 NEWSLETTER
NEWSLETTER
Have you ever found yourself looking at a product's ingredients list and Googling unfamiliar chemical names to find out what they mean? It's a common struggle: Deciphering complex product information on the spot can be overwhelming and time-consuming. Traditional methods, such as searching for each ingredient individually, often lead to fragmented and confusing results. But what if there was a smarter, faster way to analyze product ingredients and get clear, actionable information instantly? In this article, we will guide you through creating a product ingredient analyzer using Gemini 2.0, Phidata, and Tavily Web Search. Let's dig in and make sense of those ingredient lists once and for all!
Learning objectives
- Design a multi-modal ai agent architecture using Phidata and Gemini 2.0 for vision and language tasks.
- Integrate Tavily Web Search into agent workflows for better context and information retrieval.
- Create a product ingredient analyzer agent that combines image processing and web search to obtain detailed product information.
- Discover how system cues and instructions guide agent behavior in multimodal tasks.
- Develop a Streamlit user interface for real-time image analysis, nutritional details, and health-based suggestions.
This article was published as part of the Data Science Blogathon.
What are multimodal systems?
Multimodal systems process and understand multiple types of input data, such as text, images, audio, and video, simultaneously. Vision language models, such as Gemini 2.0 Flash, GPT-4o, Claude Sonnet 3.5, and Pixtral-12B, excel at understanding the relationships between these modalities and extracting meaningful information from complex inputs.
In this context, we focus on vision and language models that analyze images and generate textual information. These systems combine computer vision and natural language processing to interpret visual information based on user input.
Real-world multimodal use cases
Multimodal systems are transforming industries:
- Finance: Users can take screenshots of unfamiliar terms in online forms and get instant explanations.
- e-commerce: Shoppers can photograph product labels to receive detailed ingredient analysis and health information.
- Education: Students can capture diagrams from textbooks and receive simplified explanations.
- health care: Patients can scan medical reports or prescription labels for simplified explanations of terms and dosing instructions.
Why multimodal agent?
The shift from single-mode ai to multimodal agents marks a huge leap in the way we interact with ai systems. This is what makes multimodal agents so effective:
- They process visual and textual information simultaneously, providing more accurate and context-aware responses.
- They simplify complex information, making it accessible to users who may have difficulty with technical terms or detailed content.
- Instead of manually searching for individual components, users can upload an image and receive a complete analysis in a single step.
- By combining tools such as web search and image analysis, they provide more complete and reliable information.
Construction Product Ingredient Analyzing Agent
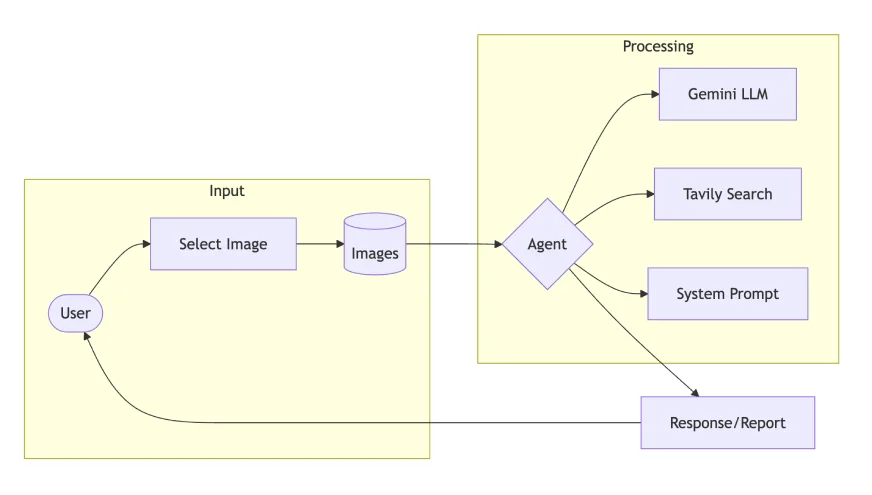
Let's analyze the implementation of a Product Ingredient Analysis Agent:
Step 1: Set up dependencies
- Gemini 2.0 Flash: Handles multi-modal processing with enhanced vision capabilities
- Tavily Search – Provides web search integration for additional context
- Phidata: organize the agent system and manage workflows
- Streamlit: Develop the prototype into web-based applications.
!pip install phidata google-generativeai tavily-python streamlit pillowStep 2: Configuration and API Configuration
In this step, we will configure the environment variables and collect the API credentials necessary to run this use case.
from phi.agent import Agent
from phi.model.google import Gemini # needs a api key
from phi.tools.tavily import TavilyTools # also needs a api key
import os
TAVILY_API_KEY = ""
GOOGLE_API_KEY = ""
os.environ('TAVILY_API_KEY') = TAVILY_API_KEY
os.environ('GOOGLE_API_KEY') = GOOGLE_API_KEYStep 3: System Notice and Instructions
To get better responses from language models, you need to write better prompts. This involves clearly defining the role and providing detailed instructions in the system message for the LLM.
Let's define the role and responsibilities of an Agent with experience in ingredient and nutrition analysis. The instructions should guide the Agent to systematically analyze food products, evaluate ingredients, consider dietary restrictions, and evaluate health implications.
SYSTEM_PROMPT = """
You are an expert Food Product Analyst specialized in ingredient analysis and nutrition science.
Your role is to analyze product ingredients, provide health insights, and identify potential concerns by combining ingredient analysis with scientific research.
You utilize your nutritional knowledge and research works to provide evidence-based insights, making complex ingredient information accessible and actionable for users.
Return your response in Markdown format.
"""
INSTRUCTIONS = """
* Read ingredient list from product image
* Remember the user may not be educated about the product, break it down in simple words like explaining to 10 year kid
* Identify artificial additives and preservatives
* Check against major dietary restrictions (vegan, halal, kosher). Include this in response.
* Rate nutritional value on scale of 1-5
* Highlight key health implications or concerns
* Suggest healthier alternatives if needed
* Provide brief evidence-based recommendations
* Use Search tool for getting context
"""Step 4: Define the agent object
The Agent, built with Phidata, is configured to process the markdown format and operate based on the system prompt and instructions defined above. The reasoning model used in this example is Gemini 2.0 Flash, known for its superior ability to understand images and videos compared to other models.
For tool integration, we will use Tavily Search, an advanced web search engine that provides relevant context directly in response to user queries, avoiding unnecessary descriptions, URLs, and irrelevant parameters.
agent = Agent(
model = Gemini(id="gemini-2.0-flash-exp"),
tools = (TavilyTools()),
markdown=True,
system_prompt = SYSTEM_PROMPT,
instructions = INSTRUCTIONS
)Step 5: Multimodal: Image Understanding
Once the Agent components are installed, the next step is to provide information to the user. This can be done in two ways: passing the image path or URL, along with a user message specifying what information should be extracted from the provided image.
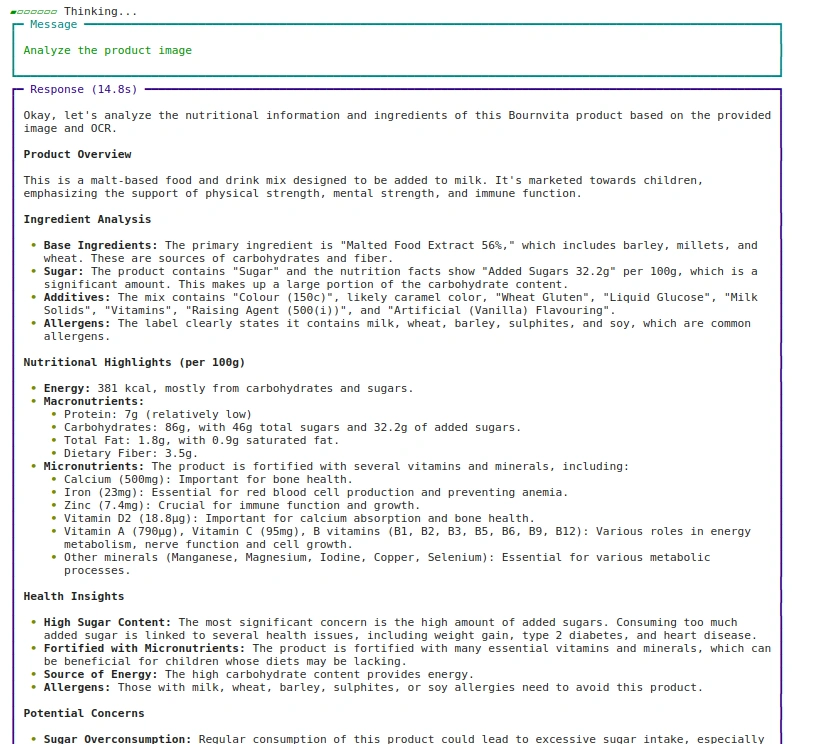
Approach: 1 Using image path

agent.print_response(
"Analyze the product image",
images = ("images/bournvita.jpg"),
stream=True
)Production:
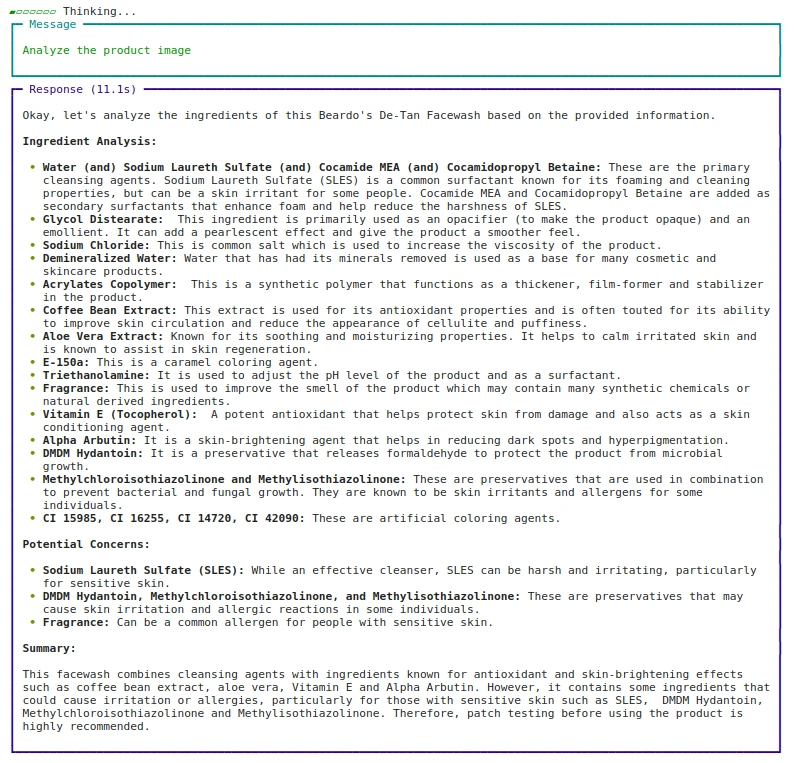
Approach: 2 Using URL
agent.print_response(
"Analyze the product image",
images = ("https://beardo.in/cdn/shop/products/9_2ba7ece4-0372-4a34-8040-5dc40c89f103.jpg?v=1703589764&width=1946"),
stream=True
)Production:
Step 6 – Develop the web application using Streamlit
Now that we know how to run the Multimodal Agent, let's build the UI part using Streamlit.
import streamlit as st
from PIL import Image
from io import BytesIO
from tempfile import NamedTemporaryFile
st.title(" Product Ingredient Analyzer")
Product Ingredient Analyzer")To optimize performance, define Agent inference to a cached function. The cache decorator helps improve efficiency by reusing the Agent instance.
Since we are using Streamlit, which refreshes the entire page after each event loop or widget activation, adding st.cache_resource ensures that the function is not refreshed and saves it to the cache.
@st.cache_resource
def get_agent():
return Agent(
model=Gemini(id="gemini-2.0-flash-exp"),
system_prompt=SYSTEM_PROMPT,
instructions=INSTRUCTIONS,
tools=(TavilyTools(api_key=os.getenv("TAVILY_API_KEY"))),
markdown=True,
)When the user provides a new image path, the analyze_image function is executed and executes the Agent object defined in get_agent. For real-time capture and image upload option, the uploaded file must be temporarily saved for processing.
The image is stored in a temporary file, and after execution is completed, the temporary file is deleted to free up resources. This can be done using the NamedTemporaryFile function of the tempfile library.
def analyze_image(image_path):
agent = get_agent()
with st.spinner('Analyzing image...'):
response = agent.run(
"Analyze the given image",
images=(image_path),
)
st.markdown(response.content)
def save_uploaded_file(uploaded_file):
with NamedTemporaryFile(dir=".", suffix='.jpg', delete=False) as f:
f.write(uploaded_file.getbuffer())
return f.nameFor better user interface, when a user selects an image, it is likely to have different resolutions and sizes. To maintain a consistent layout and correctly display the image, we may resize the uploaded or captured image to ensure it fits clearly on the screen.
LANCZOS' resampling algorithm provides high-quality resizing, which is especially beneficial for product images where text clarity is crucial for ingredient analysis.
MAX_IMAGE_WIDTH = 300
def resize_image_for_display(image_file):
img = Image.open(image_file)
aspect_ratio = img.height / img.width
new_height = int(MAX_IMAGE_WIDTH * aspect_ratio)
img = img.resize((MAX_IMAGE_WIDTH, new_height), Image.Resampling.LANCZOS)
buf = BytesIO()
img.save(buf, format="PNG")
return buf.getvalue()Step 7: UI Features for Streamlit
The interface is divided into three navigation tabs where the user can choose their interests:
- Tab-1: Example products that users can select to test the app
- Tab-2: Upload an image of your choice if it is already saved.
- Tab 3: Capture or Take a live photo and analyze the product.
We repeat the same logical flow for the 3 tabs:
- First, choose the image of your choice and resize it to display in the Streamlit UI using image st..
- Second, save that image to a temporary directory for processing in the Agent object.
- Third, analyze the image where the Agent execution will take place using Gemini 2.0 LLM and the Tavily Search tool.
State management is handled through Streamlit session state, tracking selected examples and analysis status.

def main():
if 'selected_example' not in st.session_state:
st.session_state.selected_example = None
if 'analyze_clicked' not in st.session_state:
st.session_state.analyze_clicked = False
tab_examples, tab_upload, tab_camera = st.tabs((
" Example Products",
"
Example Products",
" Upload Image",
"
Upload Image",
" Take Photo"
))
with tab_examples:
example_images = {
"
Take Photo"
))
with tab_examples:
example_images = {
" Energy Drink": "images/bournvita.jpg",
"
Energy Drink": "images/bournvita.jpg",
" Potato Chips": "images/lays.jpg",
"
Potato Chips": "images/lays.jpg",
" Shampoo": "images/shampoo.jpg"
}
cols = st.columns(3)
for idx, (name, path) in enumerate(example_images.items()):
with cols(idx):
if st.button(name, use_container_width=True):
st.session_state.selected_example = path
st.session_state.analyze_clicked = False
with tab_upload:
uploaded_file = st.file_uploader(
"Upload product image",
type=("jpg", "jpeg", "png"),
help="Upload a clear image of the product's ingredient list"
)
if uploaded_file:
resized_image = resize_image_for_display(uploaded_file)
st.image(resized_image, caption="Uploaded Image", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button(" Analyze Uploaded Image", key="analyze_upload"):
temp_path = save_uploaded_file(uploaded_file)
analyze_image(temp_path)
os.unlink(temp_path)
with tab_camera:
camera_photo = st.camera_input("Take a picture of the product")
if camera_photo:
resized_image = resize_image_for_display(camera_photo)
st.image(resized_image, caption="Captured Photo", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button(" Analyze Captured Photo", key="analyze_camera"):
temp_path = save_uploaded_file(camera_photo)
analyze_image(temp_path)
os.unlink(temp_path)
if st.session_state.selected_example:
st.divider()
st.subheader("Selected Product")
resized_image = resize_image_for_display(st.session_state.selected_example)
st.image(resized_image, caption="Selected Example", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button(" Analyze Example", key="analyze_example") and not st.session_state.analyze_clicked:
st.session_state.analyze_clicked = True
analyze_image(st.session_state.selected_example)
Shampoo": "images/shampoo.jpg"
}
cols = st.columns(3)
for idx, (name, path) in enumerate(example_images.items()):
with cols(idx):
if st.button(name, use_container_width=True):
st.session_state.selected_example = path
st.session_state.analyze_clicked = False
with tab_upload:
uploaded_file = st.file_uploader(
"Upload product image",
type=("jpg", "jpeg", "png"),
help="Upload a clear image of the product's ingredient list"
)
if uploaded_file:
resized_image = resize_image_for_display(uploaded_file)
st.image(resized_image, caption="Uploaded Image", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button(" Analyze Uploaded Image", key="analyze_upload"):
temp_path = save_uploaded_file(uploaded_file)
analyze_image(temp_path)
os.unlink(temp_path)
with tab_camera:
camera_photo = st.camera_input("Take a picture of the product")
if camera_photo:
resized_image = resize_image_for_display(camera_photo)
st.image(resized_image, caption="Captured Photo", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button(" Analyze Captured Photo", key="analyze_camera"):
temp_path = save_uploaded_file(camera_photo)
analyze_image(temp_path)
os.unlink(temp_path)
if st.session_state.selected_example:
st.divider()
st.subheader("Selected Product")
resized_image = resize_image_for_display(st.session_state.selected_example)
st.image(resized_image, caption="Selected Example", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button(" Analyze Example", key="analyze_example") and not st.session_state.analyze_clicked:
st.session_state.analyze_clicked = True
analyze_image(st.session_state.selected_example)Important links
- You can find the full code. here.
- Replace the “”placeholder with your keys.
- For tab_examples, you must have a folder image. And save the images there. Here is the GitHub URL with the images directory. here.
- If you are interested in using the use case, here is the implemented application. here.
Conclusion
Multimodal ai agents represent a breakthrough in the way we can interact and understand complex information in our daily lives. By combining vision processing, natural language understanding, and web search capabilities, these systems, such as the Product Ingredient Analyzer, can provide instant and comprehensive analysis of products and their ingredients, making decision-making informed decisions more accessible to everyone.
Key takeaways
- Multimodal ai agents improve the way we understand product information. They combine text and image analysis.
- With Phidata, an open source framework, we can create and manage agent systems. These systems use models such as GPT-4o and Gemini 2.0.
- Agents use tools such as vision processing and web search. This makes your analysis more complete and accurate. LLMs have limited knowledge, so agents use tools to better handle complex tasks.
- Streamlit makes it easy to create web applications for LLM-based tools. Examples include RAG and multimodal agents.
- Good system messages and instructions guide the agent. This ensures useful and accurate answers.
Frequently asked questions
A. LLaVA (Large Language and Vision Assistant), Pixtral-12B by Mistral.ai, Multimodal-GPT by OpenFlamingo, NVILA by Nvidia and the Qwen model are some open source or weighted multimodal vision language models that process text and images for tasks. as a visual answer to questions.
A. Yes, Llama 3 is multi-modal and also the Llama 3.2 Vision models (parameters 11B and 90B) process text and images, enabling tasks such as image captioning and visual reasoning.
A. A multimodal large language model (LLM) processes and generates data in multiple modalities, such as text, images, and audio. In contrast, a Multimodal Agent uses such models to interact with its environment, perform tasks and make decisions based on multimodal inputs, often integrating additional tools and systems to execute complex actions.
The media shown in this article is not the property of Analytics Vidhya and is used at the author's discretion.

Data Scientist at ai Planet || YouTube: AIWithTarun || Google ML Developer Expert || Won 5 ai hackathons || TensorFlow Bangalore User Group Co-Organizer || Foot and ai Ambassador at DeepLearningAI





