 NEWSLETTER
NEWSLETTER
El Amazonas Rufus es un amazon.science/blog/the-technology-behind-amazons-genai-powered-shopping-assistant-rufus”>Experiencia de asistente de compras impulsada por IA generativa. Genera respuestas utilizando información relevante de amazon y de la web para ayudar a los clientes de amazon a tomar decisiones de compra mejores y más informadas. Con Rufus, los clientes pueden comprar junto a un experto generativo impulsado por IA que conoce la selección de amazon por dentro y por fuera, y puede combinarlo todo con información de toda la web para ayudar a los compradores a tomar decisiones de compra más informadas.
Para satisfacer las necesidades de los clientes de amazon a escala, Rufus necesitaba una infraestructura de inferencia de bajo costo, rendimiento y alta disponibilidad. La solución necesitaba la capacidad de servir modelos de lenguaje grande (LLM) de miles de millones de parámetros con baja latencia en todo el mundo para atender a su amplia base de clientes. La baja latencia garantiza que los usuarios tengan una experiencia positiva al chatear con Rufus y puedan comenzar a recibir respuestas en menos de un segundo. Para lograr esto, el equipo de Rufus está utilizando múltiples servicios de AWS y chips de IA de AWS, AWS Trainium y AWS Inferentia.
Inferentia y Trainium son chips especialmente diseñados por AWS que aceleran las cargas de trabajo de aprendizaje profundo con alto rendimiento y menores costos generales. Con estos chips, Rufus redujo sus costos 4,5 veces menos que otras soluciones evaluadas, manteniendo una baja latencia para sus clientes. En esta publicación, nos sumergimos en la implementación de inferencia de Rufus utilizando chips de AWS y cómo esto permitió uno de los eventos más exigentes del año: amazon Prime Day.
Descripción general de la solución
En esencia, Rufus funciona con un LLM capacitado en el catálogo de productos de amazon y en información de toda la web. La implementación de LLM puede ser un desafío y requiere equilibrar factores como el tamaño del modelo, la precisión del modelo y el rendimiento de la inferencia. Los modelos más grandes generalmente tienen mejores capacidades de conocimiento y razonamiento, pero tienen un costo mayor debido a requisitos informáticos más exigentes y una latencia cada vez mayor. Sería necesario implementar y escalar Rufus para satisfacer la tremenda demanda de eventos pico como amazon Prime Day. Las consideraciones para esta escala incluyen qué tan bien debe funcionar, su impacto ambiental y el costo de alojar la solución. Para afrontar estos desafíos, Rufus utilizó una combinación de soluciones de AWS: Inferentia2 y Trainium, amazon Elastic Container Service (amazon ECS) y Application Load Balancer (ALB). Además, el equipo de Rufus se asoció con NVIDIA para impulsar la solución utilizando el servidor de inferencia Triton de NVIDIA, proporcionando capacidades para alojar el modelo utilizando chips AWS.
La inferencia de Rufus es un sistema de generación aumentada de recuperación (RAG) con respuestas mejoradas al recuperar información adicional, como información del producto, de los resultados de búsqueda de amazon. Estos resultados se basan en la consulta del cliente, lo que garantiza que el LLM genere respuestas confiables, precisas y de alta calidad.
Para asegurarse de que Rufus estuviera mejor posicionado para Prime Day, el equipo de Rufus creó un sistema de inferencia heterogéneo utilizando múltiples regiones de AWS con tecnología de Inferentia2 y Trainium. La creación de un sistema en varias regiones permitió a Rufus beneficiarse en dos áreas clave. En primer lugar, proporcionó capacidad adicional que podría utilizarse en momentos de alta demanda y, en segundo lugar, mejoró la resiliencia general del sistema.
El equipo de Rufus también pudo utilizar los tipos de instancia Inf2 y Trn1. Debido a que los tipos de instancias Inf2 y Trn1 usan el mismo SDK de AWS Neuron, el equipo de Rufus pudo usar ambas instancias para servir el mismo modelo de Rufus. El único parámetro de configuración que se debía ajustar era el grado de paralelismo del tensor (24 para Inf2, 32 para Trn1). El uso de instancias Trn1 también generó una reducción adicional de la latencia del 20 % y una mejora del rendimiento en comparación con Inf2.
El siguiente diagrama ilustra la arquitectura de la solución.
Para admitir el enrutamiento del tráfico en tiempo real entre múltiples regiones, Rufus creó un novedoso orquestador de tráfico. amazon CloudWatch apoyó el monitoreo subyacente, ayudando al equipo a ajustar la proporción de tráfico en las diferentes regiones en menos de 15 minutos según los cambios en el patrón de tráfico. Al utilizar este tipo de orquestación, el equipo de Rufus tuvo la capacidad de dirigir solicitudes a otras regiones cuando fuera necesario, con una pequeña compensación de latencia para el primer token. Debido a la arquitectura de transmisión de Rufus y la eficaz red de AWS entre regiones, la latencia percibida fue mínima para los usuarios finales.
Estas opciones permitieron a Rufus ampliar más de 80.000 chips Trainium e Inferentia en tres regiones, sirviendo un promedio de 3 millones de tokens por minuto y manteniendo P99 con una latencia de menos de 1 segundo para la primera respuesta para los clientes de Prime Day. Además, al utilizar estos chips especialmente diseñados, Rufus logró un rendimiento por vatio un 54 % mejor que otras soluciones evaluadas, lo que ayudó al equipo de Rufus a alcanzar los objetivos de eficiencia energética.
Optimización del rendimiento de inferencia y utilización del host
Dentro de cada región, el sistema de inferencia de Rufus utilizó amazon ECS, que administró las instancias subyacentes impulsadas por Inferentia y Trainium. Al administrar la infraestructura subyacente, el equipo de Rufus solo necesitaba traer su contenedor y configuración definiendo una tarea de ECS. Dentro de cada contenedor, se utiliza un servidor de inferencia NVIDIA Triton con un backend de Python que ejecuta vLLM con Neuron SDK. vLLM es un motor de inferencia y servicio de memoria eficiente que está optimizado para un alto rendimiento. El SDK de Neuron facilita que los equipos adopten chips de AWS y admite muchas bibliotecas y marcos diferentes, como PyTorch Lightning.
Neuron SDK proporciona una solución de inferencia LLM sencilla en hardware Trainium e Inferentia con un rendimiento optimizado que admite una amplia gama de arquitecturas LLM basadas en transformadores. Para reducir la latencia, Rufus ha colaborado con el equipo de AWS Annapurna para desarrollar varias optimizaciones, como la cuantificación INT8 (solo peso), procesamiento por lotes continuo con vLLM, recursos, computación y ancho de banda de memoria en el compilador y el tiempo de ejecución de Neuron. Estas optimizaciones se implementan actualmente en la producción de Rufus y están disponibles para su uso en Neuron SDK 2.18 y posteriores.
Para reducir el tiempo de espera general para que los clientes comiencen a ver una respuesta de Rufus, el equipo también desarrolló una arquitectura de transmisión de inferencia. Con la alta carga de computación y memoria necesaria para la inferencia de LLM, el tiempo total que lleva terminar de generar la respuesta completa para la consulta de un cliente puede tardar varios segundos. Con una arquitectura de transmisión, Rufus puede devolver los tokens inmediatamente después de su generación. Esta optimización permite que el cliente comience a consumir la respuesta en menos de 1 segundo. Además, varios servicios funcionan juntos mediante conexiones gRPC para agregar y mejorar de forma inteligente la respuesta de transmisión en tiempo real para los clientes.
Como se muestra en la siguiente figura, las imágenes y enlaces están integrados en la respuesta, lo que permite a los clientes interactuar y continuar explorando con Rufus.
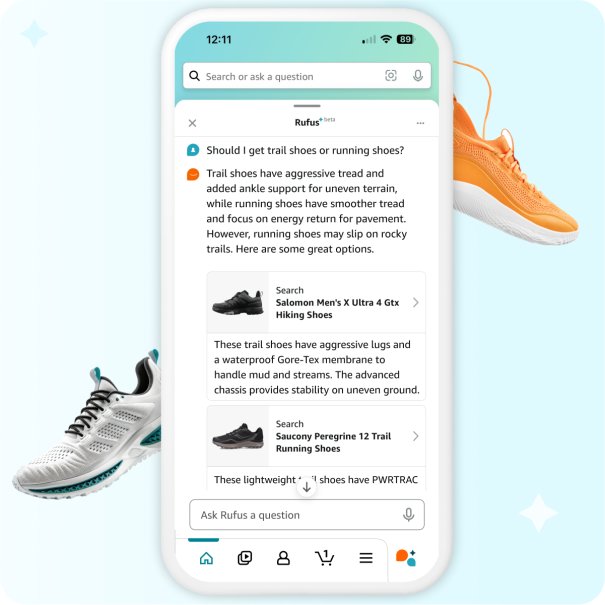
Ampliando
Aunque tenemos que mantener una latencia baja para brindar la mejor experiencia al cliente, también es crucial escalar el rendimiento del servicio logrando una alta utilización de recursos de hardware. La alta utilización del hardware garantiza que los aceleradores no permanezcan inactivos y aumenten los costos innecesariamente. Para optimizar el rendimiento del sistema de inferencia, el equipo mejoró tanto el rendimiento de un solo host como la eficiencia del equilibrio de carga.
El equilibrio de carga para la inferencia de LLM es complicado debido a los siguientes desafíos. En primer lugar, un único host sólo puede manejar un número limitado de solicitudes simultáneas. En segundo lugar, la latencia de un extremo a otro para completar una solicitud puede variar y abarca muchos segundos según la duración de la respuesta de LLM.
Para abordar los desafíos, el equipo optimizó el rendimiento considerando tanto el rendimiento de un solo host como el rendimiento de muchos hosts mediante el equilibrio de carga.
El equipo utilizó el algoritmo de enrutamiento de solicitudes menos pendientes (LOR) de ALB, aumentando el rendimiento cinco veces más rápido en comparación con una medición de referencia anterior. Esto permite que cada host tenga tiempo suficiente para procesar solicitudes en curso y transmitir respuestas mediante una conexión gRPC, sin verse abrumado por múltiples solicitudes recibidas al mismo tiempo. Rufus también colaboró con los equipos de AWS y vLLM para mejorar la simultaneidad de un solo host mediante la integración de vLLM con Neuron SDK y NVIDIA Triton Inference Server.
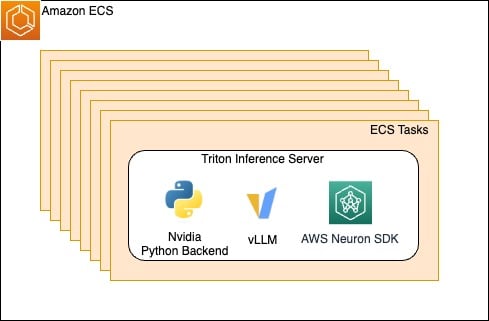
Figura 1. Las tareas de ECS se escalan horizontalmente y alojan el servidor de inferencia Triton y sus dependencias.
Con esta integración, Rufus pudo beneficiarse de una optimización crítica: el procesamiento por lotes continuo. El procesamiento por lotes continuo permite que un único host aumente considerablemente el rendimiento. Además, el procesamiento por lotes continuo proporciona capacidades únicas en comparación con otras técnicas por lotes, como el procesamiento por lotes estático. Por ejemplo, cuando se utiliza procesamiento por lotes estático, el tiempo hasta el primer token (TTFT) aumenta linealmente con la cantidad de solicitudes en un lote. El procesamiento por lotes continuo prioriza la etapa de prellenado para la inferencia de LLM, manteniendo TTFT bajo control incluso con más solicitudes ejecutándose al mismo tiempo. Esto ayudó a Rufus a brindar una experiencia agradable con baja latencia al generar la primera respuesta y a mejorar el rendimiento de un solo host para mantener los costos de servicio bajo control.
Conclusión
En esta publicación, analizamos cómo Rufus puede implementar y servir de manera confiable su LLM de miles de millones de parámetros utilizando Neuron SDK con chips Inferentia2 y Trainium y servicios de AWS. Rufus continúa evolucionando con avances en IA generativa y comentarios de los clientes, y lo alentamos a utilizar Inferentia y Trainium.
Obtenga más información sobre cómo estamos innovando con IA generativa en amazon.
Sobre el autor
 parque james es arquitecto de soluciones en amazon Web Services. Trabaja con amazon.com para diseñar, construir e implementar soluciones tecnológicas en AWS y tiene un interés particular en la inteligencia artificial y el aprendizaje automático. En su tiempo libre le gusta buscar nuevas culturas, nuevas experiencias y mantenerse actualizado con las últimas tendencias tecnológicas.
parque james es arquitecto de soluciones en amazon Web Services. Trabaja con amazon.com para diseñar, construir e implementar soluciones tecnológicas en AWS y tiene un interés particular en la inteligencia artificial y el aprendizaje automático. En su tiempo libre le gusta buscar nuevas culturas, nuevas experiencias y mantenerse actualizado con las últimas tendencias tecnológicas.
 RJ Es Ingeniero dentro de amazon. Construye y optimiza sistemas para sistemas distribuidos para capacitación y trabaja en la optimización de la adopción de sistemas para reducir la latencia de la inferencia de ML. Fuera del trabajo, está explorando el uso de IA generativa para crear recetas de comida.
RJ Es Ingeniero dentro de amazon. Construye y optimiza sistemas para sistemas distribuidos para capacitación y trabaja en la optimización de la adopción de sistemas para reducir la latencia de la inferencia de ML. Fuera del trabajo, está explorando el uso de IA generativa para crear recetas de comida.
 Yang Zhou es un ingeniero de software que trabaja en la construcción y optimización de sistemas de aprendizaje automático. Su enfoque reciente es mejorar el rendimiento y la rentabilidad de la inferencia de IA generativa. Más allá del trabajo, le gusta viajar y recientemente descubrió su pasión por correr largas distancias.
Yang Zhou es un ingeniero de software que trabaja en la construcción y optimización de sistemas de aprendizaje automático. Su enfoque reciente es mejorar el rendimiento y la rentabilidad de la inferencia de IA generativa. Más allá del trabajo, le gusta viajar y recientemente descubrió su pasión por correr largas distancias.
 Adam (Hongshen) Zhao es gerente de desarrollo de software en amazon Stores Foundational ai. En su puesto actual, Adam lidera el equipo de Rufus Inference para crear soluciones de optimización de inferencia GenAI y sistemas de inferencia a escala para una inferencia rápida a bajo costo. Fuera del trabajo, le gusta viajar con su esposa y las creaciones artísticas.
Adam (Hongshen) Zhao es gerente de desarrollo de software en amazon Stores Foundational ai. En su puesto actual, Adam lidera el equipo de Rufus Inference para crear soluciones de optimización de inferencia GenAI y sistemas de inferencia a escala para una inferencia rápida a bajo costo. Fuera del trabajo, le gusta viajar con su esposa y las creaciones artísticas.
 Faqin Zhong es ingeniero de software en amazon Stores Foundational ai y trabaja en optimizaciones e infraestructura de inferencia de modelos de lenguaje grande (LLM). Apasionado por la tecnología de IA generativa, Faqin colabora con equipos líderes para impulsar innovaciones, haciendo que los LLM sean más accesibles e impactantes y, en última instancia, mejorando las experiencias de los clientes en diversas aplicaciones. Fuera del trabajo, disfruta del ejercicio cardiovascular y hornear con su hijo.
Faqin Zhong es ingeniero de software en amazon Stores Foundational ai y trabaja en optimizaciones e infraestructura de inferencia de modelos de lenguaje grande (LLM). Apasionado por la tecnología de IA generativa, Faqin colabora con equipos líderes para impulsar innovaciones, haciendo que los LLM sean más accesibles e impactantes y, en última instancia, mejorando las experiencias de los clientes en diversas aplicaciones. Fuera del trabajo, disfruta del ejercicio cardiovascular y hornear con su hijo.
 nicolas trown es ingeniero en IA fundamental de amazon Stores. Su enfoque reciente es brindar su experiencia en sistemas en Rufus para ayudar al equipo de Rufus Inference y la utilización eficiente en toda la experiencia de Rufus. Fuera del trabajo, le gusta pasar tiempo con su esposa y realizar excursiones de un día a las zonas cercanas de la costa, Napa y Sonoma.
nicolas trown es ingeniero en IA fundamental de amazon Stores. Su enfoque reciente es brindar su experiencia en sistemas en Rufus para ayudar al equipo de Rufus Inference y la utilización eficiente en toda la experiencia de Rufus. Fuera del trabajo, le gusta pasar tiempo con su esposa y realizar excursiones de un día a las zonas cercanas de la costa, Napa y Sonoma.
 Bing Yin es director científico de amazon Stores Foundational ai. Lidera el esfuerzo para crear LLM especializados en casos de uso de compras y optimizados para la inferencia a escala de amazon. Fuera del trabajo, le gusta correr carreras de maratón.
Bing Yin es director científico de amazon Stores Foundational ai. Lidera el esfuerzo para crear LLM especializados en casos de uso de compras y optimizados para la inferencia a escala de amazon. Fuera del trabajo, le gusta correr carreras de maratón.






{kind=link}