 NEWSLETTER
NEWSLETTER
La inteligencia artificial (IA) generativa ofrece la oportunidad de mejorar la atención sanitaria al combinar y analizar datos estructurados y no estructurados de sectores que antes estaban desconectados. La IA generativa puede ayudar a elevar el nivel de eficiencia y eficacia en todo el ámbito de la prestación de servicios sanitarios.
El sector sanitario genera y recopila una cantidad importante de datos textuales no estructurados, entre los que se incluyen documentación clínica, como información de pacientes, historial médico y resultados de pruebas, así como documentación no clínica, como registros administrativos. Estos datos no estructurados pueden afectar la eficiencia y la productividad de los servicios clínicos, ya que suelen encontrarse en diversos formatos en papel que pueden resultar difíciles de gestionar y procesar. Agilizar el manejo de esta información es fundamental para que los proveedores de atención sanitaria mejoren la atención al paciente y optimicen sus operaciones.
Manejar grandes volúmenes de datos, extraer datos no estructurados de múltiples formularios en papel o imágenes y compararlos con los formularios estándar o de referencia puede ser un proceso largo y arduo, propenso a errores e ineficiencias. Sin embargo, los avances en las soluciones de IA generativa han introducido enfoques automatizados que ofrecen una solución más eficiente y confiable para comparar múltiples documentos.
amazon Bedrock es un servicio totalmente administrado que pone a disposición modelos de base (FM) de las principales empresas emergentes de inteligencia artificial y de amazon a través de una API, de modo que puede elegir entre una amplia gama de FM para encontrar el modelo que mejor se adapte a su caso de uso. amazon Bedrock ofrece una experiencia sin servidor, de modo que puede comenzar rápidamente, personalizar de forma privada los FM con sus propios datos e integrarlos e implementarlos rápidamente en sus aplicaciones utilizando las herramientas de AWS sin tener que administrar la infraestructura.
En esta publicación, exploramos el uso del modelo de lenguaje grande (LLM) de Anthropic Claude 3 en amazon Bedrock. amazon Bedrock brinda acceso a varios LLM, como Anthropic Claude 3, que se pueden usar para generar datos semiestructurados relevantes para la industria de la atención médica. Esto puede ser particularmente útil para crear varios formularios relacionados con la atención médica, como formularios de admisión de pacientes, formularios de reclamo de seguros o cuestionarios de historial médico.
Descripción general de la solución
Para ofrecer una comprensión general de cómo funciona la solución antes de profundizar en los elementos específicos y los servicios utilizados, analizamos los pasos arquitectónicos necesarios para crear nuestra solución en AWS. Ilustramos los elementos clave de la solución y le brindamos una descripción general de los distintos componentes y sus interacciones.
A continuación, examinamos cada uno de los elementos clave con más detalle, exploramos los servicios específicos de AWS que se utilizan para crear la solución y analizamos cómo estos servicios funcionan en conjunto para lograr la funcionalidad deseada. Esto proporciona una base sólida para una mayor exploración e implementación de la solución.
Parte 1: Formularios estándar: Extracción y almacenamiento de datos
El siguiente diagrama destaca los elementos clave de una solución para la extracción y almacenamiento de datos con formularios estándar.
Figura 1: Arquitectura – Forma estándar – Extracción y almacenamiento de datos.
Los pasos estándar de procesamiento son los siguientes:
- Un usuario carga imágenes de formularios en papel (PDF, PNG, JPEG) en amazon Simple Storage Service (amazon S3), un servicio de almacenamiento de objetos altamente escalable y duradero.
- amazon Simple Queue Service (amazon SQS) se utiliza como cola de mensajes. Siempre que se carga un nuevo formulario, se invoca un evento en amazon SQS.
- El mensaje SQS invoca una AWS Lambda. La función Lambda es responsable de procesar los nuevos datos del formulario.
- La función Lambda lee el nuevo objeto S3 y lo pasa a la API de amazon Textract para procesar los datos no estructurados y generar una salida estructurada y jerárquica. amazon Textract es un servicio de AWS que puede extraer texto, escritura a mano y datos de documentos e imágenes escaneados. Este enfoque permite el procesamiento eficiente y escalable de documentos complejos, lo que le permite extraer información y datos valiosos de varias fuentes.
- La función Lambda pasa el texto convertido a Anthropic Claude 3 en amazon Bedrock Anthropic Claude 3 para generar una lista de preguntas.
- Por último, la función Lambda almacena la lista de preguntas en amazon S3.
Llamada a la API de amazon Bedrock para extraer detalles del formulario
Llamamos a una API de amazon Bedrock dos veces en el proceso para las siguientes acciones:
- Extraer preguntas del formulario estándar o de referencia – La primera llamada a la API se realiza para extraer una lista de preguntas y subpreguntas del formulario estándar o de referencia. Esta lista sirve como línea base o punto de referencia para la comparación con otros formularios. Al extraer las preguntas del formulario de referencia, podemos establecer un punto de referencia con el que se pueden evaluar otros formularios.
- Extraer preguntas del formulario personalizado – La segunda llamada a la API se realiza para extraer una lista de preguntas y subpreguntas del formulario personalizado o del formulario que se debe comparar con el formulario estándar o de referencia. Este paso es necesario porque necesitamos analizar el contenido y la estructura del formulario personalizado para identificar sus preguntas y subpreguntas antes de poder compararlas con el formulario de referencia.
Al extraer y estructurar por separado las preguntas tanto para los formularios de referencia como para los personalizados, la solución puede pasar estas dos listas a la API de amazon Bedrock para el paso de comparación final. Este enfoque mantiene lo siguiente:
- Comparación precisa – La API tiene acceso a los datos estructurados de ambos formularios, lo que facilita la identificación de coincidencias y discordancias, y proporciona un razonamiento relevante.
- Procesamiento eficiente – Separar el proceso de extracción de los formularios de referencia y personalizados ayuda a evitar operaciones redundantes y optimiza el flujo de trabajo general.
- Observabilidad e interoperabilidad – Mantener las preguntas separadas permite una mejor visibilidad, análisis e integración de las preguntas de diferentes formularios.
- Evitar las alucinaciones – Al seguir un enfoque estructurado y confiar en los datos extraídos, la solución ayuda a evitar generar o alucinar contenido, proporcionando integridad en el proceso de comparación.
Este enfoque de dos pasos utiliza las capacidades de la API de amazon Bedrock mientras optimiza el flujo de trabajo, lo que permite una comparación de formularios precisa y eficiente y promueve la observabilidad e interoperabilidad de las preguntas involucradas.
Vea el siguiente código (llamada API):
Solicitud al usuario para extraer campos y enumerarlos
Proporcionamos el siguiente mensaje de usuario a Anthropic Claude 3 para extraer los campos del texto sin procesar y enumerarlos para compararlos como se muestra en el paso 3B (de la Figura 3: Extracción de datos y comparación de campos de formulario).
La siguiente figura ilustra la salida de amazon Bedrock con una lista de preguntas del formulario estándar o de referencia.

Figura 2: Lista de preguntas de muestra del formulario estándar
Almacene esta lista de preguntas en amazon S3 para que pueda usarse para comparar con otros formularios, como se muestra en la Parte 2 del proceso a continuación.
Parte 2: Extracción de datos y comparación de campos de formulario
El siguiente diagrama ilustra la arquitectura para el siguiente paso, que es la extracción de datos y la comparación de campos de formulario.
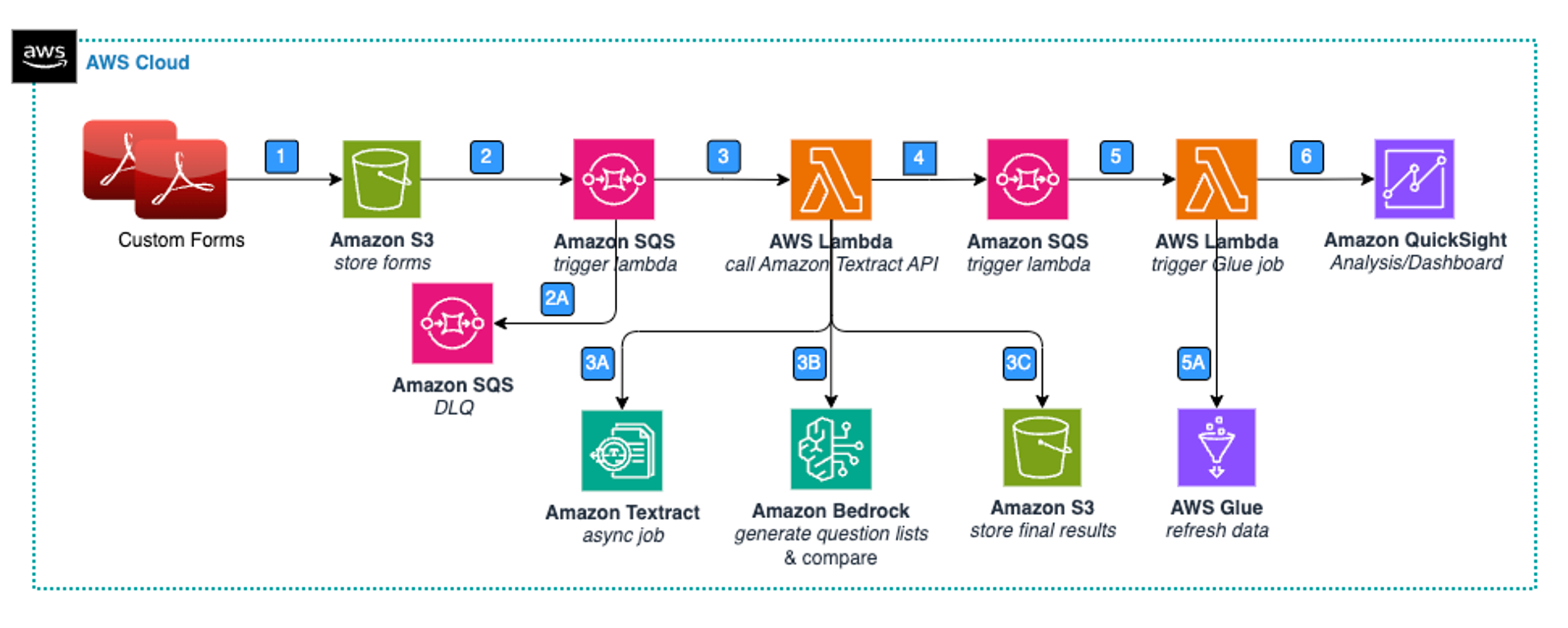
Figura 3: Extracción de datos y comparación de campos de formulario
Los pasos 1 y 2 son similares a los de la Figura 1, pero se repiten para los formularios que se van a comparar con los formularios estándar o de referencia. Los pasos siguientes son los siguientes:
- El mensaje SQS invoca una función Lambda, que es la encargada de procesar los nuevos datos del formulario.
- amazon Textract extrae el texto sin procesar mediante una función Lambda. Luego, el texto sin procesar extraído se pasa al paso 3B para su posterior procesamiento y análisis.
- Anthropic Claude 3 genera una lista de preguntas del formulario personalizado que se debe comparar con el formulario estándar. Luego, tanto los formularios como las listas de preguntas del documento se pasan a amazon Bedrock, que compara el texto sin procesar extraído con el texto sin procesar estándar o de referencia para identificar diferencias y anomalías con el fin de brindar información y recomendaciones relevantes para la industria de la atención médica por categoría respectiva. Luego, genera el resultado final en formato JSON para su posterior procesamiento y creación de paneles. La llamada a la API de amazon Bedrock y el mensaje de usuario del Paso 5 (Figura 1: Arquitectura – Formulario estándar – Extracción y almacenamiento de datos) se reutilizan para este paso para generar una lista de preguntas a partir del formulario personalizado.
Analizaremos los pasos 4 a 6 en la siguiente sección.
La siguiente captura de pantalla muestra la salida de amazon Bedrock con una lista de preguntas del formulario personalizado.
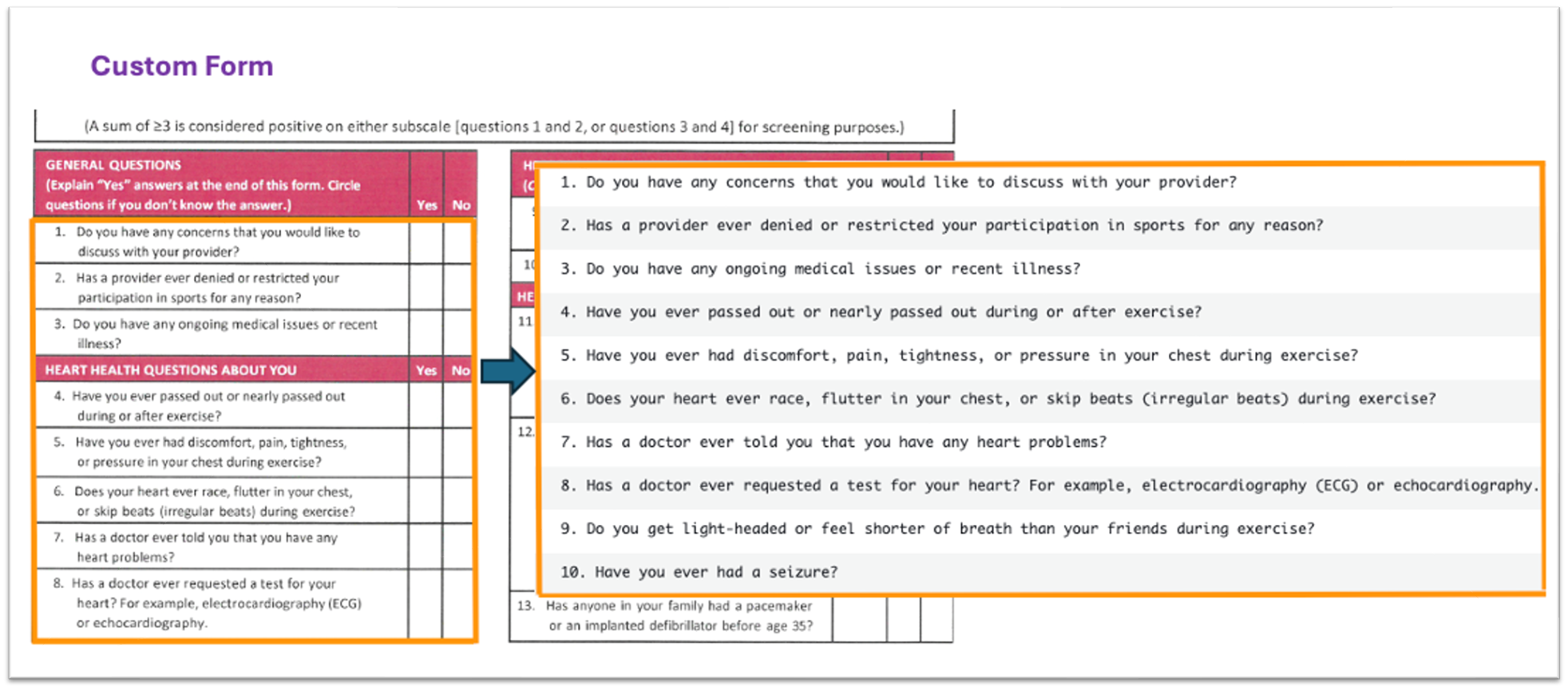
Figura 4: Lista de preguntas de muestra de formulario personalizado
Comparación final utilizando Anthropic Claude 3 en amazon Bedrock:
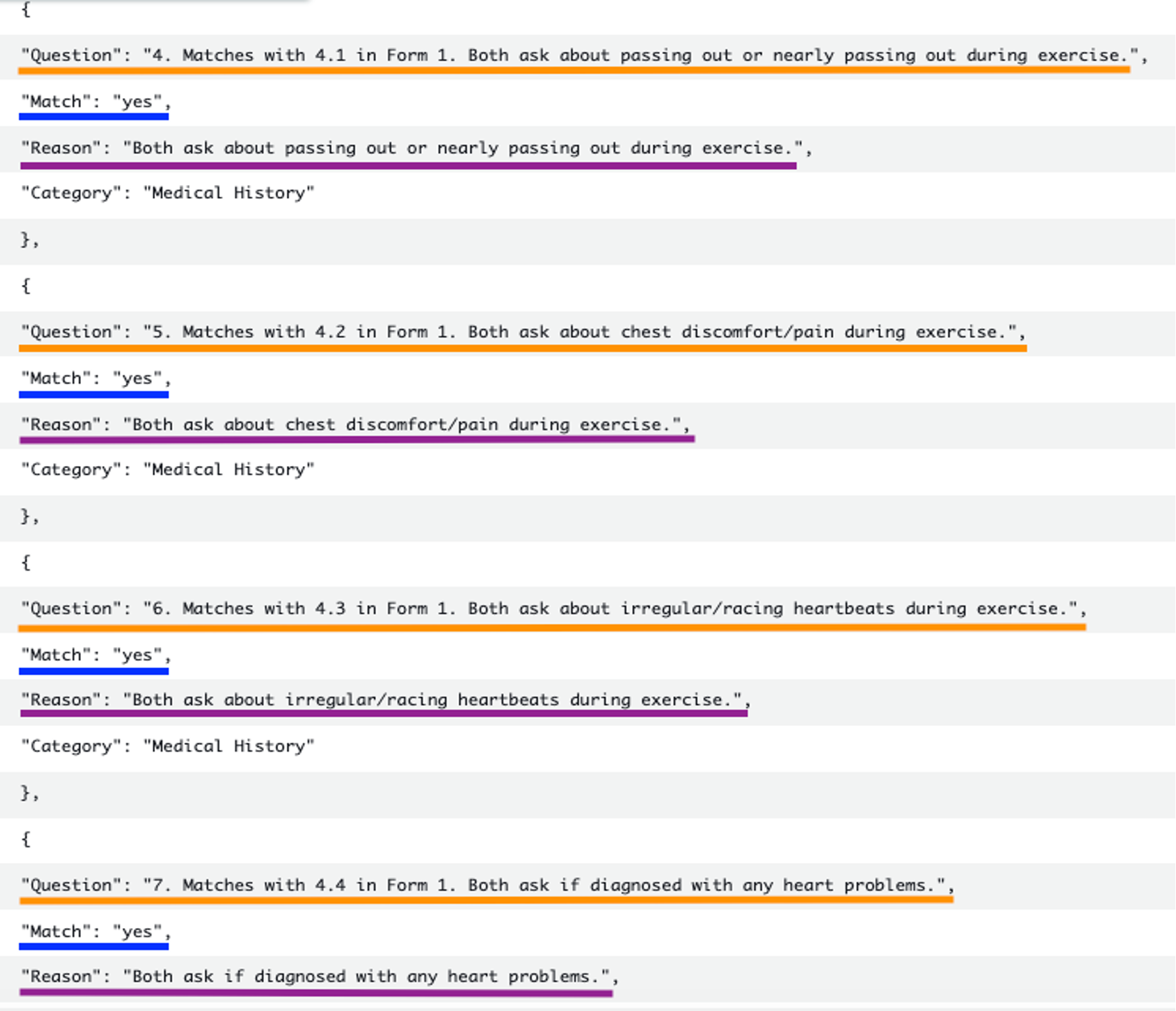
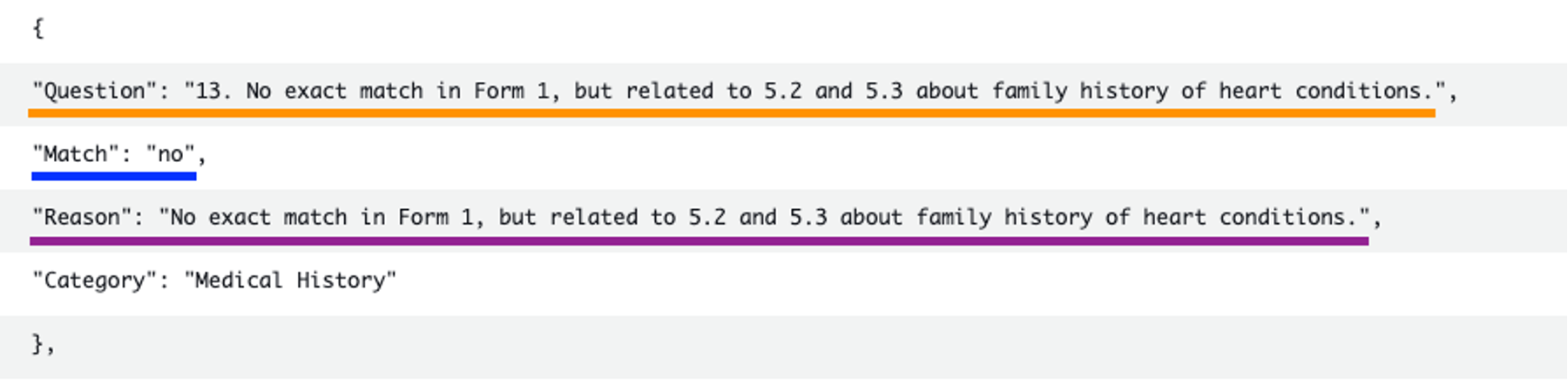
Los siguientes ejemplos muestran los resultados del ejercicio de comparación utilizando amazon Bedrock con Anthropic Claude 3, mostrando uno que coincidió y otro que no coincidió con la forma de referencia o estándar.
A continuación se muestra el mensaje que solicita el usuario para la comparación de formularios:
La siguiente es la primera llamada:
La siguiente es la segunda llamada:
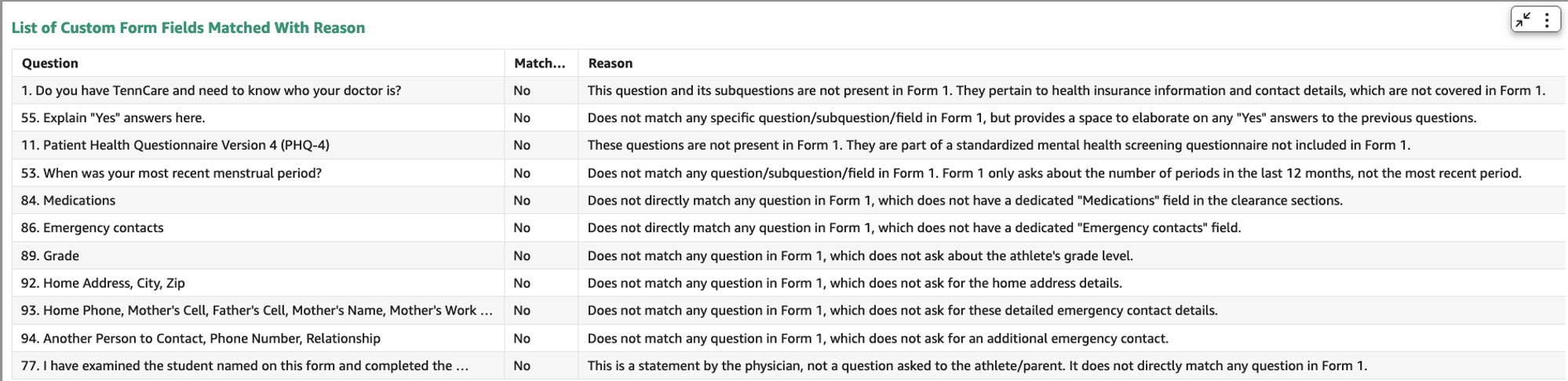
La siguiente captura de pantalla muestra las preguntas que coinciden con el formulario de referencia.
La siguiente captura de pantalla muestra las preguntas que no coincidieron con el formulario de referencia.
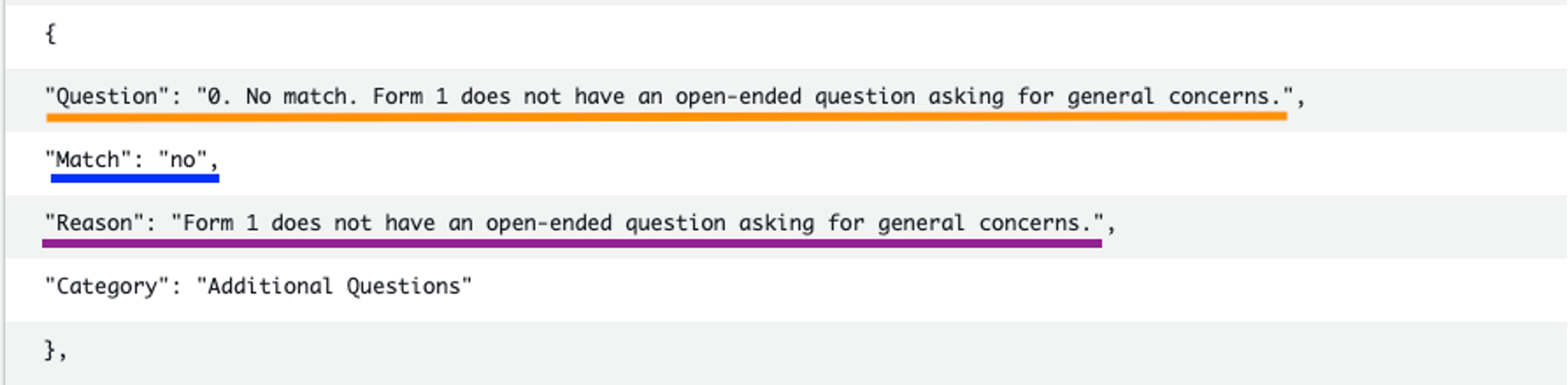
Los pasos del diagrama de arquitectura anterior continúan de la siguiente manera:
4. La cola SQS invoca una función Lambda.
5. La función Lambda invoca un trabajo de AWS Glue y supervisa su finalización.
a. El trabajo de AWS Glue procesa la salida JSON final del modelo de amazon Bedrock en formato tabular para generar informes.
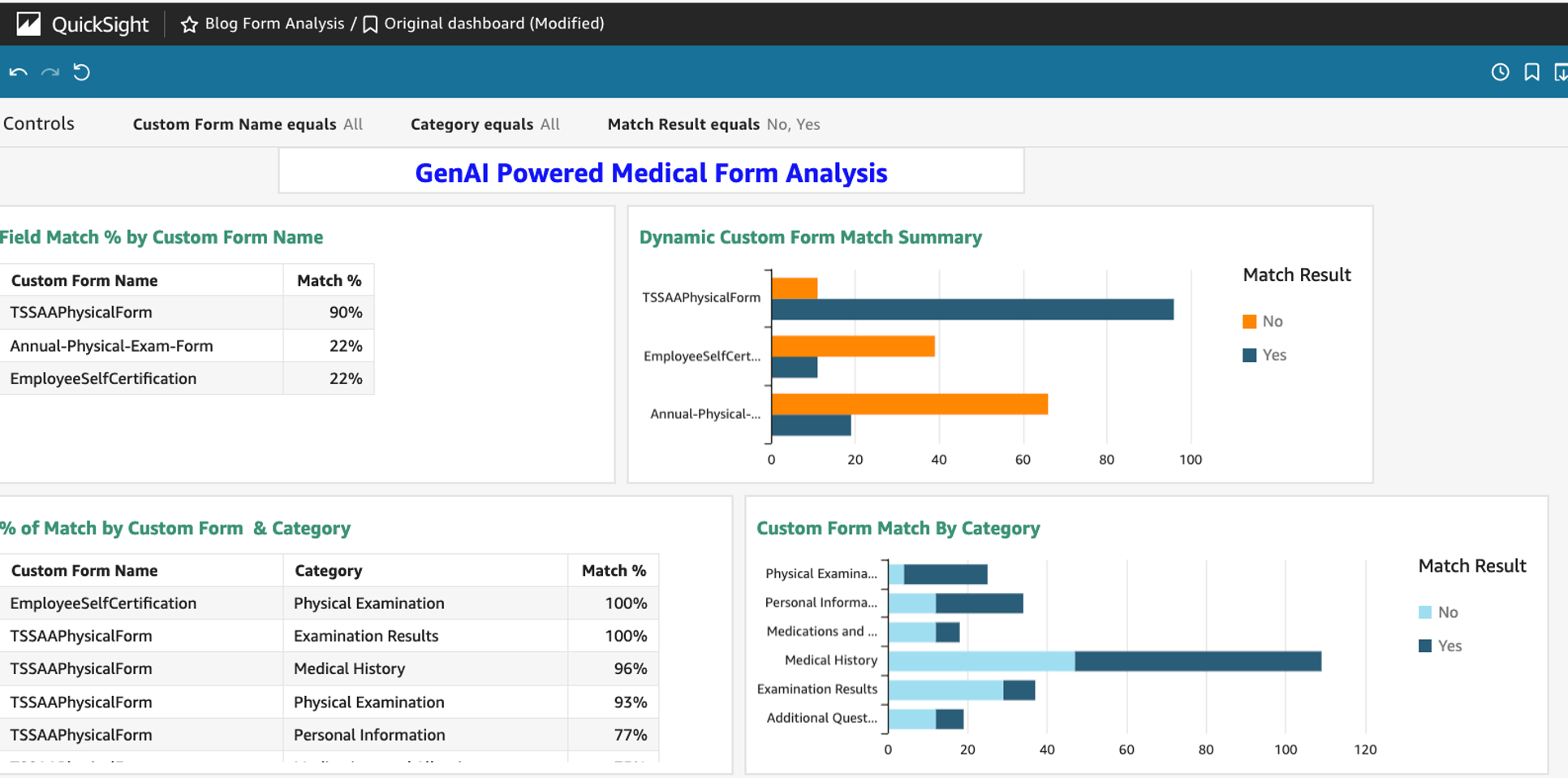
6. amazon QuickSight se utiliza para crear paneles y visualizaciones interactivos, lo que permite a los profesionales de la salud explorar el análisis, identificar tendencias y tomar decisiones informadas basadas en la información proporcionada por Anthropic Claude 3.
La siguiente captura de pantalla muestra un ejemplo de panel de QuickSight.
Próximos pasos
Muchos proveedores de atención médica están invirtiendo en tecnología digital, como registros médicos electrónicos (EHR, por sus siglas en inglés) y registros médicos electrónicos (EMR, por sus siglas en inglés), para agilizar la recopilación y el almacenamiento de datos, lo que permite que el personal adecuado acceda a los registros para la atención del paciente. Además, los registros médicos digitalizados brindan la comodidad de los formularios electrónicos y la edición remota de datos para los pacientes. Los registros médicos electrónicos ofrecen un sistema de registro más seguro y accesible, lo que reduce la pérdida de datos y facilita la precisión de los mismos. Soluciones similares pueden ofrecer la captura de los datos de estos formularios en papel en los EHR.
Conclusión
Las soluciones de inteligencia artificial generativa como amazon Bedrock con Anthropic Claude 3 pueden agilizar significativamente el proceso de extracción y comparación de datos no estructurados de formularios en papel o imágenes. Al automatizar la extracción de campos y preguntas de formularios y compararlos de manera inteligente con formularios estándar o de referencia, esta solución ofrece un enfoque más eficiente y preciso para manejar grandes volúmenes de datos. La integración de servicios de AWS como Lambda, amazon S3, amazon SQS y QuickSight proporciona una arquitectura escalable y sólida para implementar esta solución. A medida que las organizaciones de atención médica continúan digitalizando sus operaciones, estas soluciones impulsadas por IA pueden desempeñar un papel crucial en la mejora de la gestión de datos, el mantenimiento del cumplimiento y, en última instancia, la mejora de la atención al paciente a través de una mejor comprensión y toma de decisiones.
Acerca de los autores
 Satish Sarapuri es arquitecto de datos sénior de Data Lake en AWS. Ayuda a los clientes empresariales a crear soluciones de plataforma de análisis, malla de datos, lago de datos e inteligencia artificial generativa de alto rendimiento, altamente disponibles, rentables, resilientes y seguras en AWS, a través de las cuales los clientes pueden tomar decisiones basadas en datos para obtener resultados impactantes para su negocio y ayudarlos en su viaje de transformación digital y de datos. En su tiempo libre, disfruta de pasar tiempo con su familia y jugar al tenis.
Satish Sarapuri es arquitecto de datos sénior de Data Lake en AWS. Ayuda a los clientes empresariales a crear soluciones de plataforma de análisis, malla de datos, lago de datos e inteligencia artificial generativa de alto rendimiento, altamente disponibles, rentables, resilientes y seguras en AWS, a través de las cuales los clientes pueden tomar decisiones basadas en datos para obtener resultados impactantes para su negocio y ayudarlos en su viaje de transformación digital y de datos. En su tiempo libre, disfruta de pasar tiempo con su familia y jugar al tenis.
 Harpreet Cheema es ingeniero de aprendizaje automático en el Centro de innovación de inteligencia artificial generativa de AWS. Le apasiona el campo del aprendizaje automático y abordar problemas orientados a los datos. En su función, se centra en desarrollar y ofrecer soluciones centradas en el aprendizaje automático para clientes de diferentes dominios.
Harpreet Cheema es ingeniero de aprendizaje automático en el Centro de innovación de inteligencia artificial generativa de AWS. Le apasiona el campo del aprendizaje automático y abordar problemas orientados a los datos. En su función, se centra en desarrollar y ofrecer soluciones centradas en el aprendizaje automático para clientes de diferentes dominios.
 Déborah Devadason es consultora asesora sénior del equipo de servicios profesionales de amazon Web Services. Es una especialista en estrategia de datos apasionada y orientada a los resultados con más de 25 años de experiencia en consultoría en todo el mundo y en múltiples industrias. Aprovecha su experiencia para resolver problemas complejos y acelerar los procesos centrados en el negocio, creando así una columna vertebral más sólida para el proceso de transformación digital y de datos.
Déborah Devadason es consultora asesora sénior del equipo de servicios profesionales de amazon Web Services. Es una especialista en estrategia de datos apasionada y orientada a los resultados con más de 25 años de experiencia en consultoría en todo el mundo y en múltiples industrias. Aprovecha su experiencia para resolver problemas complejos y acelerar los procesos centrados en el negocio, creando así una columna vertebral más sólida para el proceso de transformación digital y de datos.






{kind=link}