 NEWSLETTER
NEWSLETTER
At Apple, we believe privacy is a fundamental human right. It’s also one of our core values, influencing both our research and the design of Apple’s products and services.
Understanding how people use their devices often helps in improving the user experience. However, accessing the data that provides such insights — for example, what users type on their keyboards and the websites they visit — can compromise user privacy. We develop system architectures that enable learning at scale by leveraging advances in machine learning (ML), such as private federated learning (PFL), combined with existing privacy best practices. We design efficient and scalable differentially private algorithms and provide rigorous analyses to demonstrate the tradeoffs among utility, privacy, server computation, and device bandwidth.
Earlier this year, Apple hosted the Workshop on Privacy-Preserving Machine Learning (PPML). This two-day hybrid event brought together Apple and members of the broader research community to discuss the state of the art in privacy-preserving machine learning.
In this post, we share highlights from workshop discussions and recordings of select talks.
Apple Workshop on Privacy-Preserving Machine Learning Videos
Federated Learning and Statistics
Workshop presenters explored advances in federated learning (FL), the associated differentially private algorithms for ML optimization, and its widespread impact via practical deployment.
PFL is now a popular technique for training ML models, in which:
- Training data remains private on user devices, commonly referred to as edge devices.
- Aggregated gradients enable data scientists to learn from a population.
- Differential privacy (DP) guarantees that the model protects the privacy of the data on edge devices.
Simulations are key to quantifying data requirements and the impact of federated partitioning, as well as for bootstrapping the gradient and hyper-parameter search space. In their talk, presenters Mona Chitnis and Filip Granqvist of Apple discussed their work developing a PFL simulation framework. This framework has enabled the training of models with PFL for various use cases, including large vocabulary language models on resource-constrained devices, a tokenizer, and a recommender system improved with embeddings.
In conjunction with the workshop, we open sourced the pfl-research Python framework for PFL simulations, with key benchmarks showing much faster speeds than existing open source tools. We envision that pfl-research will accelerate research by equipping the community with vetted tools for prototyping algorithms and promoting the reproducibility of realistic FL benchmarks. This follows the open sourcing of the FLAIR dataset, which was shared at the Workshop on Privacy Preserving Machine Learning in 2022.
As discussed in pfl-research: Simulation Framework for Accelerating Research in Private Federated Learning, the key differentiators of pfl-research are:
- Execution speed 7–72x faster than alternative open source frameworks, in both single and multi-GPU settings.
- A collection of realistic large-scale FL benchmarks.
- Seamless DP integration with privacy accountants and mechanisms.
- Intuitive API for local and central optimization, and for implementing new research algorithms, featuring an extensible object-oriented design.
- Support for non-neural network (NN) models to enhance explainability, including gradient-boosted decisions trees (GBDT) and Gaussian mixture models (GMM).
Benchmarks Dashboard
Image 1: CIFAR10 iid no DP benchmark results.
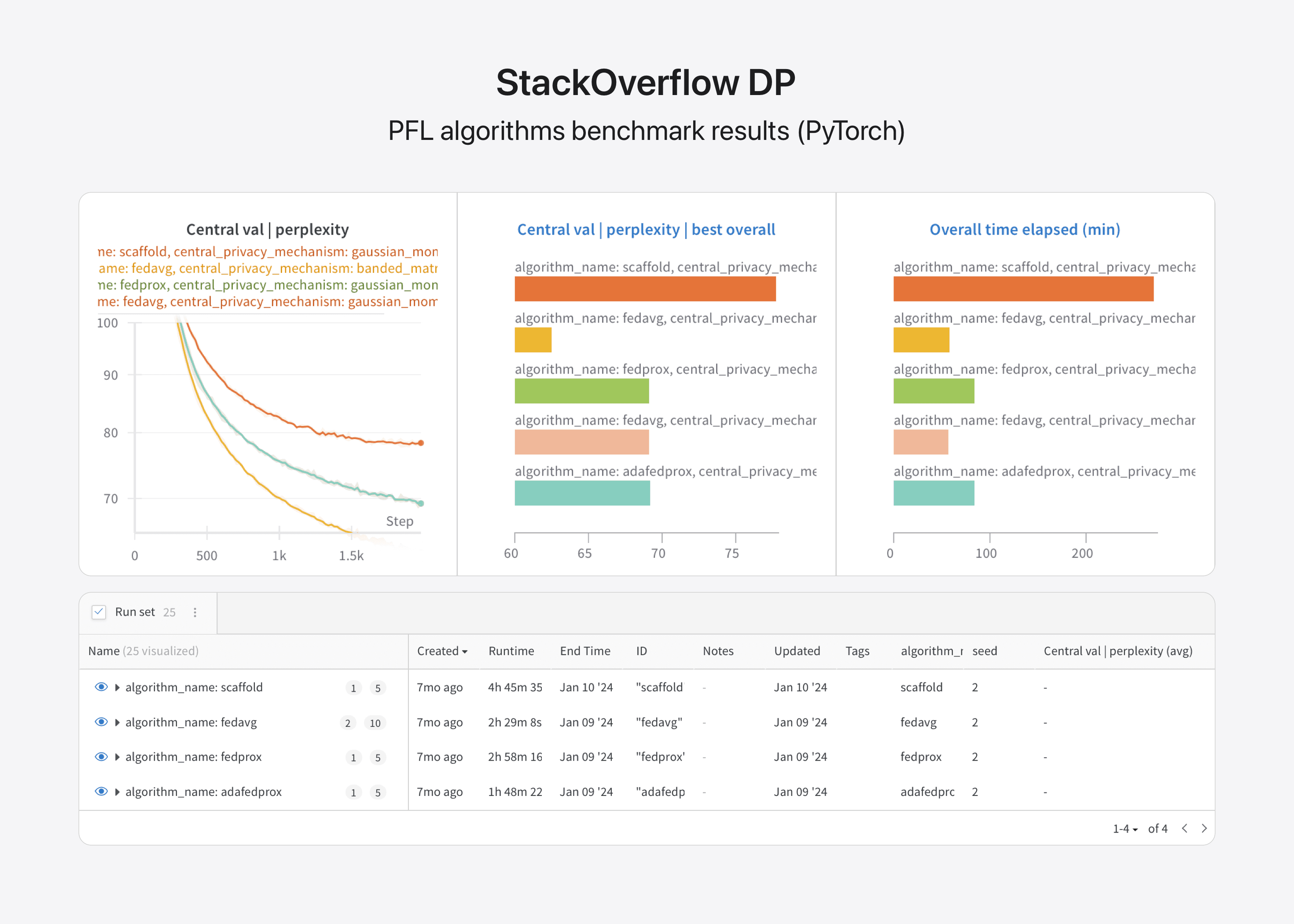
Image 2: StackOverflow no DP benchmark results.
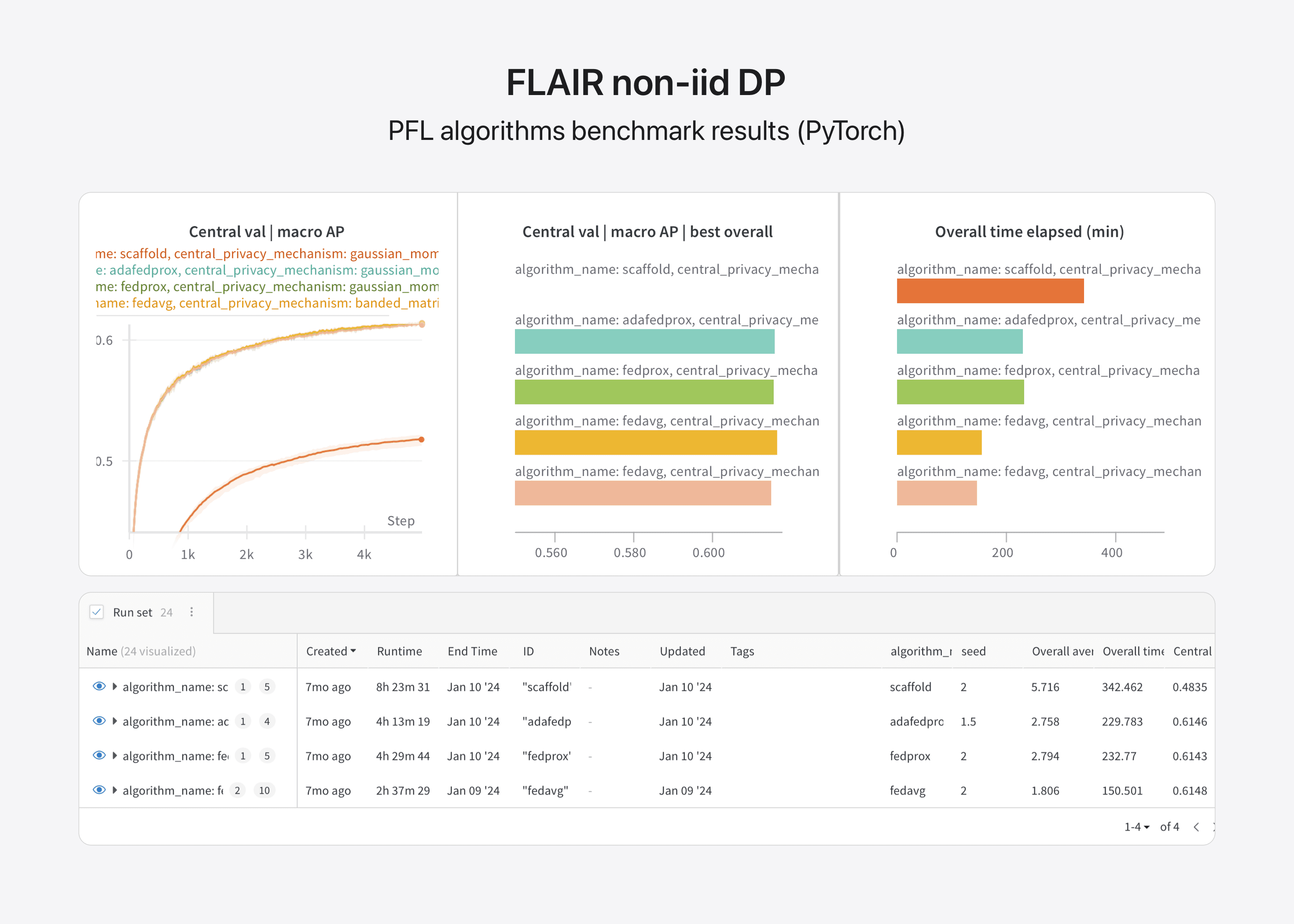
Image 3: FLAIR non-iid DP benchmark results.
In a talk titled Matrix Factorization of DP-FTRL Outperforms DP-SGD for Both Cross-Device FL and Centralized Training, Brendan McMahan of Google presented the motivation and design behind a DP and follow-the-regularized-leader (DP-FTRL) mechanism for model training with privacy. McMahan discussed training ML models with DP to ensure users of those models (both end users and teams) cannot reconstruct private information.
The moments-accountant method has proven to be a great fit for deep learning, enabling privacy amplification through random subsampling. However, it can be challenging in some implementations to have provable privacy in a dynamic production setting like cross-device FL. McMahan’s innovative approach uses a stateful DP mechanism to accurately estimate prefix-sums rather than full gradients, allowing for correlated rather than independent Gaussian noise. With an intuitive visualization in vector space, McMahon illustrated that estimating prefix-sums is closer to true gradients, and thus more accurate, than differentially private stochastic gradient descent (DP-SGD). This approach also makes it harder for an adversary to attack with a single gradient.
This work builds on three years of DP-FTRL research, focusing on the tree aggregation technique. This technique introduces FTRL, generalizes to a matrix mechanism, applies the result to multi-epoch matrix factorization with capped contributions and iteration separation, and then utilizes the latest findings with amplified banded matrix factorization. This approach relaxes earlier constraints and offers amplification benefits for epsilon in a smaller regime (<8.0<annotation encoding="application/x-tex”><8.0<8.0). For more information, refer to Practical and Private (Deep) Learning Without Sampling or Shuffling, Multi-Epoch Matrix Factorization Mechanisms for Private Machine Learning, and (Amplified) Banded Matrix Factorization: A Unified Approach to Private Training.
Researchers must consider compute as an additional factor in the trade-offs between privacy and utility, McMahan said. DP-FTRL research has progressively made compute over epochs in a client batch feasible, helping to bridge the gap with non-private training. Some of these techniques apply to ML training in both centralized datacenter and federated settings.
With the published article Advances in Private Training for Production On-Device Language Models, McMahan described how GBoard language models are trained and deployed with FL and DP guarantees. It underscores the trends of continual improvement in PPML and the importance of transparency to end users with published DP guarantees.
Private Learning and Statistics in the Central Model
Several speakers at the workshop focused on a central topic: the best methods to combine learning and statistics with privacy in both centralized and federated settings.
In the talk titled Eliciting End Users’ Privacy-Accuracy Preferences for DP Deployments, Rachel Cummings of Columbia University highlighted the importance of effectively and accurately explaining privacy guarantees to end users. This allows users to make informed data-sharing decisions. Users care about privacy, but the way in which privacy guarantees are communicated can sometimes lead to a gap between user expectations and the actual guarantees. Cummings and collaborators discussed the challenges of various communication strategies in their paper titled “I Need a Better Description”: An Investigation into User Expectations for Differential Privacy. In a more recent paper, What Are the Chances? Explaining the Epsilon Parameter in Differential Privacy, Cummings and her team analyzed three approaches to explaining the epsilon parameter that controls differential privacy guarantees, arguing odds-based explanation methods are most effective.
Salil Vadhan of Harvard University presented an introduction to OpenDP – a suite of open-source DP tools, and discussed the concept of interactive DP in the talk, Interactive Differential Privacy in the OpenDP Library. According to Vadhan, OpenDP emphasizes the following values:
- Trustworthiness: Assisting participants implementing differential privacy correctly.
- Flexibility: Providing easy to extend tools.
- Community governance: Involving multiple stakeholders in development.
Vadhan elaborated on the theory of privacy for interactive measurement, which generates a queryable object that can be interrogated by an adversary. He demonstrated examples of this model’s implementation using OpenDP. In conclusion, Vadhan presented findings on the concurrent composition of multiple interactive measurements, highlighting that these cannot be effectively modeled using sequential composition.
Trust Models and Security
Another topic of interest at the workshop was trust models. The privacy and security properties of a system are inextricably linked to the observer’s perspective. In a federated setting, making the output model differentially private ensures that an observer only sees the published model without learning information about individual users. However, ensuring privacy against an observer who can access the server’s internal state requires additional measures. Cryptographic tools like secure multiparty computation can provide privacy guarantees. Typically, these tools are used to implement a few primitives, on top of which richer functionalities are built. In private learning and statistics, shuffling and aggregation are versatile primitives that support a wide range of private algorithms. Researchers have proposed implementing these primitives under various trust models. See, for example, Prochlo: Strong Privacy for Analytics in the Crowd by Bittau and colleagues, and Practical Secure Aggregation for Privacy-Preserving Machine Learning by Bonawitz and team.
In the talk Samplable Anonymous Aggregation for Private Federated Data Analysis, Kunal Talwar of Apple presented a new primitive called samplable aggregation, which enhances utility and reduces communication costs for many important practical tasks. He also proposed a secure implementation approach, building on the Prio protocol from Prio: Private, Robust, and Scalable Computation of Aggregate Statistics, which uses additive secret sharing among two or more servers for aggregation. Prio provides strong privacy guarantees against any observer with access to all but one of the servers. Talwar’s talk demonstrated how the Prio protocol could be combined with two additional components — an anonymization infrastructure and an authentication infrastructure — to securely implement a samplable aggregation system. He argued that these two building blocks can be implemented using existing methods such as PrivacyPass and Oblivious HTTP.
Although these secure aggregation methods prevent any server from seeing individual contributions, they may increase vulnerability to malicious clients. For example, while each client is expected to contribute a bounded-norm gradient vector, a compromised device might send a much larger vector to disrupt the computation. Fortunately, the Prio protocol enables servers to validate various properties of client contributions while still protecting their privacy. Thus, two servers can ensure a client has secret-shared a vector of norm 1<annotation encoding="application/x-tex”>11 without either learning anything about the vector itself. These zero-knowledge proofs can be constructed for any predicate but require additional computation and communication from the client. In the talk, PINE: Private Inexpensive Norm Enforcement, Guy Rothblum of Apple argued existing protocols for validating the bounded Euclidean norm property incur significant communication overhead. He proposed a new protocol, Private Inexpensive Norm Enforcement (PINE) which addresses this overhead. Rothblum demonstrated PINE can validate the Euclidean norm of large vectors while ensuring the communication overhead is minimal – at most a few percent.
PPML and Foundation Models
The emergence of large language models (LLMs) is profoundly transforming machine learning capabilities and applications. Recent research has demonstrated these massive models are particularly prone to memorizing training data, which can be relatively easy to extract (see Scalable Extraction of Training Data from (Production) Language Models). This, along with the new range of user-facing LLM applications, presents unique challenges for PPML.
An important goal of the workshop was to explore these emerging challenges and to discuss existing research addressing them.
LLMs have significantly improved the prediction accuracy of automatic speech recognition (ASR). However, user speech data is highly sensitive and often accessible only on user devices. This raises the question of whether the large models needed for high-accuracy speech recognition can be trained within the constraints of PFL. Tatiana Likhomanenko of Apple addressed this in the talk, Private Federated Learning (PFL) for Speech Recognition (ASR). She described an architecture and training algorithms that achieve near-optimal accuracy on several standard speech-recognition datasets while maintaining strong privacy guarantees within FL constraints. The training algorithm requires a seed model to start, but as Likhomanenko and colleagues demonstrated in a previous work, Federated Learning with Differential Privacy for End-to-End Speech Recognition, the seed model can originate from a different domain than ASR.
LLMs also have the unique ability to include a large amount of query-specific context in the prompt. One approach to adapt a general-purpose LLM to a specific domain is to include a domain-specific dataset as part of the query prompt. However, as Nicholas Papernot of the University of Toronto pointed out in the talk, Flocks of Stochastic Parrots: Differentially Private Prompt Learning for Large Language Models, the query response may leak private information about the domain-specific queries. Papernot described two techniques addressing this challenge. The first technique privately trains an embedding of the domain-specific data to improve accuracy on domain-specific queries (for details, see Flocks of Stochastic Parrots: Differentially Private Prompt Learning for Large Language Models’). This approach is more efficient than private fine-tuning of an LLM, but still requires computing model gradients. The second technique, based on PATE (as described in Scalable Private Learning with PATE), requires only black-box access to the model. It splits the domain-specific dataset into subsets, runs a query for each subset, and privately aggregates the responses. Papernot demonstrated how this approach allows data scientists to answer domain-specific queries with strong privacy guarantees, while achieving nearly the same accuracy as the original non–privacy-preserving approach.
Privacy-preserving learning and applications of LLMs are becoming a key focus of research in academia and industry, and we look forward to continue to actively participate in this research.
Workshop Resources
Related Videos
 “Flocks of Stochastic Parrots: Differentially Private Prompt Learning for Large Language Models.” by Nicolas Papernot, University of Toronto and Vector Institute.
“Flocks of Stochastic Parrots: Differentially Private Prompt Learning for Large Language Models.” by Nicolas Papernot, University of Toronto and Vector Institute.
“Interactive Differential Privacy in the OpenDP Library.” by Salil Vadhan, Harvard University.
“PINE: Private Inexpensive Norm Enforcement.” by Guy Rothblum, Apple.
“Eliciting End Users’ Privacy-Accuracy Preferences for DP Deployments.” by Rachel Cummings, Columbia University.
“Matrix Factorization DP-FTRL outperforms DP-SGD for cross-device federated learning and centralized training.” by Brendan McMahan, Google Research.
“Samplable Anonymous Aggregation for Private Federated Data Analysis.” by Kunal Talwar, Apple.
“Private Federated Learning (PFL) framework.” by Mona Chitnis and Filip Granqvist, Apple.
“Private Federated Learning (PFL) for Speech Recognition (ASR).” by Tatiana Likhomanenko, Apple.
Related Work
 Advances in Private Training for Production On-Device Language Models by Zheng Xu and Yanxiang Zhang
Advances in Private Training for Production On-Device Language Models by Zheng Xu and Yanxiang Zhang
(Amplified) Banded Matrix Factorization: A Unified Approach to Private Training by Christopher A. Choquette-Choo, Arun Ganesh, Ryan McKenna, H. Brendan McMahan, Keith Rush, Abhradeep Thakurta, and Zheng Xu
Apple Privacy-Preserving Machine Learning Workshop 2022 by Apple Machine Learning Research
Federated Learning with Differential Privacy for End-to-End Speech Recognition by Martin Pelikan, Sheikh Shams Azam, Vitaly Feldman, Jan “Honza” Silovsky, Kunal Talwar, and Tatiana Likhomanenko
FLAIR: Federated Learning Annotated Image Repository by Congzheng Song, Filip Granqvist, and Kunal Talwar
Flocks of Stochastic Parrots: Differentially Private Prompt Learning for Large Language Models by Haonan Duan, Adam Dziedzic, Nicolas Papernot, and Franziska Boenisch
“I Need a Better Description”: An Investigation into User Expectations for Differential Privacy by Rachel Cummings, Gabriel Kaptchuk, and Elissa M. Redmiles
Learning Compressed Embeddings for On-Device Inference by Niketan Pansare, Jay Katukuri, Aditya Arora, Frank Cipollone, Riyaaz Shaik, Noyan Tokgozoglu, and Chandru Venkataraman
Multi-Epoch Matrix Factorization Mechanisms for Private Machine Learning by Christopher A. Choquette-Choo, H. Brendan McMahan, Keith Rush, and Abhradeep Thakurta
Oblivious HTTP by M. Thomson and C.A. Wood
OpenDP: Developing Open Source Tools for Differential Privacy (website)
pfl-research: Simulation Framework for Accelerating Research in Private Federated Learning by Filip Granqvist, Congzheng Song, Áine Cahill, Rogier van Dalen, Martin Pelikan, Yi Sheng Chan, Xiaojun Feng, et al.
pfl-research (GitHub repository)
PINE: Efficient Verification of a Euclidean Norm Bound of a Secret-Shared Vector by Guy Rothblum, Eran Omri, Junye Chen, and Kunal Talwar
Practical and Private (Deep) Learning Without Sampling or Shuffling by Peter Kairouz, Brendan McMahan, Shuang Song, Om Thakkar, Abhradeep Thakurta, and Zheng Xu
Practical Secure Aggregation for Privacy-Preserving Machine Learning by Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H. Brendan McMahan, Sarvar Patel, Daniel Ramage, et al.
Prio: Private, Robust, and Scalable Computation of Aggregate Statistics by Henry Corrigan-Gibbs and Dan Boneh
Prochlo: Strong Privacy for Analytics in the Crowd by Andrea Bittau, Úlfar Erlingsson, Petros Maniatis, Ilya Mironov, Ananth Raghunathan, David Lie, Mitch Rudominer, et al.
Rate-Limited Token Issuance Protocol by S. Hendrickson, J. Iyengar, T. Pauly, S. Valdez, and C. A. Wood
Samplable Anonymous Aggregation for Private Federated Data Analysis by Kunal Talwar, Shan Wang, Audra McMillan, Vojta Jina, Vitaly Feldman, Bailey Basile, Aine Cahill, et al.
Scalable Extraction of Training Data from (Production) Language Models by Milad Nasr, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A. Feder Cooper, Daphne Ippolito, Christopher A. Choquette-Choo, et al.
Scalable Private Learning with PATE by Nicolas Papernot, Shuang Song, Ilya Mironov, Ananth Raghunathan, Kunal Talwar, and Úlfar Erlingsson
Training a Tokenizer for Free by Eugene Bagdasaryan, Congzheng Song, Rogier van Dalen, Matt Seigel, and Áine Cahill
Training Large-Vocabulary Neural Language Models by Private Federated Learning for Resource-Constrained Devices by Mingbin Xu, Congzheng Song, Ye Tian, Neha Agrawal, Filip Granqvist, Rogier van Dalen, Xiao Zhang, et al.
What Are the Chances? Explaining the Epsilon Parameter in Differential Privacy by Priyanka Nanayakkara, Mary Anne Smart, Rachel Cummings, Gabriel Kaptchuk, and Elissa Redmiles
Acknowledgments
Many people contributed to this workshop, including Hilal Asi, Mona Chitnis, Vitaly Feldman, Amitabha Ghosh, Andrew W. Hill, Tatiana Likhomanenko, Audra McMillan, Martin Pelikan, Guy Rothblum, Congzheng Song, and Kunal Talwar.






{kind=link}