It invokes the model using bedrock.invoke_model and returns the response containing the base64-encoded generated image.
Finally, the code snippet calls get_titan_ai_request_body with the provided prompts and input image string, then passes the request body to generate_image, resulting in the enhanced image.
The following images showcase the enhanced versions generated based on input prompts like “Christmas tree, holiday decoration, warm lights,” a selected position (such as bottom-middle), and a brand (“Luxury Brand”). These settings influence the output images. If the generated image is unsatisfactory, you can repeat the process until you achieve the desired outcome.

Next, generate the post text, taking into consideration the user inputs, brand guidelines (provided in the brand_guideline.csv file, which you can replace with your own data), and the enhanced image generated from the previous step.
The generate_text_with_claude function is the higher-level function that handles the image and text input, prepares the necessary data, and calls generate_vision_answer to interact with the amazon Bedrock model (Claude 3 models) and receive the desired response. The generate_vision_answer function performs the core interaction with the amazon Bedrock model, processes the model’s response, and returns it to the caller. Together, they enable generating text responses based on combined image and text inputs.
In the following code snippet, an initial post prompt is constructed using formatting placeholders for various elements such as role, product name, target brand, tone, hashtag, copywriting, and brand messaging. These elements are provided in the brand_guideline.csv file to make sure that the generated text aligns with the brand preferences and guidelines. This initial prompt is then passed to the generate_text_with_claude function, along with the enhanced image to generate the final post text.
The following example shows the generated post text. It provides a detailed description of the product, aligns well with the brand guidelines, and incorporates elements from the image (such as the Christmas tree). Additionally, we instructed the model to include hashtags and emojis where appropriate, and the results demonstrate that it followed the prompt instructions effectively.
|
Post text: Elevate your style with Luxury Brand’s latest masterpiece. Crafted with timeless elegance and superior quality, this exquisite bag embodies unique craftsmanship. Indulge in the epitome of sophistication and let it be your constant companion for life’s grandest moments. #LuxuryBrand #TimelessElegance #ExclusiveCollection |
Retrieve and analyze the top three relevant posts
The next step involves using the generated image and text to search for the top three similar historical posts from a vector database. We use the amazon Titan Multimodal Embeddings model to create embedding vectors, which are stored in amazon OpenSearch Serverless. The relevant historical posts, which might have many likes, are displayed on the application webpage to give users an idea of what successful social media posts look like. Additionally, we analyze these retrieved posts and provide actionable improvement recommendations for the user. The following code snippet shows the implementation of this step.
The code defines two functions: find_similar_items and process_images. find_similar_items performs semantic search using the k-nearest neighbors (kNN) algorithm on the input image prompt. It computes a multimodal embedding for the image and query prompt, constructs an OpenSearch kNN query, runs the search, and retrieves the top matching images and post texts. process_images analyzes a list of similar images in parallel using multiprocessing. It generates analysis texts for the images by calling generate_text_with_claude with an analysis prompt, running the calls in parallel, and collecting the results.
In the snippet, find_similar_items is called to retrieve the top three similar images and post texts based on the input image and a combined query prompt. process_images is then called to generate analysis texts for the first three similar images in parallel, displaying the results simultaneously.
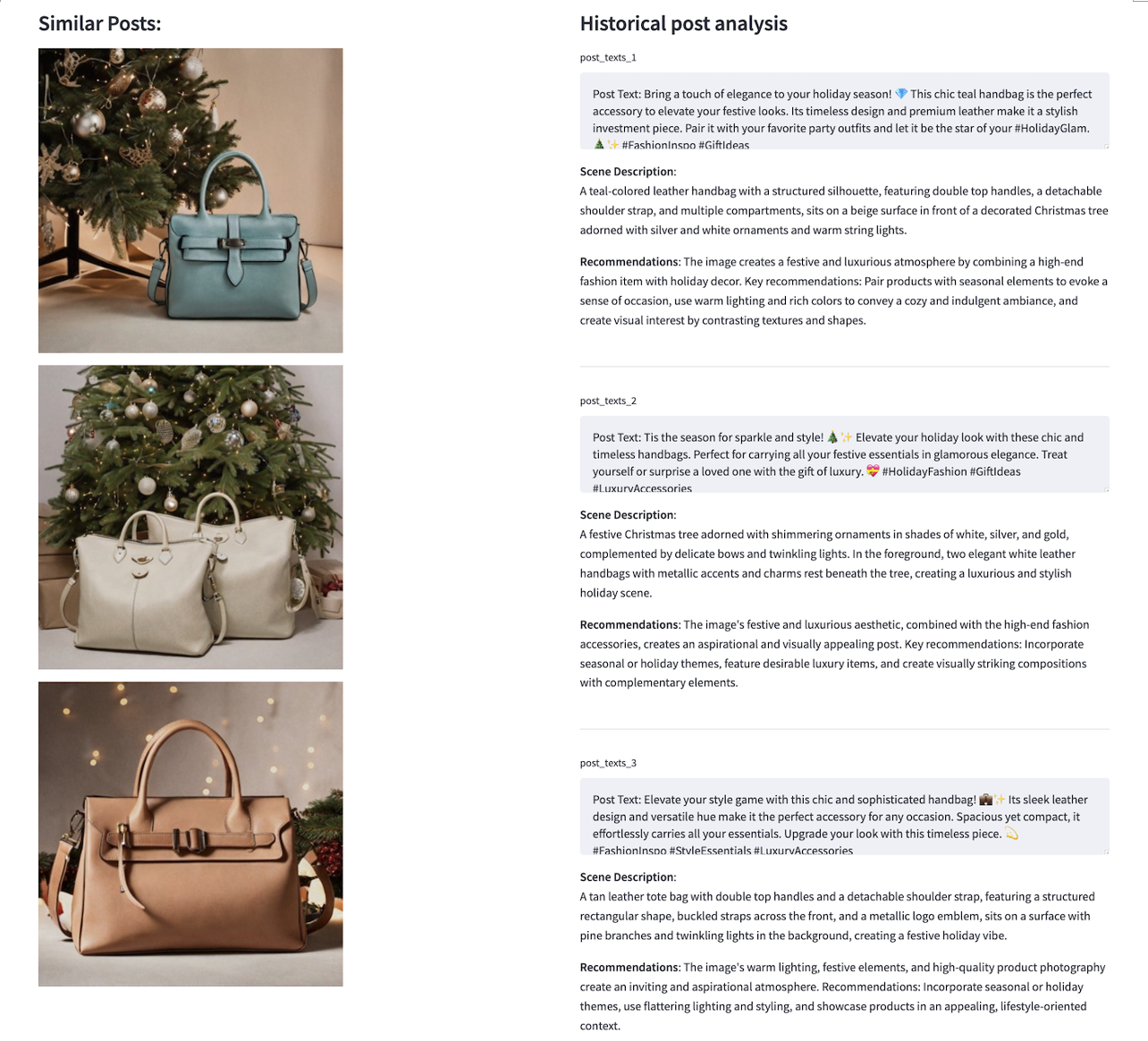
An example of historical post retrieval and analysis is shown in the following screenshot. Post images are listed on the left. On the right, the full text content of each post is retrieved and displayed. We then use an LLM model to generate a comprehensive scene description for the post image, which can serve as a prompt to inspire image generation. Next, the LLM model generates automatic recommendations for improvement. In this solution, we use the Claude 3 Sonnet model for text generation.
As the final step, the solution incorporates the recommendations and refines the post text to make it more appealing and likely to attract more attention from social media users.
Run the solution with Streamlit App
You can download the solution from this amazon-Bedrock” target=”_blank” rel=”noopener”>Git repository. Use the following steps to run the Streamlit application and quickly test out the solution in your SageMaker Studio environment.
- In SageMaker Studio, choose SageMaker Classic, then start an instance under your user profile.
- After you have the JupyterLab environment running, clone the code repository and navigate to the
streamlit-appfolder in a terminal: - You will see a webpage link generated in the terminal, which will look similar to the following:
https://(USER-PROFILE-ID).studio.(REGION).sagemaker.aws/jupyter/default/proxy/8501/
- To check the status of the Streamlit application, run
sh status.shin the terminal. - To shut down the application, run
sh cleanup.sh.
With the Streamlit app downloaded, you can begin by providing initial prompts and selecting the products you want to retain in the image. You have the option to upload an image from your local machine, plug in your camera to take an initial product picture on the fly, or quickly test the solution by selecting a pre-uploaded image example. You can then optionally adjust the product’s location in the image by setting its position. Next, select the brand for the product. In the demo, we use the luxury brand and the fast fashion brand, each with its own preferences and guidelines. Finally, choose the image style. Choose Submit to start the process.
The application will automatically handle post-image and text generation, retrieve similar posts for analysis, and refine the final post. This end-to-end process can take approximately 30 seconds. If you aren’t satisfied with the result, you can repeat the process a few times. An end-to-end demo is shown below.
Inspiration from historical posts using image similarity search
If you find yourself lacking ideas for initial prompts to create the enhanced image, consider using a reverse search approach. During the retrieve and analyze posts step mentioned earlier, scene descriptions are also generated, which can serve as inspiration. You can modify these descriptions as needed and use them to generate new images and accompanying text. This method effectively uses existing content to stimulate creativity and enhance the application’s output.
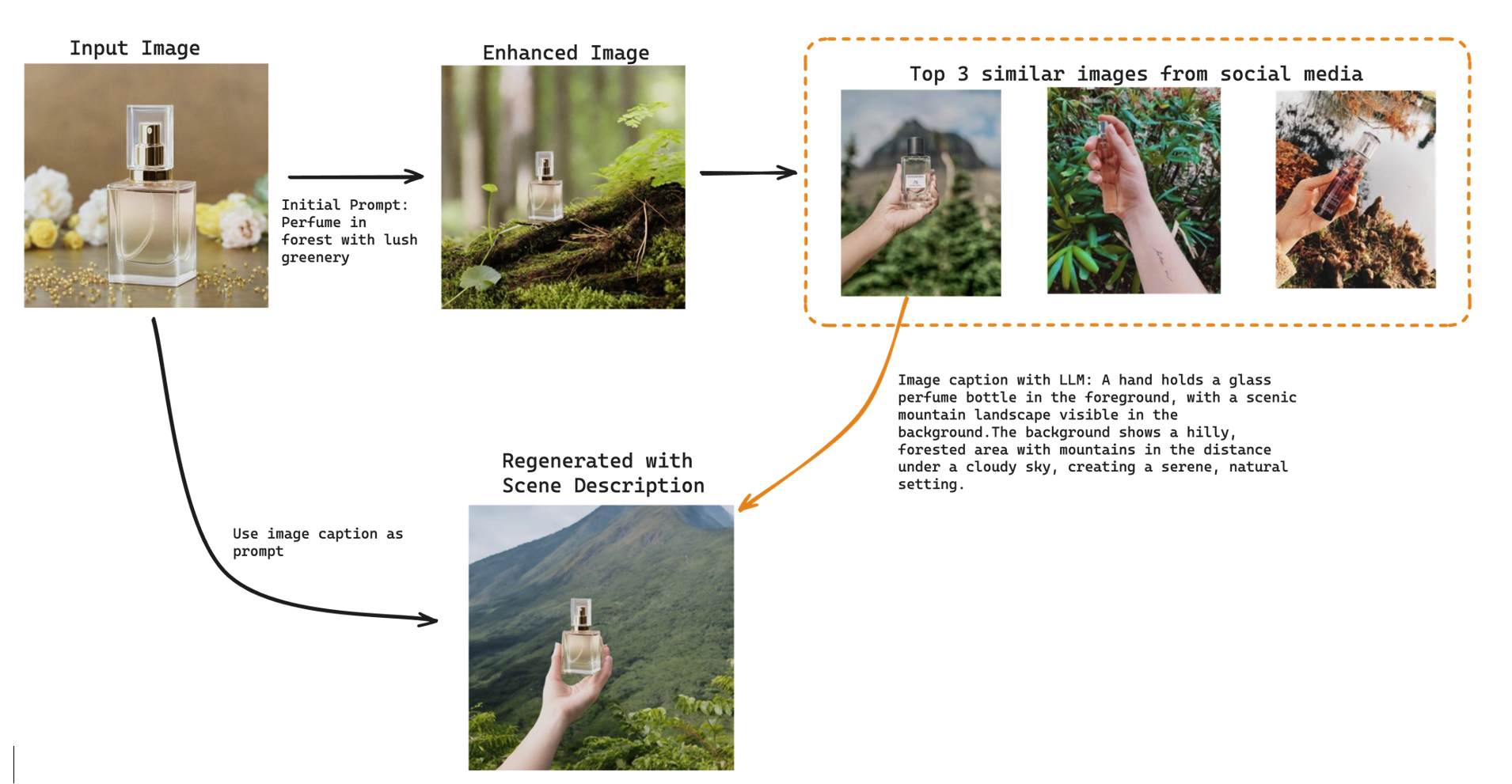
In the preceding example, the top three similar images to our generated images show perfume pictures posted to social media by users. This insight helps brands understand their target audience and the environments in which their products are used. By using this information, brands can create dynamic and engaging content that resonates with their users. For instance, in the example provided, “a hand holding a glass perfume bottle in the foreground, with a scenic mountain landscape visible in the background,” is unique and visually more appealing than a dull picture of “a perfume bottle standing on a branch in a forest.” This illustrates how capturing the right scene and context can significantly enhance the attractiveness and impact of social media content.
Clean up
When you finish experimenting with this solution, use the following steps to clean up the AWS resources to avoid unnecessary costs:
- Navigate to the amazon S3 console and delete the S3 bucket and data created for this solution.
- Navigate to the amazon OpenSearch Service console, choose Serverless, and then select Collection. Delete the collection that was created for storing the historical post embedding vectors.
- Navigate to the amazon SageMaker console. Choose Admin configurations and select Domains. Select your user profile and delete the running application from Spaces and Apps.
Conclusion
In this blog post, we introduced a multimodal social media content generator solution that uses FMs from amazon Bedrock, such as the amazon Titan Image Generator, Claude 3, and amazon Titan Multimodal Embeddings. The solution streamlines the content creation process, enabling brands and influencers to produce engaging and brand-consistent content rapidly. You can try out the solution using this amazon-Bedrock” target=”_blank” rel=”noopener”>code sample.
The solution involves enhancing product images with relevant backgrounds using the amazon Titan Image Generator, generating brand-aligned text descriptions through Claude 3, and retrieving similar historical posts using amazon Titan Multimodal Embeddings. It provides actionable recommendations to refine content for better audience resonance. This multimodal ai approach addresses challenges in rapid content production, personalization, and brand consistency, empowering creators to boost creativity and engagement while maintaining brand identity.
We encourage brands, influencers, and content teams to explore this solution and use the capabilities of FMs to streamline their content creation processes. Additionally, we invite developers and researchers to build upon this solution, experiment with different models and techniques, and contribute to the advancement of multimodal ai in the realm of social media content generation.
See this announcement blog post for information about the amazon Titan Image Generator and amazon Titan Multimodal Embeddings model. For more information, see amazon Bedrock and amazon Titan in amazon Bedrock.
About the Authors
 Ying Hou, PhD, is a Machine Learning Prototyping Architect at AWS, specialising in building GenAI applications with customers, including RAG and agent solutions. Her expertise spans GenAI, ASR, Computer Vision, NLP, and time series prediction models. Outside of work, she enjoys spending quality time with her family, getting lost in novels, and hiking in the UK’s national parks.
Ying Hou, PhD, is a Machine Learning Prototyping Architect at AWS, specialising in building GenAI applications with customers, including RAG and agent solutions. Her expertise spans GenAI, ASR, Computer Vision, NLP, and time series prediction models. Outside of work, she enjoys spending quality time with her family, getting lost in novels, and hiking in the UK’s national parks.
 Bishesh Adhikari, is a Senior ML Prototyping Architect at AWS with over a decade of experience in software engineering and ai/ML. Specializing in GenAI, LLMs, NLP, CV, and GeoSpatial ML, he collaborates with AWS customers to build solutions for challenging problems through co-development. His expertise accelerates customers’ journey from concept to production, tackling complex use cases across various industries. In his free time, he enjoys hiking, traveling, and spending time with family and friends.
Bishesh Adhikari, is a Senior ML Prototyping Architect at AWS with over a decade of experience in software engineering and ai/ML. Specializing in GenAI, LLMs, NLP, CV, and GeoSpatial ML, he collaborates with AWS customers to build solutions for challenging problems through co-development. His expertise accelerates customers’ journey from concept to production, tackling complex use cases across various industries. In his free time, he enjoys hiking, traveling, and spending time with family and friends.






{kind=link}