 NEWSLETTER
NEWSLETTER
Hoy, Amazon SageMaker lanza una nueva versión (0.25.0) de contenedores de aprendizaje profundo (DLC) de inferencia de modelos grandes (LMI) y agrega soporte para Biblioteca TensorRT-LLM de NVIDIA. Con estas actualizaciones, puede acceder sin esfuerzo a herramientas de última generación para optimizar modelos de lenguajes grandes (LLM) en SageMaker y lograr beneficios de precio-rendimiento. El DLC Amazon SageMaker LMI TensorRT-LLM reduce la latencia en un 33 % en promedio y mejora el rendimiento en un 60 % en promedio para los modelos Llama2-70B, Falcon-40B y CodeLlama-34B, en comparación con la versión anterior.
Los LLM han experimentado un crecimiento sin precedentes en popularidad en un amplio espectro de aplicaciones. Sin embargo, estos modelos suelen ser demasiado grandes para caber en un solo acelerador o dispositivo GPU, lo que dificulta lograr una inferencia y escala de baja latencia. SageMaker ofrece DLC de LMI para ayudarlo a maximizar la utilización de los recursos disponibles y mejorar el rendimiento. Los últimos DLC de LMI ofrecen soporte de procesamiento por lotes continuo para solicitudes de inferencia para mejorar el rendimiento, operaciones colectivas de inferencia eficientes para mejorar la latencia, Paged Attention V2 (que mejora el rendimiento de cargas de trabajo con longitudes de secuencia más largas) y la última biblioteca TensorRT-LLM de NVIDIA para maximizar Rendimiento en GPU. Los DLC LMI ofrecen una interfaz de bajo código que simplifica la compilación con TensorRT-LLM simplemente solicitando el ID del modelo y los parámetros del modelo opcionales; Todo el trabajo pesado necesario para construir un modelo optimizado para TensorRT-LLM y crear un repositorio de modelos es administrado por el DLC de LMI. Además, puede utilizar las últimas técnicas de cuantificación (GPTQ, AWQ y SmoothQuant) que están disponibles con los DLC LMI. Como resultado, con los DLC de LMI en SageMaker, puede acelerar el tiempo de obtención de valor para sus aplicaciones de IA generativa y optimizar los LLM para el hardware de su elección para lograr la mejor relación precio-rendimiento de su clase.
En esta publicación, profundizamos en las nuevas funciones con la última versión de LMI DLC, analizamos los puntos de referencia de rendimiento y describimos los pasos necesarios para implementar LLM con LMI DLC para maximizar el rendimiento y reducir costos.
Nuevas funciones con los DLC de SageMaker LMI
En esta sección, analizamos tres funciones nuevas de los DLC LMI de SageMaker.
SageMaker LMI ahora es compatible con TensorRT-LLM
SageMaker ahora ofrece TensorRT-LLM de NVIDIA como parte de la última versión de DLC de LMI (0.25.0), lo que permite optimizaciones de última generación como SmoothQuant, FP8 y procesamiento por lotes continuo para LLM cuando se utilizan GPU de NVIDIA. TensorRT-LLM abre la puerta a experiencias de latencia ultrabaja que pueden mejorar enormemente el rendimiento. El SDK de TensorRT-LLM admite implementaciones que van desde configuraciones de una sola GPU hasta configuraciones de múltiples GPU, con posibles ganancias de rendimiento adicionales a través de técnicas como el paralelismo tensorial. Para usar la biblioteca TensorRT-LLM, elija el DLC TensorRT-LLM de los DLC LMI disponibles y configure engine=MPI entre otros escenarios como option.model_id. El siguiente diagrama ilustra la pila tecnológica de TensorRT-LLM.
Operaciones colectivas de inferencia eficientes.
En una implementación típica de LLM, los parámetros del modelo se distribuyen en varios aceleradores para adaptarse a los requisitos de un modelo grande que no cabe en un solo acelerador. Esto mejora la velocidad de inferencia al permitir que cada acelerador realice cálculos parciales en paralelo. Posteriormente se introduce una operación colectiva para consolidar estos resultados parciales al final de estos procesos y redistribuirlos entre las aceleradoras.
Para los tipos de instancias P4D, SageMaker implementa una nueva operación colectiva que acelera la comunicación entre GPU. Como resultado, obtiene una latencia más baja y un mayor rendimiento con los últimos DLC de LMI en comparación con las versiones anteriores. Además, esta función es compatible de fábrica con los DLC de LMI y no necesita configurar nada para usarla porque está integrada en los DLC de LMI de SageMaker y está disponible exclusivamente para Amazon SageMaker.
Soporte de cuantificación
Los DLC LMI de SageMaker ahora admiten las últimas técnicas de cuantificación, incluidos modelos precuantizados con GPTQ, cuantificación de peso con reconocimiento de activación (AWQ) y cuantificación justo a tiempo como SmoothQuant.
GPTQ permite a LMI ejecutar modelos populares INT3 e INT4 de Hugging Face. Ofrece los pesos de modelo más pequeños posibles que caben en una sola GPU/multi-GPU. Los DLC LMI también admiten la inferencia AWQ, lo que permite una velocidad de inferencia más rápida. Finalmente, los DLC LMI ahora admiten SmoothQuant, que permite que la cuantificación INT8 reduzca la huella de memoria y el costo computacional de los modelos con una pérdida mínima de precisión. Actualmente, le permitimos realizar conversiones justo a tiempo para modelos SmoothQuant sin ningún paso adicional. GPTQ y AWQ deben cuantificarse con un conjunto de datos para usarse con DLC LMI. También puede adquirir modelos GPTQ y AWQ precuantizados populares para usar en DLC LMI. Para utilizar SmoothQuant, configure option.quantize=smoothquant con engine=DeepSpeed en serving.properties. Un cuaderno de muestra que utiliza SmoothQuant para alojar GPT-Neox en ml.g5.12xlarge se encuentra en GitHub.
Uso de DLC de SageMaker LMI
Puede implementar sus LLM en SageMaker utilizando los nuevos LMI DLC 0.25.0 sin ningún cambio en su código. Los DLC LMI de SageMaker utilizan el servicio DJL para servir su modelo para realizar inferencias. Para comenzar, solo necesita crear un archivo de configuración que especifique configuraciones como la paralelización de modelos y las bibliotecas de optimización de inferencias que se utilizarán. Para obtener instrucciones y tutoriales sobre el uso de los DLC de SageMaker LMI, consulte Paralelismo de modelos e inferencia de modelos grandes y nuestra lista de DLC de SageMaker LMI disponibles.
El contenedor DeepSpeed incluye una biblioteca llamada LMI Distributed Inference Library (LMI-Dist). LMI-Dist es una biblioteca de inferencia que se utiliza para ejecutar inferencia de modelos grandes con la mejor optimización utilizada en diferentes bibliotecas de código abierto, en los marcos vLLM, Text-Generation-Inference (hasta la versión 0.9.4), FasterTransformer y DeepSpeed. Esta biblioteca incorpora tecnologías populares de código abierto como FlashAttention, PagedAttention, FusedKernel y núcleos de comunicación GPU eficientes para acelerar el modelo y reducir el consumo de memoria.
TensorRT LLM es una biblioteca de código abierto lanzada por NVIDIA en octubre de 2023. Optimizamos la biblioteca TensorRT-LLM para acelerar la inferencia y creamos un conjunto de herramientas para simplificar la experiencia del usuario al admitir la conversión de modelos justo a tiempo. Este kit de herramientas permite a los usuarios proporcionar una ID de modelo de Hugging Face e implementar el modelo de un extremo a otro. También admite procesamiento por lotes continuo con transmisión. Puede esperar aproximadamente entre 1 y 2 minutos para compilar los modelos Llama-2 7B y 13B, y alrededor de 7 minutos para el modelo 70B. Si desea evitar esta sobrecarga de compilación durante la configuración del punto final de SageMaker y el escalado de instancias, le recomendamos utilizar la compilación anticipada (AOT) con nuestro ai/docs/serving/serving/docs/lmi/tutorials/trtllm_aot_tutorial.html”>tutorial para preparar el modelo. También aceptamos cualquier modelo de TensorRT LLM creado para Triton Server que pueda usarse con LMI DLC.
Resultados de la evaluación comparativa de rendimiento
Comparamos el rendimiento de la última versión de DLC de SageMaker LMI (0.25.0) con la versión anterior (0.23.0). Realizamos experimentos en los modelos Llama-2 70B, Falcon 40B y CodeLlama 34B para demostrar la ganancia de rendimiento con TensorRT-LLM y operaciones colectivas de inferencia eficientes (disponibles en SageMaker).
Los contenedores LMI de SageMaker vienen con un script de controlador predeterminado para cargar y alojar modelos, lo que proporciona una opción de código bajo. También tiene la opción de traer su propio script si necesita realizar alguna personalización en los pasos de carga del modelo. Debe pasar los parámetros requeridos en un serving.properties archivo. Este archivo contiene las configuraciones necesarias para que el servidor de modelos Deep Java Library (DJL) descargue y aloje el modelo. El siguiente código es el serving.properties utilizado para nuestra implementación y evaluación comparativa:
El engine El parámetro se utiliza para definir el motor de ejecución para el servidor modelo DJL. Podemos especificar el ID del modelo de Hugging Face o la ubicación del servicio de almacenamiento simple de Amazon (Amazon S3) del modelo utilizando el model_id parámetro. El parámetro de tarea se utiliza para definir la tarea de procesamiento del lenguaje natural (NLP). El tensor_parallel_degree El parámetro establece el número de dispositivos sobre los cuales se distribuyen los módulos tensores paralelos. El use_custom_all_reduce El parámetro se establece en verdadero para las instancias de GPU que tienen NVLink habilitado para acelerar la inferencia del modelo. Puede configurar esto para P4D, P4de, P5 y otras GPU que tengan NVLink conectado. El output_formatter El parámetro establece el formato de salida. El max_rolling_batch_size El parámetro establece el límite para el número máximo de solicitudes simultáneas. El model_loading_timeout establece el valor de tiempo de espera para descargar y cargar el modelo para realizar inferencias. Para obtener más detalles sobre las opciones de configuración, consulte Configuraciones y ajustes.
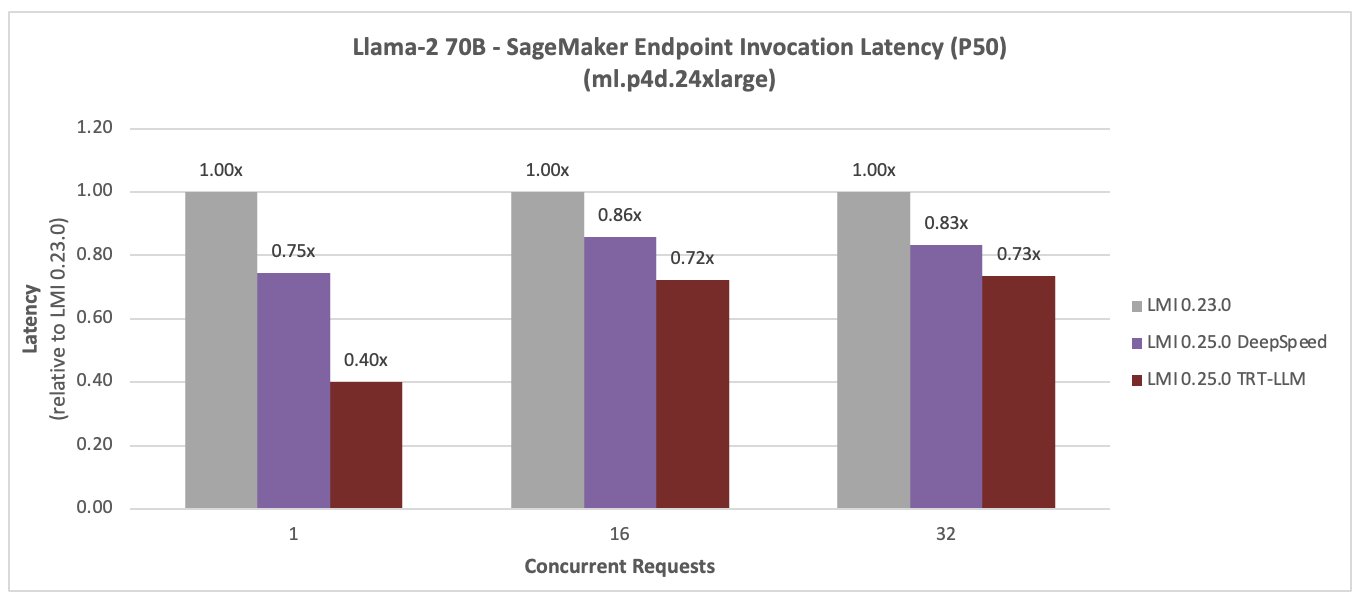
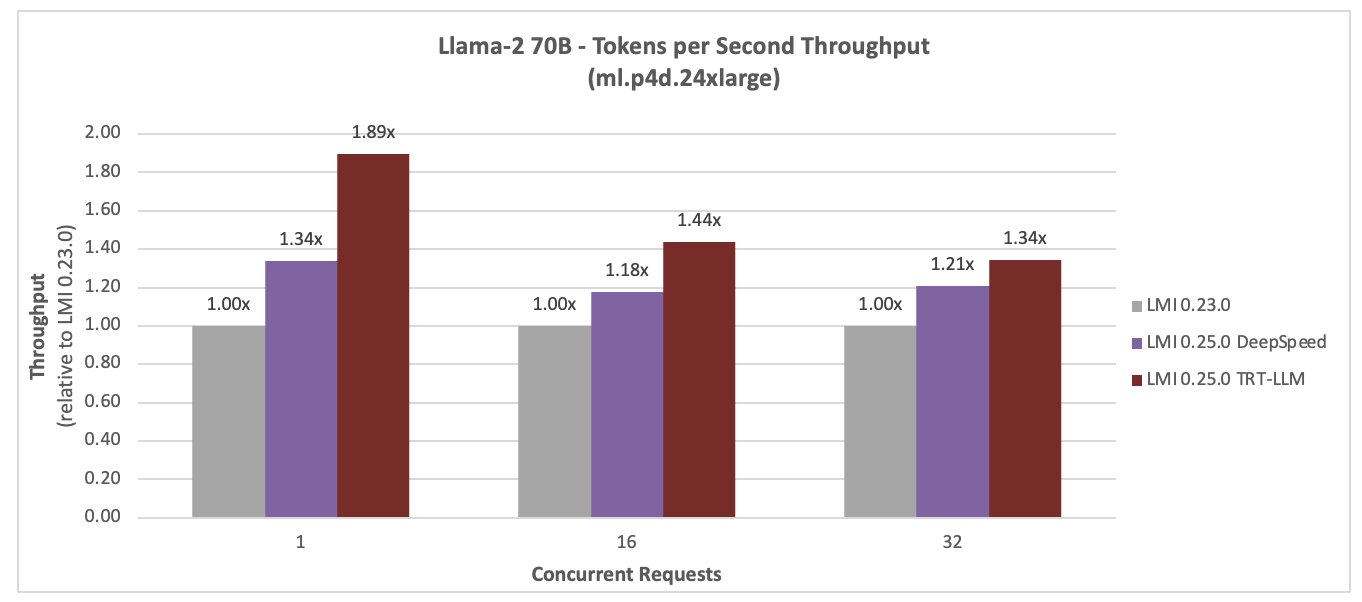
Llama-2 70B
Los siguientes son los resultados de la comparación de rendimiento de Llama-2 70B. La latencia se redujo en un 28 % y el rendimiento aumentó en un 44 % para una simultaneidad de 16, con el nuevo DLC LMI TensorRT LLM.
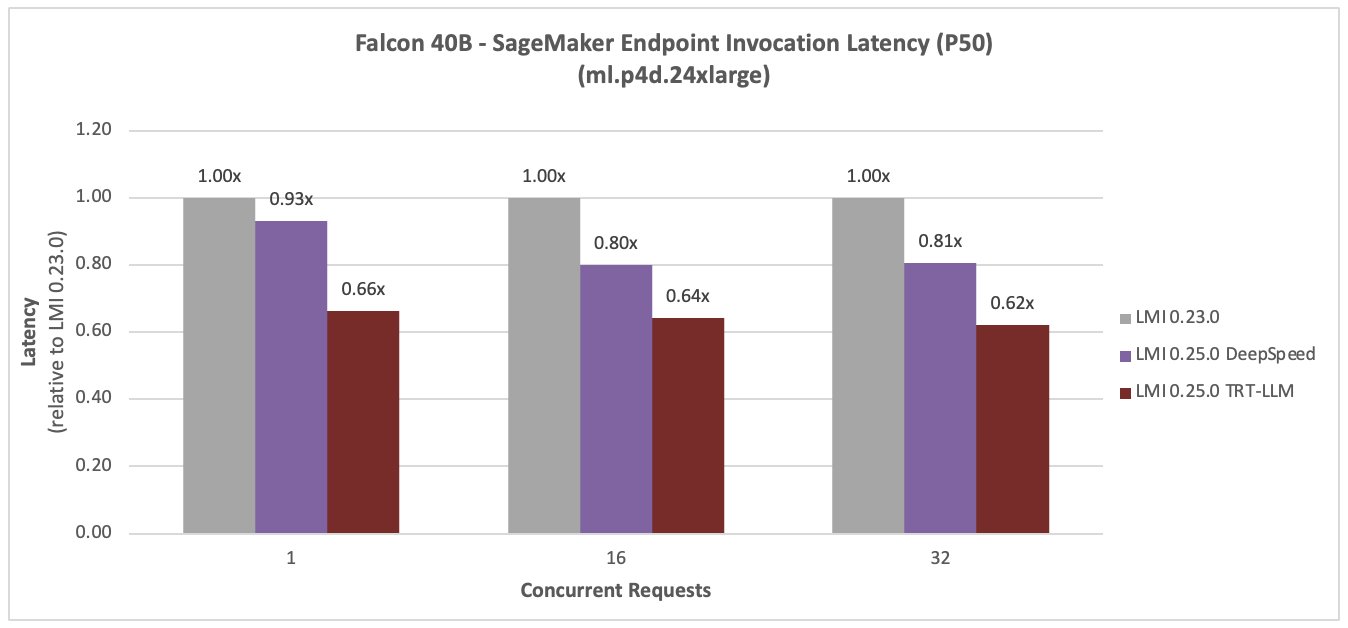
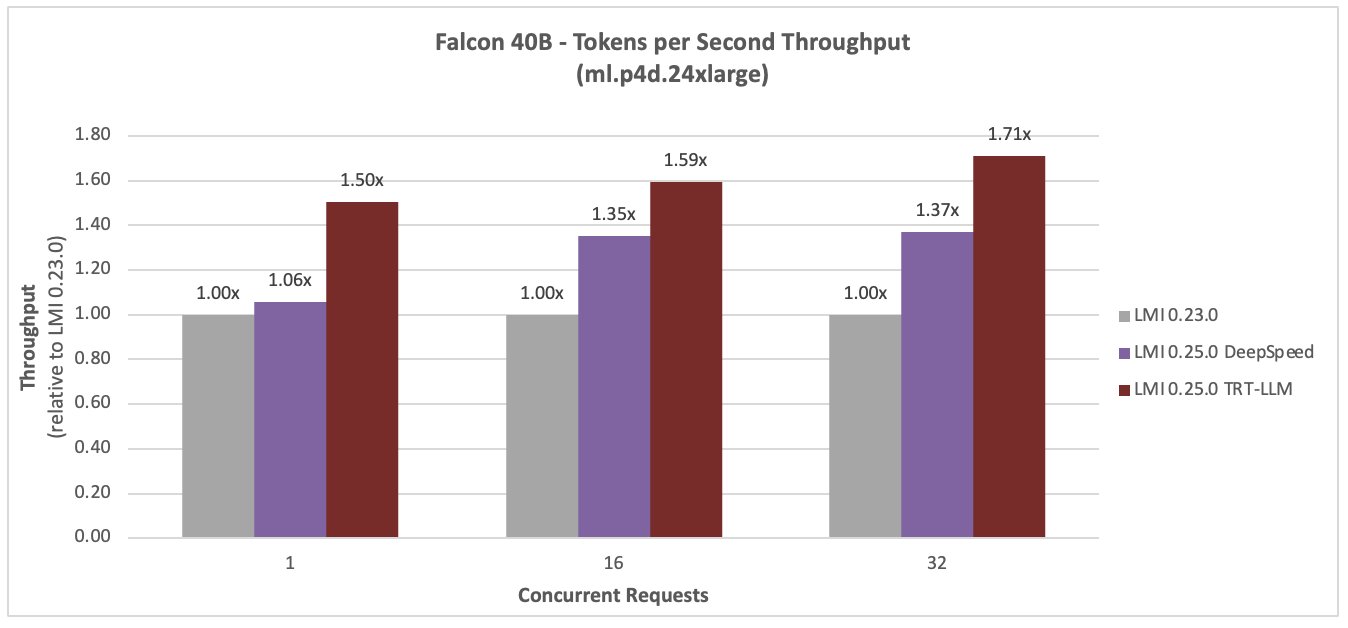
Halcón 40B
Las siguientes figuras comparan el Falcon 40B. La latencia se redujo en un 36 % y el rendimiento aumentó en un 59 % para una simultaneidad de 16, con el nuevo DLC LMI TensorRT LLM.
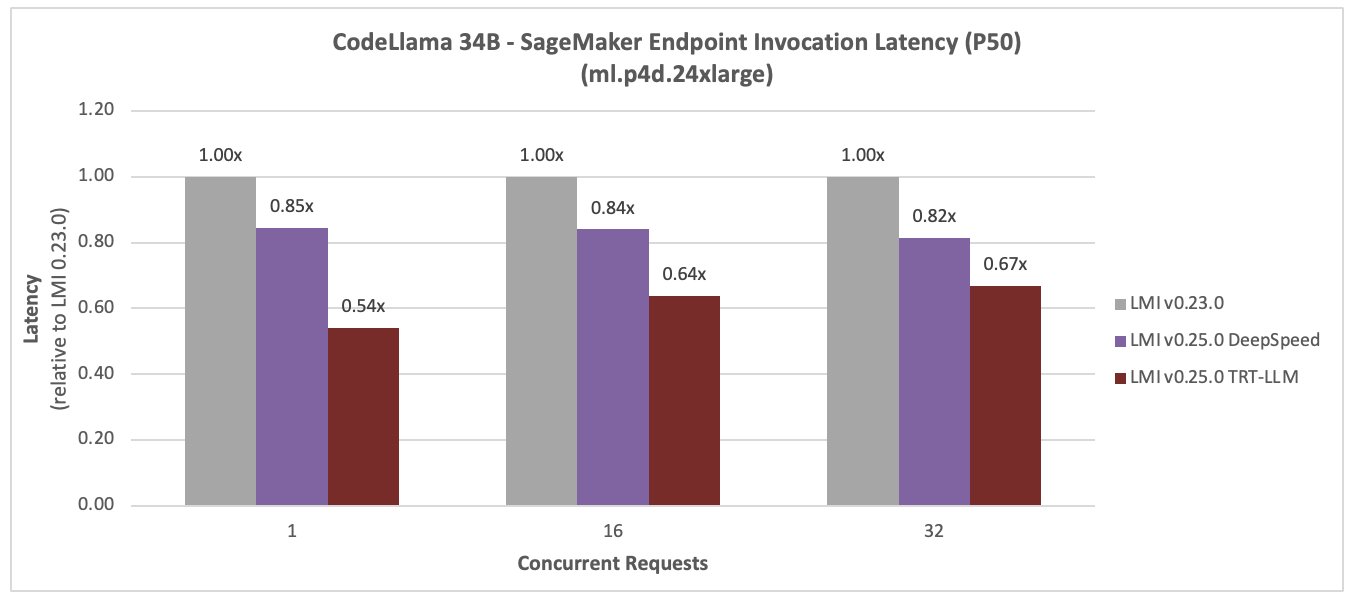
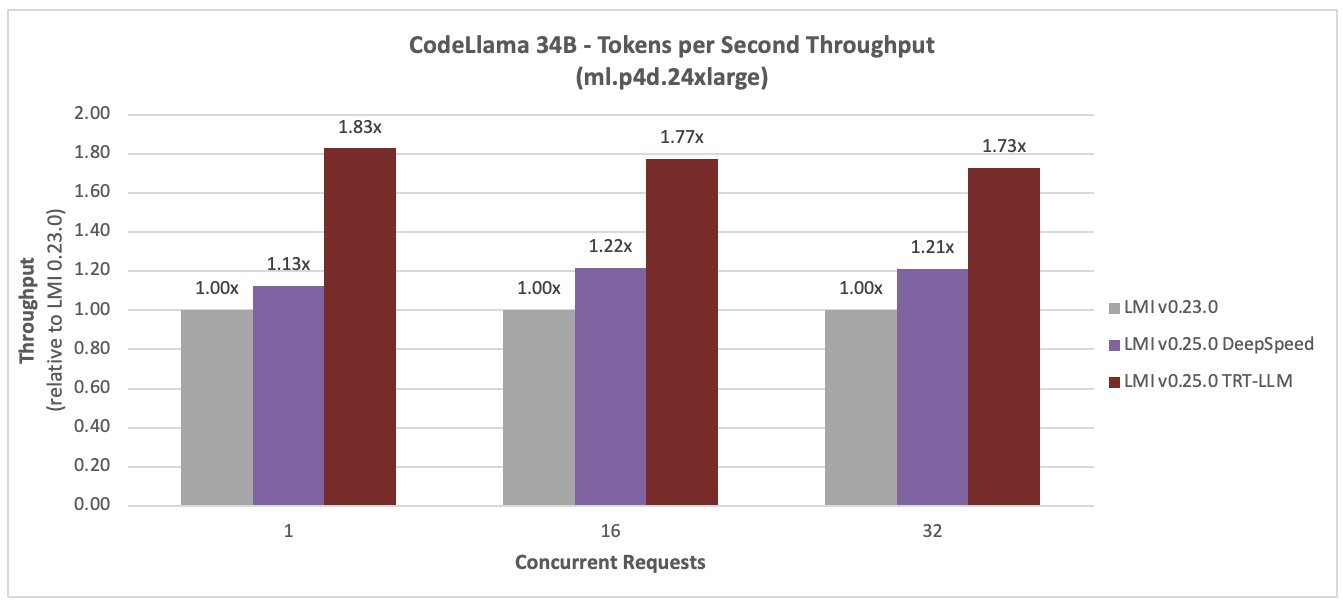
CódigoLlama 34B
Las siguientes figuras comparan CodeLlama 34B. La latencia se redujo en un 36 % y el rendimiento aumentó en un 77 % para una simultaneidad de 16, con el nuevo DLC LMI TensorRT LLM.
Configuración y contenedor recomendados para alojar LLM
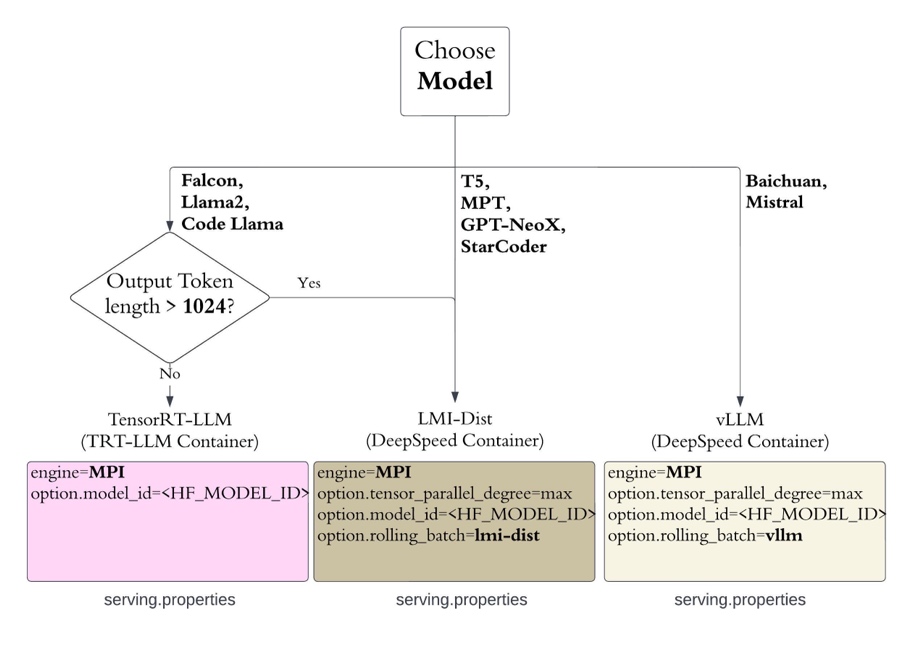
Con la última versión, SageMaker proporciona dos contenedores: 0.25.0-deepspeed y 0.25.0-tensorrtllm. El contenedor DeepSpeed contiene DeepSpeed, la biblioteca de inferencia distribuida LMI. El contenedor TensorRT-LLM incluye Biblioteca TensorRT-LLM de NVIDIA para acelerar la inferencia LLM.
Recomendamos la configuración de implementación que se ilustra en el siguiente diagrama.
Para comenzar, consulte los cuadernos de muestra:
Conclusión
En esta publicación, mostramos cómo puede utilizar los DLC LMI de SageMaker para optimizar los LLM para su caso de uso empresarial y lograr beneficios de precio-rendimiento. Para obtener más información sobre las capacidades de LMI DLC, consulte Paralelismo de modelos e inferencia de modelos grandes. Nos entusiasma ver cómo utiliza estas nuevas capacidades de Amazon SageMaker.
Sobre los autores
 Michael Nguyen es arquitecto sénior de soluciones de inicio en AWS y se especializa en aprovechar la IA/ML para impulsar la innovación y desarrollar soluciones comerciales en AWS. Michael posee 12 certificaciones de AWS y tiene una licenciatura y maestría en ingeniería eléctrica e informática y un MBA de la Universidad Penn State, la Universidad de Binghamton y la Universidad de Delaware.
Michael Nguyen es arquitecto sénior de soluciones de inicio en AWS y se especializa en aprovechar la IA/ML para impulsar la innovación y desarrollar soluciones comerciales en AWS. Michael posee 12 certificaciones de AWS y tiene una licenciatura y maestría en ingeniería eléctrica e informática y un MBA de la Universidad Penn State, la Universidad de Binghamton y la Universidad de Delaware.
 Rishabh Ray Chaudhury Es gerente senior de productos en Amazon SageMaker y se centra en la inferencia de aprendizaje automático. Le apasiona innovar y crear nuevas experiencias para los clientes de Machine Learning en AWS para ayudarlos a escalar sus cargas de trabajo. En su tiempo libre le gusta viajar y cocinar. Puedes encontrarlo en LinkedIn.
Rishabh Ray Chaudhury Es gerente senior de productos en Amazon SageMaker y se centra en la inferencia de aprendizaje automático. Le apasiona innovar y crear nuevas experiencias para los clientes de Machine Learning en AWS para ayudarlos a escalar sus cargas de trabajo. En su tiempo libre le gusta viajar y cocinar. Puedes encontrarlo en LinkedIn.
 Qinglan es ingeniero de desarrollo de software en AWS. Ha estado trabajando en varios productos desafiantes en Amazon, incluidas soluciones de inferencia de aprendizaje automático de alto rendimiento y sistemas de registro de alto rendimiento. El equipo de Qing lanzó con éxito el primer modelo de mil millones de parámetros en Amazon Advertising con una latencia muy baja requerida. Qing tiene un conocimiento profundo sobre la optimización de la infraestructura y la aceleración del aprendizaje profundo.
Qinglan es ingeniero de desarrollo de software en AWS. Ha estado trabajando en varios productos desafiantes en Amazon, incluidas soluciones de inferencia de aprendizaje automático de alto rendimiento y sistemas de registro de alto rendimiento. El equipo de Qing lanzó con éxito el primer modelo de mil millones de parámetros en Amazon Advertising con una latencia muy baja requerida. Qing tiene un conocimiento profundo sobre la optimización de la infraestructura y la aceleración del aprendizaje profundo.
 Jian Sheng es ingeniero de desarrollo de software en Amazon Web Services y ha trabajado en varios aspectos clave de los sistemas de aprendizaje automático. Ha sido un colaborador clave del servicio SageMaker Neo, centrándose en la compilación de aprendizaje profundo y la optimización del tiempo de ejecución del marco. Recientemente, ha dirigido sus esfuerzos y contribuido a optimizar el sistema de aprendizaje automático para la inferencia de modelos grandes.
Jian Sheng es ingeniero de desarrollo de software en Amazon Web Services y ha trabajado en varios aspectos clave de los sistemas de aprendizaje automático. Ha sido un colaborador clave del servicio SageMaker Neo, centrándose en la compilación de aprendizaje profundo y la optimización del tiempo de ejecución del marco. Recientemente, ha dirigido sus esfuerzos y contribuido a optimizar el sistema de aprendizaje automático para la inferencia de modelos grandes.
 Vivek Gangasani es un arquitecto de soluciones de inicio de IA/ML para nuevas empresas de IA generativa en AWS. Ayuda a las nuevas empresas emergentes de GenAI a crear soluciones innovadoras utilizando los servicios de AWS y la computación acelerada. Actualmente, se centra en desarrollar estrategias para afinar y optimizar el rendimiento de inferencia de modelos de lenguaje grandes. En su tiempo libre, Vivek disfruta haciendo senderismo, viendo películas y probando diferentes platos.
Vivek Gangasani es un arquitecto de soluciones de inicio de IA/ML para nuevas empresas de IA generativa en AWS. Ayuda a las nuevas empresas emergentes de GenAI a crear soluciones innovadoras utilizando los servicios de AWS y la computación acelerada. Actualmente, se centra en desarrollar estrategias para afinar y optimizar el rendimiento de inferencia de modelos de lenguaje grandes. En su tiempo libre, Vivek disfruta haciendo senderismo, viendo películas y probando diferentes platos.
 Harish Tummalacherla es ingeniero de software del equipo de rendimiento de aprendizaje profundo en SageMaker. Trabaja en ingeniería de rendimiento para ofrecer modelos de lenguaje grandes de manera eficiente en SageMaker. En su tiempo libre le gusta correr, andar en bicicleta y esquiar de montaña.
Harish Tummalacherla es ingeniero de software del equipo de rendimiento de aprendizaje profundo en SageMaker. Trabaja en ingeniería de rendimiento para ofrecer modelos de lenguaje grandes de manera eficiente en SageMaker. En su tiempo libre le gusta correr, andar en bicicleta y esquiar de montaña.





{kind=link}