 NEWSLETTER
NEWSLETTER
The financial service (FinServ) industry has unique generative ai requirements related to domain-specific data, data security, regulatory controls, and industry compliance standards. In addition, customers are looking for choices to select the most performant and cost-effective machine learning (ML) model and the ability to perform necessary customization (fine-tuning) to fit their business use cases. Amazon SageMaker JumpStart is ideally suited for generative ai use cases for FinServ customers because it provides the necessary data security controls and meets compliance standards requirements.
In this post, we demonstrate question answering tasks using a Retrieval Augmented Generation (RAG)-based approach with large language models (LLMs) in SageMaker JumpStart using a simple financial domain use case. RAG is a framework for improving the quality of text generation by combining an LLM with an information retrieval (IR) system. The LLM generated text, and the IR system retrieves relevant information from a knowledge base. The retrieved information is then used to augment the LLM’s input, which can help improve the accuracy and relevance of the model generated text. RAG has been shown to be effective for a variety of text generation tasks, such as question answering and summarization. It is a promising approach for improving the quality and accuracy of text generation models.
Advantages of using SageMaker JumpStart
With SageMaker JumpStart, ML practitioners can choose from a broad selection of state-of-the-art models for use cases such as content writing, image generation, code generation, question answering, copywriting, summarization, classification, information retrieval, and more. ML practitioners can deploy foundation models to dedicated Amazon SageMaker instances from a network isolated environment and customize models using SageMaker for model training and deployment.
SageMaker JumpStart is ideally suited for generative ai use cases for FinServ customers because it offers the following:
- Customization capabilities – SageMaker JumpStart provides example notebooks and detailed posts for step-by-step guidance on domain adaptation of foundation models. You can follow these resources for fine-tuning, domain adaptation, and instruction of foundation models or to build RAG-based applications.
- Data security – Ensuring the security of inference payload data is paramount. With SageMaker JumpStart, you can deploy models in network isolation with single-tenancy endpoint provision. Furthermore, you can manage access control to selected models through the private model hub capability, aligning with individual security requirements.
- Regulatory controls and compliances – Compliance with standards such as HIPAA BAA, SOC123, PCI, and HITRUST CSF is a core feature of SageMaker, ensuring alignment with the rigorous regulatory landscape of the financial sector.
- Model choices – SageMaker JumpStart offers a selection of state-of-the-art ML models that consistently rank among the top in industry-recognized HELM benchmarks. These include, but are not limited to, Llama 2, Falcon 40B, AI21 J2 Ultra, AI21 Summarize, Hugging Face MiniLM, and BGE models.
In this post, we explore building a contextual chatbot for financial services organizations using a RAG architecture with the Llama 2 foundation model and the Hugging Face GPTJ-6B-FP16 embeddings model, both available in SageMaker JumpStart. We also use Vector Engine for Amazon OpenSearch Serverless (currently in preview) as the vector data store to store embeddings.
Limitations of large language models
LLMs have been trained on vast volumes of unstructured data and excel in general text generation. Through this training, LLMs acquire and store factual knowledge. However, off-the-shelf LLMs present limitations:
- Their offline training renders them unaware of up-to-date information.
- Their training on predominantly generalized data diminishes their efficacy in domain-specific tasks. For instance, a financial firm might prefer its Q&A bot to source answers from its latest internal documents, ensuring accuracy and compliance with its business rules.
- Their reliance on embedded information compromises interpretability.
To use specific data in LLMs, three prevalent methods exist:
- Embedding data within the model prompts, allowing it to utilize this context during output generation. This can be zero-shot (no examples), few-shot (limited examples), or many-shot (abundant examples). Such contextual prompting steers models towards more nuanced results.
- Fine-tuning the model using pairs of prompts and completions.
- RAG, which retrieves external data (non-parametric) and integrates this data into the prompts, enriching the context.
However, the first method grapples with model constraints on context size, making it tough to input lengthy documents and possibly increasing costs. The fine-tuning approach, while potent, is resource-intensive, particularly with ever-evolving external data, leading to delayed deployments and increased costs. RAG combined with LLMs offers a solution to the previously mentioned limitations.
Retrieval Augmented Generation
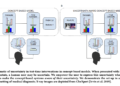
RAG retrieves external data (non-parametric) and integrates this data into ML prompts, enriching the context. Lewis et al. introduced RAG models in 2020, conceptualizing them as a fusion of a pre-trained sequence-to-sequence model (parametric memory) and a dense vector index of Wikipedia (non-parametric memory) accessed via a neural retriever.
Here’s how RAG operates:
- Data sources – RAG can draw from varied data sources, including document repositories, databases, or APIs.
- Data formatting – Both the user’s query and the documents are transformed into a format suitable for relevancy comparisons.
- Embeddings – To facilitate this comparison, the query and the document collection (or knowledge library) are transformed into numerical embeddings using language models. These embeddings numerically encapsulate textual concepts.
- Relevancy search – The user query’s embedding is compared to the document collection’s embeddings, identifying relevant text through a similarity search in the embedding space.
- Context enrichment – The identified relevant text is appended to the user’s original prompt, thereby enhancing its context.
- LLM processing – With the enriched context, the prompt is fed to the LLM, which, due to the inclusion of pertinent external data, produces relevant and precise outputs.
- Asynchronous updates – To ensure the reference documents remain current, they can be updated asynchronously along with their embedding representations. This ensures that future model responses are grounded in the latest information, guaranteeing accuracy.
In essence, RAG offers a dynamic method to infuse LLMs with real-time, relevant information, ensuring the generation of precise and timely outputs.
The following diagram shows the conceptual flow of using RAG with LLMs.
Solution overview
The following steps are required to create a contextual question answering chatbot for a financial services application:
- Use the SageMaker JumpStart GPT-J-6B embedding model to generate embeddings for each PDF document in the Amazon Simple Storage Service (Amazon S3) upload directory.
- Identify relevant documents using the following steps:
- Generate an embedding for the user’s query using the same model.
- Use OpenSearch Serverless with the vector engine feature to search for the top K most relevant document indexes in the embedding space.
- Retrieve the corresponding documents using the identified indexes.
- Combine the retrieved documents as context with the user’s prompt and question. Forward this to the SageMaker LLM for response generation.
We employ LangChain, a popular framework, to orchestrate this process. LangChain is specifically designed to bolster applications powered by LLMs, offering a universal interface for various LLMs. It streamlines the integration of multiple LLMs, ensuring seamless state persistence between calls. Moreover, it boosts developer efficiency with features like customizable prompt templates, comprehensive application-building agents, and specialized indexes for search and retrieval. For an in-depth understanding, refer to the LangChain documentation.
Prerequisites
You need the following prerequisites to build our context-aware chatbot:
For instructions on how to set up an OpenSearch Serverless vector engine, refer to Introducing the vector engine for Amazon OpenSearch Serverless, now in preview.
For a comprehensive walkthrough of the following solution, clone the GitHub repo and refer to the Jupyter notebook.
Deploy the ML models using SageMaker JumpStart
To deploy the ML models, complete the following steps:
- Deploy the Llama 2 LLM from SageMaker JumpStart:
- Deploy the GPT-J embeddings model:
Chunk data and create a document embeddings object
In this section, you chunk the data into smaller documents. Chunking is a technique for splitting large texts into smaller chunks. It’s an essential step because it optimizes the relevance of the search query for our RAG model, which in turn improves the quality of the chatbot. The chunk size depends on factors such as the document type and the model used. A chunk chunk_size=1600 has been selected because this is the approximate size of a paragraph. As models improve, their context window size will increase, allowing for larger chunk sizes.
Refer to the Jupyter notebook in the GitHub repo for the complete solution.
- Extend the LangChain
SageMakerEndpointEmbeddingsclass to create a custom embeddings function that uses the gpt-j-6b-fp16 SageMaker endpoint you created earlier (as part of employing the embeddings model): - Create the embeddings object and batch the creation of the document embeddings:
- These embeddings are stored in the vector engine using LangChain
OpenSearchVectorSearch. You store these embeddings in the next section. Store the document embedding in OpenSearch Serverless. You’re now ready to iterate over the chunked documents, create the embeddings, and store these embeddings in the OpenSearch Serverless vector index created in vector search collections. See the following code:
Question and answering over documents
So far, you have chunked a large document into smaller ones, created vector embeddings, and stored them in a vector engine. Now you can answer questions regarding this document data. Because you created an index over the data, you can do a semantic search; this way, only the most relevant documents required to answer the question are passed via the prompt to the LLM. This allows you to save time and money by only passing relevant documents to the LLM. For more details on using document chains, refer to Documents.
Complete the following steps to answer questions using the documents:
- To use the SageMaker LLM endpoint with LangChain, you use
langchain.llms.sagemaker_endpoint.SagemakerEndpoint, which abstracts the SageMaker LLM endpoint. You perform a transformation for the request and response payload as shown in the following code for the LangChain SageMaker integration. Note that you may need to adjust the code in ContentHandler based on the content_type and accepts format of the LLM model you choose to use.
Now you’re ready to interact with the financial document.
- Use the following query and prompt template to ask questions regarding the document:
Cleanup
To avoid incurring future costs, delete the SageMaker inference endpoints that you created in this notebook. You can do so by running the following in your SageMaker Studio notebook:
If you created an OpenSearch Serverless collection for this example and no longer require it, you can delete it via the OpenSearch Serverless console.
Conclusion
In this post, we discussed using RAG as an approach to provide domain-specific context to LLMs. We showed how to use SageMaker JumpStart to build a RAG-based contextual chatbot for a financial services organization using Llama 2 and OpenSearch Serverless with a vector engine as the vector data store. This method refines text generation using Llama 2 by dynamically sourcing relevant context. We’re excited to see you bring your custom data and innovate with this RAG-based strategy on SageMaker JumpStart!
About the authors
 Sunil Padmanabhan is a Startup Solutions Architect at AWS. As a former startup founder and CTO, he is passionate about machine learning and focuses on helping startups leverage ai/ML for their business outcomes and design and deploy ML/ai solutions at scale.
Sunil Padmanabhan is a Startup Solutions Architect at AWS. As a former startup founder and CTO, he is passionate about machine learning and focuses on helping startups leverage ai/ML for their business outcomes and design and deploy ML/ai solutions at scale.
 Suleman Patel is a Senior Solutions Architect at Amazon Web Services (AWS), with a special focus on Machine Learning and Modernization. Leveraging his expertise in both business and technology, Suleman helps customers design and build solutions that tackle real-world business problems. When he’s not immersed in his work, Suleman loves exploring the outdoors, taking road trips, and cooking up delicious dishes in the kitchen.
Suleman Patel is a Senior Solutions Architect at Amazon Web Services (AWS), with a special focus on Machine Learning and Modernization. Leveraging his expertise in both business and technology, Suleman helps customers design and build solutions that tackle real-world business problems. When he’s not immersed in his work, Suleman loves exploring the outdoors, taking road trips, and cooking up delicious dishes in the kitchen.





{kind=link}