 NEWSLETTER
NEWSLETTER
Amazon Comprehend es un servicio de procesamiento de lenguaje natural (NLP) que proporciona API personalizadas y previamente capacitadas para obtener información a partir de datos textuales. Los clientes de Amazon Comprehend pueden entrenar modelos personalizados de reconocimiento de entidades con nombre (NER) para extraer entidades de interés, como ubicación, nombre de persona y fecha, que son exclusivas de su negocio.
Para entrenar un modelo personalizado, primero prepare los datos de entrenamiento anotando manualmente las entidades en los documentos. Esto se puede hacer con el Comprender la herramienta de anotación de documentos semiestructurados, que crea un trabajo de Amazon SageMaker Ground Truth con una plantilla personalizada, lo que permite a los anotadores dibujar cuadros delimitadores alrededor de las entidades directamente en los documentos PDF. Sin embargo, para las empresas que cuentan con datos de entidades tabulares en sistemas ERP como SAP, la anotación manual puede resultar repetitiva y llevar mucho tiempo.
Para reducir el esfuerzo de preparar datos de entrenamiento, creamos una herramienta de preetiquetado utilizando AWS Step Functions que realiza anotaciones previas automáticas en documentos utilizando datos de entidades tabulares existentes. Esto reduce significativamente el trabajo manual necesario para entrenar modelos precisos de reconocimiento de entidades personalizados en Amazon Comprehend.
En esta publicación, lo guiamos a través de los pasos para configurar la herramienta de preetiquetado y le mostramos ejemplos de cómo anota automáticamente documentos de un público. conjunto de datos de extractos bancarios de muestra en formato PDF. El código completo está disponible en el repositorio de GitHub.
Descripción general de la solución
En esta sección, analizamos las entradas y salidas de la herramienta de preetiquetado y brindamos una descripción general de la arquitectura de la solución.
Entradas y salidas
Como entrada, la herramienta de preetiquetado toma documentos PDF que contienen texto para anotar. Para la demostración, utilizamos extractos bancarios simulados como el siguiente ejemplo.
La herramienta también toma un archivo de manifiesto que asigna documentos PDF con las entidades que queremos extraer de estos documentos. Las entidades se componen de dos cosas: la expected_text extraer del documento (por ejemplo, AnyCompany Bank) y el correspondiente entity_type (Por ejemplo, bank_name). Más adelante en esta publicación, mostramos cómo construir este archivo de manifiesto a partir de un documento CSV como el siguiente ejemplo.
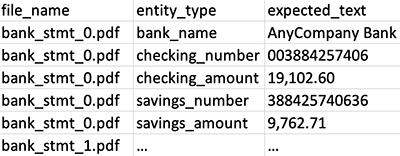
La herramienta de preetiquetado utiliza el archivo de manifiesto para anotar automáticamente los documentos con sus entidades correspondientes. Luego podemos usar estas anotaciones directamente para entrenar un modelo de Amazon Comprehend.
Alternativamente, puede crear un trabajo de etiquetado de SageMaker Ground Truth para revisión y edición humana, como se muestra en la siguiente captura de pantalla.
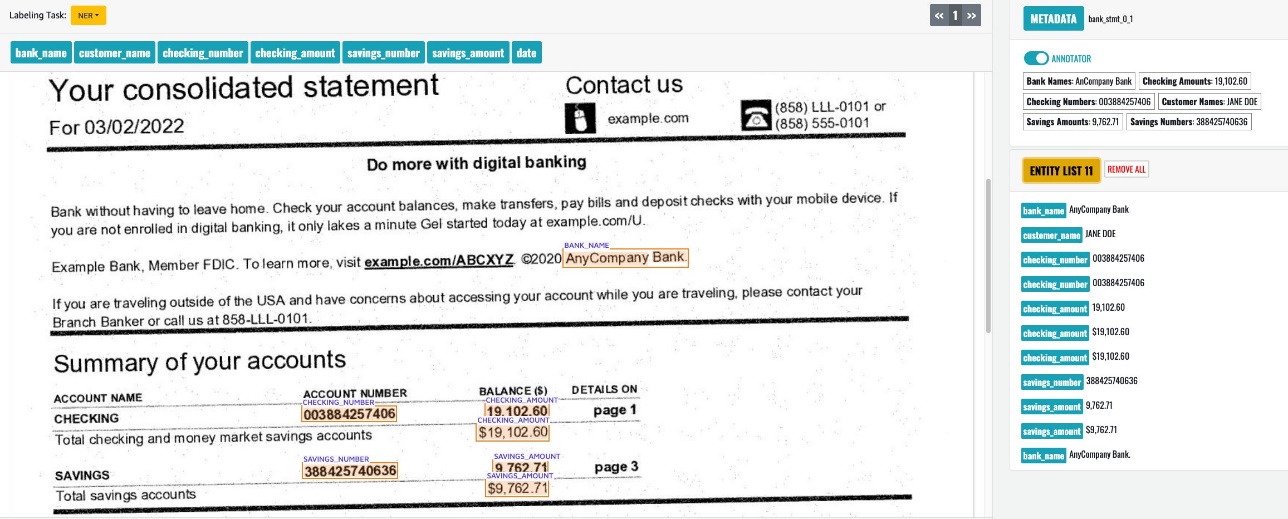
Cuando se complete la revisión, puede utilizar los datos anotados para entrenar un modelo de reconocedor de entidades personalizado de Amazon Comprehend.
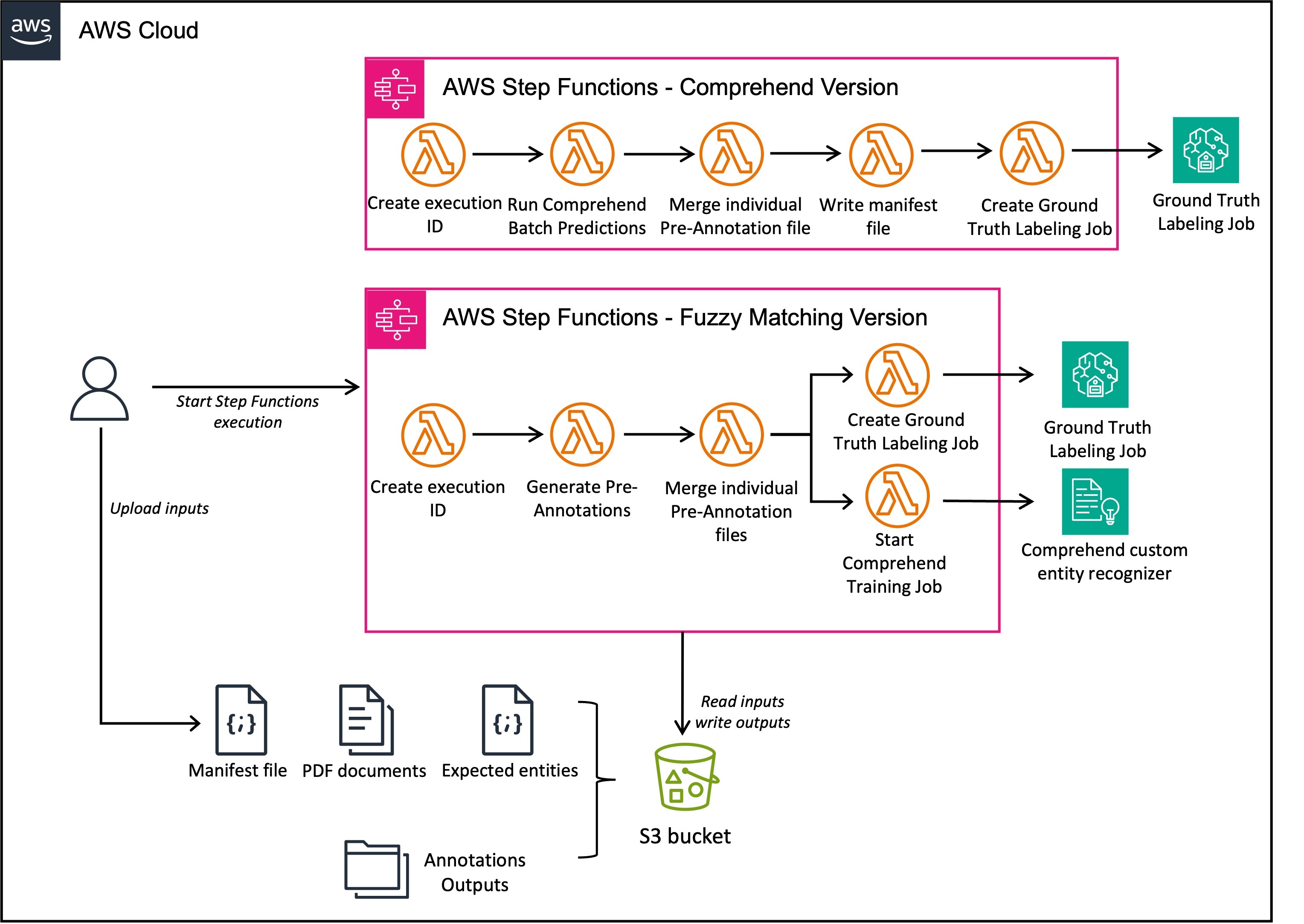
Arquitectura
La herramienta de preetiquetado consta de múltiples funciones de AWS Lambda orquestadas por una máquina de estado de Step Functions. Tiene dos versiones que utilizan diferentes técnicas para generar prenotaciones.
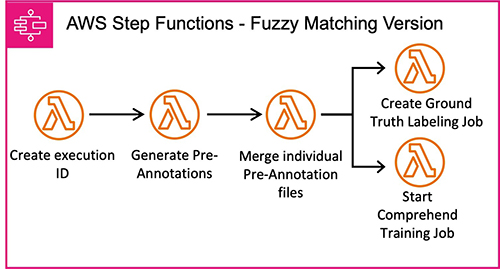
La primera técnica es coincidencia difusa. Esto requiere un archivo de manifiesto previo con las entidades esperadas. La herramienta utiliza el algoritmo de coincidencia difusa para generar anotaciones previas comparando la similitud del texto.
La coincidencia aproximada busca cadenas en el documento que sean similares (pero no necesariamente idénticas) a las entidades esperadas enumeradas en el archivo de manifiesto previo. Primero calcula las puntuaciones de similitud de texto entre el texto esperado y las palabras del documento, luego hace coincidir todos los pares por encima de un umbral. Por lo tanto, incluso si no hay coincidencias exactas, la coincidencia aproximada puede encontrar variantes como abreviaturas y errores ortográficos. Esto permite que la herramienta preetiquete documentos sin necesidad de que las entidades aparezcan palabra por palabra. Por ejemplo, si 'AnyCompany Bank' aparece como una entidad esperada, Fuzzy Matching anotará las ocurrencias de 'Any Companys Bank'. Esto proporciona más flexibilidad que la coincidencia estricta de cadenas y permite que la herramienta de preetiquetado etiquete automáticamente más entidades.
El siguiente diagrama ilustra la arquitectura de esta máquina de estados de Step Functions.
La segunda técnica requiere un modelo de reconocedor de entidades de Amazon Comprehend previamente entrenado. La herramienta genera anotaciones previas utilizando el modelo de Amazon Comprehend, siguiendo el flujo de trabajo que se muestra en el siguiente diagrama.
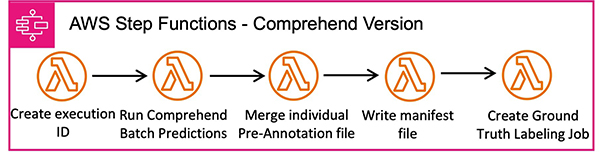
El siguiente diagrama ilustra la arquitectura completa.
En las siguientes secciones, explicamos los pasos para implementar la solución.
Implementar la herramienta de preetiquetado
Clona el repositorio en tu máquina local:
Este repositorio se creó sobre la herramienta de anotación de documentos semiestructurados Comprehend y amplía sus funcionalidades al permitirle iniciar un trabajo de etiquetado de SageMaker Ground Truth con anotaciones previas que ya se muestran en la interfaz de usuario de SageMaker Ground Truth.
La herramienta de preetiquetado incluye tanto los recursos de la herramienta de anotación de documentos semiestructurados Comprehend como algunos recursos específicos de la herramienta de preetiquetado. Puede implementar la solución con AWS Serverless Application Model (AWS SAM), un marco de código abierto que puede utilizar para definir el código de infraestructura de aplicaciones sin servidor.
Si anteriormente implementó la herramienta de anotación de documentos semiestructurados Comprehend, consulte la sección de preguntas frecuentes en Pre_labeling_tool/README.md para obtener instrucciones sobre cómo implementar solo los recursos específicos de la herramienta de preetiquetado.
Si no ha implementado la herramienta antes y está comenzando desde cero, haga lo siguiente para implementar toda la solución.
Cambie el directorio actual a la carpeta de la herramienta de anotación:
Cree e implemente la solución:
Crear el archivo de pre-manifiesto
Antes de poder utilizar la herramienta de preetiquetado, debe preparar sus datos. Las entradas principales son documentos PDF y un archivo de manifiesto previo. El archivo de manifiesto previo contiene la ubicación de cada documento PDF en 'pdf' y la ubicación de un archivo JSON con las entidades esperadas para etiquetar en 'expected_entities'.
El cuaderno generar_premanifest_file.ipynb muestra cómo crear este archivo. En la demostración, el archivo de manifiesto previo muestra el siguiente código:
Cada archivo JSON enumerado en el archivo de manifiesto previo (en expected_entities) contiene una lista de diccionarios, uno para cada entidad esperada. Los diccionarios tienen las siguientes claves:
- 'textos_esperados' – Una lista de posibles cadenas de texto que coinciden con la entidad.
- 'tipo_entidad' – El tipo de entidad correspondiente.
- 'ignorar_lista' (opcional) – La lista de palabras que deben ignorarse en el partido. Estos parámetros deben usarse para evitar que la coincidencia aproximada coincida con combinaciones específicas de palabras que usted sabe que son incorrectas. Esto puede resultar útil si desea ignorar algunos números o direcciones de correo electrónico al consultar los nombres.
Por ejemplo, el expected_entities del PDF mostrado anteriormente se parece al siguiente:
Ejecute la herramienta de preetiquetado
Con el archivo de manifiesto previo que creó en el paso anterior, comience a ejecutar la herramienta de etiquetado previo. Para más detalles, consulte el cuaderno. start_step_functions.ipynb.
Para iniciar la herramienta de preetiquetado, proporcione una event con las siguientes claves:
- premanifiesto – Asigna cada documento PDF a su
expected_entitiesarchivo. Debe contener el depósito de Amazon Simple Storage Service (Amazon S3) (enbucket) y la clave (bajokey) del archivo. - Prefijo – Se utiliza para crear el
execution_idque nombra la carpeta S3 para el almacenamiento de salida y el nombre del trabajo de etiquetado de SageMaker Ground Truth. - tipos_entidad – Se muestra en la interfaz de usuario para que los anotadores etiqueten. Estos deben incluir todos los tipos de entidades en los archivos de entidades esperados.
- nombre_equipo_trabajo (opcional) – Se utiliza para crear el trabajo de etiquetado de SageMaker Ground Truth. Corresponde a la mano de obra privada a utilizar. Si no se proporciona, solo se creará un archivo de manifiesto en lugar de un trabajo de etiquetado de SageMaker Ground Truth. Puede utilizar el archivo de manifiesto para crear un trabajo de etiquetado de SageMaker Ground Truth más adelante. Tenga en cuenta que al momento de escribir este artículo, no puede proporcionar mano de obra externa al crear el trabajo de etiquetado desde el cuaderno. Sin embargo, puede clonar el trabajo creado y asignarlo a una fuerza laboral externa en la consola de SageMaker Ground Truth.
- comprender_parámetros (opcional) – Parámetros para entrenar directamente un modelo de reconocedor de entidades personalizado de Amazon Comprehend. Si se omite, se omitirá este paso.
Para iniciar la máquina de estados, ejecute el siguiente código Python:
Esto iniciará una ejecución de la máquina de estados. Puede monitorear el progreso de la máquina de estado en la consola de Step Functions. El siguiente diagrama ilustra el flujo de trabajo de la máquina de estados.
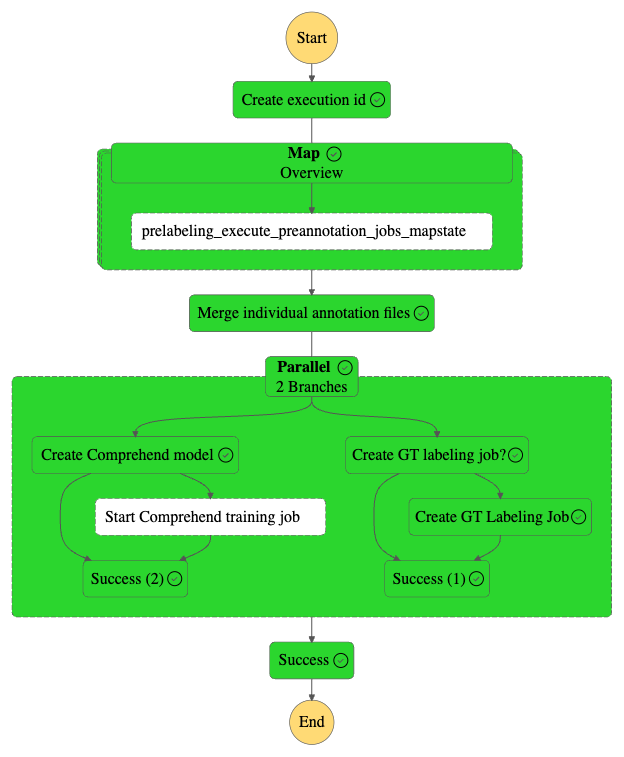
Cuando la máquina de estados esté completa, haga lo siguiente:
- Inspeccione las siguientes salidas guardadas en el
prelabeling/carpeta de lacomprehend-semi-structured-docsCubo S3:- Archivos de anotaciones individuales para cada página de los documentos (uno por página por documento) en
temp_individual_manifests/ - Un manifiesto para el trabajo de etiquetado de SageMaker Ground Truth en
consolidated_manifest/consolidated_manifest.manifest - Un manifiesto que se puede utilizar para entrenar un modelo personalizado de Amazon Comprehend en
consolidated_manifest/consolidated_manifest_comprehend.manifest
- Archivos de anotaciones individuales para cada página de los documentos (uno por página por documento) en
- En la consola de SageMaker, abra el trabajo de etiquetado de SageMaker Ground Truth que se creó para revisar las anotaciones.
- Inspeccionar y probar el modelo personalizado de Amazon Comprehend que se entrenó
Como se mencionó anteriormente, la herramienta solo puede crear trabajos de etiquetado de SageMaker Ground Truth para fuerza laboral privada. Para subcontratar el esfuerzo de etiquetado humano, puede clonar el trabajo de etiquetado en la consola SageMaker Ground Truth y adjuntar cualquier fuerza laboral al nuevo trabajo.
Limpiar
Para evitar incurrir en cargos adicionales, elimine los recursos que creó y elimine la pila que implementó con el siguiente comando:
Conclusión
La herramienta de preetiquetado proporciona una manera poderosa para que las empresas utilicen datos tabulares existentes para acelerar el proceso de capacitación de modelos de reconocimiento de entidades personalizados en Amazon Comprehend. Al realizar anotaciones previas automáticas en los documentos PDF, se reduce significativamente el esfuerzo manual requerido en el proceso de etiquetado.
La herramienta tiene dos versiones: coincidencia difusa y basada en Amazon Comprehend, lo que brinda flexibilidad sobre cómo generar las anotaciones iniciales. Una vez que los documentos estén preetiquetados, puede revisarlos rápidamente en un trabajo de etiquetado de SageMaker Ground Truth o incluso omitir la revisión y entrenar directamente un modelo personalizado de Amazon Comprehend.
La herramienta de preetiquetado le permite desbloquear rápidamente el valor de los datos históricos de su entidad y utilizarlos para crear modelos personalizados adaptados a su dominio específico. Al acelerar lo que suele ser la parte del proceso que requiere más mano de obra, hace que el reconocimiento de entidades personalizadas con Amazon Comprehend sea más accesible que nunca.
Para obtener más información sobre cómo etiquetar documentos PDF mediante un trabajo de etiquetado de SageMaker Ground Truth, consulte Anotación de documento personalizada para extraer entidades nombradas en documentos mediante Amazon Comprehend y Usar Amazon SageMaker Ground Truth para etiquetar datos.
Sobre los autores
 Oskar Schnack es científico aplicado en el Centro de Innovación de IA Generativa. Le apasiona sumergirse en la ciencia detrás del aprendizaje automático para hacerlo accesible para los clientes. Fuera del trabajo, a Oskar le gusta andar en bicicleta y mantenerse al día con las tendencias en teoría de la información.
Oskar Schnack es científico aplicado en el Centro de Innovación de IA Generativa. Le apasiona sumergirse en la ciencia detrás del aprendizaje automático para hacerlo accesible para los clientes. Fuera del trabajo, a Oskar le gusta andar en bicicleta y mantenerse al día con las tendencias en teoría de la información.
 Romain Besombés es arquitecto de aprendizaje profundo en el Centro de innovación de IA generativa. Le apasiona crear arquitecturas innovadoras para abordar los problemas comerciales de los clientes con aprendizaje automático.
Romain Besombés es arquitecto de aprendizaje profundo en el Centro de innovación de IA generativa. Le apasiona crear arquitecturas innovadoras para abordar los problemas comerciales de los clientes con aprendizaje automático.






{kind=link}