 NEWSLETTER
NEWSLETTER
Introduction
Large Language Models or LLMs, have been all the rage since the advent of ChatGPT in 2022. This is largely thanks to the success of the transformer architecture and availability of terabytes worth of text data over the internet. Despite their fame, LLMs are fundamentally limited to working only with texts.
A VLM is worth 1000 LLMs
Vision Language Models or VLMs are ai models that use both images and textual data to perform tasks that fundamentally need both of them. With how good LLMs have become, building quality VLMs has become the next logical step towards Artificial General Intelligence.
In this article, let’s understand the fundamentals of VLMs with a focus on how to build one. Throughout this article, we will cover the latest papers in the research and will provide with relevant links to the papers.
To give an overview, in the following sections, we will cover following topics:
- The applications of VLMs
- The historical background of VLMs, including their origins and factors contributing to their rise.
- A taxonomy of different VLM architectures, with examples for each category.
- An overview of key components involved in training VLMs, along with notable papers that utilized these components.
- A review of datasets used to train various VLMs, highlighting what made them unique.
- Evaluation benchmarks used to compare model performance, explaining why certain evaluations are crucial for specific applications.
- State-of-the-art VLMs in relation to these benchmarks.
- A section focusing on VLMs for document understanding and leading models for extracting information from documents.
- Finally, we will conclude with key things to consider for picking up a VLM for your use case.
A couple of disclaimers:
VLMs work with texts and images, and there are a class of models called Image Generators that do the following:
- Image Generation from text/prompt: Generate images from scratch that follow a description
- Image Generation from text and image: Generate images that resemble a given image but are modified as per the description
While these are still considered VLMs on a technicality, we will not be talking about them as the research involved is fundamentally different. Our coverage will be exclusive to VLMs that generate text as output.
There exists another class of models, known as Multimodal-LLMs (MLLMs). Although they sound similar to VLMs, MLLMs are a broader category that can work with various combinations of image, video, audio, and text modalities. In other words, VLMs are just a subset of MLLMs.
Finally, the figures for model architectures and benchmarks were taken from the respective papers preceding the figures.
Applications of VLMs
Here are some straightforward applications that only VLMs can solve –
Image Captioning: Automatically generate text describing the images️
Dense Captioning: Generating multiple captions with a focus on describing all the salient features/objects in the image
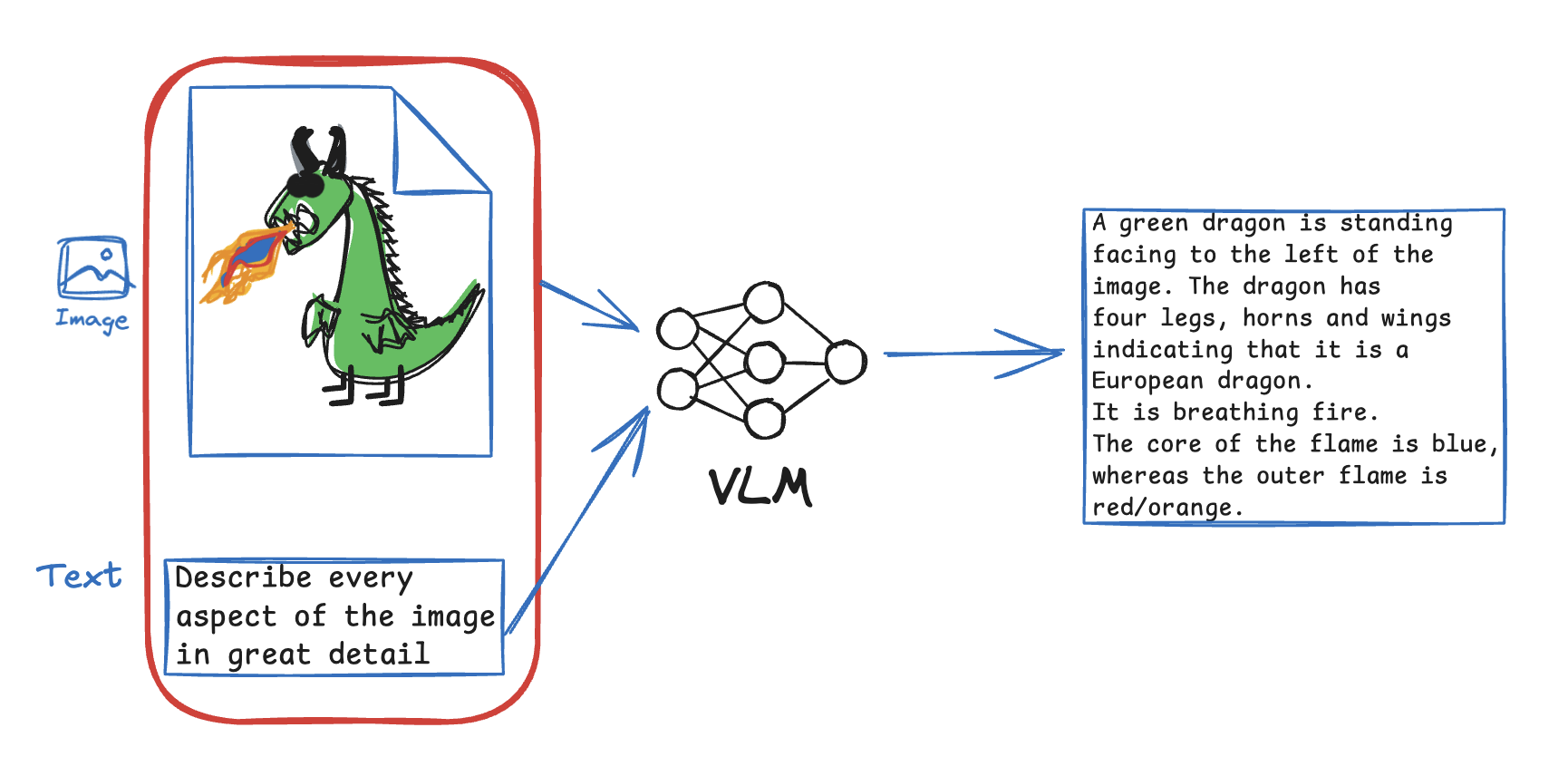
Instance Detection: Detection of objects with bounding boxes in an image
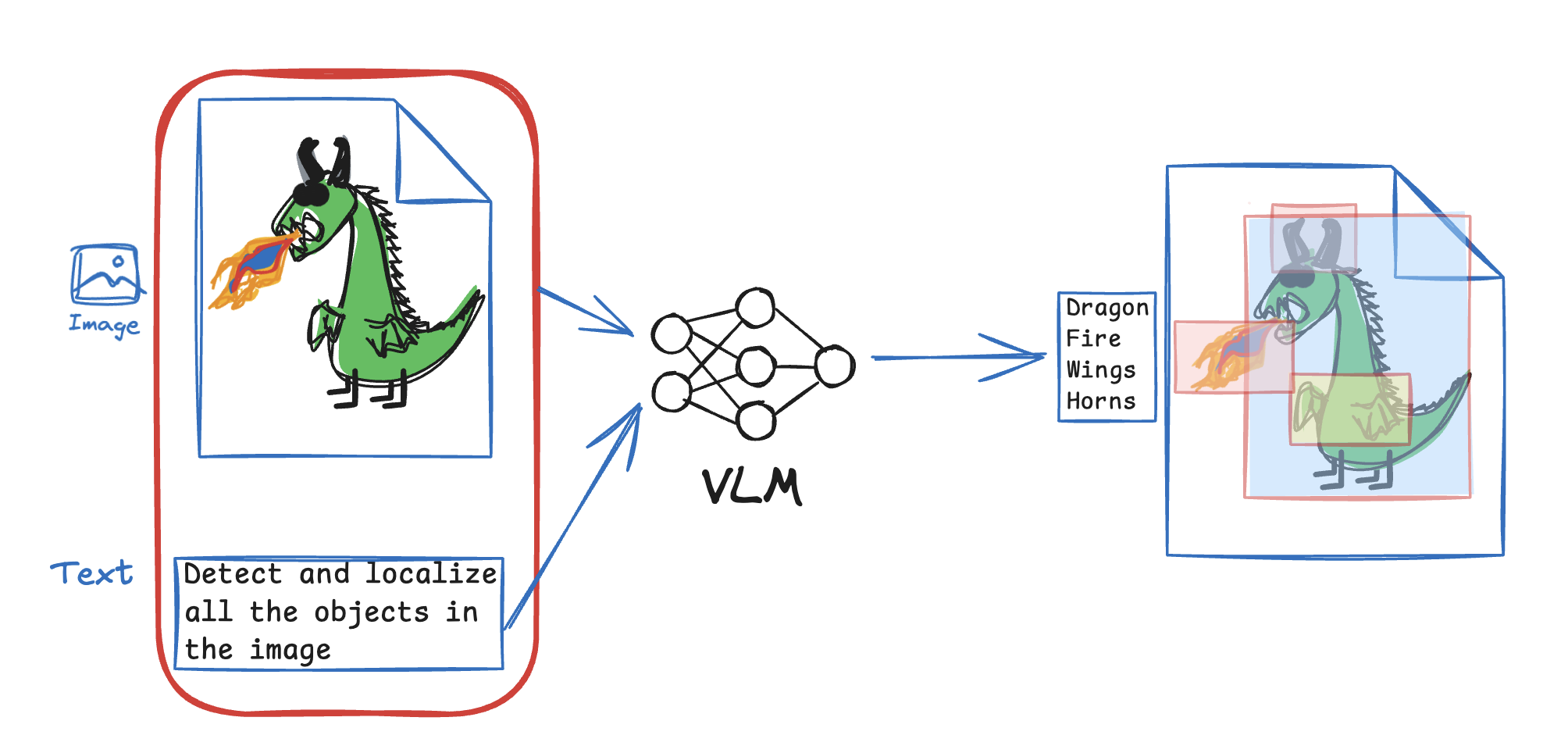
Visual Question Answering (VQA): Questioning (text) and answering (text) about an image️
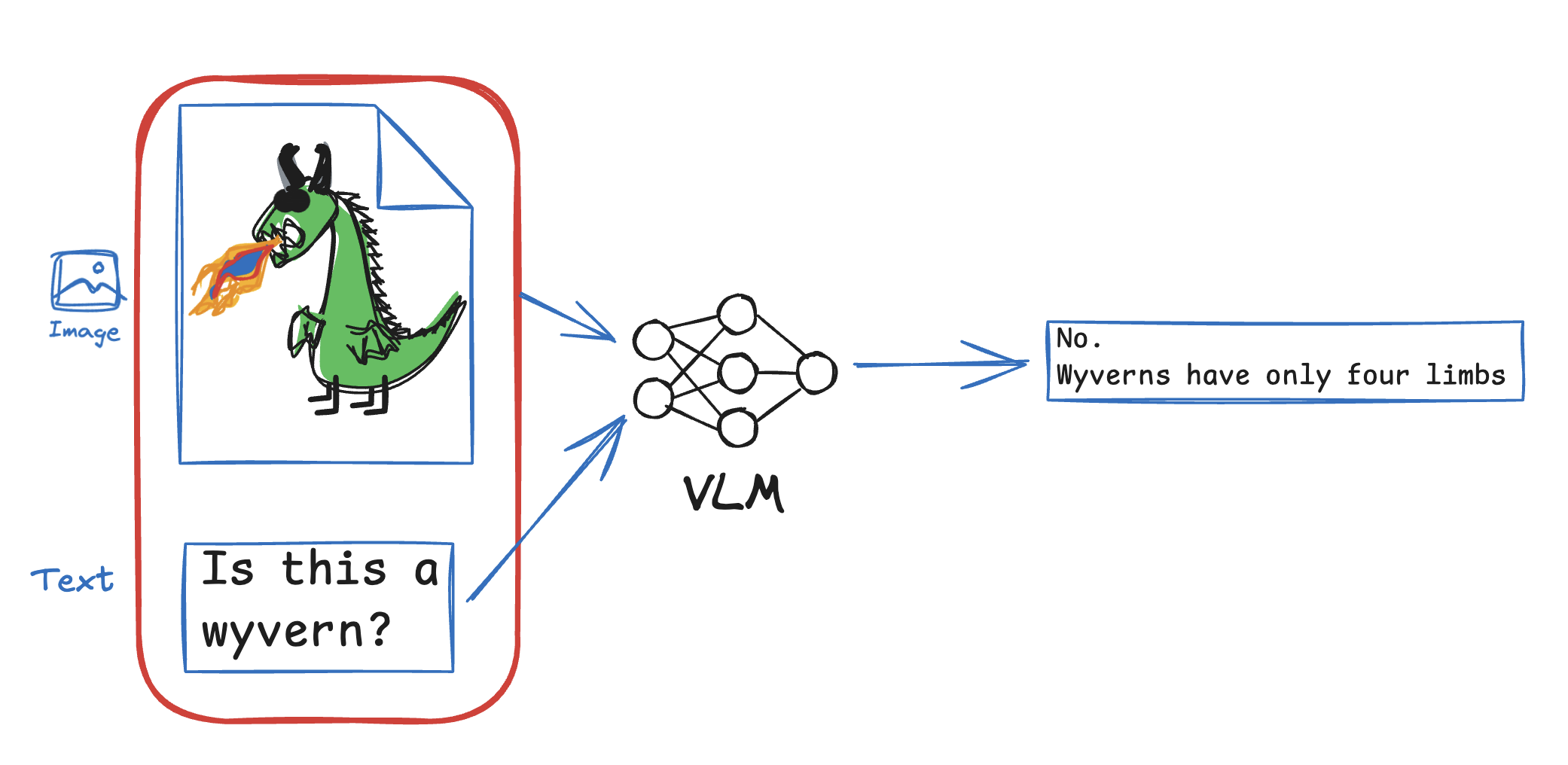
Image Retrieval or Text to Image discovery: Finding images that match a given text description (Sort of the opposite of Image Captioning)
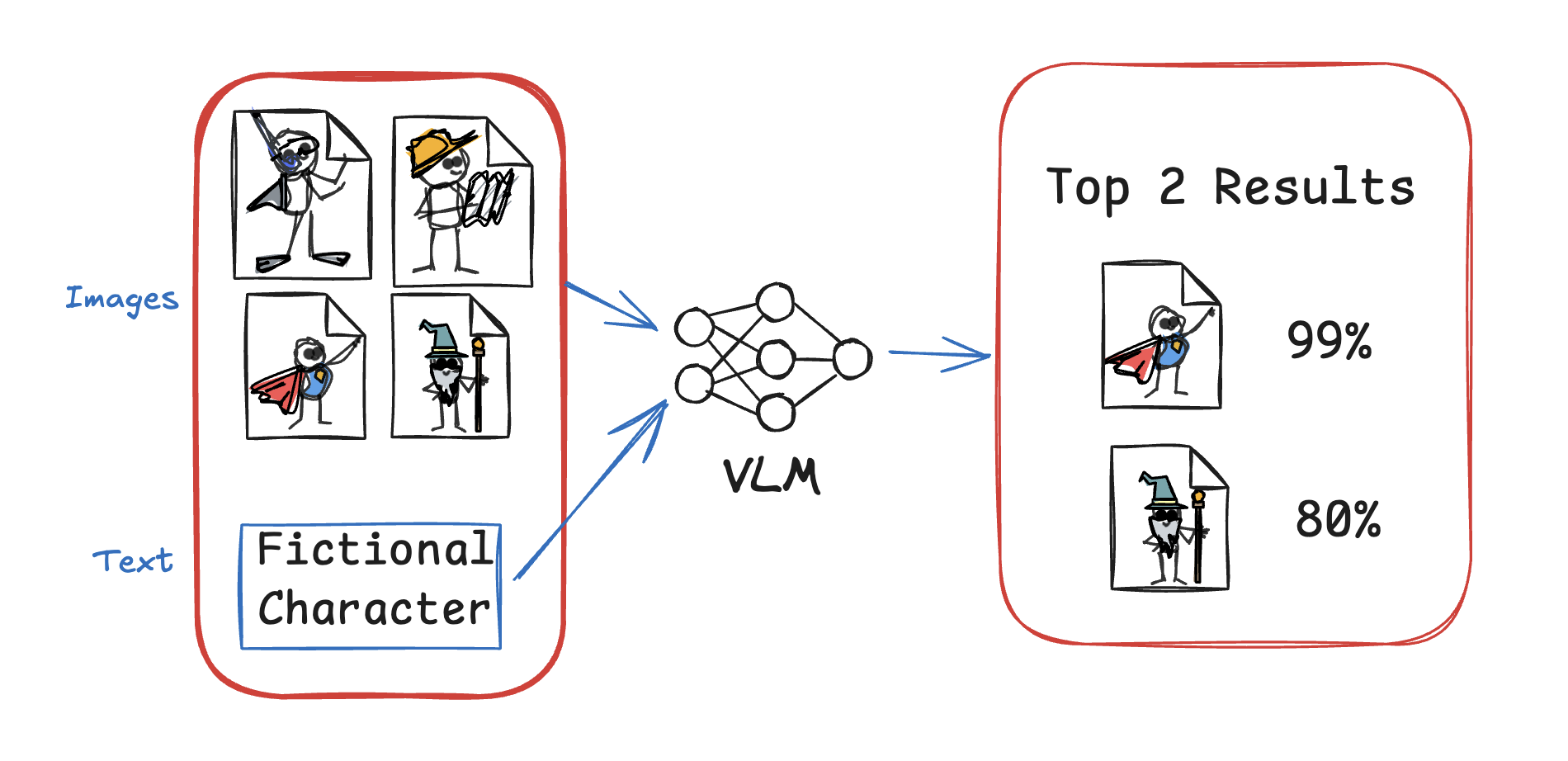
Zero Shot Image classification: The key distinction of this task from regular image classification is that it aims to categorize new classes without requiring additional training.
Synthetic data generation: Given the capabilities of LLMs and VLMs, we’ve developed numerous strategies to generate high-quality synthetic data by leveraging variations in image and text outputs from these models. Exploring these methods alone could be enough for an entire thesis! This is usually done to train more capable VLMs for other tasks
Variations of above mentioned applications can be used in medical, industrial, educational, finance, e-commerce and many other domains where there are large volumes of images and texts to work with. We have listed some examples below
- Automating Radiology Report Generation via Dense Image Captioning in Medical Diagnostics.
- Defect detection in manufacturing and automotive industries using zeroshot/fewshot image classification.
- Document retrieval in financial/legal domains
- Image Search in e-commerce can be turbo charged with VLMs by allowing the search queries to be as nuanced as possible.
- Summarizing and answering questions based on diagrams in education, research, legal and financial domains.
- Creating detailed descriptions of products and its specifications in e-commerce,
- Generic Chatbots that can answer user’s questions based on a images.
- Assisting Visually Impaired by describing their current scene and text in the scene. VLMs can provide relevant contextual information about the user’s environment, significantly improving their navigation and interaction with the world.
- Fraud detection in journalism, and finance industries by flagging suspicious articles.
History
Earliest VLMs were in mid 2010s. Two of the most successful attempts were Show and Tell and Visual Question Answering. The reason for the success of these two papers is also the fundamental concept what makes a VLM work – Facilitate effective communication between visual and textual representations, by adjusting image embeddings from a visual backbone to make them compatible with a text backbone. The field as such never really took off due to lack of large amount of data or good architectures.
The first promising model in 2020s was CLIP. It addressed the scarcity of training data by leveraging the vast number of images on the internet accompanied by captions and alt-text. Unlike traditional supervised models, which treat each image-caption pair as a single data point, CLIP utilized contrastive learning to transform the problem into a one-image-to-many-text comparison task. This approach effectively multiplied the number of data points to train on, enabling for a more effective training.
When CLIP was introduced, the transformer architecture had already demonstrated its versatility and reliability across various domains, solidifying its status as a go-to choice for researchers. However they were largely focussed only on text related tasks.️ ViT was the landmark paper that proved transformers can be also used for image tasks. The release of LLMs along with the promise of ViT has effectively paved way for the modern VLMs that we know.
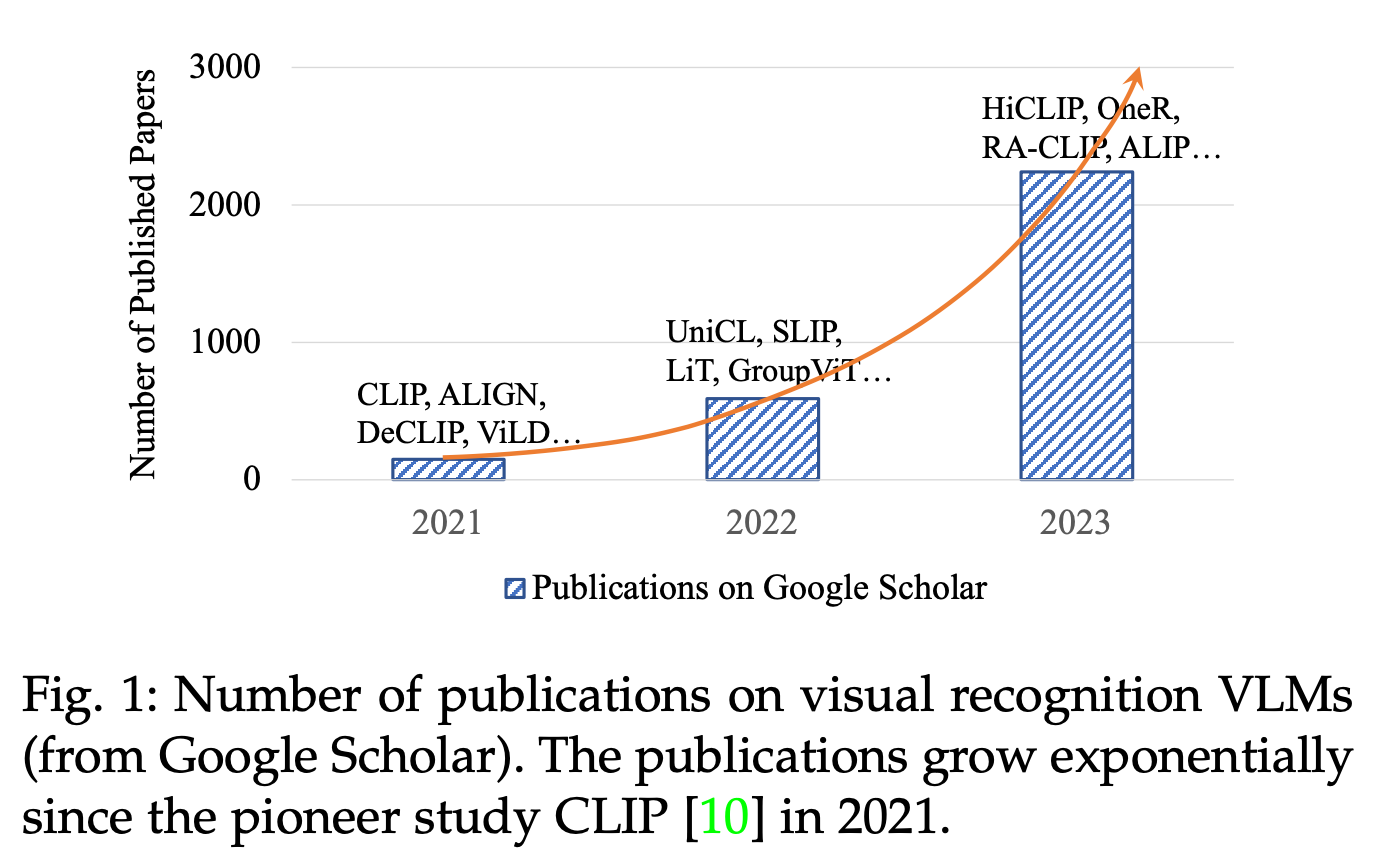
Here’s an image giving the number of VLM publications over the last few years
VLM Architectures
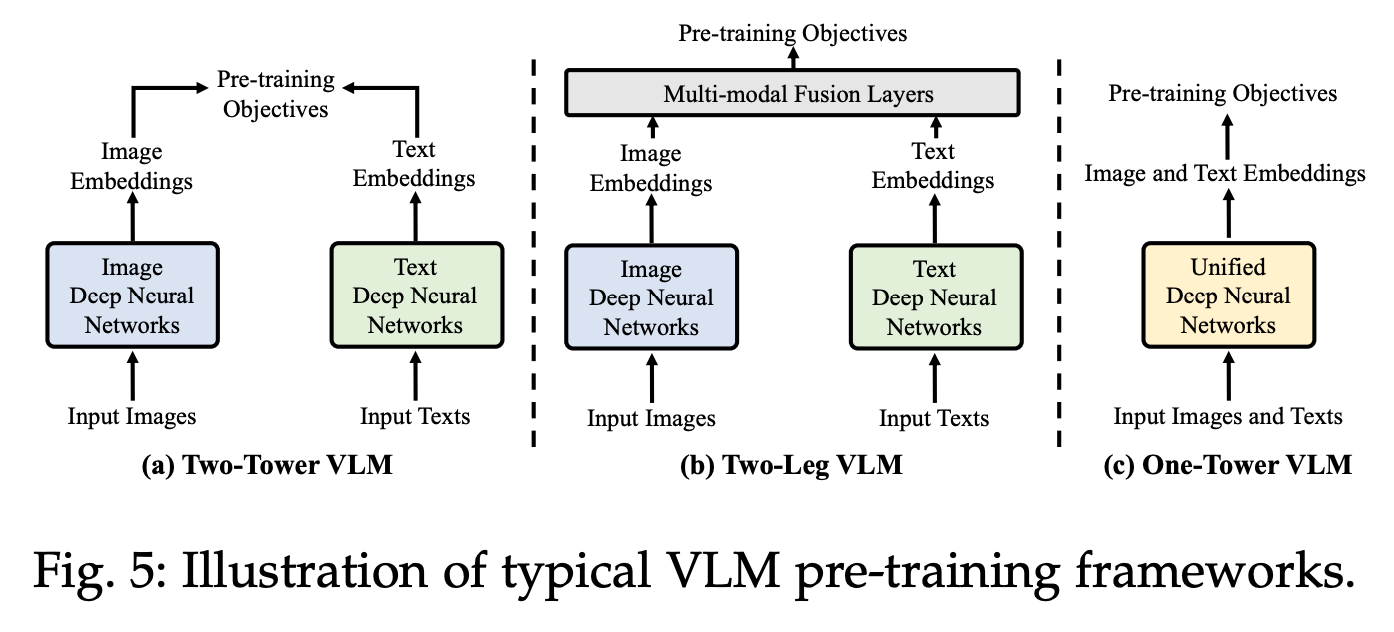
As discussed in the above section, one of the crucial aspect of a good VLM is how to bring image embeddings into the text embedding space. The architectures are typically of the three
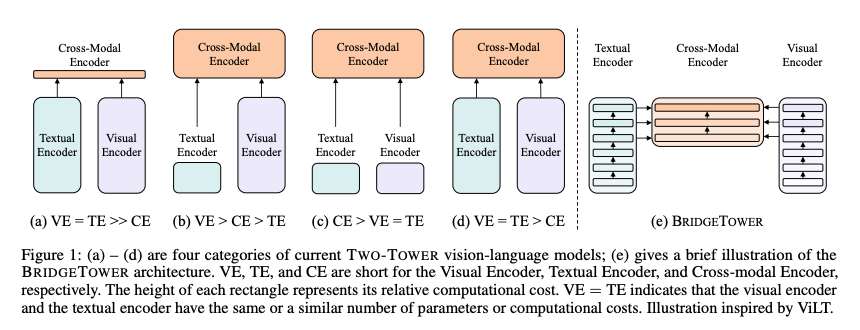
- Two-Tower VLM where the only connection between vision and text networks is at the final layer. CLIP is the classic example for this
- Two-Leg VLM where a single LLM takes text tokens along with tokens from vision encoder.
- Unified VLM where the backbone is attending to visual and textual inputs at the same time
Keep in mind that there is no hard taxonomy and there will be exceptions. With that, following are the common ways that have VLMs have shown promise.
- Shallow/Early Fusion
- Late Fusion
- Deep Fusion
Let’s discuss each one of them below.
Shallow/Early fusion
A common feature of the architectures in this section is that the connection between vision inputs and language occurs early in the process. Typically, this means the vision inputs are minimally transformed before entering the text domain, hence the term “shallow”. When a well-aligned vision encoder is established, it can effectively handle multiple image inputs, a capability that even sophisticated models often struggle to attain!
Let’s cover the two types of early fusion methods below.
Vision Encoder
This is one of the simplest. Ensure your vision encoder outputs are compatible with an LLMs inputs and just train the vision encoder while keeping the LLM frozen.
The architecture is essentially an LLM (specifically a decoder only transformer) with a branch for an image encoder. It’s fast to code, easy to understand and usually does not need writing any new layers.
These architectures have the same loss as LLMs (i.e., the quality of next token prediction)
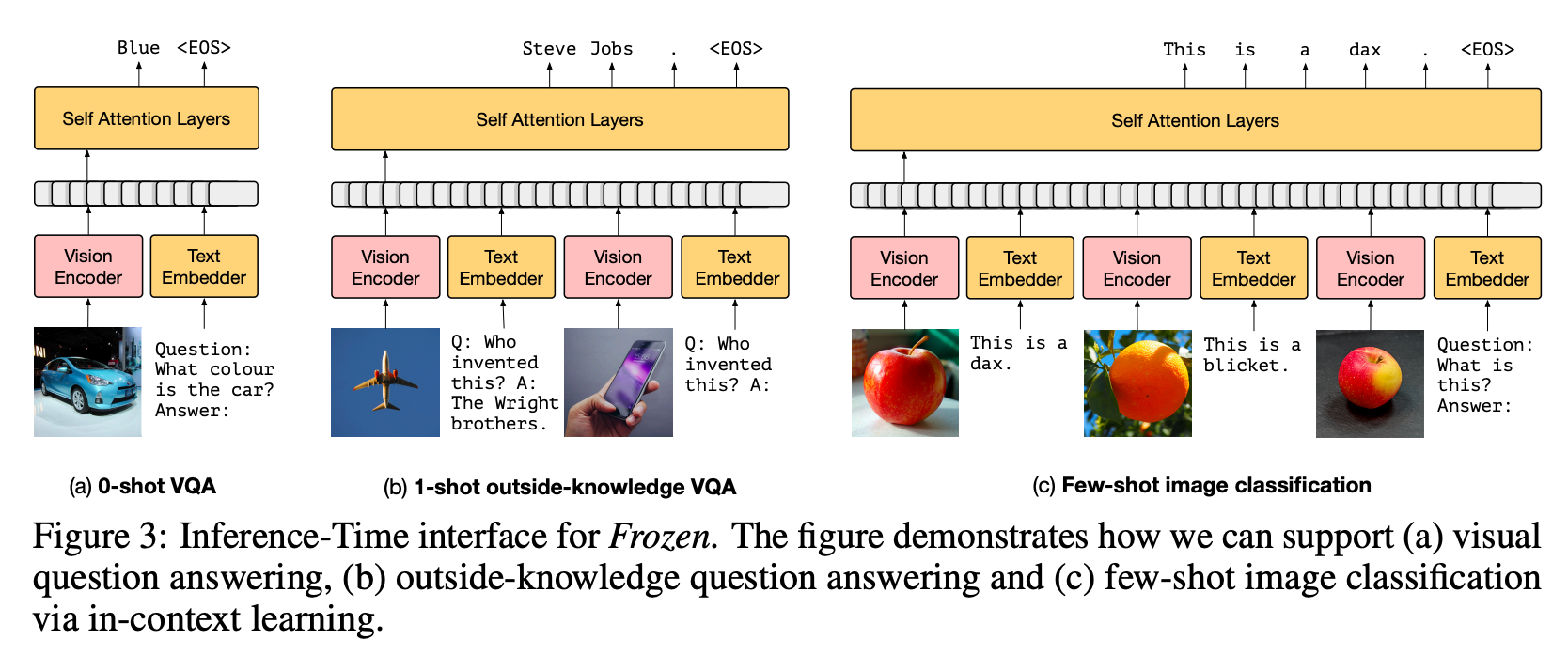
Frozen is an example of such implementation. In addition to training the vision encoder, the method employs prefix-tuning, which involves attaching a static token to all visual inputs. This setup enables the vision encoder to adjust itself based on the LLM’s response to the prefix.
Vision Projector/Adapter
Issue with using just a Vision Encoder is that it’s difficult to ensure the vision encoder’s outputs are compatible with the LLM, restricting the number of choices for Vision,LLM pairs. What is easier is to have an intermediate layer between Vision and LLM networks that makes this output from Vision compatible with LLM. With the projector inserted between them, any vision embeddings can be aligned for any LLM’s comprehension. This architecture offers increased/similar flexibility compared to training a vision encoder. One now has a choice to freeze both vision and LLM networks. also accelerating training due to the typically compact size of adapters.️
The projectors could be as simple as MLP, i.e, several linear layers interleaved with non-linear activation functions. Some such models are –
- LLaVa family of models – A deceptively simple architecture that gained prominence for its emphasis on training with high-quality synthetic data.
- Bunny – An architecture which supports several vision and language backbones. It uses LoRA to train LLMs component as well.
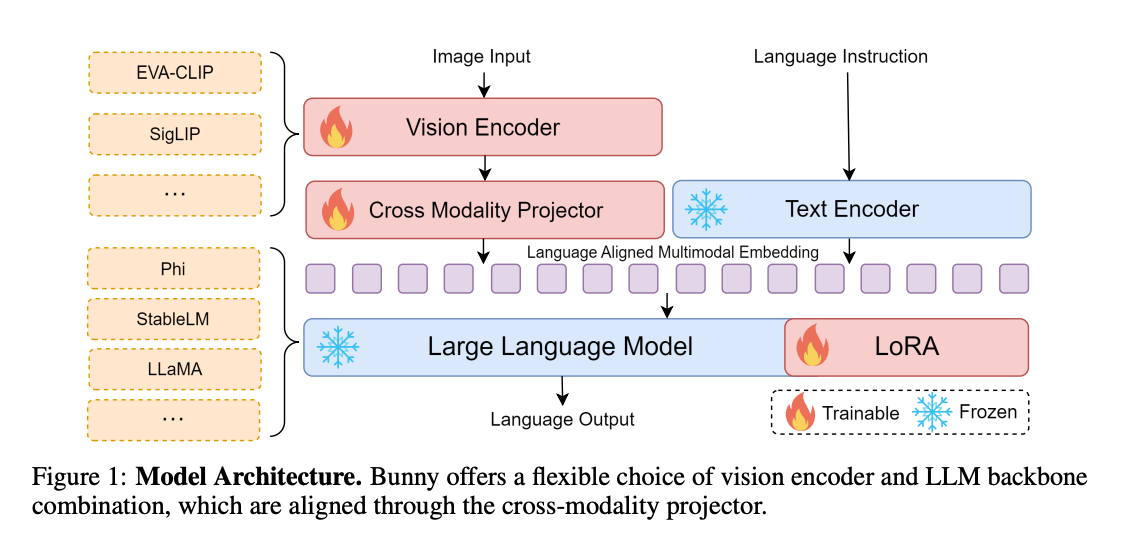
- MM1 uses mixture of experts models, a 3B-MoE using 64 experts that replaces a dense layer with a sparse layer in every-2 layers and a 7B-MoE using 32 experts that replaces a dense layer with a sparse layer in every-4 layers. By leveraging MoEs and curating the datasets, MM1 creates a strong family of models that are very efficient and accurate.
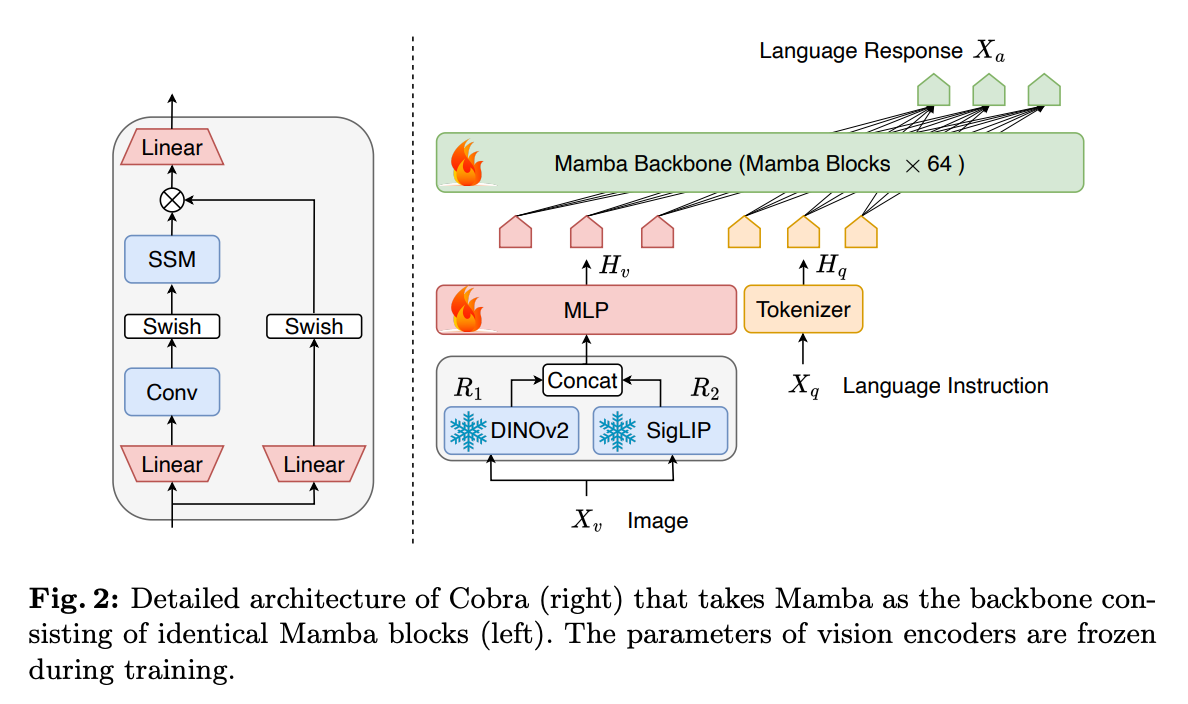
- Cobra – Uses the mamba architecture instead of the usual transformers
Projectors can also be specialized/complex as exemplified by the following architectures
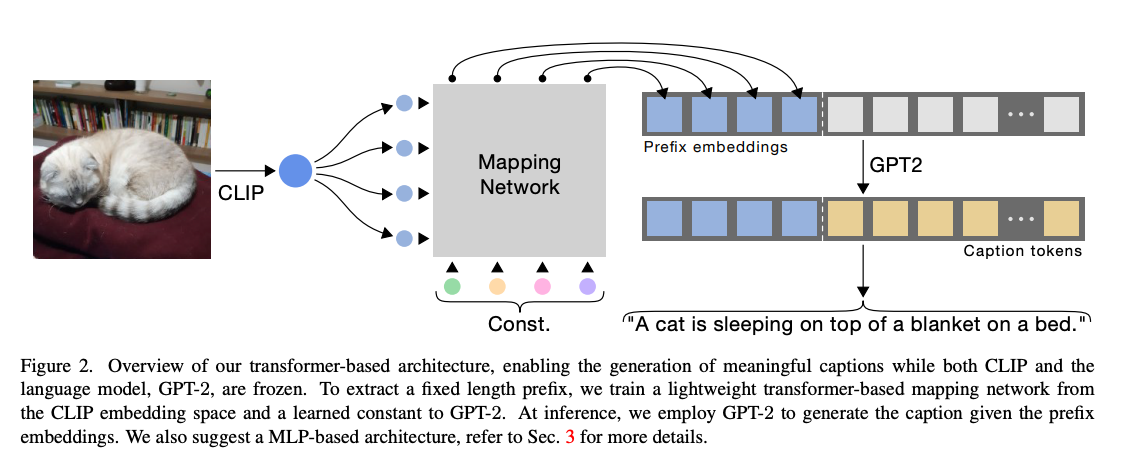
- CLIP Cap – Here the “vision encoder” is essentially a combination of CLIP’s vision encoder + a transformer encoder
- BLIP-2 utilizes a Q-Former as its adapter for stronger grounding of content with respect to images
- MobileVLMv2 uses a lightweight point-wise convolution based architecture as VLM with MobileLLama as (Small Language Model) SLM instead of an LLM, focussing on the speed of predictions.
One can use multiple projectors as well
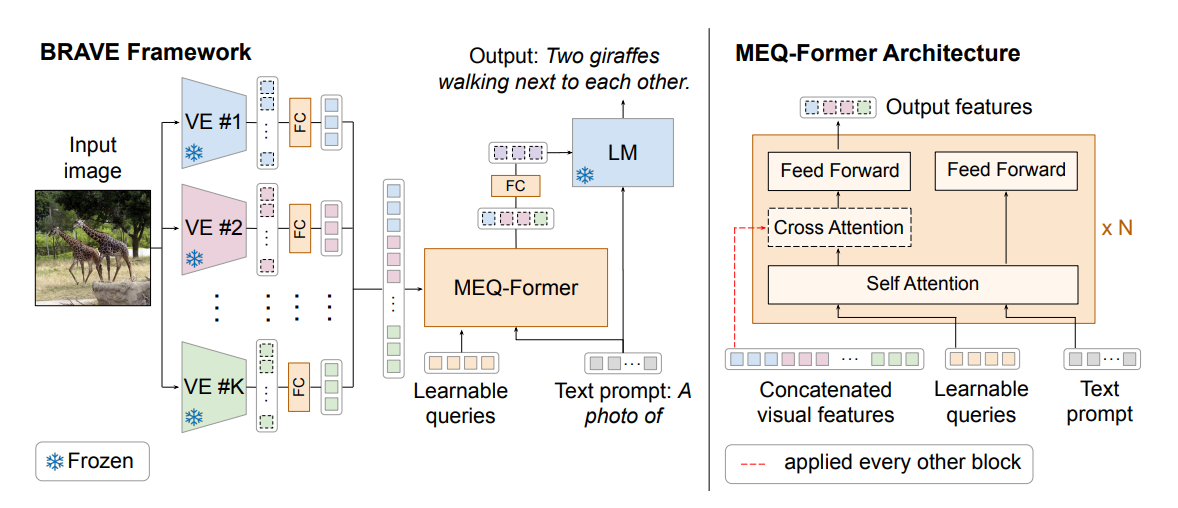
- BRAVE uses up to 5 vision encoders and an adapter called MEQ-Former that concatenates all the vision inputs into one before sending to the VLM
- Honeybee – uses two specialized vision encoders called C-Abstractor and D-Abstractor that focus on locality preservation and ability to output a flexible number of output tokens respectively
- DeepSeek VL also uses multiple encoders to preserve both high-level and low-level details in the image. However in this case LLM is also trained leading to deep fusion which we will cover in a subsequent section.
Late Fusion
These architectures have vision and text models fully disjoint. The only place where text and vision embeddings come together are during loss computation and this loss is typically contrastive loss.
- CLIP is the classic example where text and image are encoded separately and are compared via contrastive loss to adjust the encoders.
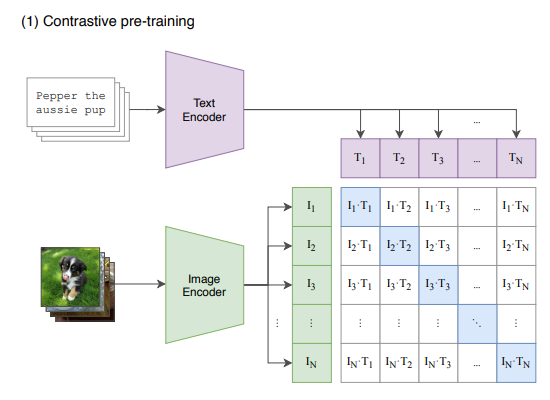
- JINA CLIP puts a twist on CLIP architecture by jointly optimizing CLIP Loss (i.e., image-text contrast) along with text-text contrast where text pairs are deemed similar if and only if they have similar semantic meaning. There’s a lesson to learn here, use more objective functions to make the alignment more accurate.
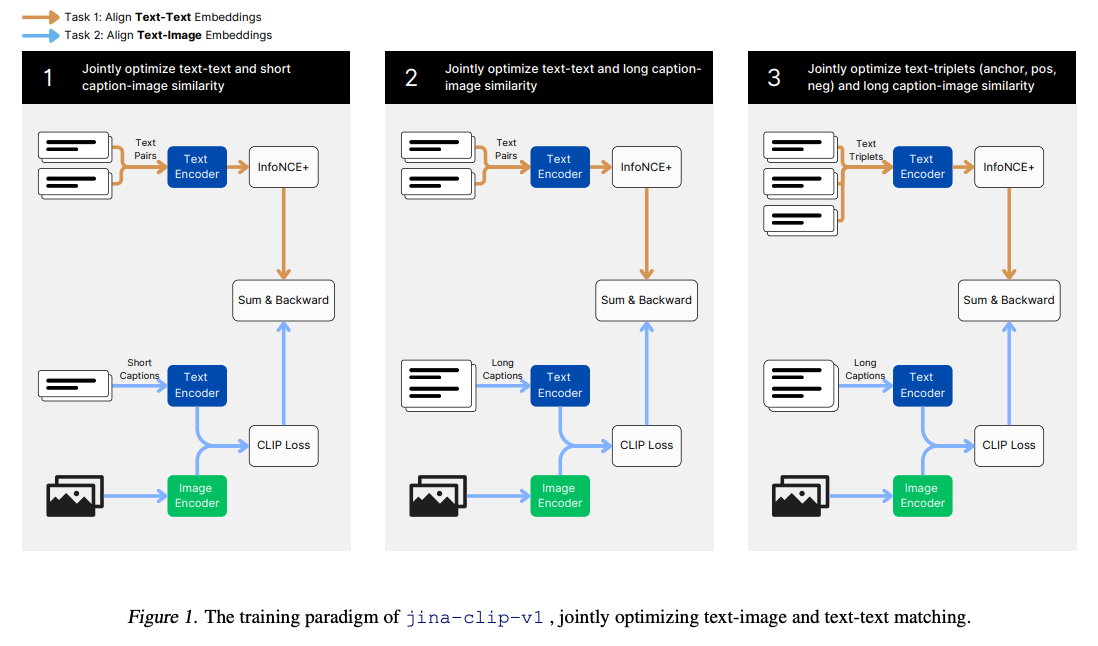
- ColPali is another example of late fusion, specifically trained for document retrieval. However, it differs slightly from CLIP in that it uses a vision encoder combined with a large language model (LLM) for vision embeddings, while relying solely on the LLM for text embeddings.
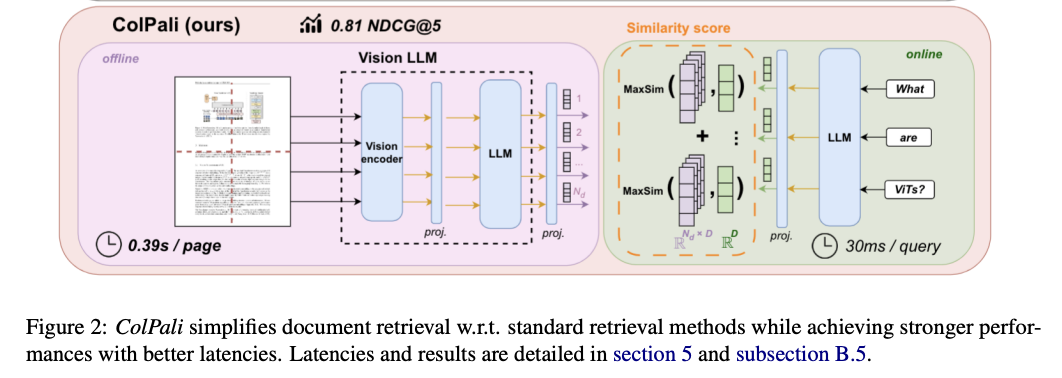
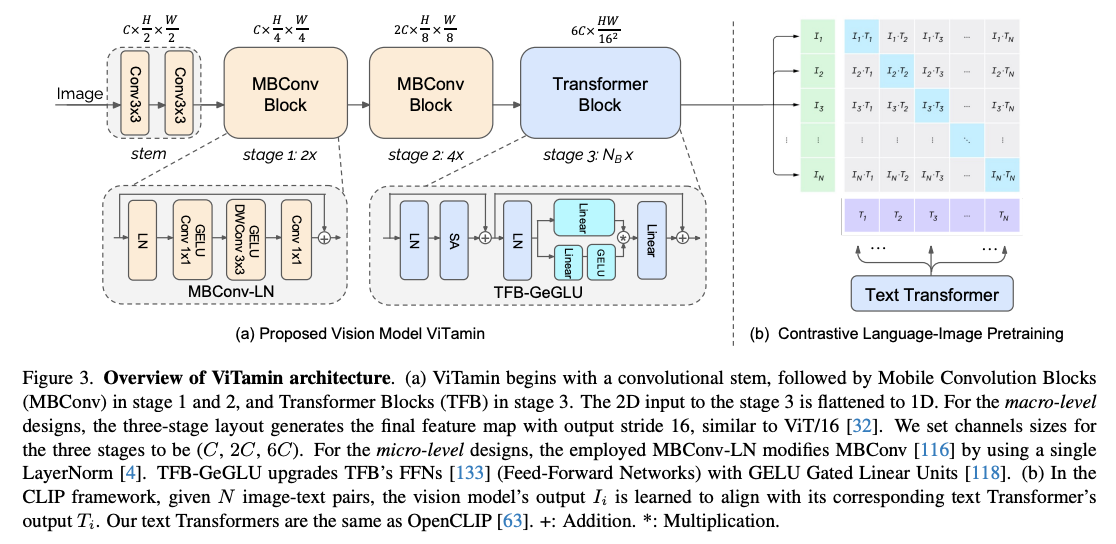
- ViTamin trains a vision tower that is a concatenation of Convolution and Transformer blocks to get the best of both worlds.
Deep Fusion
These architectures typically attend to image features in the deeper layers of the network allowing for richer cross modal knowledge transfer. Typically the training spans across all the modalities. These typically take more time to train but may offer better efficiency and accuracies. Sometimes the architectures are similar to Two-Leg VLMs with LLMs unfrozen
- CLIPPO is a variation of CLIP that uses a single encoder for both text and images.
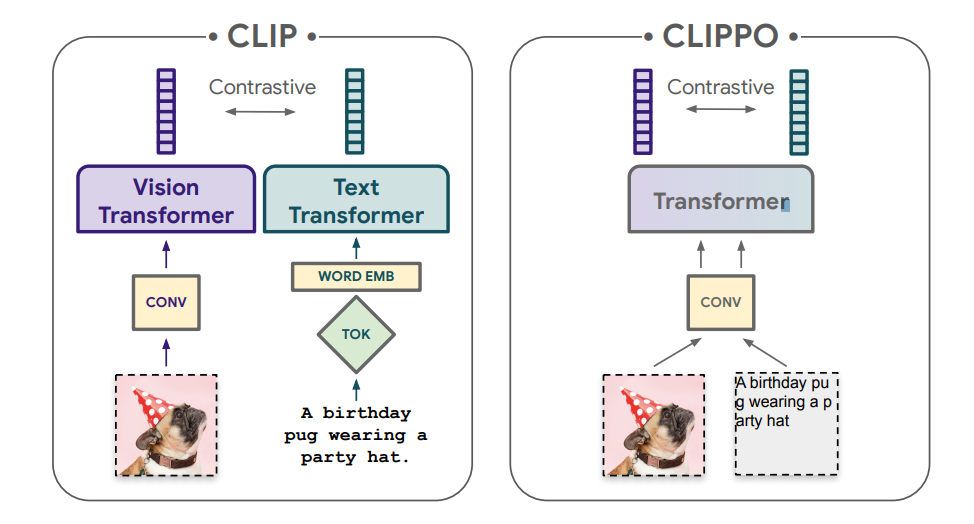
- Single-tower Transformer trains a single transformer from scratch enabling several VLM applications at once.
- DINO uses localization loss in addition to cross-modality transformer to perform zero-shot object detection, i.e, predict classes that were not present in training
- KOSMOS-2 treats bounding boxes as inputs/outputs along with text and image tokens baking object detection into the language model itself.
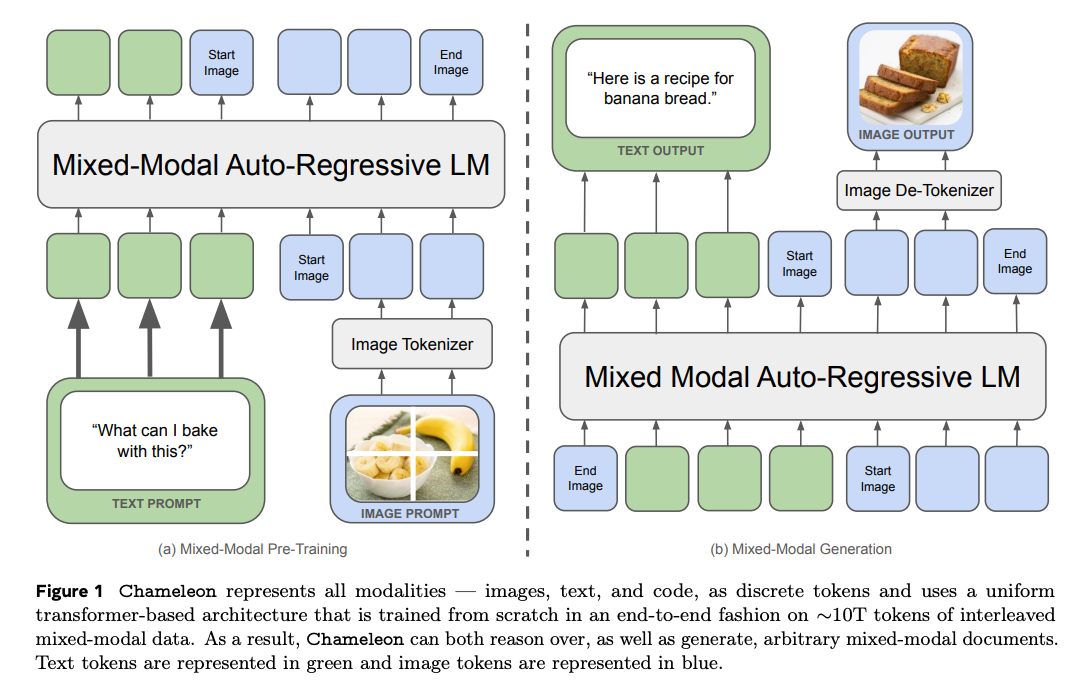
- Chameleon treats images natively as tokens by using a quantizer leading to text-vision agnostic architecture
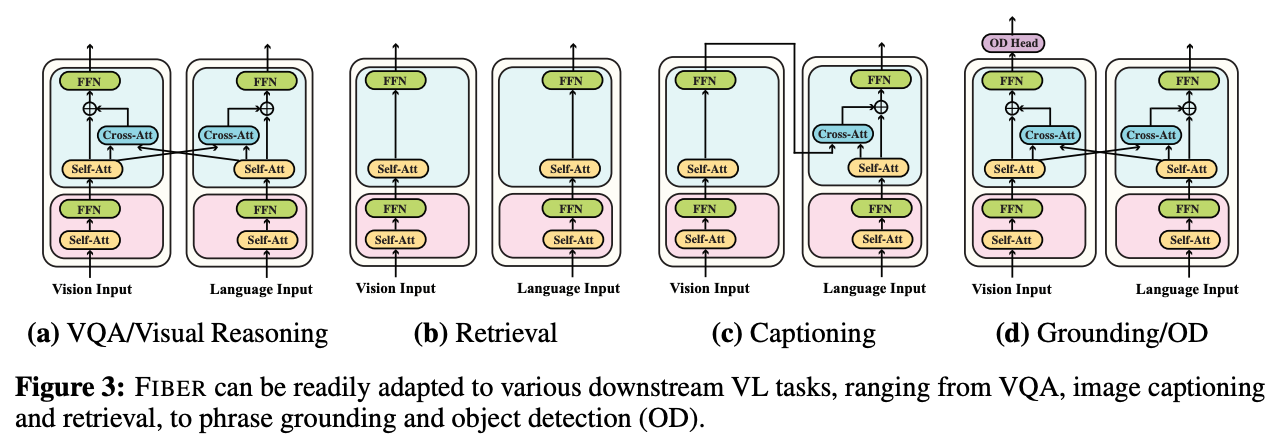
- FIBER uses dynamic cross attention modules by switching them on/off to perform different tasks.
- BridgeTower creates a separate cross-modal encoder with a “bridge-layer” to cross attend to both text on vision and vision on text tokens to encapsulate a richer interaction.
- Flamingo – The vision tokens are computed with a modified version of Resnet and from from a specialized layer called the Perceiver Resampler that is similar to DETR. It then uses dense fusion of vision with text by cross-attending vision tokens with language tokens using a Chinchilla LLM as the frozen backbone.
- MoE-LLaVa uses the mixture of experts technique to handle both vision and text tokens. It trains the model in two stages where only the FFNs are trained first and later the LLM
VLM Training
Training a VLM is a complex process that can involve multiple objectives, each tailored to improve performance on a variety of tasks. Below, we’ll explore
- Objectives – the common objectives used during training and pre-training of VLMs, and
- Training Best Practices – some of the best practices such as pre-training, fine-tuning, and instruction tuning, which help optimize these models for real-world applications
Objectives
There is a rich interaction between images and texts. Given the variety of architectures and tasks in VLM, there’s no single way to train the models. Let’s cover the common objectives used for training/pre-training of VLMs
- Contrastive Loss: This aims to adjust the embeddings so that the distance between matching pairs is minimized, while the distance between non-matching pairs is maximized. It’s particularly useful because it’s easy to obtain matching pairs, and on top of that every exponentially increasing the number of negative samples available for training.
- CLIP and all it’s variations are a classic example of training with contrastive loss where the match happens between embeddings of (image and text) pairs. InternVL, BLIP2, SigLIP are also some notable examples.
- SLIP demonstrates that pre-training of vision encoder with image-to-image contrastive loss even before pre-training CLIP, will help a great deal in improving the overall performance
- Florence modifies the contrastive loss by including the image label and hash of the text, calling it Unified-CL
- ColPali uses two contrastive losses, one for image-text and one for text-text.
- Generative Loss – This class of losses treat the VLM as a generator and is usually used for zero-shot and language generation tasks.
- Language Modeling Loss – This is typically the loss you would use when training the VLM for next token prediction. Chameleon puts a twist on this loss by using it to predict image tokens as well.
- Masked Language Modeling – You train a text language encoder to predict intermediate token given the surrounding context FIBER are just a couple of examples among hundreds.
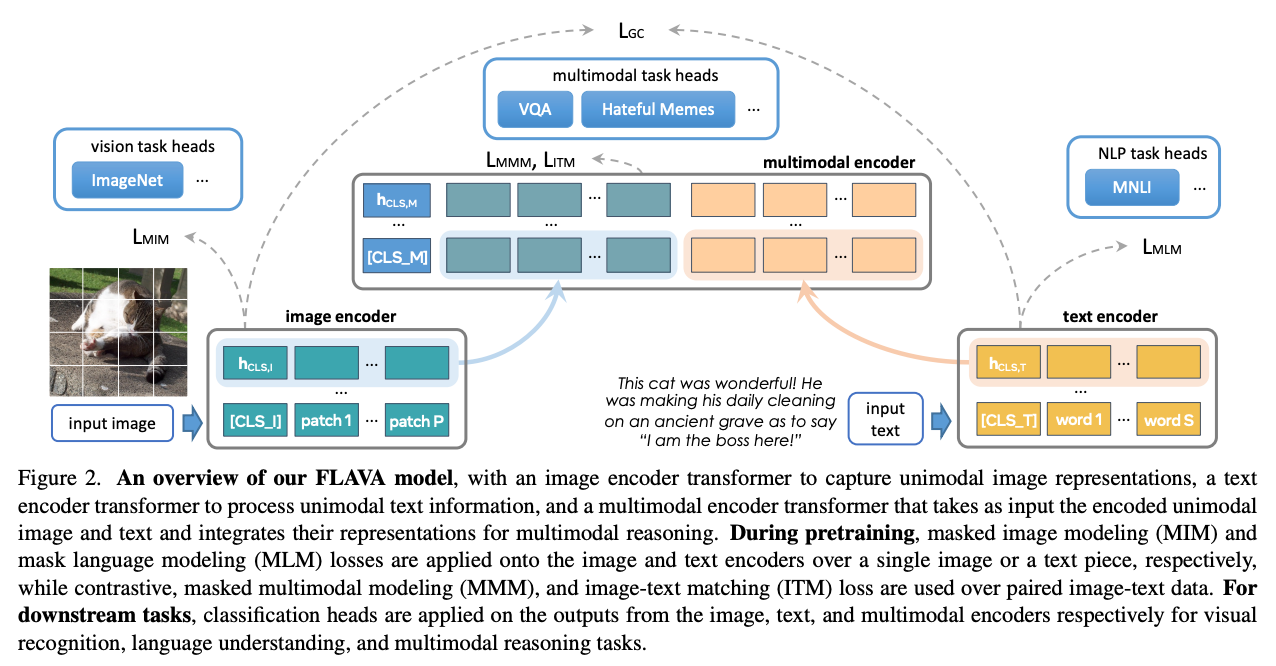
- Masked Image Modeling – You train a transformer to predict image tokens by masking them during the input, forcing the model to learn with limited data. LayoutLM, and usage of MAE by SegCLIP, BeiT by FLAVA are examples of this loss
- Masked Image+Text Modelling – As the name suggests, one can use a two-leg architecture to simultaneously mask both image and text tokens to ensure the network learns as much cross-domain interactions as possible with limited data. FLAVA is one such example.
- Niche Cross Modality Alignments – Note that one can always come up with good objective functions given the richness of the landscape. For example –
- BLIP2 created an Image-grounded Text Generation loss,
- LayoutLM uses something called Word Patch Alignment to roughly identify where a word is present in the document
Training Best Practices
Training VLMs effectively requires more than just choosing the right objectives—it also involves following established best practices to ensure optimal performance. In this section, we’ll dive into key practices such as pre-training on large datasets, fine-tuning for specialized tasks, instruction tuning for chatbot capabilities, and using techniques like LoRAs to efficiently train large language models. Additionally, we’ll cover strategies to handle complex visual inputs, such as multiple resolutions and adaptive image cropping.
Pre-training
Here, only the adapter/projector layer is trained with as much data as possible (typically goes into millions of image-text pairs). The goal is to align image encoder with text decoder and the focus is very much on the quantity of the data. Typically, this task is unsupervised in nature and uses one of contrastive loss or the next token prediction loss while adjusting the input text prompt to make sure that the image context is well understood by the language model.
Fine tuning
Depending on the architecture some, or all of the adapter, text, vision components are unfrozen from step 1 and trained. The training is going to be very slow because of the large number of trainable parameters. Due to this, the number of data points is reduced to a fraction of data that was used in first step and it is ensured that every data point is of highest quality.
Instruction Tuning
This could be the second/third training step depending on the implementation. Here the data is curated to be in the form of instructions specifically to make a model that can be used as a chatbot. Usually the available data is converted into instruction format using an LLM. LLaVa and Vision-Flan are a couple of examples

Using LoRAs
As discussed, the second stage of training might involve unfreezing LLMs. This is a very costly affair since LLMs are massive. An efficient alternative to training LLMs without this drawback is to utilize Low Rank Adaptation that inserts small layers in-between the LLM layers ensuring that while LLM is getting adjusted overall, only a fraction of the size of LLM is being trained.
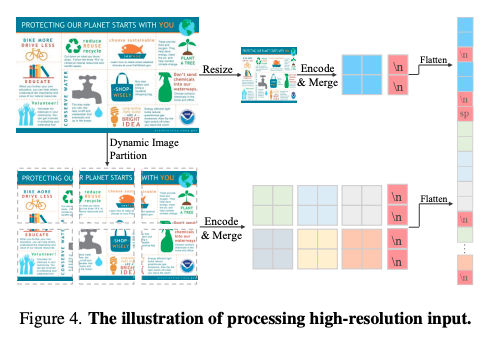
Multiple Resolutions
VLMs face challenges when input images have too much dense information such as in tasks with object/crowd counting and word recognition in OCR. Here are some papers that try to address it:
- The easiest way is to simply resize image to several resolutions and take all the crops from each resolution feed them to the vision encoder and feed them as tokens to LLM, this was proposed in Scaling on Scales and is used by Bunny family of models, one of the top performers across all tasks.
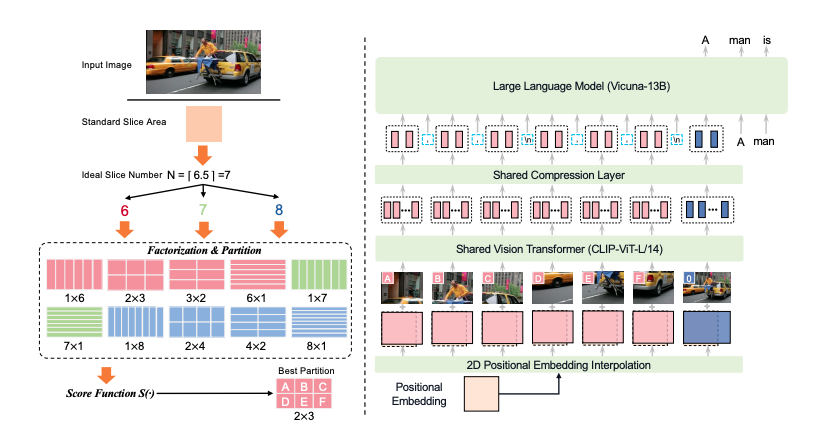
- LLaVA-UHD tries to find the best way to slice the image into grids before feeding to the vision encoder.
Training Datasets
Now that we know what are the best practices, let’s digress into some of the available datasets for both training and fine-tuning.
There are broadly two categories of datasets for VLMs. One category of datasets focus on the volume and are primarily for ensuring a good amount of unsupervised pre-training is possible. The second category of datasets emphasizes specializations that enhance niche or application-specific capabilities, such as being domain-specific, instruction-oriented, or enriched with additional modalities like bounding boxes.
Below are some of the datasets and highlight their qualities that have elevated VLMs to where they are.
| Dataset | Number of Image Text Pairs | Description |
|---|---|---|
| WebLI (2022) | 12B | One of the biggest datasets built on web crawled images in 109 languages. Unfortunately this is not a public dataset |
| ai/blog/laion-5b/”>LAION-5B (2022) | 5.5B | A collection image and alt-text pairs over the internet. One of largest publicly available dataset that is used by a lot of implementations to pretrain VLMs from scratch. |
| COYO (2022) | 700M | Another giant that filters uninformative pairs through the image and text level filtering process |
| ai/blog/laion-coco/”>LAION-COCO (2022) | 600M | A subset of LAION-5B with synthetic captions generated since alt-texts may not be always accurate |
| Obelics (2023) | 141M | Dataset is in chat format, i.e., a coversation with images and texts. Best for instruction pretraining and fine-tuning |
| MMC4 (Interleaved) (2023) | 101M | Similar chat format as above. Uses a linear assignment algorithm to place images into longer bodies of text using CLIP features |
| Yahoo Flickr Creative Commons 100 Million (YFCC100M) (2016) | 100M | One of the earliest large scale datasets |
| Wikipedia-based Image Text (2021) | 37M | Unique for its association of encyclopedic knowledge with images |
| Conceptual Captions (CC12M) (2021) | 12M | Focusses on a larger and diverse set of concepts as opposed to other datasets where generally cover real world incidents/objects |
| Red Caps (2021) | 12M | Collected from Reddit, this dataset’s captions reflect real-world, user-generated content across various categories, adding authenticity and variability compared to more curated datasets |
| Visual Genome (2017) | 5.4M | Has detailed annotations, including object detection, relationships, and attributes within scenes, making it ideal for scene understanding and dense captioning tasks |
| ai.google.com/research/ConceptualCaptions/download”>Conceptual Captions (CC3M) (2018) | 3.3M | Not a subset of CC12M, this is more appropriate for fine-tuning |
| Bunny-pretrain-LAION-2M (2024) | 2M | Emphasizes on the quality of visual-text alignment |
| ShareGPT4V-PT (2024) | 1.2M | Derived from the ShareGPT platform the captions were generated by a model which was trained on GPT4V captions |
| SBU Caption (2011) | 1M | Sourced from Flickr, this dataset is useful for casual, everyday image-text relationships |
| COCO Caption (2016) | 1M | Five independent human generated captions are be provided for each image |
| Localized Narratives (2020) | 870k | This dataset contains localized object-level descriptions, making it suitable for tasks like image grounding |
| ALLaVA-Caption-4V (2024) | 715k | Captions were generated by GPT4V, this dataset focuesses on image captioning and visual reasoning |
| LLava-1.5-PT (2024) | 558k | Yet another dataset that was genereated by calling GPT4 on images. The focus is on quality prompts for visual reasoning, dense captioning |
| DocVQA (2021) | 50k | Document-based VQA dataset where the questions focus on document content, making it crucial for information extraction tasks in the financial, legal, or administrative domains |
Evaluation Benchmarks
In this section, let’s explore key benchmarks and state-of-the-art (SOTA) models for evaluating vision-language models (VLMs) across a wide range of tasks. From visual question answering to document-specific challenges, these benchmarks assess models’ abilities in perception, reasoning, and knowledge extraction. We’ll highlight popular datasets like MMMU, MME, and Math-Vista, designed to prevent biases and ensure comprehensive testing. Additionally, we’ll discuss the leading open-source models like LLaVA and InternVL2, emphasizing what led to their success across various benchmarks.
Visual Question Answering
MMMU – 11.5k documents – 2024
Massive Multi-discipline Multimodal Understanding and Reasoning (MMMU) benchmark is one of the most popular benchmarks for evaluating VLMs. It focusses on a variety of domains to ensure the good VLMs tested are generalized.
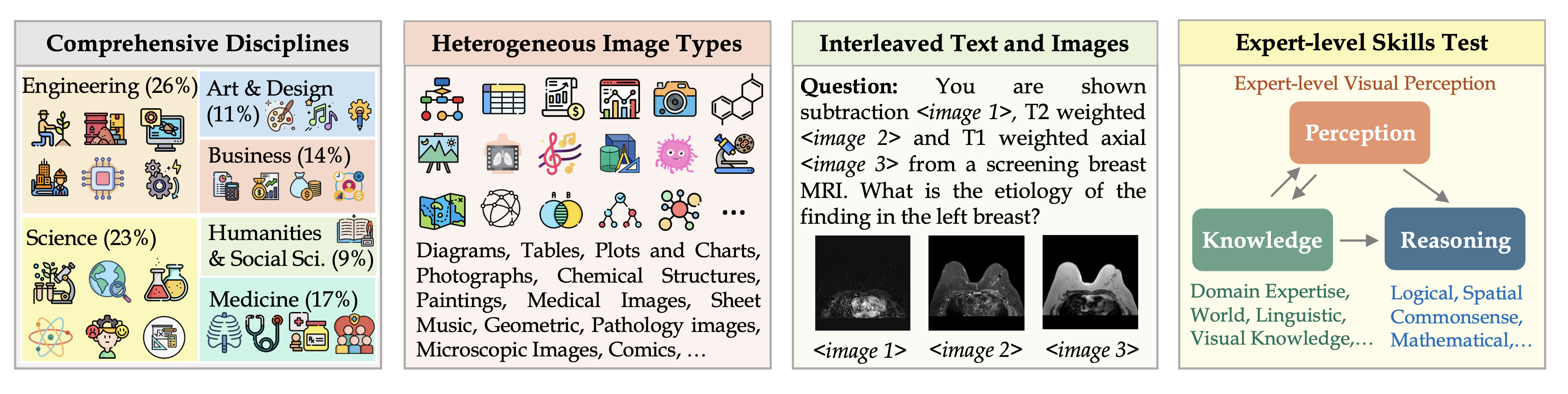
Perception, knowledge, and reasoning are the three skills that are being assessed by this benchmark. The evaluation is a conducted under a zero-shot setting to generate accurate answers without fine-tuning or few-shot demonstrations on our benchmark.

MMMU-PRO is a new version of MMMU that improves on MMMU by adding more challenging questions and filtering out some data points that could have be solved by text input alone.
MME – < 1000 images – 2024
This dataset focusses on quality by handpicking images and creating annotations. None of the examples are availble any where over the internet and this is done to ensure the VLMs are not accidentally trained on any of them.
There are 14 subtasks in the benchmark with around 50 images in each task. Every task has a yes/no answers only. Some of the example tasks are existence of objects, perception of famous objects/people, text translation etc. Every image further has 2 questions one framed positively expected to get a “YES” from VLM and one frame negatively to get a “NO” from VLM. Every subtask is it’s own benchmark. There are two sub-aggregate benchmarks one for cognition and one for perception which are sums of respective subtask-group’s accuracies. The final benchmark is the sum of all the benchmarks.
An example set of questions for Cognition (reasoning) task in the dataset

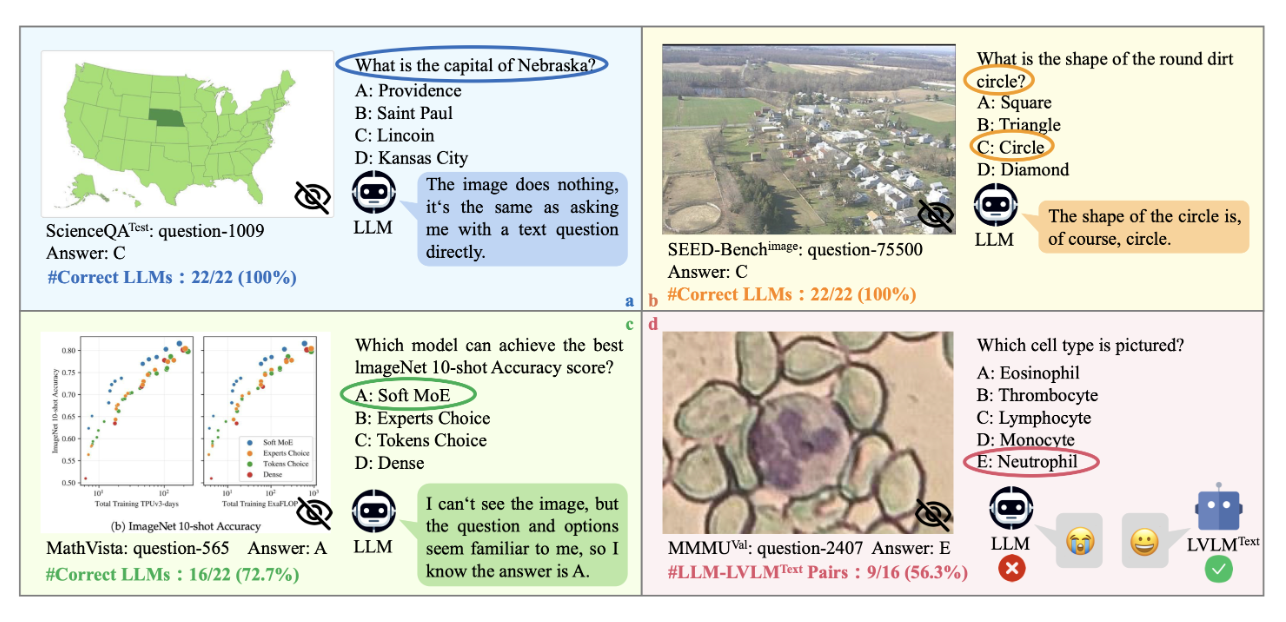
MMStar – 1500 – 2024
This dataset is a subset of 6 VQA datasets that have been thoroughly filtered for high quality ensuring the following –
- None of the samples are answered by LLMs using only text-based world knowledge.
- In no instances is the question itself found to contain the answer, making images superfluous.
- None of the samples are recalled directly from LLMs’ training corpora with the textual questions and answers.
Much like MME, this is a dataset that focusses on quality over quantity.
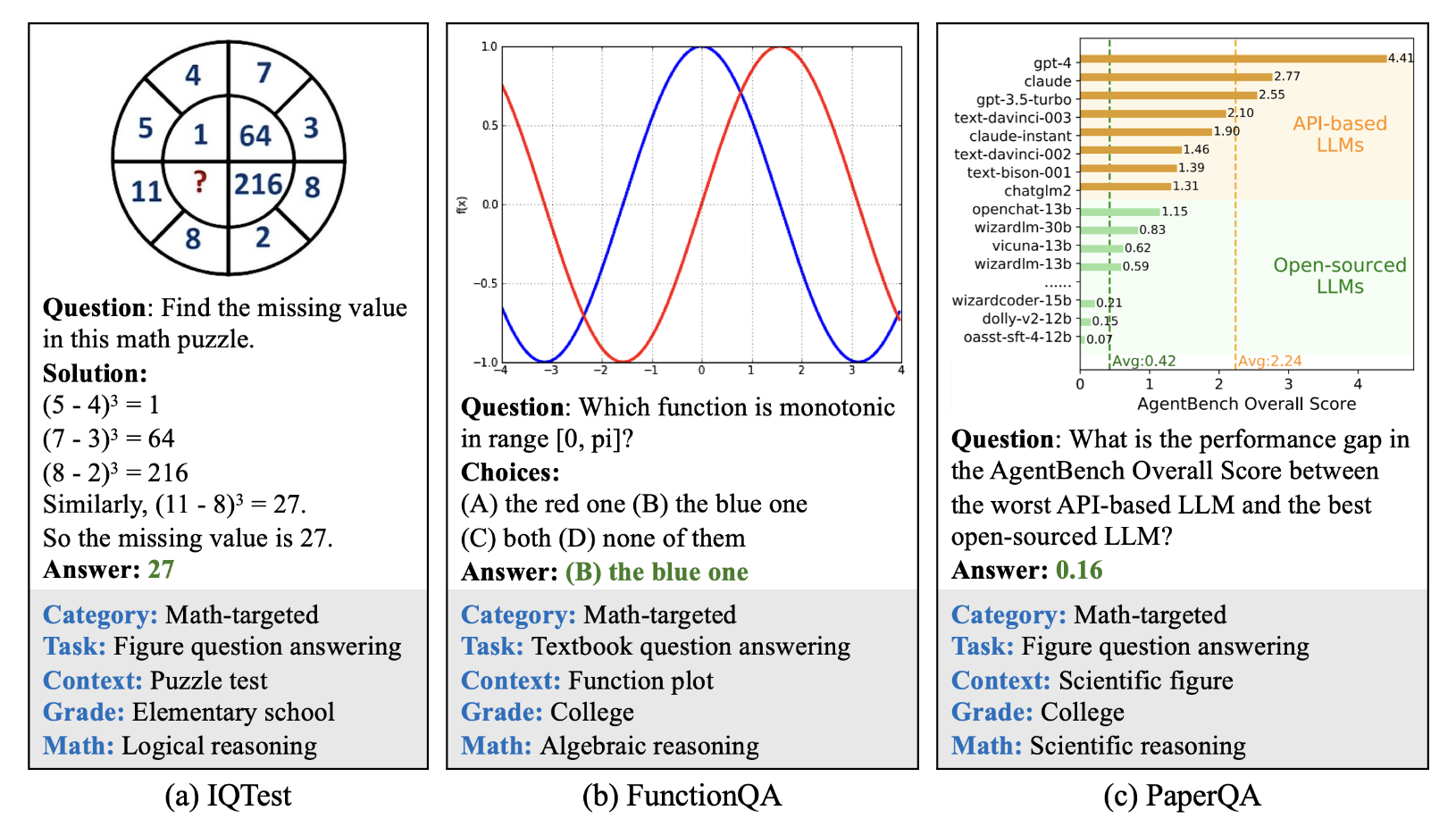
Math-Vista – 6.1k documents – 2024
Collected and curated from over 31 difference sources, this benchmark has questions specific to mathematics across several reasoning types, task types, grade levels and contexts.
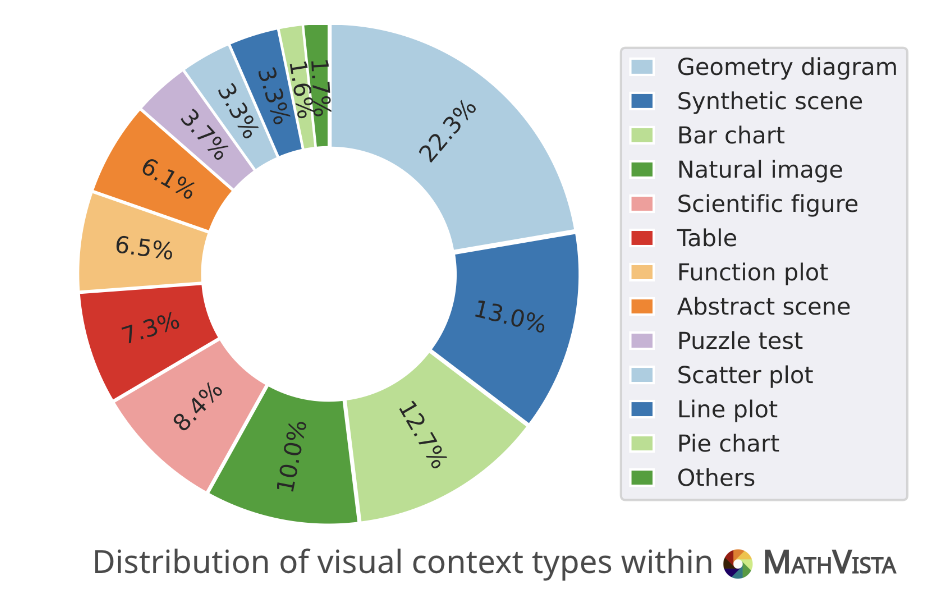
The answers are one of multiple choices or numeric making it easy to evaluate.
MathVerse is a very similar but different dataset that covers more specific 2D, 3D geometry and analytical functions as subjects.
AI2D – 15k – 2016
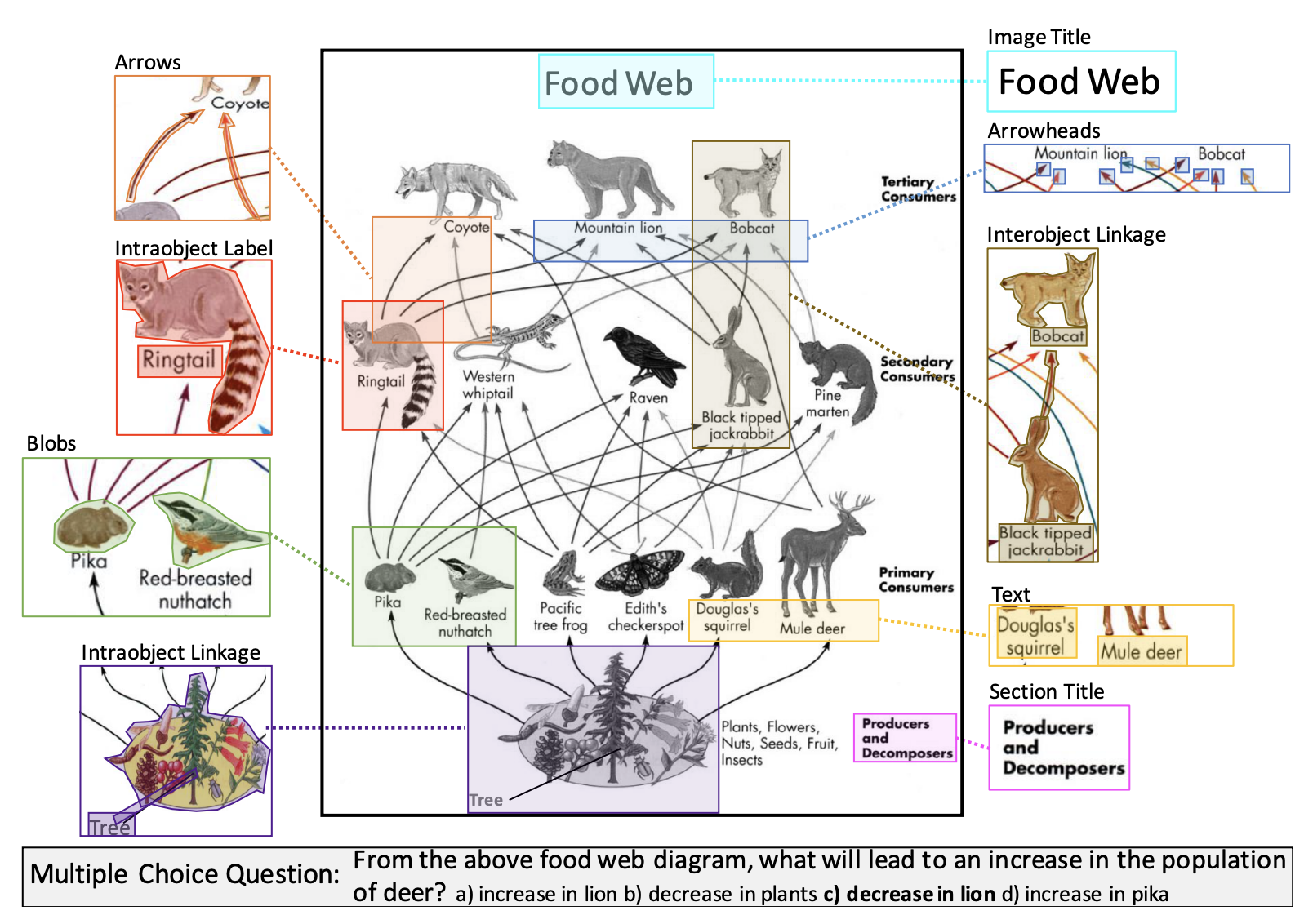
A dataset that is very focussed on science diagrams, this benchmark validates the understanding of several high level concepts of a VLM. One needs to not only parse the available pictures but also their relative positions, the arrows connecting them and finally the text that is presented for each and every component. This is a dataset with 5000 grade school science diagrams covering over 150000 rich annotations, their ground truth syntactic parses, and more than 15000 corresponding multiple choice questions.
ScienceQA – 21k – 2022
Yet another domain specific dataset that tests the “Chain of Thought” (COT) paradigm by evaluating elaborate explanations along with multiple choice answers. It also evaluates the chat like capability by sending multiple texts and images to the VLM.
MM-Vet v2 – 200 questions – 2024
One of the most popular benchmarks and the smallest, this dataset asseses recognition, knowledge, spatial awareness, language generation, OCR, and math capabilities of a model by evaluating both single-image-single-text as well as chat-like scenarios. Once again InternVL has one of the highest scores in open source options.
VisDial – 120k images, 1.2M data points – 2020
Derived from COCO, this is a dataset that tries to evaluates a VLM Chatbot’s response to a series of image + text inputs followed by a question.
LLaVA-NeXT-Interleave – 17k – 2024
This benchmark evaluates how capable a models is based on several input images. The bench combines 9 new and 13 existing datasets including Muir-Bench and ReMI
Other datasets
Here are a few more visual question answering benchmarks which have simple (typically one phrase/word) questions and answers and have specific area of focus
- SEED (19k, 2023) – Multiple Choice questions of both images and videos
- VQA (2M, 2015) – One of the first datasets. Covers a wide range of day to day scenarios
- GQA (22M, 2019) – has compositional question answering, i.e., questions that relate multiple objects in an image.
- VisWiz (8k, 2020) – is a dataset that was generated by blind people who each took an image and recorded a spoken question about it, together with 10 crowdsourced answers per visual question.
Other Vision Benchmarks
Note that any vision task is a VLM task simply by adding the requirement in the form of a text.
- For example any image classification dataset can be used for zero-shot image classification by adding the text prompt, “idenity the salient object in the image” task. ImageNet is still one of the best and OG dataset for this purpose and almost all the VLMs have decent performance in this task.
- POPE is a curious dataset that exemplifies how one can create complexity using simple building blocks. It has questions posed as presence/abscence of objects in an image, by first using an object detection model to find objects for presence and using negation to create a negative/abscence sample set. This is also used for identifying if the VLM is hallucinating.
VLM Benchmarks specific to Documents
- Document classification – RVL-CDIP is a 16 class dataset with classes such as Letter, Email, Form, Invoice etc. Docformer is a good baseline.
- Semantic Entity Recognition – FunSD, EPHOIE, CORD are all variations on printed documents wich evaluate models on f1 score of their respective classes. LiLT is a strong baseline.
- Multi-language Semantic Entity Recognition – Similar to above point except that the documents are in more than one language. XFUND is a dataset with documents in 7 languages and approximately 100k images. LiLT is again among the top performers as it uses an LLM.
- OCRBench – is a well rounded dataset of questions and answers for images containing texts be it natural scenes or documents. It has overall 5 tasks spanning from OCR to VQA in varying scene and task complexities. InternVL2 is a strong baseline for this benchmark, proving all round performance
- DocVQA – is a dataset that is essentialy VQA for documents, with usually one sentence/phrase questions and one word answers.
- ViDoRe – focusses exclusively on document retrieval encompassing documents with texts, figures, infographics, tables in medical, business, scientific, administrative domains in both English and French. ColPali is a good out of the box model for this benchmark and task
State of the Art
It’s important for the reader to know that across the dozens of papers the author went through, one common observation was that the GPT4 family of models from OpenAI and the Gemini family of models from Google seem to be the top performers with one or two exceptions here and there. Open source models are still catching up to proprietary models. This can be attributed to more focussed research, more human hours and more proprietary data at the disposal in private scenarios where one can generate, modify and annotate large volumes of data. That said, let’s list the best open source models and point out what were the criteria that led to their successes.
Firstly, the LLaVA family of models are a close second best across tasks. LLaVa-OneVision is their latest iteration that is currently the leader in MathVista demonstrating high language and logic comprehension.
The MM1 set of models also perform high on a lot of benchmarks mainly due to its dataset curation and the use of mixture of experts in its decoders.
The Overall best performers in terms of majority of the tasks were InternVL2, InternVL2-8B and Bunny-3B respectively for large, medium and tiny models among the benchmarks.
A couple of things common across all of these these models is
- the usage of curated data for training, and
- image inputs are processed in high resolution or through multiple image encoders to ensure that details at any level of granularity are accurately captured.
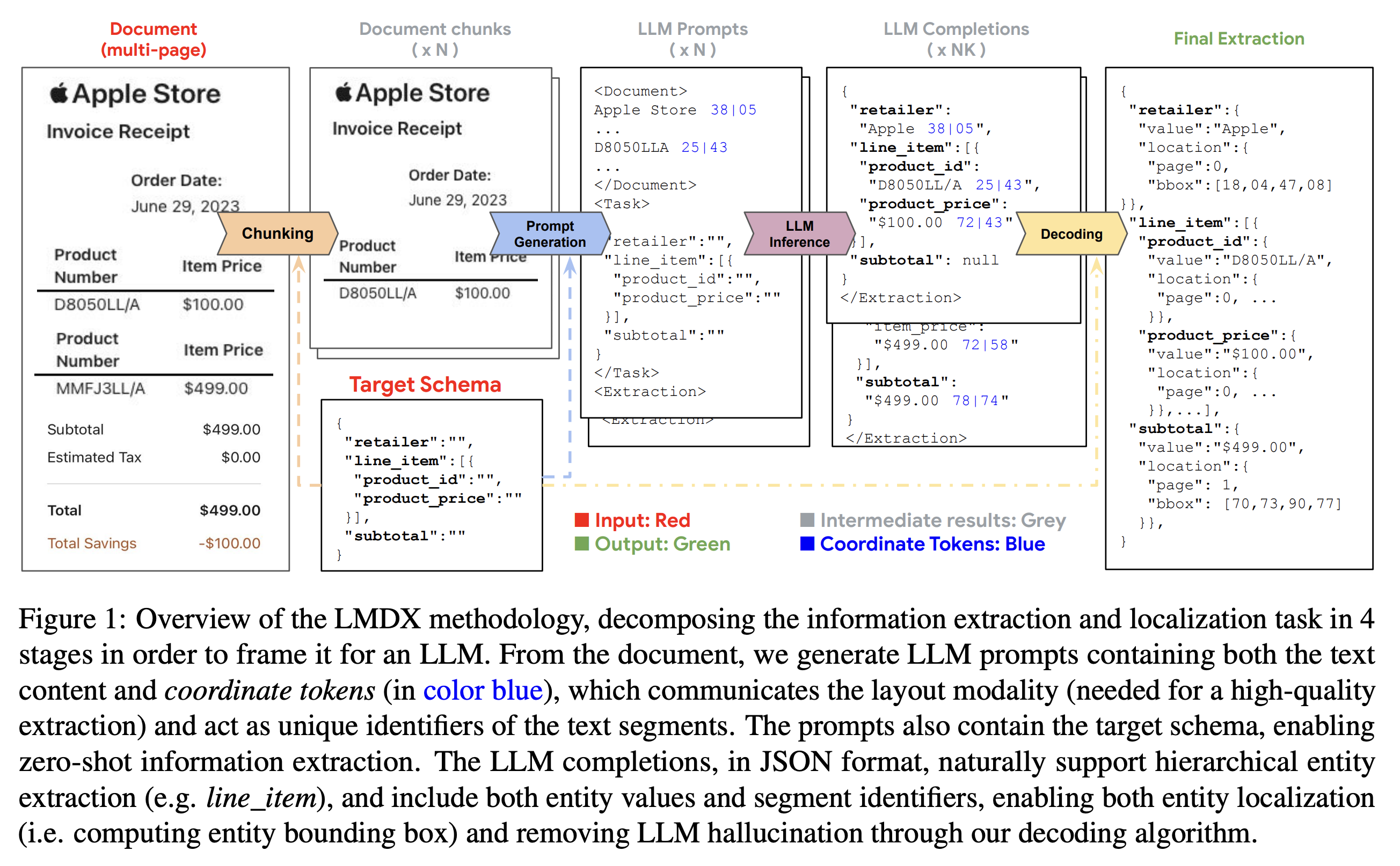
One of the simplest ways to extract information from documents is to first use an OCR to convert the image into a layout aware text and feed it to an LLM along with the desired information. This completely by passes a need for VLM by using OCR as a proxy for image encoder.
LMDX is one such example which converts OCR text into a layout aware text before sending to LLM.
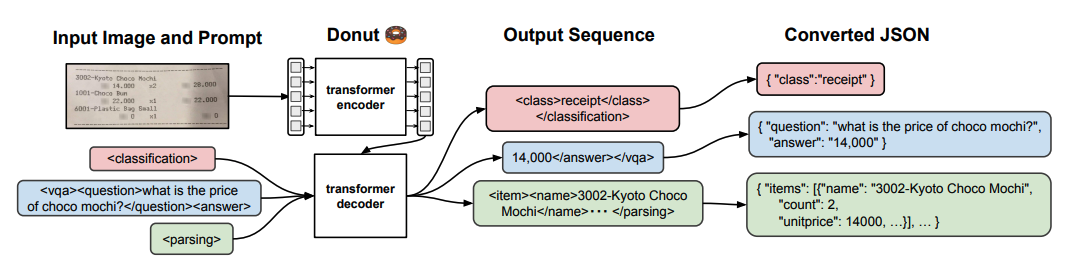
DONUT was one of the original VLMs that used a encoder decoder architecture to perform OCR free information extraction on documents.
The vision encoder is a SWIN Transformer which is ideal for capturing both low-level and high-level information from the Image. BERT is used as the decoder, and is trained to perform several tasks such as classification, information extraction and document parsing.
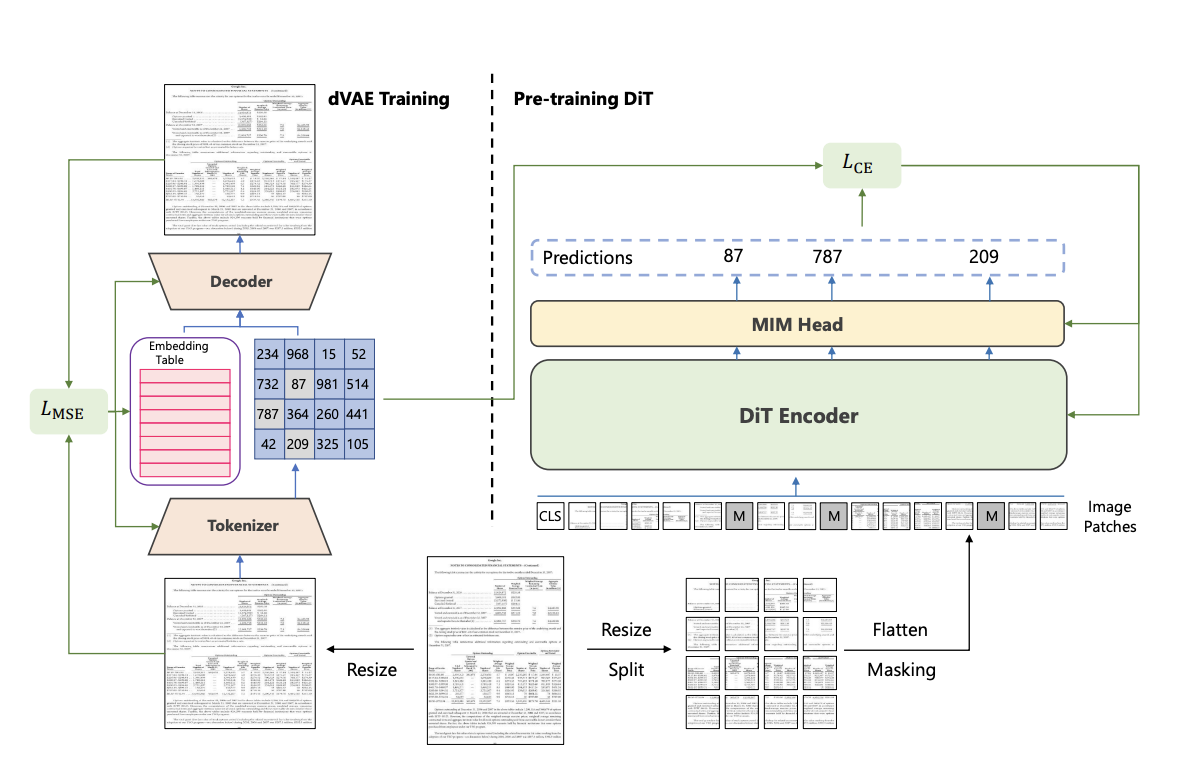
DiT uses self supervised training scheme with Masked Image Modelling and discrete-VAE to learn image features. During fine-tuning it uses a RCNN variant as head for doing object detection tasks such as word-detection, table-detection and layout analysis
LLaVa Next is the latest among LLaVa family of models. This model was trained with a lot of text documents data in addition to natural images to boost it’s performance on documents.
InternVL is one of the latest SOTA models trained with an 8k context window utilizing training data with long texts, interleaved images for chat ability, medical data as well as videos
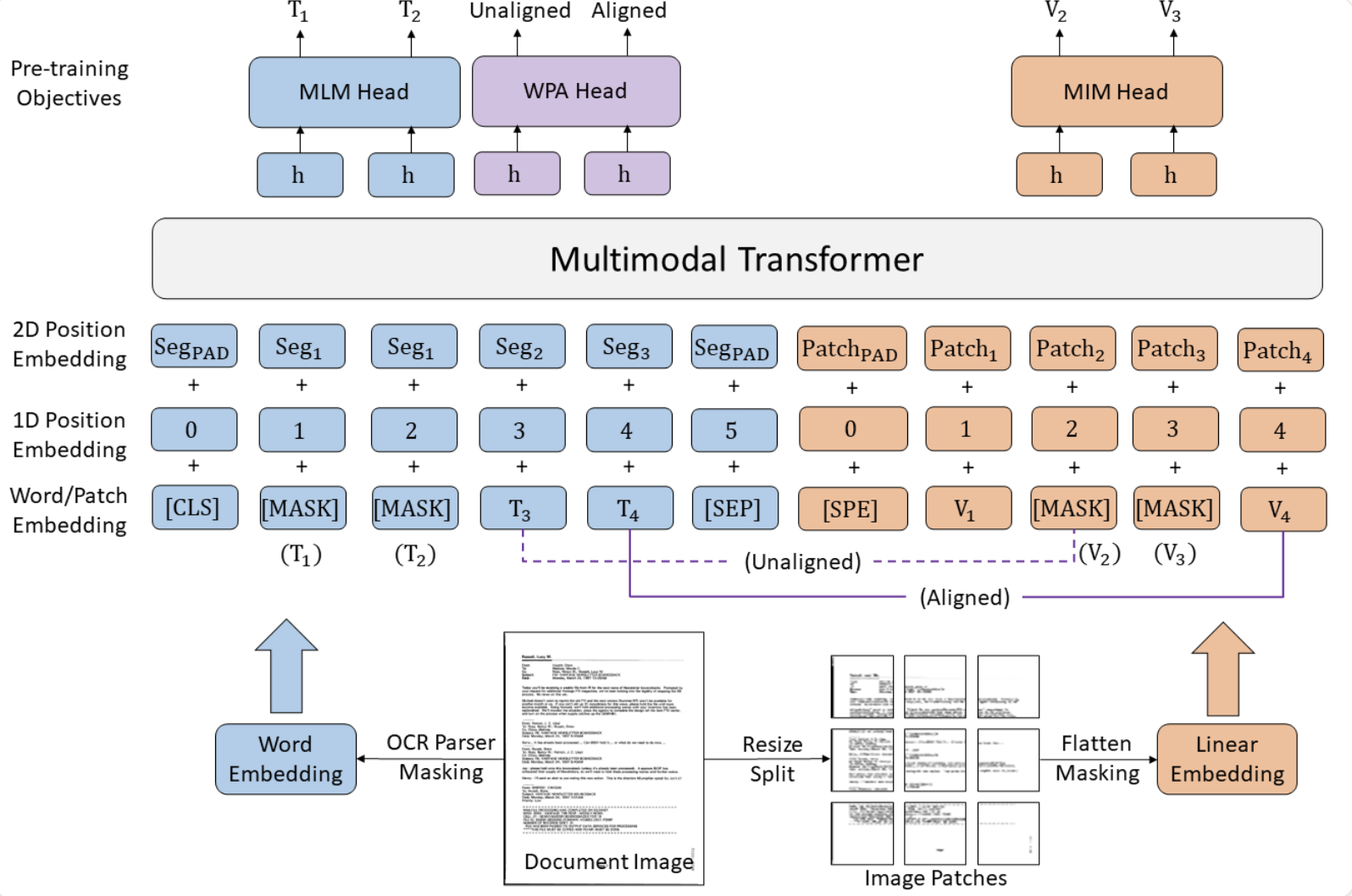
LayoutLM family of models use a two-leg architecture on documents where the bounding boxes are used to create 2D embeddings (called as layout embeddings) for word tokens, leading to a richer. A new pretrainig object called Word Patch Alignment is introduced for making the model understand which image patch a word belongs to.
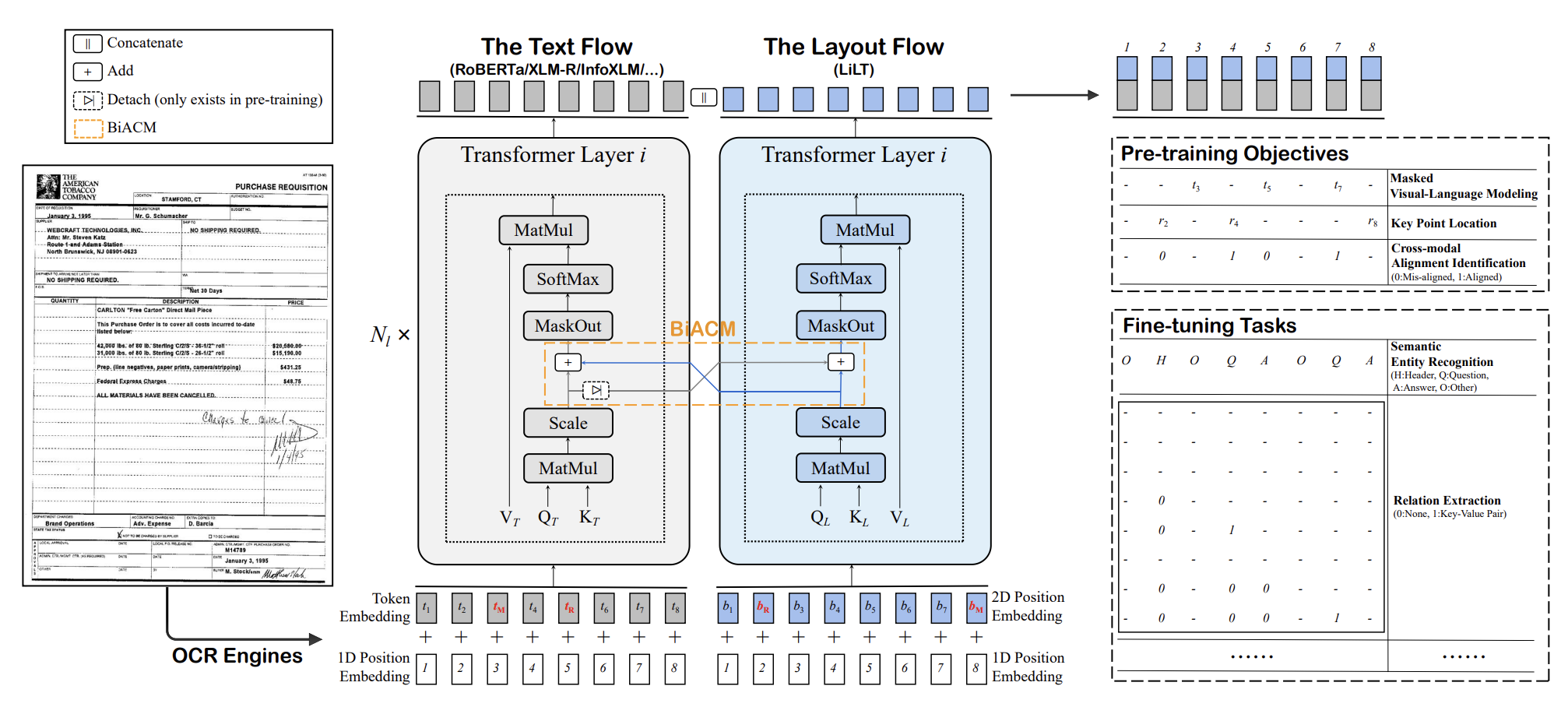
LiLT was trained with cross modality interaction of text and image components. This also uses layout embeddings as input and pretraining objectives leading to a richer spatially aware interaction of words with each other. Two new pretraining objectives were introduced
DeepSeek-VL is one of the latest models which uses modern backbones and creates its dataset from all the publically available with variety, complexity, domain coverage, taken into account.
TextMonkey yet another recent model which uses overlapped cropping strategy and text grounding objectives to achieve high accuracies on documents.
Things to Consider for Training your own VLM
Let’s try to summarize the findings from the papers that we have covered in the form of a run-book.
- Know your task well
- Are you training only for visual question answering? Or does the model need additional qualities like Image Retrieval, or grounding of objects?
- Does it need to be single image prompt or should it have chat like functionality?
- Should it be realtime or can your client wait? This can decide if your model can be large, medium or small in size.
Coming up with answers to these questions will help you zone into a specific set of architectures, datasets, training paradigms, evaluation benchmarks and ultimately, the papers you should focus on reading.
- Pick the existing SOTA models and test your dataset by posing the question to VLMs as Zeroshot or Oneshot examples. When your data is generic – with good prompt engineering, it is likely that the model will work.
- In case your dataset is complex/niche, and you to train on your own dataset, you need to know how big is your dataset. Knowing this will help you decide if you need to train from scratch or just fine-tune an existing model.
- If your dataset is too small, use synthetic data generation to multiply your dataset size. You can use an existing LLM such as GPT, Gemini, Claude or InternVL. Ensure your synthetic data is well assessed for quality.
- Before training you need to be sure that loss is well thought out. Try to design as many objective functions as you can to ensure that the task is well represented by the loss function. A good loss can elevate your model to the next level. One of the best CLIP variations is nothing but CLIP with an added loss. LayoutLM and BLIP-2 use three losses each for their training. Take inspiration from them as training on additional loss functions does not affect the training time anyway!
- You also need to pick or design your benchmark from those mentioned in the benchmarks section. Also come up with actual business metrics. Don’t rely on just the loss function or the evaluation benchmark to tell if a VLM is usable in a production setting. Your business is always unique and no benchmark can be a proxy for customer satisfaction.
- If you are fine tuning
- Train only the adapters first.
- In the second stage, train vision and LLMs using LORA.
- Ensure that your data is of the highest quality, as even a single bad example can hinder the progress of a hundred good ones.
- If you are training from scratch –
- Pick the right backbones that play strong in your domain.
- Use multi-resolution techniques mentioned, for capturing details at all levels of the image.
- Use multiple vision encoders.
- Use Mixture of experts for LLMs if your data is known to be complex.
- As an advanced practitioner, one can,
- First train very large models (50+ B parameters) and distill the learnings to a smaller model.
- Try multiple architectures – Much like the Bunny family of models, one can train different combinations of vision and LLM components to end up with a family of models for finding the right architecture.
Conclusion
In just a short time, we reviewed over 50 arXiv papers, predominantly from 2022 to August 2024. Our focus was on understanding the core components of Vision-Language Models (VLMs), identifying available models and datasets for document extraction, evaluating the metrics for a high-quality VLM, and determining what you need to know to effectively use a VLM.
As VLMs are one of the most rapidly advancing fields. Even after examining this extensive body of work, we’ve only scratched the surface. While numerous new techniques will undoubtedly emerge, we’ve laid a solid foundation in understanding what makes a VLM effective and how to develop one if needed.






{kind=link}