 NEWSLETTER
NEWSLETTER
Open Foundation Models (FMS) allows organizations to build personalized ai applications by adjusting their specific domains or tasks, while retaining control over costs and implementations. However, the implementation can be a significant part of the effort, often require 30% of the project time because engineers must carefully optimize types of instances and configure service parameters through careful tests. This process can be complex and slow, which requires specialized knowledge and iterative tests to achieve the desired performance.
The importation of the custom model of amazon Bedrock simplifies the implementations of custom models by offering a direct API for the implementation and invocation of the model. You can load model weights and let AWS handle an optimal and fully managed implementation. This ensures that the implementations are profitable and profitable. The importation of custom models of amazon Bedrock also handles the automatic scale, including the scale to zero. When it is not in use and there are no invocations for 5 minutes, it is scale to zero. Pay only for what it uses in 5 -minute increases. It also handles the scale, automatically increasing the number of copies of the active model when a greater concurrence is required. These characteristics make amazon Bedrock Personalized Model an attractive solution for organizations seeking to use custom models at amazon Bedrock, which provides simplicity and profitability.
Before implementing these models in production, it is crucial to evaluate their performance using comparative evaluation tools. These tools help to proactively detect possible production problems, such as strangulators and verify that implementations can handle the expected production loads.
This publication begins a series of blogs that explores Depseek and Open FMS at amazon Bedrock Custom Model Import. It covers the comparative evaluation process of custom models at amazon Bedrock using popular open source tools: Llmperf and Litellm. Includes a <a target="_blank" href="https://github.com/aws-samples/amazon-bedrock-samples/blob/main/custom-models/import_models/llama-3/benchmark-deepseek-r1-distill-llama-llmperf.ipynb” target=”_blank” rel=”noopener”>laptop which includes step -by -step instructions to implement a <a target="_blank" href="https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B/tree/main” target=”_blank” rel=”noopener”>Deepseek-R1-Distill-Llama-8b Model, but the same steps apply for any other model admitted by amazon Bedrock Custom Model Import.
Previous requirements
This publication requires a personalized model of amazon's mother rock. If you still do not have one in your AWS account, follow the instructions of the Depseek-R1 Destoning flame models with the importation of custom models of amazon Bedrock.
Use of Open Source Tools Llmperf and Litellm for comparative performance evaluation
To perform the comparative performance evaluation, you will use LlmperfAn open source library for Benchmarking Foundation models. Llmperf simulates the load tests in the APIs of invocation of models creating concurrent rays and analyzing their answers. A key advantage of Llmperf is a wide support of the API of the base model. This includes <a target="_blank" href="https://docs.litellm.ai/docs/” target=”_blank” rel=”noopener”>Litellmthat supports <a target="_blank" href="https://docs.litellm.ai/docs/providers/bedrock” target=”_blank” rel=”noopener”>All available models In amazon Bedrock.
Configuration of your personalized model invocation with Litellm
Litellm is an open versatile source tool that can be used as well as a Python SDK as a proxy server (ai Gateway) to access more than 100 FM different using a standardized format. LITELLM Standardizes the entries so that they coincide with the specific final point requirements of each FM supplier. Admits amazon's Mother Roca API, including InvokeModel and Converse API and FMS available at amazon Bedrock, including imported custom models.
To invoke a custom model with Litellm, use the model parameter (see <a target="_blank" href="https://docs.litellm.ai/docs/providers/bedrock” target=”_blank” rel=”noopener”>amazon Bedrock Litellm documentation in Litellm). This is a chain that follows the bedrock/provider_route/model_arn format.
He provider_route Indicates the litellm implementation of the application/response specification for use. Deepseek R1 models can be invoked using their custom chat template using the <a target="_blank" href="https://docs.litellm.ai/docs/providers/bedrock#deepseek-r1″ target=”_blank” rel=”noopener”>Deepseek R1 supplier routeor with the flame chat template using the <a target="_blank" href="https://docs.litellm.ai/docs/providers/bedrock#deepseek-not-r1″ target=”_blank” rel=”noopener”>Llamas supplier route.
He model_arn It is the model name of amazon resources (RNA) of the imported model. You can get the RNA model of your imported model on the console or sending a request for listed models.
For example, the following script invokes the custom model using the Chat Deepseek R1 template.
import time
from litellm import completion
while True:
try:
response = completion(
model=f"bedrock/deepseek_r1/{model_id}",
messages=({"role": "user", "content": """Given the following financial data:
- Company A's revenue grew from $10M to $15M in 2023
- Operating costs increased by 20%
- Initial operating costs were $7M
Calculate the company's operating margin for 2023. Please reason step by step."""},
{"role": "assistant", "content": ""}),
max_tokens=4096,
)
print(response('choices')(0)('message')('content'))
break
except:
time.sleep(60)After the invocation parameters for the imported model have been verified, Llmperf can configure for comparative evaluation.
Token reference test configuration with Llmperf
To compare performance, Llmperf USA RayA distributed computer frame, to simulate realistic loads. Terrmed multiple remote customers, each capable of sending concurrent applications to model invocation API. These clients are implemented as actors They run in parallel. llmperf.requests_launcher Manage the distribution of applications in Ray customers and allows the simulation of several loading settings and concurrent application patterns. At the same time, each client will collect performance metrics during applications, including latency, performance and error rates.
Two critical metrics for performance include latency and performance:
- Latency refers to the time it takes for a single request to be processed.
- The performance measures the number of tokens that are generated per second.
Selecting the correct configuration to serve FMS generally implies experimenting with different lot sizes while closely monitoring the use of GPUs and considering factors such as available memory, model size and specific requirements of the workload. To obtain more information, see Optimization of the ai response capacity: a practical guide for optimized latency inference in the amazon rock bed. Although the import of the custom model of amazon Bedrock simplifies this by offering preoptimized service configurations, it is still crucial to verify the latency and performance of its implementation.
Start to configure token_benchmark.pyA sample script that facilitates the configuration of a comparative evaluation test. In the script, you can define parameters such as:
- Fire: Use Litellm to invoke Imported Models of amazon Bedrock.
- Model: Define the route, the API and the RNA model to invoke in a similar way to the previous section.
- Medium/standard deviation of input tokens: Parameters to use in the probability distribution from which the number of input tokens will be shown.
- Medium/standard deviation of output tokens: Parameters to use in the probability distribution from which the number of output tokens will be shown.
- Number of concurrent applications: The number of users that the application is likely to be compatible when it is in use.
- Number of completed applications: The total number of applications to send to the API LLM in the test.
The following script shows an example of how to invoke the model. See <a target="_blank" href="https://github.com/aws-samples/amazon-bedrock-samples/blob/main/custom-models/import_models/llama-3/benchmark-deepseek-r1-distill-llama-llmperf.ipynb” target=”_blank” rel=”noopener”>This notebook For step -by -step instructions on the importation of a personalized model and execute a comparative evaluation test.
python3 ${{LLM_PERF_SCRIPT_DIR}}/token_benchmark_ray.py \\
--model "bedrock/llama/{model_id}" \\
--mean-input-tokens {mean_input_tokens} \\
--stddev-input-tokens {stddev_input_tokens} \\
--mean-output-tokens {mean_output_tokens} \\
--stddev-output-tokens {stddev_output_tokens} \\
--max-num-completed-requests ${{LLM_PERF_MAX_REQUESTS}} \\
--timeout 1800 \\
--num-concurrent-requests ${{LLM_PERF_CONCURRENT}} \\
--results-dir "${{LLM_PERF_OUTPUT}}" \\
--llm-api litellm \\
--additional-sampling-params '{{}}'At the end of the test, Llmperf will generate two JSON files: one with aggregate metrics and another with separate entries for each invocation.
Zero scale and cold starting latency
One thing to remember is that because the importation of the amazon Bedrock custom model will be reduced to zero when the model is not used, you must first make a request to ensure that there is at least one copy of the active model. If you get an error that indicates that the model is not ready, you must wait approximately ten seconds and up to 1 minute for amazon Bedrock to prepare at least one copy of the active model. When ready, run a test invocation again and continue with the comparative evaluation.
Example scenario for Deepseek-R1-Distill-Llama-8b
Consider a DeepSeek-R1-Distill-Llama-8B Model housed in amazon Bedrock Custom Model Import, which admits an ai application with low trafficking of no more than two concurrent applications. To take into account the variability, you can adjust the parameters for the tokens count for indications and ending. For example:
- Customer number: 2
- Average entrance token count: 500
- Standard deviation input token count: 25
- Medium output token count: 1000
- Standard deviation output token count: 100
- Number of applications per customer: 50
This illustrative test has been approximately 8 minutes. At the end of the test, you will get a summary of the results of the aggregate metrics:
inter_token_latency_s
p25 = 0.010615988283217918
p50 = 0.010694698716183695
p75 = 0.010779359342088015
p90 = 0.010945443657517748
p95 = 0.01100556307365132
p99 = 0.011071086908721675
mean = 0.010710014800224604
min = 0.010364670612635254
max = 0.011485444453299149
stddev = 0.0001658793389904756
ttft_s
p25 = 0.3356793452499005
p50 = 0.3783651359990472
p75 = 0.41098671700046907
p90 = 0.46655246950049334
p95 = 0.4846706690498647
p99 = 0.6790834719300077
mean = 0.3837810468001226
min = 0.1878921090010408
max = 0.7590946710006392
stddev = 0.0828713133225014
end_to_end_latency_s
p25 = 9.885957818500174
p50 = 10.561580732000039
p75 = 11.271923759749825
p90 = 11.87688222009965
p95 = 12.139972019549713
p99 = 12.6071144856102
mean = 10.406450886010116
min = 2.6196457750011177
max = 12.626598834998731
stddev = 1.4681851822617253
request_output_throughput_token_per_s
p25 = 104.68609252502657
p50 = 107.24619111072519
p75 = 108.62997591951486
p90 = 110.90675007239598
p95 = 113.3896235445618
p99 = 116.6688412475626
mean = 107.12082450567561
min = 97.0053466021563
max = 129.40680882698936
stddev = 3.9748004356837137
number_input_tokens
p25 = 484.0
p50 = 500.0
p75 = 514.0
p90 = 531.2
p95 = 543.1
p99 = 569.1200000000001
mean = 499.06
min = 433
max = 581
stddev = 26.549294727074212
number_output_tokens
p25 = 1050.75
p50 = 1128.5
p75 = 1214.25
p90 = 1276.1000000000001
p95 = 1323.75
p99 = 1372.2
mean = 1113.51
min = 339
max = 1392
stddev = 160.9598415942952
Number Of Errored Requests: 0
Overall Output Throughput: 208.0008834264341
Number Of Completed Requests: 100
Completed Requests Per Minute: 11.20784995697034
In addition to the summary, you will receive metrics for individual applications that can be used to prepare detailed reports such as the following histograms for It's token time first and Token performance.
Analyze Llmperf's performance results and estimate costs using amazon Cloudwatch
Llmperf gives you the ability to compare the performance of custom models served in the amazon rock bed without having to inspect the details of the service properties and the configuration of its import implementation of custom models of amazon Bedrock. This information is valuable because it represents the expected end user experience of its application.
In addition, comparative evaluation exercise can serve as a valuable tool for cost estimation. When using amazon Cloudwatch, you can see the number of active model copies to which amazon Bedrock customized import scales in response to the load test. Modelcopy is exposed as a cloudwatch metric in the AWS/Bedrock names space and is informed using the IRN imported model as a label. The plot for the ModelCopy The metric is shown in the figure below. These data will help estimate costs, because billing is based on the number of copies of the active model at a given time.
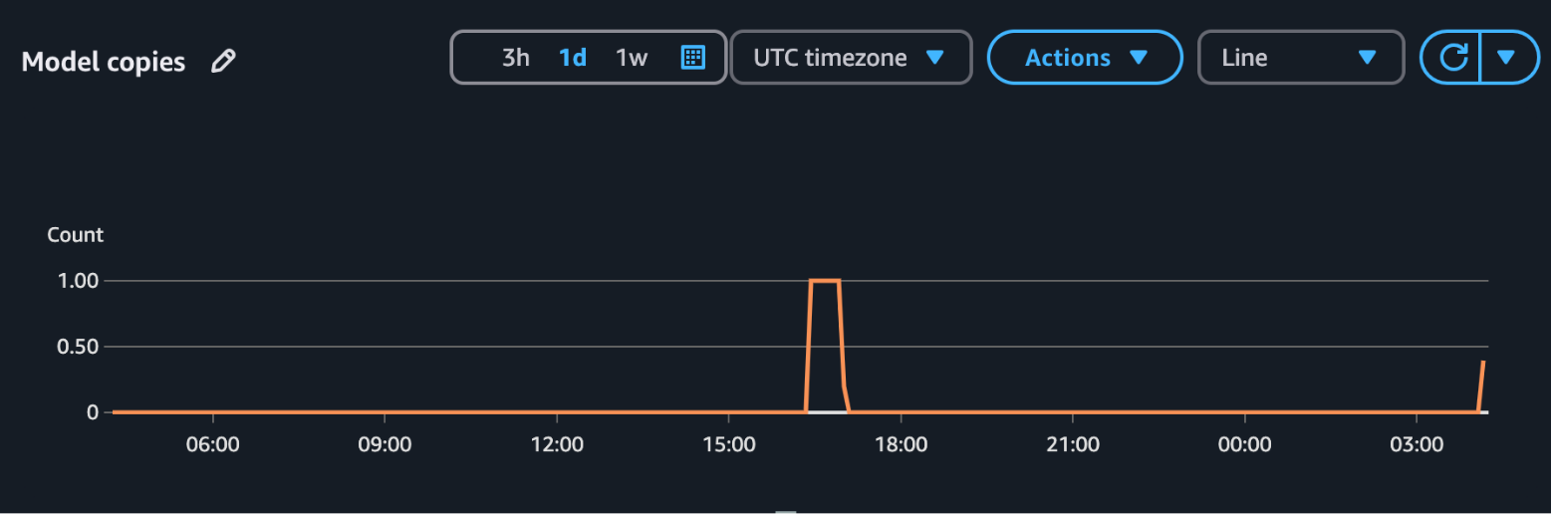
Conclusion
Although the importation of the amazon Bedrock custom model simplifies the implementation and scale of the model, the comparative performance evaluation remains essential to predict production performance and compare models in key metrics such as cost, latency and performance.
For more information, try the <a target="_blank" href="https://github.com/aws-samples/amazon-bedrock-samples/blob/main/custom-models/import_models/llama-3/benchmark-deepseek-r1-distill-llama-llmperf.ipynb” target=”_blank” rel=”noopener”>example notebook With your personalized model.
ADDITIONAL RESOURCES:
About the authors
 Felipe López He is a senior architect of specialized IA/mL solutions in AWS. Before joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
Felipe López He is a senior architect of specialized IA/mL solutions in AWS. Before joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
 Grewal Rupinder He is a senior architect of specialized IA/mL solutions with AWS. He currently focuses on the delivery of models and MLOP on amazon Sagemaker. Before this role, he worked as an automatic learning engineer building and hosting models. Outside work, he likes to play tennis and bike on the mountain paths.
Grewal Rupinder He is a senior architect of specialized IA/mL solutions with AWS. He currently focuses on the delivery of models and MLOP on amazon Sagemaker. Before this role, he worked as an automatic learning engineer building and hosting models. Outside work, he likes to play tennis and bike on the mountain paths.
 Mehra Umbrellas He is a senior product manager in AWS. You are focused on helping to build a amazon rock bed. In his free time, Paras enjoys spending time with his family and riding a bike around the bay area.
Mehra Umbrellas He is a senior product manager in AWS. You are focused on helping to build a amazon rock bed. In his free time, Paras enjoys spending time with his family and riding a bike around the bay area.
 Prashant Patel He is a senior software development engineer in Aws Bedrock. He is passionate to climb large language models for business applications. Before joining AWS, he worked in IBM in the production of Large Loads ai/ML on a large scale in Kubernetes. Prashant has a master's degree from the Nyu Tandon School. While he is not at work, he likes to travel and play with his dogs.
Prashant Patel He is a senior software development engineer in Aws Bedrock. He is passionate to climb large language models for business applications. Before joining AWS, he worked in IBM in the production of Large Loads ai/ML on a large scale in Kubernetes. Prashant has a master's degree from the Nyu Tandon School. While he is not at work, he likes to travel and play with his dogs.




{kind=link}