
Creating scalable and efficient machine learning (ML) pipelines is crucial for streamlining the development, deployment, and management of ML models. In this post, we present a framework for automating the creation of a directed acyclic graph (DAG) for Amazon SageMaker Pipelines based on simple configuration files. The framework code and examples presented here only cover model training pipelines, but can be readily extended to batch inference pipelines as well.
This dynamic framework uses configuration files to orchestrate preprocessing, training, evaluation, and registration steps for both single-model and multi-model use cases based on user-defined Python scripts, infrastructure needs (including Amazon Virtual Private Cloud (Amazon VPC) subnets and security groups, AWS Identity and Access Management (IAM) roles, AWS Key Management Service (AWS KMS) keys, containers registry, and instance types), input and output Amazon Simple Storage Service (Amazon S3) paths, and resource tags. Configuration files (YAML and JSON) allow ML practitioners to specify undifferentiated code for orchestrating training pipelines using declarative syntax. This enables data scientists to quickly build and iterate on ML models, and empowers ML engineers to run through continuous integration and continuous delivery (CI/CD) ML pipelines faster, decreasing time to production for models.
Solution overview
The proposed framework code starts by reading the configuration files. It then dynamically creates a SageMaker Pipelines DAG based on the steps declared in the configuration files and the interactions and dependencies among steps. This orchestration framework caters to both single-model and multi-model use cases, and provides a smooth flow of data and processes. The following are the key benefits of this solution:
- Automation – The entire ML workflow, from data preprocessing to model registry, is orchestrated with no manual intervention. This reduces the time and effort required for model experimentation and operationalization.
- Reproducibility – With a predefined configuration file, data scientists and ML engineers can reproduce the entire workflow, achieving consistent results across multiple runs and environments.
- Scalability – Amazon SageMaker is used throughout the pipeline, enabling ML practitioners to process large datasets and train complex models without infrastructure concerns.
- Flexibility – The framework is flexible and can accommodate a wide range of ML use cases, ML frameworks (such as XGBoost and TensorFlow), multi-model training, and multi-step training. Every step of the training DAG can be customized via the configuration file.
- Model governance – The Amazon SageMaker Model Registry integration allows for tracking model versions, and therefore promoting them to production with confidence.
The following architecture diagram depicts how you can use the proposed framework during both experimentation and operationalization of ML models. During experimentation, you can clone the framework code repository provided in this post and your project-specific source code repositories into Amazon SageMaker Studio, and set your virtual environment (detailed later in this post). You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices. To create and run a SageMaker Pipelines training DAG, you can call the framework’s entry point, which will read all the configuration files, create the necessary steps, and orchestrate them based on the specified step ordering and dependencies.
During operationalization, the CI pipeline clones the framework code repository and project-specific training repositories into an AWS CodeBuild job, where the framework’s entry point script is called to create or update the SageMaker Pipelines training DAG, and then run it.
Repository structure
The GitHub repository contains the following directories and files:
- /framework/conf/ – This directory contains a configuration file that is used to set common variables across all modeling units such as subnets, security groups, and IAM role at the runtime. A modeling unit is a sequence of up to six steps for training an ML model.
- /framework/createmodel/ – This directory contains a Python script that creates a SageMaker model object based on model artifacts from a SageMaker Pipelines training step. The model object is later used in a SageMaker batch transform job for evaluating model performance on a test set.
- /framework/modelmetrics/ – This directory contains a Python script that creates an Amazon SageMaker Processing job for generating a model metrics JSON report for a trained model based on results of a SageMaker batch transform job performed on test data.
- /framework/pipeline/ – This directory contains Python scripts that use Python classes defined in other framework directories to create or update a SageMaker Pipelines DAG based on the specified configurations. The model_unit.py script is used by pipeline_service.py to create one or more modeling units. Each modeling unit is a sequence of up to six steps for training an ML model: process, train, create model, transform, metrics, and register model. Configurations for each modeling unit should be specified in the model’s respective repository. The pipeline_service.py also sets dependencies among SageMaker Pipelines steps (how steps within and across modeling units are sequenced or chained) based on the sagemakerPipeline section, which should be defined in the configuration file of one of the model repositories (the anchor model). This allows you to override default dependencies inferred by SageMaker Pipelines. We discuss the configuration file structure later in this post.
- /framework/processing/ – This directory contains a Python script that creates a SageMaker Processing job based on the specified Docker image and entry point script.
- /framework/registermodel/ – This directory contains a Python script for registering a trained model along with its calculated metrics in SageMaker Model Registry.
- /framework/training/ – This directory contains a Python script that creates a SageMaker training job.
- /framework/transform/ – This directory contains a Python script that creates a SageMaker batch transform job. In the context of model training, this is used to calculate the performance metric of a trained model on test data.
- /framework/utilities/ – This directory contains utility scripts for reading and joining configuration files, as well as logging.
- /framework_entrypoint.py – This file is the entry point of the framework code. It calls a function defined in the /framework/pipeline/ directory to create or update a SageMaker Pipelines DAG and run it.
- /examples/ – This directory contains several examples of how you can use this automation framework to create simple and complex training DAGs.
- /env.env – This file allows you to set common variables such as subnets, security groups, and IAM role as environment variables.
- /requirements.txt – This file specifies Python libraries that are required for the framework code.
Prerequisites
You should have the following prerequisites before deploying this solution:
- An AWS account
- SageMaker Studio
- A SageMaker role with Amazon S3 read/write and AWS KMS encrypt/decrypt permissions
- An S3 bucket for storing data, scripts, and model artifacts
- Optionally, the AWS Command Line Interface (AWS CLI)
- Python3 (Python 3.7 or greater) and the following Python packages:
- Additional Python packages used in your custom scripts
Deploy the solution
Complete the following steps to deploy the solution:
- Organize your model training repository according to the following structure:
- Clone the framework code and your model source code from the Git repositories:
-
- Clone
dynamic-sagemaker-pipelines-frameworkrepo into a training directory. In the following code, we assume the training directory is calledaws-train: - Clone the model source code under the same directory. For multi-model training, repeat this step for as many models as you need to train.
- Clone
For single-model training, your directory should look like the following:
For multi-model training, your directory should look like the following:
- Set up the following environment variables. Asterisks indicate environment variables that are required; the rest are optional.
| Environment Variable | Description |
SMP_ACCOUNTID* |
AWS account where the SageMaker pipeline is run |
SMP_REGION* |
AWS Region where the SageMaker pipeline is run |
SMP_S3BUCKETNAME* |
S3 bucket name |
SMP_ROLE* |
SageMaker role |
SMP_MODEL_CONFIGPATH* |
Relative path of the of single-model or multi-model configuration files |
SMP_SUBNETS |
Subnet IDs for SageMaker networking configuration |
SMP_SECURITYGROUPS |
Security group IDs for SageMaker networking configuration |
For single-model use cases, SMP_MODEL_CONFIGPATH will be <MODEL-DIR>/conf/conf.yaml. For multi-model use cases, SMP_MODEL_CONFIGPATH will be */conf/conf.yaml, which allows you to find all conf.yaml files using Python’s glob module and combine them to form a global configuration file. During experimentation (local testing), you can specify environment variables inside the env.env file and then export them by running the following command in your terminal:
Note that the values of environment variables in env.env should be placed inside quotation marks (for example, SMP_REGION="us-east-1"). During operationalization, these environment variables should be set by the CI pipeline.
- Create and activate a virtual environment by running the following commands:
- Install the required Python packages by running the following command:
- Edit your model training
conf.yamlfiles. We discuss the configuration file structure in the next section. - From the terminal, call the framework’s entry point to create or update and run the SageMaker Pipeline training DAG:
- View and debug the SageMaker Pipelines run on the Pipelines tab of the SageMaker Studio UI.
Configuration file structure
There are two types of configuration files in the proposed solution: framework configuration and model configuration. In this section, we describe each in detail.
Framework configuration
The /framework/conf/conf.yaml file sets the variables that are common across all modeling units. This includes SMP_S3BUCKETNAME, SMP_ROLE, SMP_MODEL_CONFIGPATH, SMP_SUBNETS, SMP_SECURITYGROUPS, and SMP_MODELNAME. Refer to Step 3 of deployment instructions for descriptions of these variables and how to set them via environment variables.
Model configuration
For each model in the project, we need to specify the following in the <MODEL-DIR>/conf/conf.yaml file (asterisks indicate required sections; the rest are optional):
- /conf/models* – In this section, you can configure one or more modeling units. When the framework code is run, it will automatically read all configuration files during runtime and append them to the config tree. Theoretically, you can specify all modeling units in the same
conf.yamlfile, but it’s recommended to specify each modeling unit configuration in its respective directory or Git repository to minimize errors. The units are as follows:- {model-name}* – The name of the model.
- source_directory* – A common
source_dirpath to use for all steps within the modeling unit. - preprocess – This section specifies preprocessing parameters.
- train* – This section specifies training job parameters.
- transform* – This section specifies SageMaker Transform job parameters for making predictions on the test data.
- evaluate – This section specifies SageMaker Processing job parameters for generating a model metrics JSON report for the trained model.
- registry* – This section specifies parameters for registering the trained model in SageMaker Model Registry.
- /conf/sagemakerPipeline* – This section defines the SageMaker Pipelines flow, including dependencies among steps. For single-model use cases, this section is defined at the end of the configuration file. For multi-model use cases, the
sagemakerPipelinesection only needs to be defined in the configuration file of one of the models (any of the models). We refer to this model as the anchor model. The parameters are as follows:- pipelineName* – Name of the SageMaker pipeline.
- models* – Nested list of modeling units:
- {model-name}* – Model identifier, which should match a {model-name} identifier in the /conf/models section.
- steps* –
- step_name* – Step name to be displayed in the SageMaker Pipelines DAG.
- step_class* – (Union(Processing, Training, CreateModel, Transform, Metrics, RegisterModel))
- step_type* – This parameter is only required for preprocessing steps, for which it should be set to preprocess. This is needed to distinguish preprocess and evaluate steps, both of which have a
step_classof Processing. - enable_cache – ((Union(True, False))). This indicates whether to enable SageMaker Pipelines caching for this step.
- chain_input_source_step – ((list(step_name))). You can use this to set the channel outputs of another step as input to this step.
- chain_input_additional_prefix – This is only allowed for steps of the Transform
step_class, and can be used in conjunction withchain_input_source_stepparameter to pinpoint the file that should be used as the input to the transform step.
- steps* –
- {model-name}* – Model identifier, which should match a {model-name} identifier in the /conf/models section.
- dependencies – This section specifies the sequence in which the SageMaker Pipelines steps should be run. We have adapted the Apache Airflow notation for this section (for example,
{step_name} >> {step_name}). If this section is left blank, explicit dependencies specified by thechain_input_source_stepparameter or implicit dependencies define the SageMaker Pipelines DAG flow.
Note that we recommend having one training step per modeling unit. If multiple training steps are defined for a modeling unit, the subsequent steps implicitly take the last training step to create the model object, calculate metrics, and register the model. If you need to train multiple models, it’s recommended to create multiple modeling units.
Examples
In this section, we demonstrate three examples of ML model training DAGs created using the presented framework.
Single-model training: LightGBM
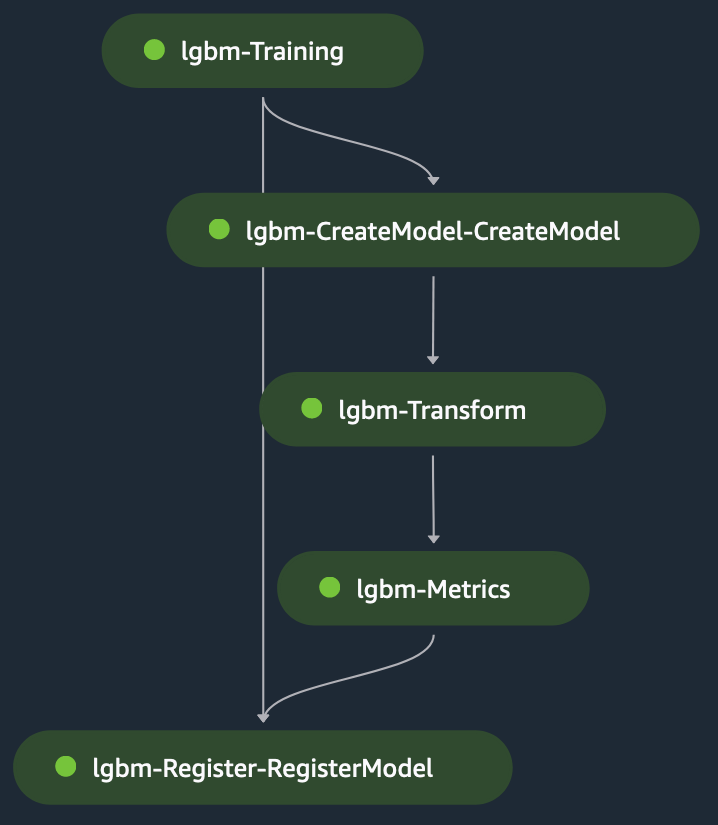
This is a single-model example for a classification use case where we use LightGBM in script mode on SageMaker. The dataset consists of categorical and numerical variables to predict the binary label Revenue (to predict if the subject makes a purchase or not). The preprocessing script is used to model the data for training and testing and then stage it in an S3 bucket. The S3 paths are then provided to the training step in the configuration file.
When the training step runs, SageMaker loads the file on the container at /opt/ml/input/data/{channelName}/, accessible via the environment variable SM_CHANNEL_{channelName} on the container (channelName= ‘train’ or ‘test’).The training script does the following:
- Load the files locally from local container paths using the NumPy load module.
- Set hyperparameters for the training algorithm.
- Save the trained model at the local container path
/opt/ml/model/.
SageMaker takes the content under /opt/ml/model/ to create a tarball that is used to deploy the model to SageMaker for hosting.
The transform step takes as input the staged test file as input and the trained model to make predictions on the trained model. The output of the transform step is chained to the metrics step to evaluate the model against the ground truth, which is explicitly supplied to the metrics step. Finally, the output of the metrics step is implicitly chained to the register step to register the model in SageMaker Model Registry with information about the model’s performance produced in the metrics step. The following figure shows a visual representation of the training DAG. You can refer to the scripts and configuration file for this example in the GitHub repo.
Single-model training: LLM fine-tuning
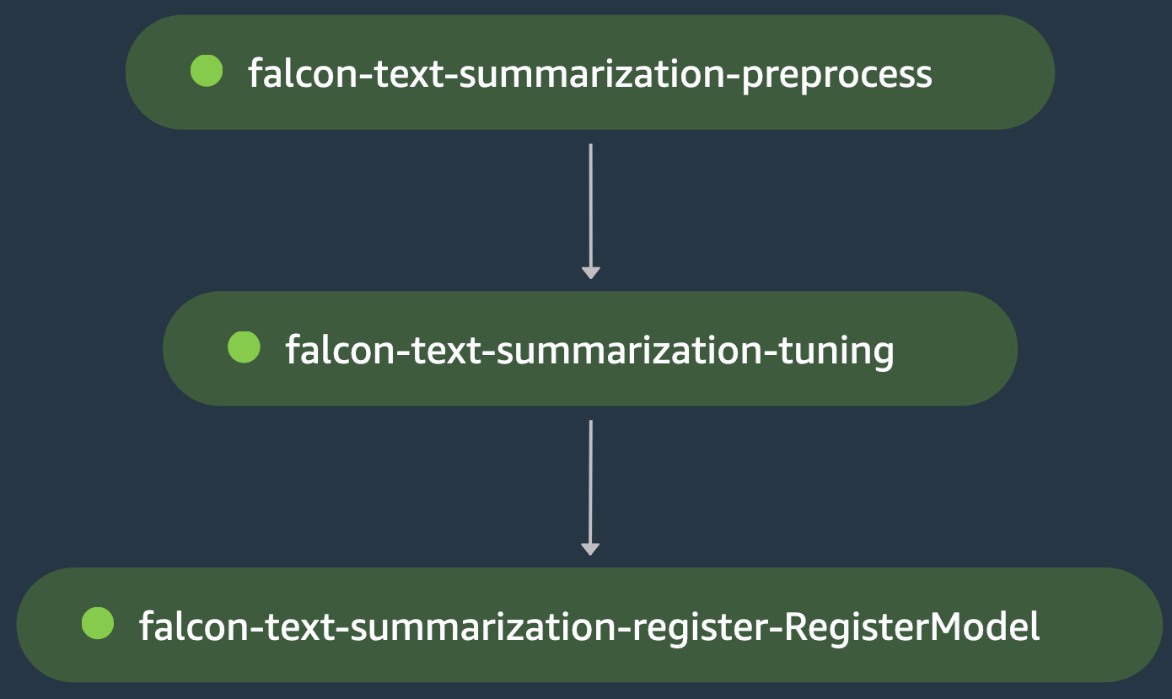
This is another single-model training example, where we orchestrate fine-tuning of a Falcon-40B large language model (LLM) from Hugging Face Hub for a text summarization use case. The preprocessing script loads the samsum dataset from Hugging Face, loads the tokenizer for the model, and processes the train/test data splits for fine-tuning the model on this domain data in the falcon-text-summarization-preprocess step.
The output is chained to the falcon-text-summarization-tuning step, where the training script loads the Falcon-40B LLM from Hugging Face Hub and starts accelerated fine-tuning using LoRA on the train split. The model is evaluated in the same step after fine-tuning, which gatekeeps the evaluation loss to fail the falcon-text-summarization-tuning step, which causes the SageMaker pipeline to stop before it is able to register the fine-tuned model. Otherwise, the falcon-text-summarization-tuning step runs successfully and the model is registered in SageMaker Model Registry. The following figure shows a visual representation of the LLM fine-tuning DAG. The scripts and configuration file for this example are available in the GitHub repo.
Multi-model training
This is a multi-model training example where a principal component analysis (PCA) model is trained for dimensionality reduction, and a TensorFlow Multilayer Perceptron model is trained for California Housing Price prediction. The TensorFlow model’s preprocessing step uses a trained PCA model to reduce dimensionality of its training data. We add a dependency in the configuration to ensure the TensorFlow model is registered after PCA model registration. The following figure shows a visual representation of the multi-model training DAG example. The scripts and configuration files for this example are available in the GitHub repo.

Clean up
Complete the following steps to clean up your resources:
- Use the AWS CLI to list and remove any remaining pipelines that are created by the Python scripts.
- Optionally, delete other AWS resources such as the S3 bucket or IAM role created outside SageMaker Pipelines.
Conclusion
In this post, we presented a framework for automating SageMaker Pipelines DAG creation based on configuration files. The proposed framework offers a forward-looking solution to the challenge of orchestrating complex ML workloads. By using a configuration file, SageMaker Pipelines provides the flexibility to build orchestration with minimal code, so you can streamline the process of creating and managing both single-model and multi-model pipelines. This approach not only saves time and resources, but also promotes MLOps best practices, contributing to the overall success of ML initiatives. For more information about implementation details, review the GitHub repo.
About the Authors
 Luis Felipe Yepez Barrios, is a Machine Learning Engineer with AWS Professional Services, focused on scalable distributed systems and automation tooling to expedite scientific innovation in the field of Machine Learning (ML). Furthermore, he assists enterprise clients in optimizing their machine learning solutions through AWS services.
Luis Felipe Yepez Barrios, is a Machine Learning Engineer with AWS Professional Services, focused on scalable distributed systems and automation tooling to expedite scientific innovation in the field of Machine Learning (ML). Furthermore, he assists enterprise clients in optimizing their machine learning solutions through AWS services.
 Jinzhao Feng, is a Machine Learning Engineer at AWS Professional Services. He focuses on architecting and implementing large scale Generative ai and classical ML pipeline solutions. He is specialized in FMOps, LLMOps and distributed training.
Jinzhao Feng, is a Machine Learning Engineer at AWS Professional Services. He focuses on architecting and implementing large scale Generative ai and classical ML pipeline solutions. He is specialized in FMOps, LLMOps and distributed training.
 Harsh Asnani, is a Machine Learning Engineer at AWS. His Background is in Applied Data Science with a focus on operationalizing Machine Learning workloads in the cloud at scale.
Harsh Asnani, is a Machine Learning Engineer at AWS. His Background is in Applied Data Science with a focus on operationalizing Machine Learning workloads in the cloud at scale.
 Hasan Shojaei, is a Sr. Data Scientist with AWS Professional Services, where he helps customers across different industries solve their business challenges through the use of big data, machine learning, and cloud technologies. Prior to this role, Hasan led multiple initiatives to develop novel physics-based and data-driven modeling techniques for top energy companies. Outside of work, Hasan is passionate about books, hiking, photography, and history.
Hasan Shojaei, is a Sr. Data Scientist with AWS Professional Services, where he helps customers across different industries solve their business challenges through the use of big data, machine learning, and cloud technologies. Prior to this role, Hasan led multiple initiatives to develop novel physics-based and data-driven modeling techniques for top energy companies. Outside of work, Hasan is passionate about books, hiking, photography, and history.
 Alec Jenab, is a Machine Learning Engineer who specializes in developing and operationalizing machine learning solutions at scale for enterprise customers. Alec is passionate about bringing innovative solutions to market, especially in areas where machine learning can meaningfully improve end user experience. Outside of work, he enjoys playing basketball, snowboarding, and discovering hidden gems in San Francisco.
Alec Jenab, is a Machine Learning Engineer who specializes in developing and operationalizing machine learning solutions at scale for enterprise customers. Alec is passionate about bringing innovative solutions to market, especially in areas where machine learning can meaningfully improve end user experience. Outside of work, he enjoys playing basketball, snowboarding, and discovering hidden gems in San Francisco.






{kind=link}