 NEWSLETTER
NEWSLETTER

Image created by the author using Midjourney
Introduction to RAG
In the ever-evolving world of language models, one firm methodology of particular interest is Retrieval Augmented Generation (RAG), a procedure that incorporates elements of Information Retrieval (IR) within the framework of a generation language model. to generate human-like texts. text with the goal of being more useful and accurate than what would be generated with the default language model alone. We will introduce the elementary concepts of RAG in this post, with a view to building some RAG systems in later posts.
RAG Overview
We create language models using vast generic data sets that are not tailored to your personal or custom data. To address this reality, RAG can combine your particular data with the existing “knowledge” of a language model. To facilitate this, what you need to do, and what RAG does, is index your data so that it is searchable. When a composite search is run on your data, relevant and important information is extracted from the indexed data and can be used within a query against a language model to return a relevant and useful response made by the model. For any ai engineer, data scientist, or developer interested in building chatbots, modern information retrieval systems, or other types of personal assistants, it is vitally important to understand RAG and know how to leverage your own data.
Simply put, RAG is a novel technique that enriches language models with input retrieval functionality, which improves language models by incorporating IR mechanisms into the generation process, mechanisms that can personalize (increase) “knowledge.” “inherent of the model used for generative purposes.
In summary, RAG involves the following high-level steps:
- Retrieve information from your custom data sources
- Add this data to your message as additional context
- Have the LLM generate a response based on the augmented message
RAG offers these advantages over the alternative of model fine-tuning:
- No training is done with RAG, so there are no costs or adjustment time
- Custom data is as current as you create it, so the model can effectively stay up to date.
- Specific custom data documents can be cited during (or after) the process, making the system much more verifiable and reliable.
A closer look
Upon closer examination, we can say that a RAG system will go through 5 phases of operation.
1. Load: Collecting the raw text data (from text files, PDFs, web pages, databases, and more) is the first of many steps, putting the text data into the processing pipeline, making it one step necessary in the process. Without loading data, RAG simply cannot work.
2. Index: The data you have now needs to be structured and maintained for retrieval, search, and query. Language models will use vector embeddings created from the content to provide numerical representations of the data, as well as employ particular metadata to enable successful search results.
3. Store: After its creation, the index should be saved along with the metadata, ensuring that this step does not need to be repeated regularly, allowing for easier scaling of the RAG system.
4. Consultation: With this index implemented, the content can be traversed using the indexer and language model to process the data set according to various queries.
5. Evaluate: It is useful to evaluate performance against other possible generative steps, either when modifying existing processes or when testing the inherent latency and accuracy of systems of this nature.
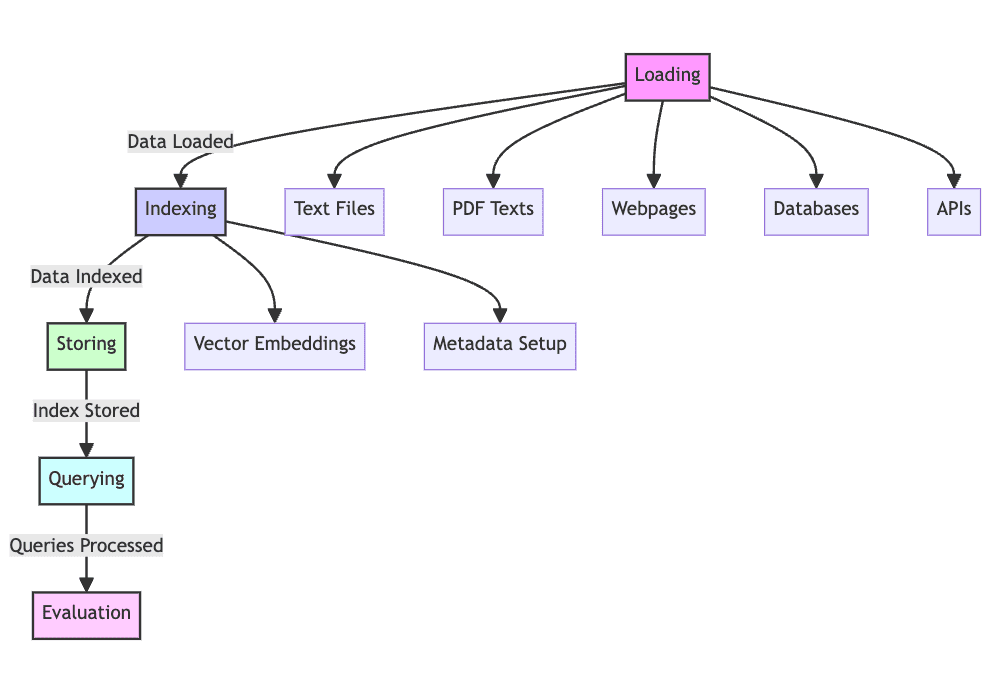
Image created by the author
A brief example
Consider the following simple RAG implementation. Let's imagine that this is a system created to respond to customer queries about a fictitious online store.
1. Loading: Content will emerge from product documentation, user reviews and customer feedback, stored in multiple formats such as message boards, databases and APIs.
2. Indexing: Will produce vector embeddings for product documentation and user reviews, etc., along with indexing metadata assigned to each data point, such as product category or customer rating.
3. Storage: The index thus developed will be stored in a vector store, a specialized database for optimal storage and retrieval of vectors, which is how embeddings are stored.
4. Consulting: When a customer query arrives, the vector warehouse databases will be searched based on the text of the question and then language models will be used to generate responses using the sources of this precursor data as context.
5. Evaluation: System performance will be evaluated against other options, such as traditional language model recovery, measuring metrics such as response correctness, response latency, and overall user satisfaction, to ensure that the RAG system can be modify and refine to offer superior quality. results.
This example tutorial should give you an idea of the methodology behind RAG and its use to convey information retrievability in a language model.
Conclusion
The topic of this article was the introduction of augmented generation retrieval, which combines text generation with information retrieval to improve the accuracy and contextual consistency of language model output. The method allows the extraction and augmentation of data stored in indexed sources to incorporate them into the generated output of language models. This RAG system can provide improved value compared to simply tuning the language model.
The next steps in our RAG journey will be learning the tools of the trade so we can implement some of our own RAG systems. We will first focus on using LlamaIndex tools such as data connectors, engines, and application connectors to facilitate RAG integration and scaling. But we will save this for the next article.
In upcoming projects we will build complex RAG systems and analyze potential uses and improvements of RAG technology. The hope is to reveal many new possibilities in the field of artificial intelligence and use these diverse data sources to build smarter, more contextualized systems.
Matthew May (twitter.com/mattmayo13″ rel=”noopener”>@mattmayo13) has a master's degree in computer science and a postgraduate diploma in data mining. As Editor-in-Chief, Matthew aims to make complex data science concepts accessible. His professional interests include natural language processing, machine learning algorithms, and exploring emerging ai. He is driven by the mission to democratize knowledge in the data science community. Matthew has been coding since he was 6 years old.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}