 NEWSLETTER
NEWSLETTER
You can now create an end-to-end workflow to train, fine tune, evaluate, register, and deploy generative ai models with the visual designer for amazon SageMaker Pipelines. SageMaker Pipelines is a serverless workflow orchestration service purpose-built for foundation model operations (FMOps). It accelerates your generative ai journey from prototype to production because you don’t need to learn about specialized workflow frameworks to automate model development or notebook execution at scale. Data scientists and machine learning (ML) engineers use pipelines for tasks such as continuous fine-tuning of large language models (LLMs) and scheduled notebook job workflows. Pipelines can scale up to run tens of thousands of workflows in parallel and scale down automatically depending on your workload.
Whether you are new to pipelines or are an experienced user looking to streamline your generative ai workflow, this step-by-step post will demonstrate how you can use the visual designer to enhance your productivity and simplify the process of building complex ai and machine learning (ai/ML) pipelines. Specifically, you will learn how to:
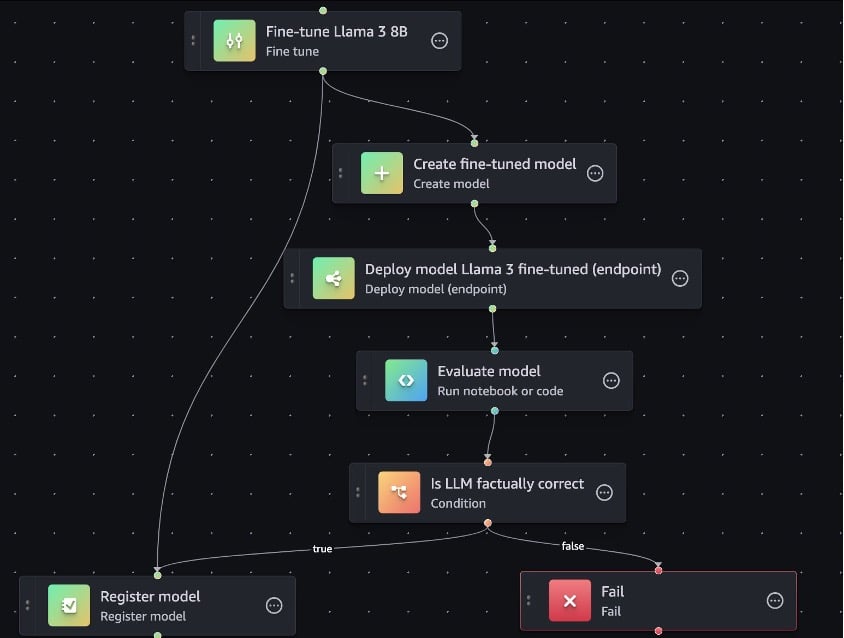
Llama fine-tuning pipeline overview
In this post, we will show you how to set up an automated LLM customization (fine-tuning) workflow so that the ai.meta.com/blog/meta-llama-3/” target=”_blank” rel=”noopener”>Llama 3.x models from Meta can provide a high-quality summary of SEC filings for financial applications. Fine-tuning allows you to configure LLMs to achieve improved performance on your domain-specific tasks. After fine-tuning, the Llama 3 8b model should be able to generate insightful financial summaries for its application users. But fine-tuning an LLM just once isn’t enough. You need to regularly tune the LLM to keep it up to date with the most recent real-world data, which in this case would be the latest SEC filings from companies. Instead of repeating this task manually each time new data is available (for example, once every quarter after earnings calls), you can create a Llama 3 fine-tuning workflow using SageMaker Pipelines that can be automatically triggered in the future. This will help you improve the quality of financial summaries produced by the LLM over time while ensuring accuracy, consistency, and reproducibility.
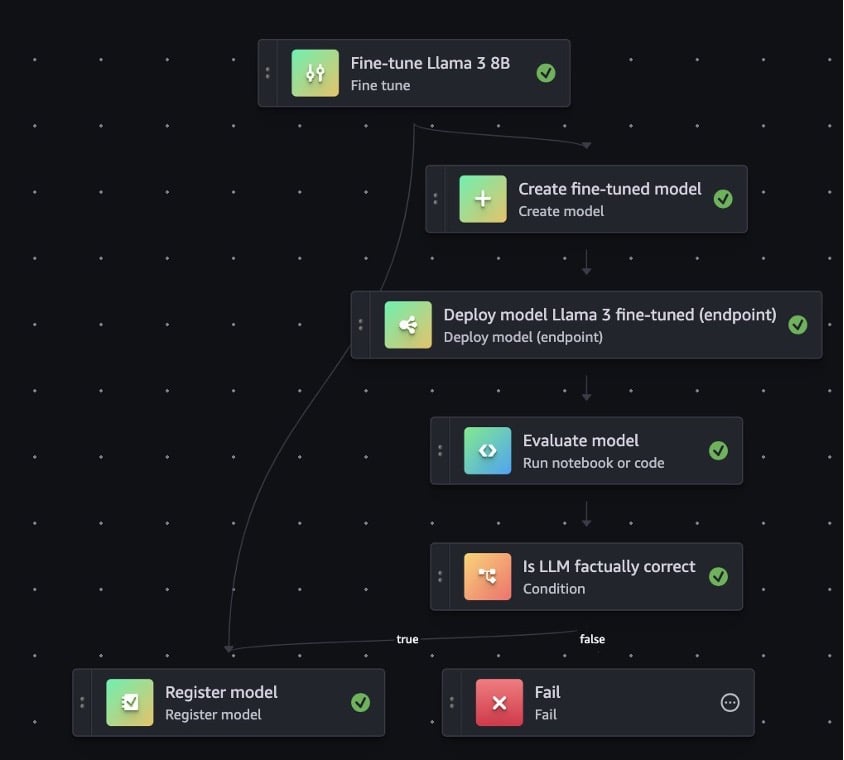
The SEC filings dataset is publicly available through an amazon SageMaker JumpStart bucket. Here’s an overview of the steps to create the pipeline.
- Fine tune a Meta Llama 3 8B model from SageMaker JumpStart using the SEC financial dataset.
- Prepare the fine-tuned Llama 3 8B model for deployment to SageMaker Inference.
- Deploy the fine-tuned Llama 3 8B model to SageMaker Inference.
- Evaluate the performance of the fine-tuned model using the open-source Foundation Model Evaluations (fmeval) library
- Use a condition step to determine if the fine-tuned model meets your desired performance. If it does, register the fine-tuned model to the SageMaker Model Registry. If the performance of the fine-tuned model falls below the desired threshold, then the pipeline execution fails.
Prerequisites
To build this solution, you need the following prerequisites:
- An AWS account that will contain all your AWS resources.
- An AWS Identity and Access Management (IAM) role to access SageMaker. To learn more about how IAM works with SageMaker, see Identity and Access Management for amazon SageMaker.
- Access to SageMaker Studio to access the SageMaker Pipelines visual editor. You first need to create a SageMaker domain and a user profile. See the Guide to getting set up with amazon SageMaker.
- An ml.g5.12xlarge instance for endpoint usage to deploy the model to, and an ml.g5.12xlarge training instance to fine-tune the model. You might need to request a quota increase; see Requesting a quota increase for more information.
Accessing the visual editor
Access the visual editor in the SageMaker Studio console by choosing Pipelines in the navigation pane, and then selecting Create in visual editor on the right. SageMaker pipelines are composed of a set of steps. You will see a list of step types that the visual editor supports.
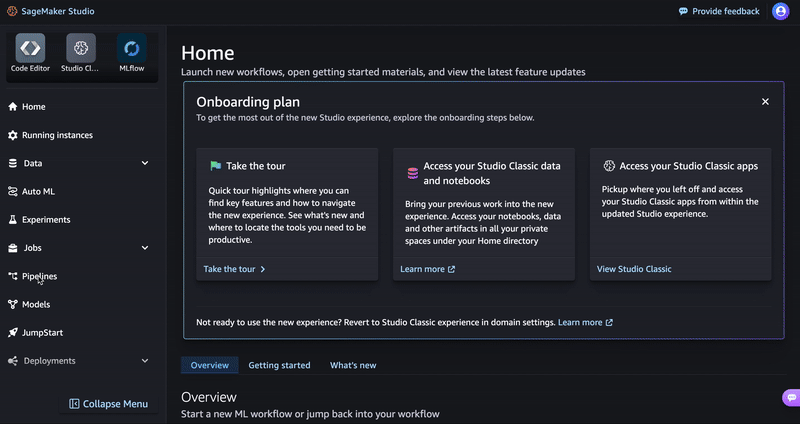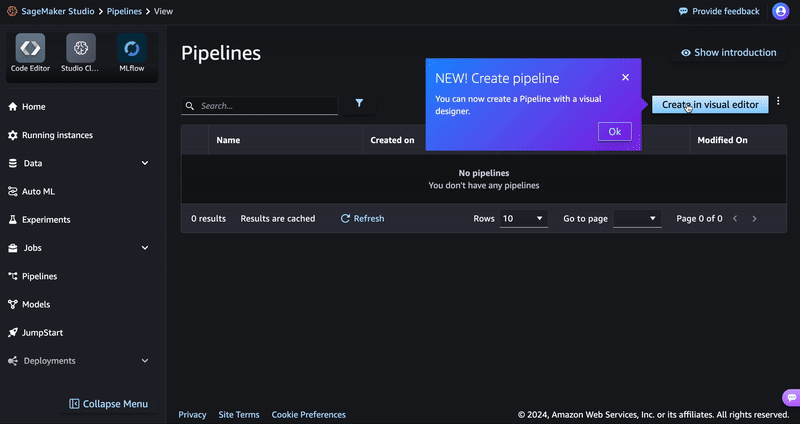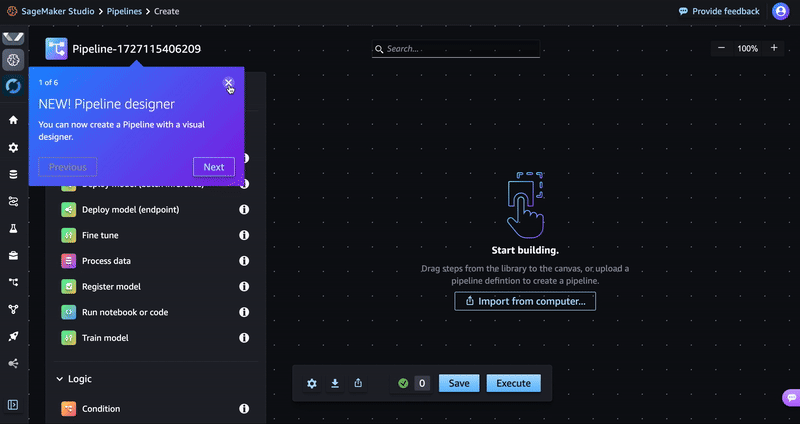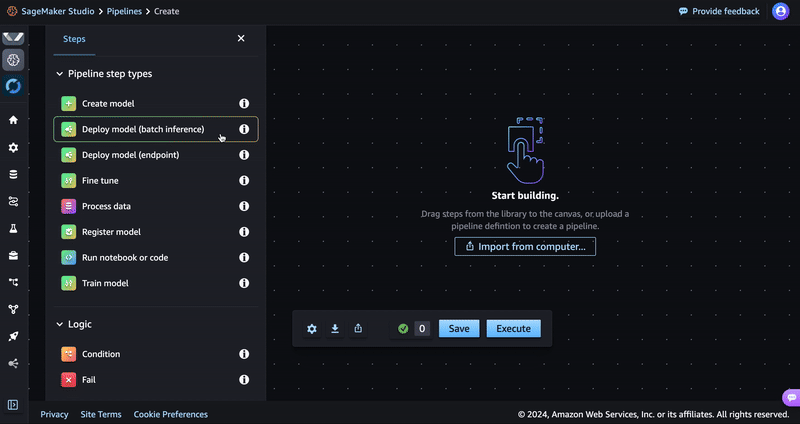
At any time while following this post, you can pause your pipeline building process, save your progress, and resume later. Download the pipeline definition as a JSON file to your local environment by choosing Export at the bottom of the visual editor. Later, you can resume building the pipeline by choosing Import button and re-uploading the JSON file.
Step #1: Fine tune the LLM
With the new editor, we introduce a convenient way to fine tune models from SageMaker JumpStart using the Fine tune step. To add the Fine tune step, drag it to the editor and then enter the following details:
- In the Model (input) section select Meta-Llama-3-8B. Scroll to the bottom of the window to accept the EULA and choose Save.
- The Model (output) section automatically populates the default amazon Simple Storage Service (amazon S3) You can update the S3 URI to change the location where the model artifacts will be stored.
- This example uses the default SEC dataset for training. You can also bring your own dataset by updating the Dataset (input)
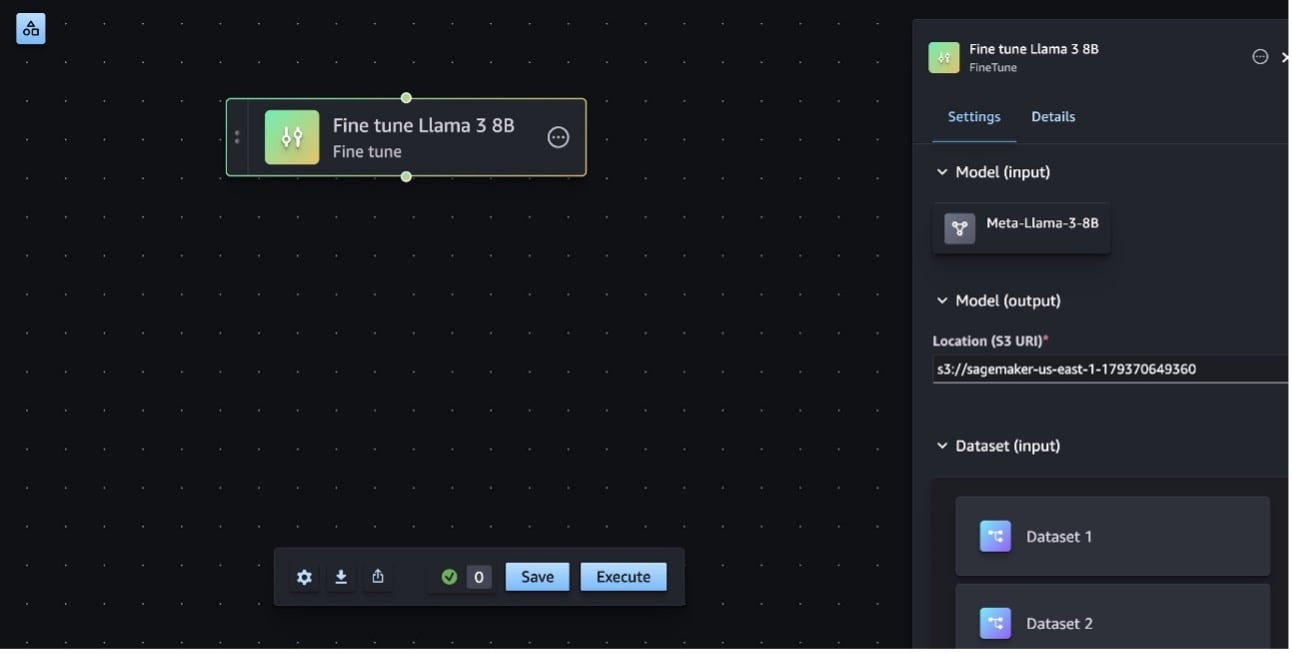
- Choose the ml.g5.12x.large instance.
- Leave the default hyperparameter settings. These can be adjusted depending on your use case.
- Optional) You can update the name of the step on the Details tab under Step display name. For this example, update the step name to Fine tune Llama 3 8B.
Step #2: Prepare the fine-tuned LLM for deployment
Before you deploy the model to an endpoint, you will create the model definition, which includes the model artifacts and Docker container needed to host the model.
- Drag the Create model step to the editor.
- Connect the Fine tune step to the Create model step using the visual editor.
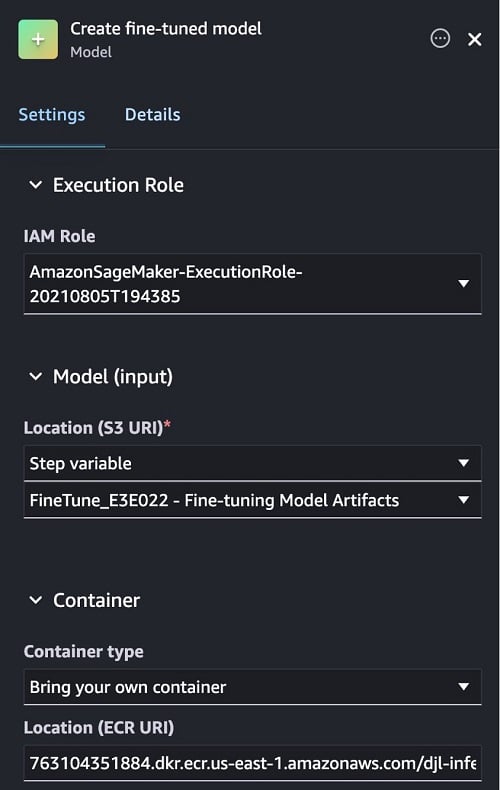
- Add the following details under the Settings tab:
- Choose an IAM role with the required permissions.
- Model (input):Step variable and Fine-tuning Model Artifacts.
- Container: Bring your own container and enter the image URI
dkr.ecr..amazonaws.com/djl-inference:0.28.0-lmi10.0.0-cu124(replace with your AWS Region) as the Location (ECR URI). This example uses a large model inference container. You can learn more about the deep learning containers that are available on GitHub.
Step #3: Deploy the fine-tuned LLM
Next, deploy the model to a real-time inference endpoint.
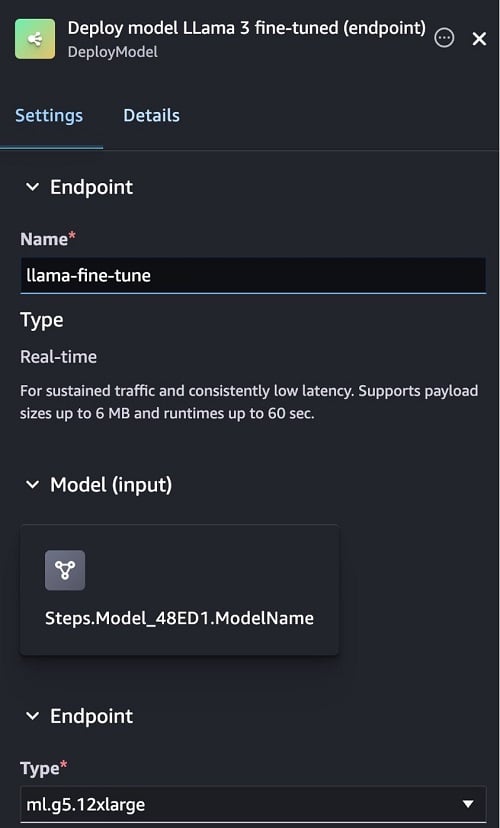
- Drag the Deploy model (endpoint) step to the editor.
- Enter a name such as llama-fine-tune for the endpoint name.
- Connect this step to the Create model step using the visual editor.
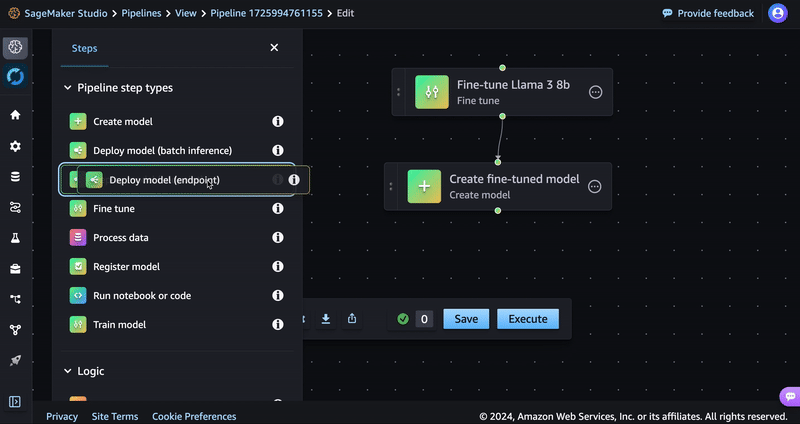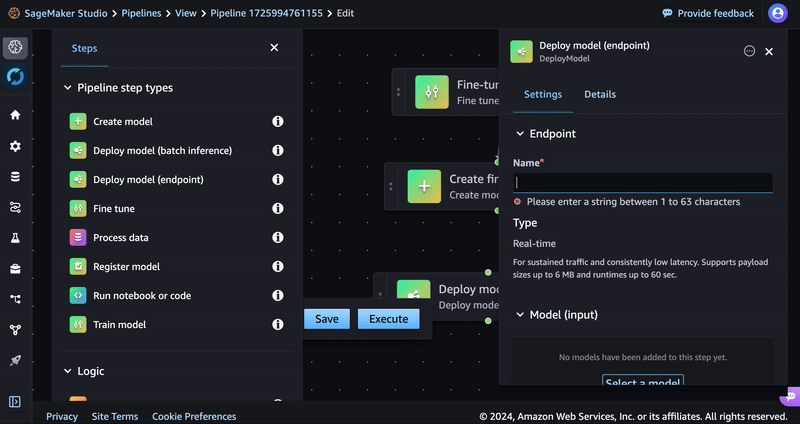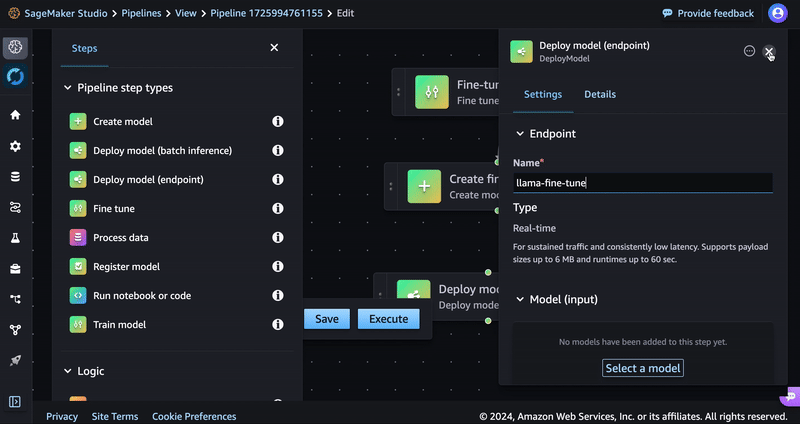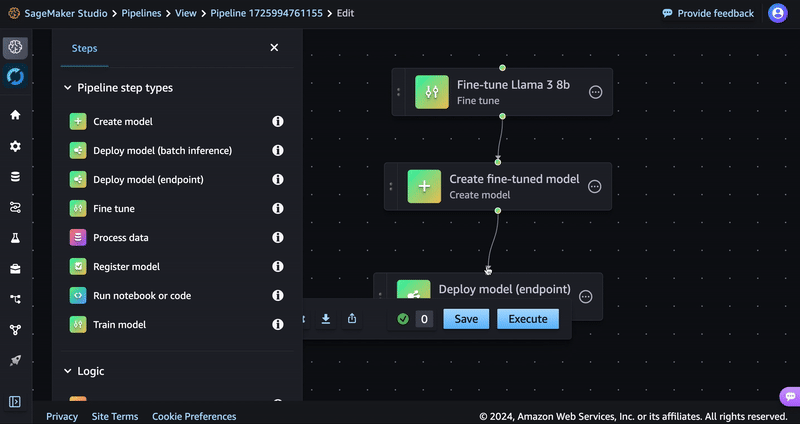
- In the Model (input) section, select Inherit model. Under Model name, select Step variable and the Model Name variable should be populated from the previous step. Choose Save.
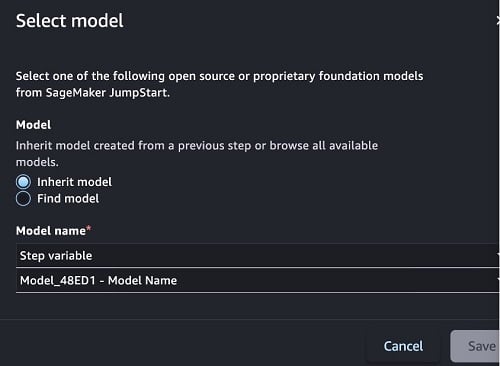
- Select g5.12xlarge instance as the Endpoint Type.
Step #4: Evaluate the fine-tuned LLM
After the LLM is customized and deployed on an endpoint, you want to evaluate its performance against real-world queries. To do this, you will use an Execute code step type that allows you to run the Python code that performs model evaluation using the factual knowledge evaluation from the fmeval library. The Execute code step type was introduced along with the new visual editor and provides three execution modes in which code can be run: Jupyter Notebooks, Python functions, and Shell or Python scripts. For more information about the Execute code step type, see the developer guide. In this example, you will use a Python function. The function will install the fmeval library, create a dataset to use for evaluation, and automatically test the model on its ability to reproduce facts about the real world.
Download the complete Python file, including the function and all imported libraries. The following are some code snippets of the model evaluation.
Define the LLM evaluation logic
Define a predictor to test your endpoint with a prompt:
Invoke your endpoint:
Generate a dataset:
Set up and run model evaluation using fmeval:
Upload the LLM evaluation logic
Drag a new Execute code (Run notebook or code) step onto the editor and update the display name to Evaluate model using the Details tab from the settings panel.
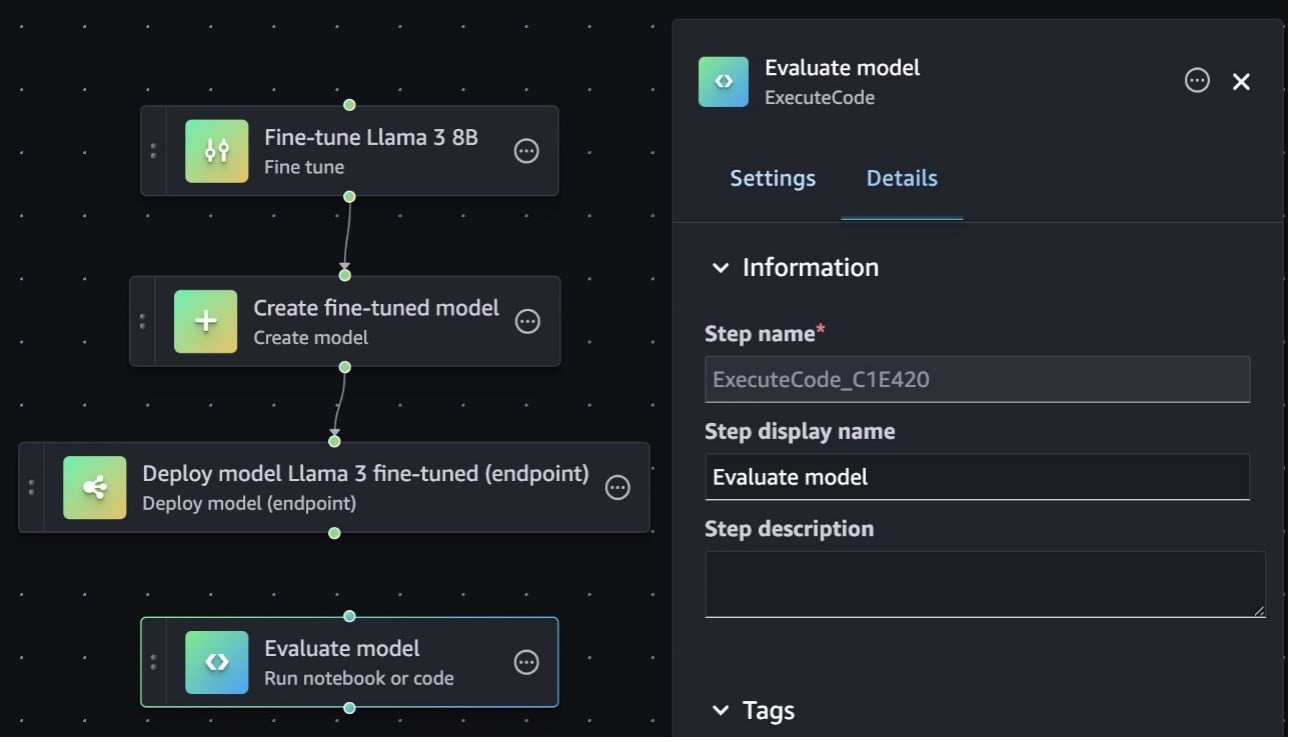
To configure the Execute code step settings, follow these steps in the Settings panel:
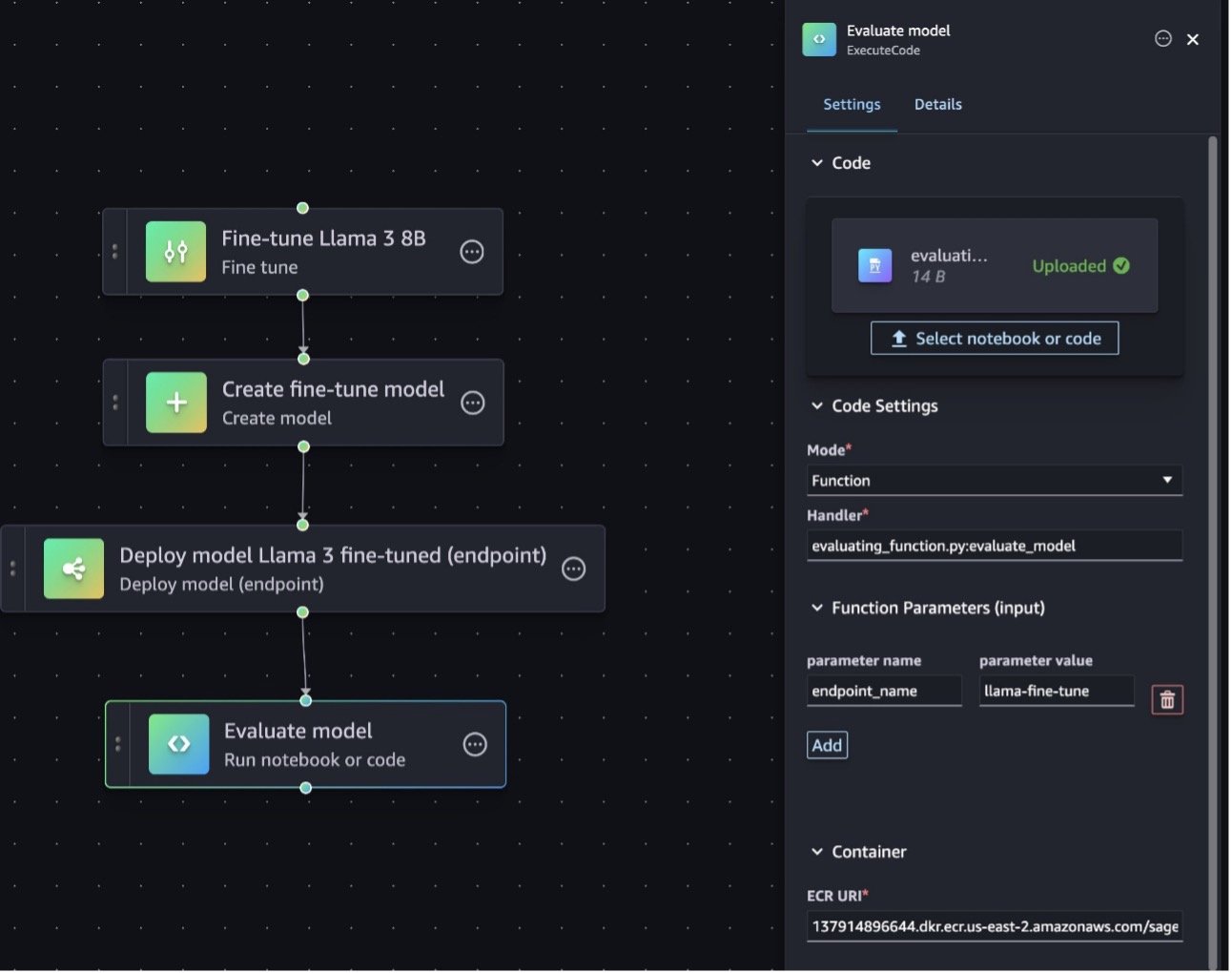
- Upload the python file py containing the function.
- Under Code Settings change the Mode to Function and update the Handler to
evaluating_function.py:evaluate_model. The handler input parameter is structured by putting the file name on the left side of the colon, and the handler function name on the right side:file_name.py:handler_function. - Add the
endpoint_nameparameter for your handler with the value of the endpoint created previously under Function Parameters (input); for example,llama-fine-tune. - Keep the default container and instance type settings.
After configuring this step, you connect the Deploy model (endpoint) step to the Execute code step using the visual editor.
Step #5: Condition step
After you execute the model evaluation code, you drag a Condition step to the editor. The condition step registers the fine-tuned model to a SageMaker Model Registry if the factual knowledge evaluation score exceeded the desired threshold. If the performance of the model was below the threshold, then the model isn’t added to the model registry and the pipeline execution fails.
- Update the Condition step name under the Details tab to Is LLM factually correct.
- Drag a Register model step and a Fail step to the editor as shown in the following GIF. You will not configure these steps until the next sections.
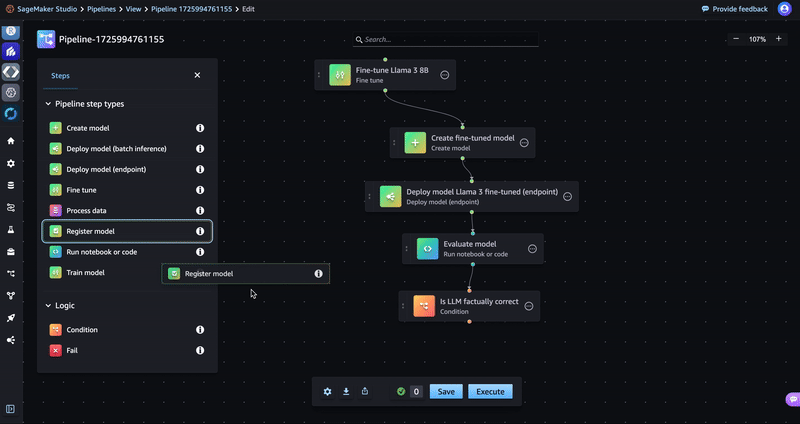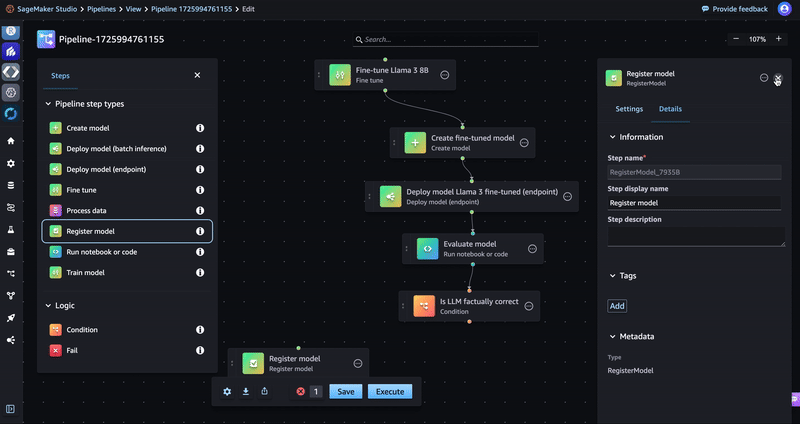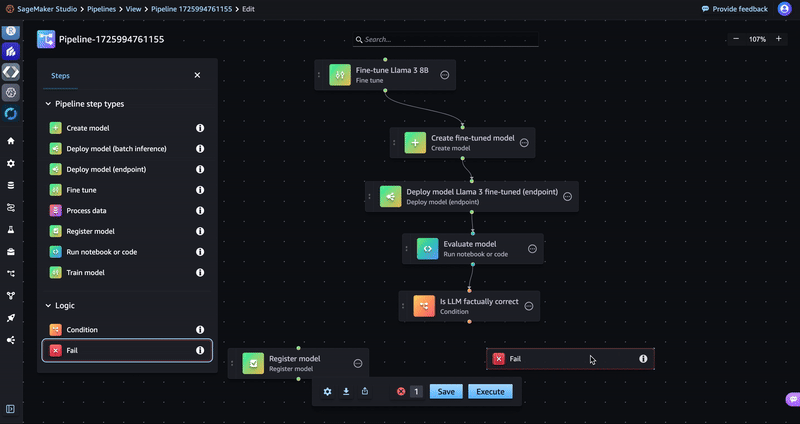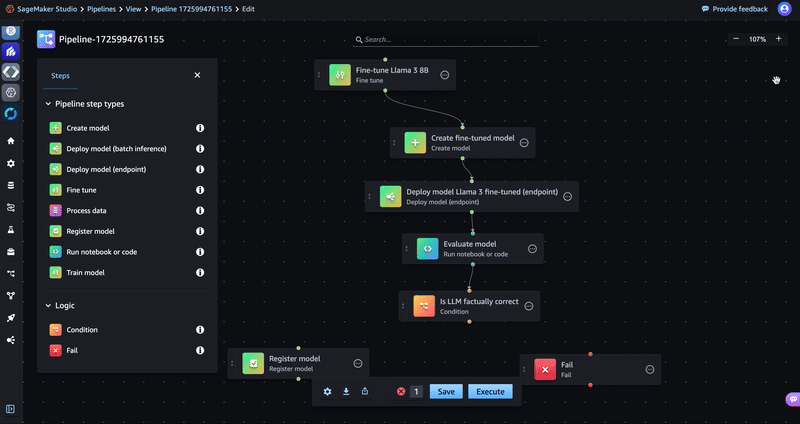
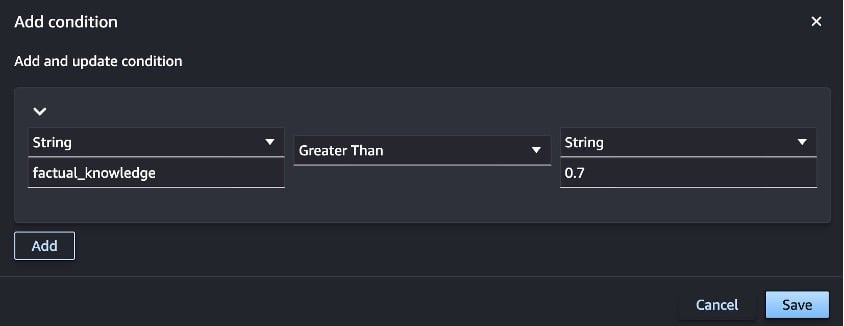
- Return to the Condition step and add a condition under Conditions (input).
- For the first String, enter factual_knowledge.
- Select Greater Than as the test.
- For the second String enter 7. The evaluation averages a single binary metric across every prompt in the dataset. For more information, see Factual Knowledge.
- In the Conditions (output) section, for Then (execute if true), select Register model, and for Else (execute if false), select Fail.
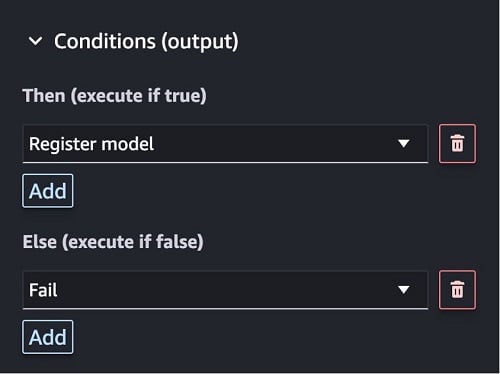
- After configuring this step, connect the Execute code step to the Condition step using the visual editor.
You will configure the Register model and Fail steps in the following sections.
Step #6: Register the model
To register your model to the SageMaker Model Registry, you need to configure the step to include the S3 URI of the model and the image URI.
- Return to the Register model step in the Pipelines visual editor that you created in the previous section and use the following steps to connect the Fine-tune step to the Register model This is required to inherit the model artifacts of the fine-tuned model.
- Select the step and choose Add under the Model (input)
- Enter the image URI dkr.ecr..amazonaws.com/djl-inference:0.28.0-lmi10.0.0-cu124(replace with your Region) in the Image field. For the Model URI field, select Step variable and Fine-tuning Model Artifacts. Choose Save.
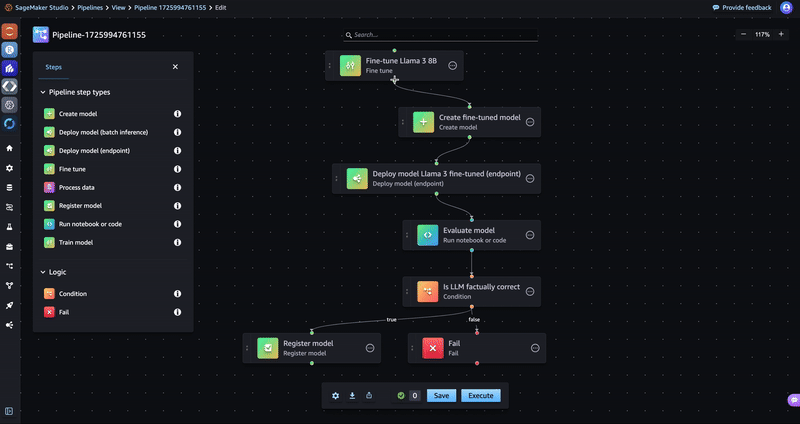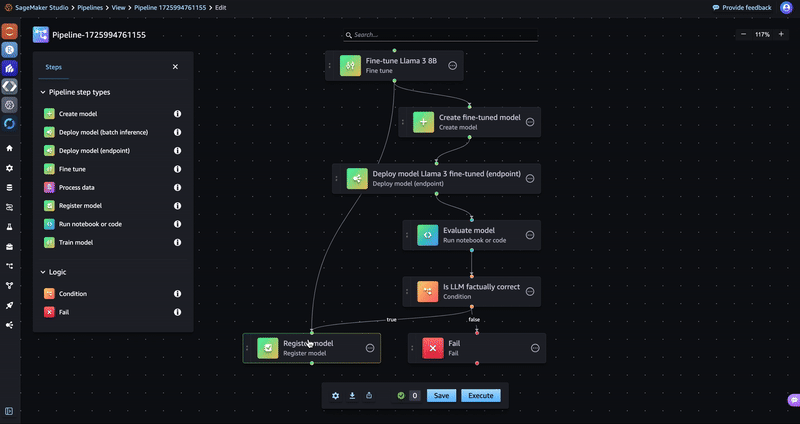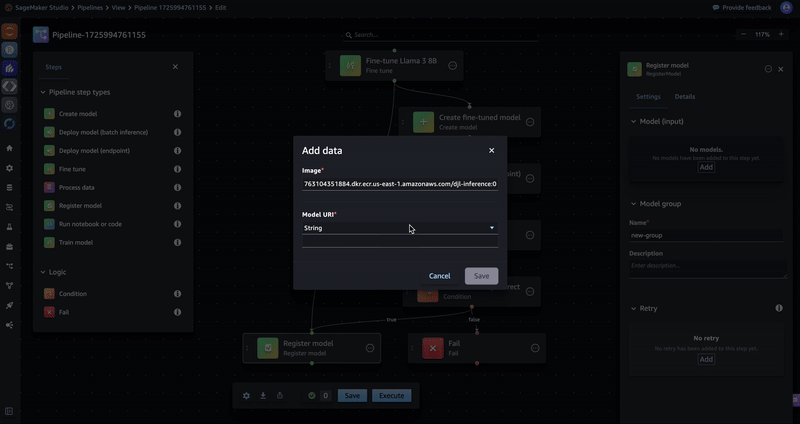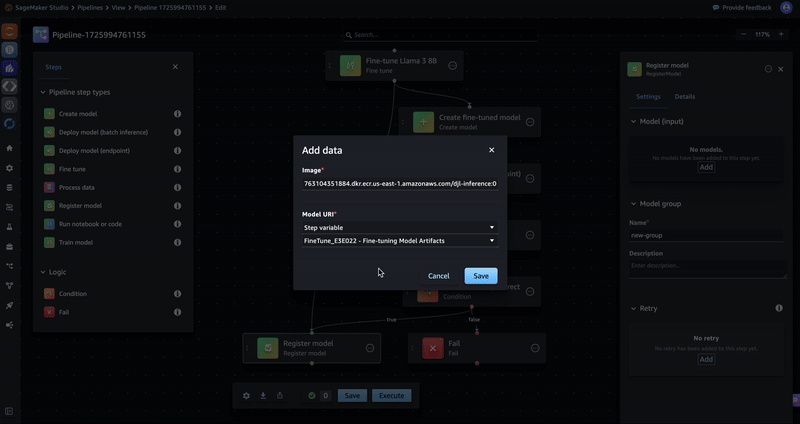
- Enter a name for the Model group.
Step #7: Fail step
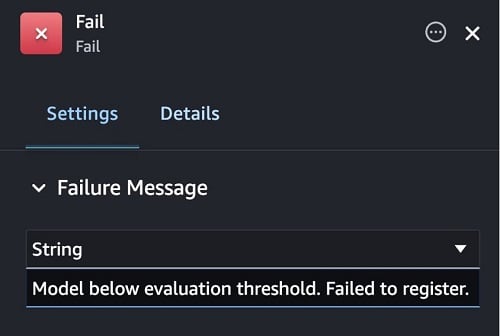
Select the Fail step on the canvas and enter a failure message to be displayed if the model fails to be registered to the model registry. For example: Model below evaluation threshold. Failed to register.
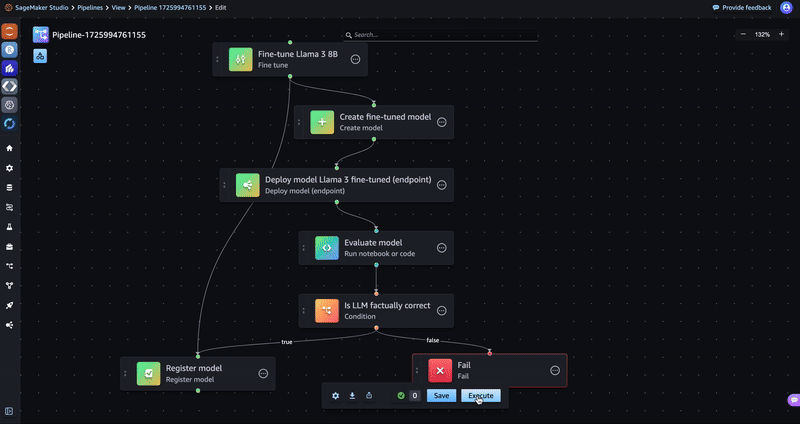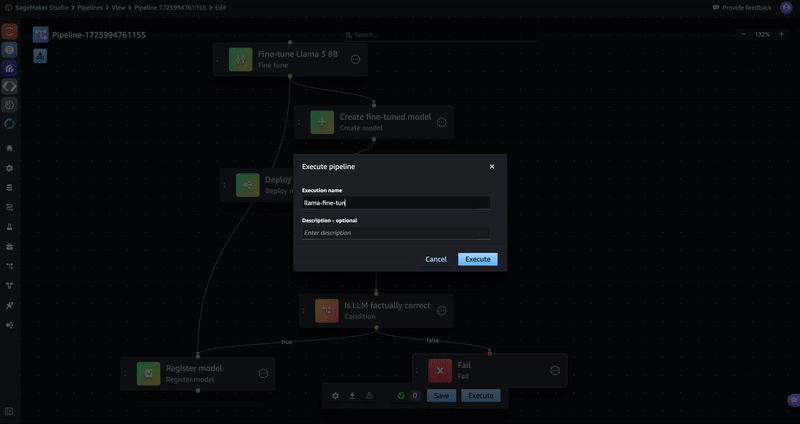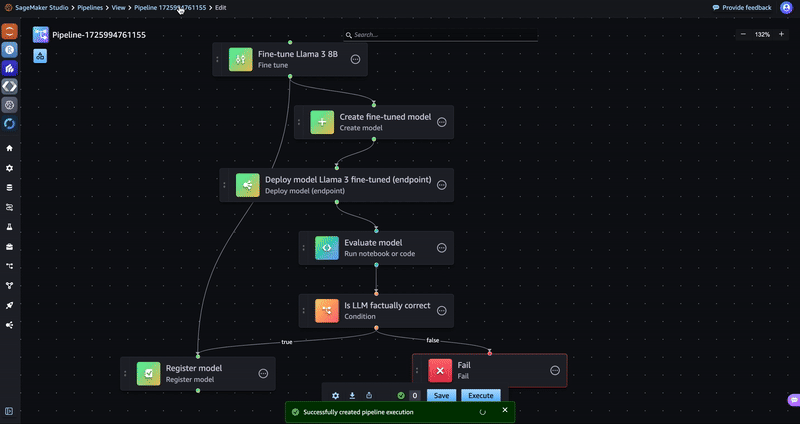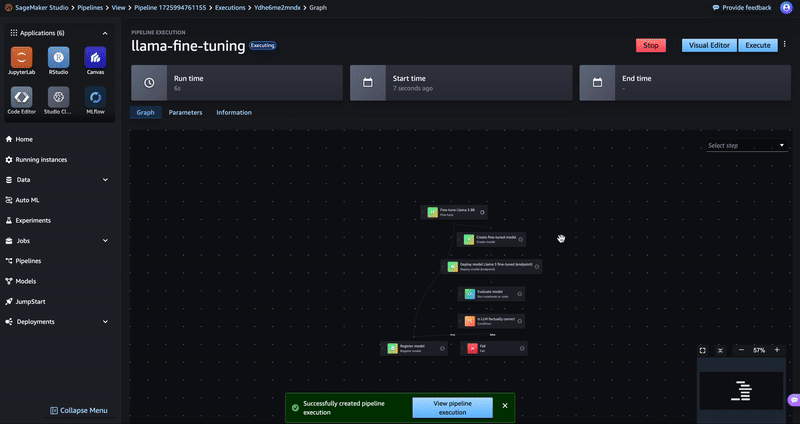
Save and execute the pipeline
Now that your pipeline has been constructed, choose Execute and enter a name for the execution to run the pipeline. You can then select the pipeline to view its progress. The pipeline will take 30–40 minutes to execute.
LLM customization at scale
In this example you executed the pipeline once manually from the UI. But by using the SageMaker APIs and SDK, you can trigger multiple concurrent executions of this pipeline with varying parameters (for example, different LLMs, different datasets, or different evaluation scripts) as part of your regular CI/CD processes. You don’t need to manage the capacity of the underlying infrastructure for SageMaker Pipelines because it automatically scales up or down based on the number of pipelines, number of steps in the pipelines, and number of pipeline executions in your AWS account. To learn more about the default scalability limits and request an increase in the performance of Pipelines, see the amazon SageMaker endpoints and quotas.
Clean up
Delete the SageMaker model endpoint to avoid incurring additional charges.
Conclusion
In this post, we walked you through a solution to fine-tune a Llama 3 model using the new visual editor for amazon SageMaker Pipelines. We introduced the fine-tuning step to fine-tune LLMs, and the Execute code step to run your own code in a pipeline step. The visual editor provides a user-friendly interface to create and manage ai/ML workflows. By using this capability, you can rapidly iterate on workflows before executing them at scale in production tens of thousands of times. For more information about this new feature, see Create and Manage Pipelines. Try it out and let us know your thoughts in the comments!
About the Authors
 Lauren Mullennex is a Senior ai/ML Specialist Solutions Architect at AWS. She has a decade of experience in DevOps, infrastructure, and ML. Her areas of focus include MLOps/LLMOps, generative ai, and computer vision.
Lauren Mullennex is a Senior ai/ML Specialist Solutions Architect at AWS. She has a decade of experience in DevOps, infrastructure, and ML. Her areas of focus include MLOps/LLMOps, generative ai, and computer vision.
 Brock Wade is a Software Engineer for amazon SageMaker. Brock builds solutions for MLOps, LLMOps, and generative ai, with experience spanning infrastructure, DevOps, cloud services, SDKs, and UIs.
Brock Wade is a Software Engineer for amazon SageMaker. Brock builds solutions for MLOps, LLMOps, and generative ai, with experience spanning infrastructure, DevOps, cloud services, SDKs, and UIs.
 Piyush Kadam is a Product Manager for amazon SageMaker, a fully managed service for generative ai builders. Piyush has extensive experience delivering products that help startups and enterprise customers harness the power of foundation models.
Piyush Kadam is a Product Manager for amazon SageMaker, a fully managed service for generative ai builders. Piyush has extensive experience delivering products that help startups and enterprise customers harness the power of foundation models.






{kind=link}