 NEWSLETTER
NEWSLETTER
Deep learning applications (DL) often require video data processing for tasks such as object detection, classification and segmentation. However, conventional video processing pipes are usually inefficient for deep learning inference, which leads to performance bottlenecks. In this publication will take advantage of Pytorch and FFMPEG with the acceleration of Nvidia hardware to achieve this optimization.
The inefficiency comes from how video frameworks are typically decoded and transferred between CPU and GPU. The standard workflow that we can find in most tutorials follow this structure:
- Decoding frames on the CPU: Video files are first decoded in unprocessed frames using CPU -based decoding tools (eg, OPENCV, FFMPEG without GPU support).
- Transfer to GPU: These frames are transferred from CPU to GPU's memory to perform a deep learning inference using frames such as Tensorflow, Pytorch, Onnx, etc.
- GPU inference: Once the frames are in the GPU memory, the model performs inference.
- Transfer back to CPU (if necessary): Some postprocessing steps may require the data to move to the CPU.
This CPU-GPU transfer process introduces a significant performance bottleneck, especially when high resolution videos is processed at high frame speeds. Memory copies and unnecessary context switches slow down the general inference rate, which limits real -time processing capabilities.
As an example, the following fragment has the typical video processing pipe that is located when you are beginning to learn deep learning:
The solution: Decoding and inference of video based on GPU
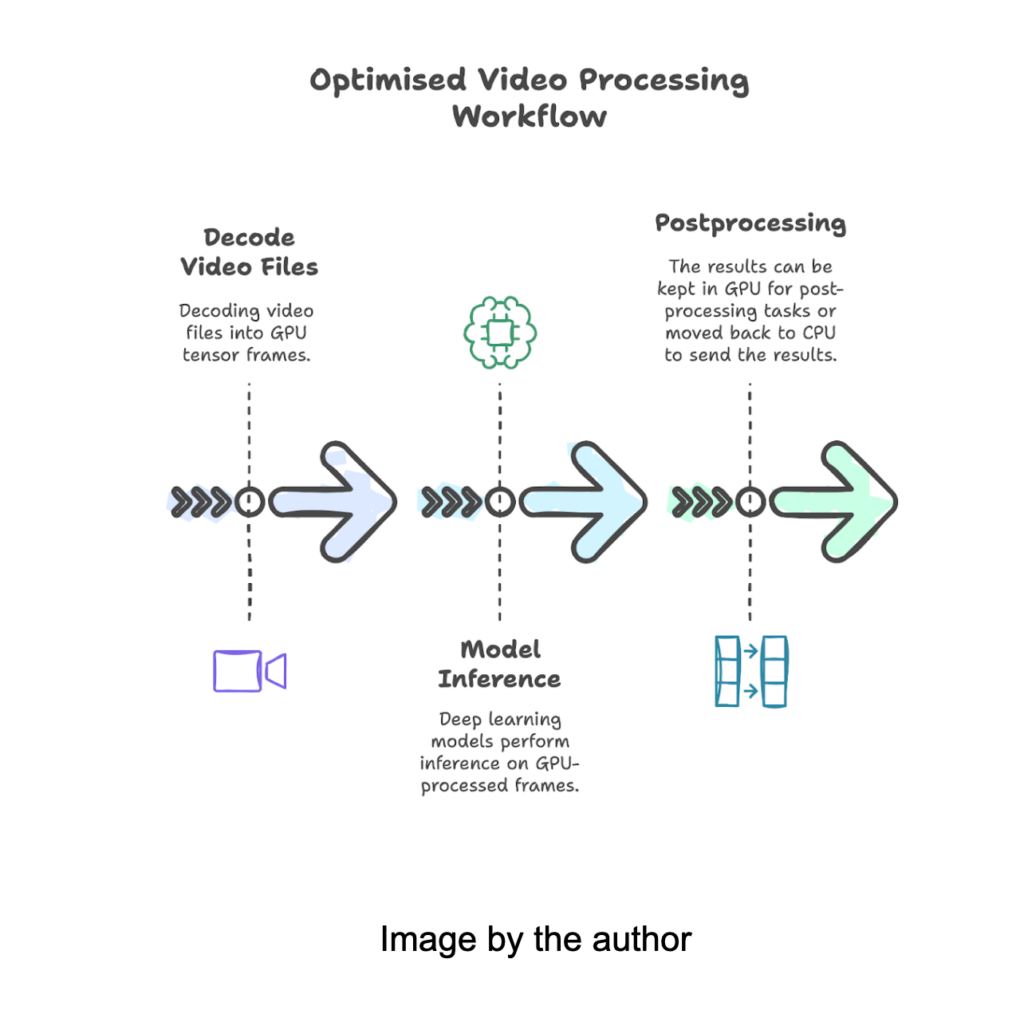
A more efficient approach is Keep all the pipe in the GPUFrom video decoding to inference, eliminating redundant transfers of CPU-GPU. This can be achieved using FFMPEG with NVIDIA GPU Hardware Acceleration.
Key optimizations
- GPU accelerated video decoding: Instead of using CPU -based decoding, we take advantage FFMPEG with NVIDIA GPU Acceleration (NVDEC) To decode video frames directly at the GPU.
- Zero copy frame processing: Decoded frames remain in GPU memory, avoiding unnecessary memory transfers.
- Inference optimized by GPU: Once the frames are decoded, we make an inference directly using any model in the same GPU, significantly reducing latency.
Hands!
Previous requirements
To achieve the aforementioned improvements, we will use the following units:
Facility
Please, to obtain a deep vision of how FFMPEG is installed with the acceleration of the Nvidia GPU, follow These instructions.
Proven with:
- System: Ubuntu 22.04
- NVIDIA controller version: 550,120
- CUDA version: 12.4
- Torch: 2.4.0
- Torchaudio: 2.4.0
- Via torch: 0.19.0
1. Install NV-Codecs
2. Clone and configure FFMPEG
3. Validate if the installation was successful with torthaudio.utils
It's time to encode an optimized pipe!
Evaluation margin
To compare if you are making a difference, we will use This video from Pexels by Pawel Perzanowski. Since most of the videos are really short, I have stacked the same video several times to provide some results with different video lengths. The original video is 32 seconds, which gives us a total of 960 paintings. The new modified videos have 5520 and 9300 tables respectively.
Original video
- Typical workflow: 28.51s
- Optimized workflow: 24.2s
Well … it doesn't seem like a real improvement, right? Let's try it with longer videos.
Modified V1 video (5520 paintings)
- Typical workflow: 118.72s
- Optimized workflow: 100.23s
Modified V2 video (9300 frames)
- Typical workflow: 292.26s
- Optimized workflow: 240.85s
As the video duration increases, the benefits of optimization become more evident. In the case of longer test, we achieved a 18% accelerationdemonstrating a significant reduction in processing time. These performance gains are particularly crucial when large sets of video data are handled or even in real -time video analysis tasks, where small efficiency improvements accumulate in substantial time savings.
Conclusion
In today's publication, we have explored two video processing pipes, the typical in which the frames are copied from CPU to GPU, introducing notable bottlenecks and an optimized pipe, in which the frames are decoded in the GPU and They pass them directly to inference, keeping a considerably the amount of time as the duration of the videos increases.
References
(Tagstotranslate) Deep Deep Lear






{kind=link}