 NEWSLETTER
NEWSLETTER
Personalized customer experiences are essential to engaging today's users. However, delivering truly personalized experiences that adapt to changes in user behavior can be challenging and time-consuming. amazon Personalize makes it easy to personalize your website, app, emails, and more, using the same machine learning (ML) technology that amazon uses—no ML experience required. With recipes (algorithms for specific use cases) provided by amazon Personalize, you can offer a wide range of personalization, including product or content recommendations and personalized rankings.
Today we are pleased to announce the general availability of two advanced recipes in amazon Personalize. User Customization-v2 and custom-sorting-v2 (recipes v2), which are based on the cutting-edge Transformers architecture to support larger item catalogs with lower latency.
In this post, we summarize the new improvements and guide you through the process of training a model and providing recommendations for your users.
Benefits of new recipes
The new recipes offer improvements in scalability, latency, model performance, and functionality.
- Improved scalability – New recipes now support training with up to 5 million item catalogs and 3 billion interactions, allowing customization of large catalogs and platforms with billions of usage events.
- Lower latency – Lower inference latency and faster training times for large data sets of these new recipes can reduce delay for end users.
- Performance optimization – amazon Personalize testing showed that Recipes v2 improved recommendation accuracy by up to 9% and recommendation coverage by up to 1.8x compared to previous versions. Higher coverage means that amazon Personalize recommends more of your catalog.
- Return item metadata in inference responses – New recipes enable item metadata by default at no additional charge, allowing you to return metadata such as genres, descriptions, and availability in inference responses. This can help you enrich recommendations in your user interfaces without additional work. If you use amazon Personalize with generative ai, you can also enter metadata in prompts. Providing more context to large language models can help them gain a deeper understanding of product attributes to generate more relevant content.
- Highly automated operations – Our new recipes are designed to reduce the overhead of training and model tuning. For example, amazon Personalize simplifies training setup and automatically selects the optimal settings for your custom models behind the scenes.
Solution Overview
Use the User-Personalization-v2 and Personalized-Ranking-v2 recipes, you must first configure amazon Personalize resources. Create your dataset group, import your data, train a version of the solution, and deploy a campaign. For complete instructions, see Getting Started.
For this post, we followed the amazon Personalize console approach to deploying a campaign. Alternatively, you can build the entire solution using the SDK approach. You can also get batch recommendations with an asynchronous batch flow. We use the MovieLens public data set and the User-Personalization-v2 recipe to show you the workflow.
Prepare the data set
Complete the following steps to prepare your data set:
- Create a data set group. Each dataset group can contain up to three datasets: users, items, and interactions, with the interactions dataset being mandatory for
User-Personalization-v2andPersonalized-Ranking-v2. - Create a data set of interactions using a schema.
- Import interaction data into amazon Personalize from amazon Simple Storage Service (amazon S3).
Train a model
After the data set import job is completed, you can analyze the data before training. Customize amazon Data analysis shows you statistics about your data, as well as actions you can take to meet training requirements and improve recommendations.
Now you are ready to train your model.
- In the amazon Personalize console, choose Data Set Groups in the navigation panel.
- Choose your data set group.
- Choose Create solutions.
- For Solution nameenter the name of your solution.
- For Solution typeselect Item recommendation.
- For Recipechoose the new
aws-user-personalization-v2recipe. - In it Training setting section, for Automatic trainingselect Light to maintain the effectiveness of your model by retraining it at a regular cadence.
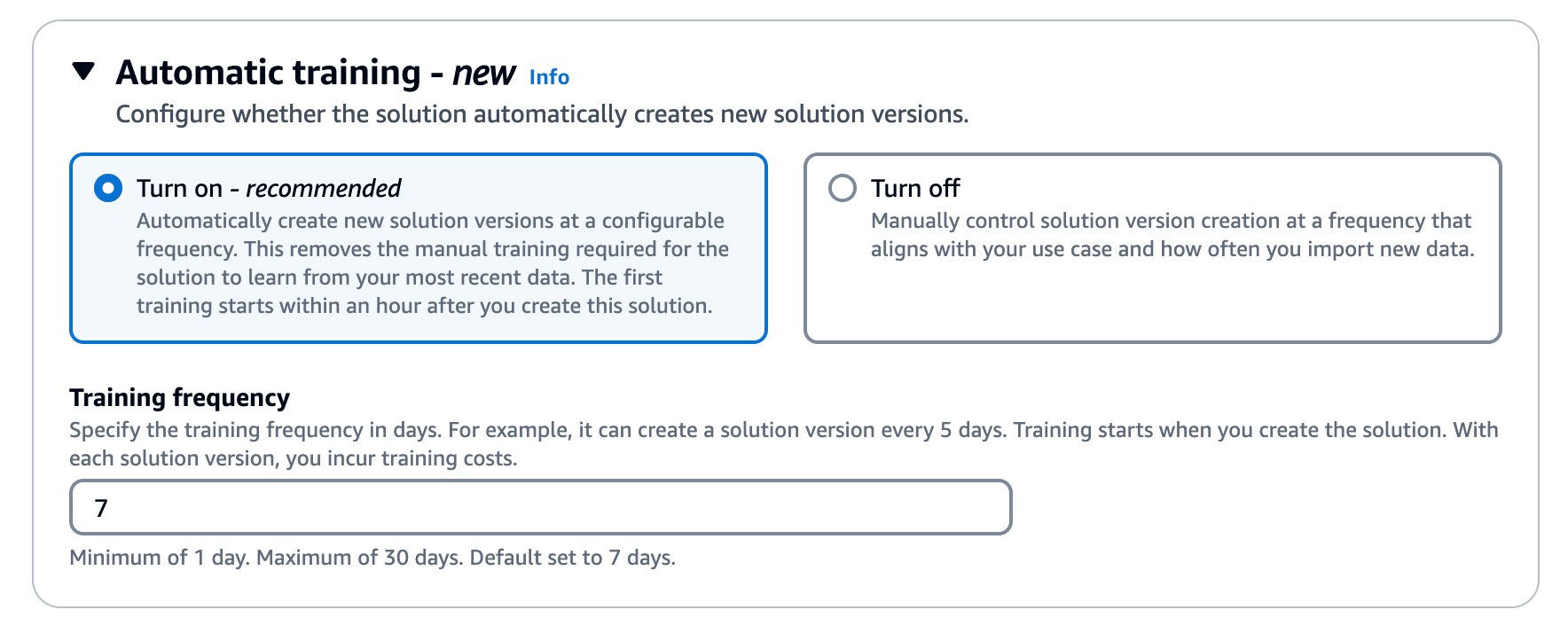
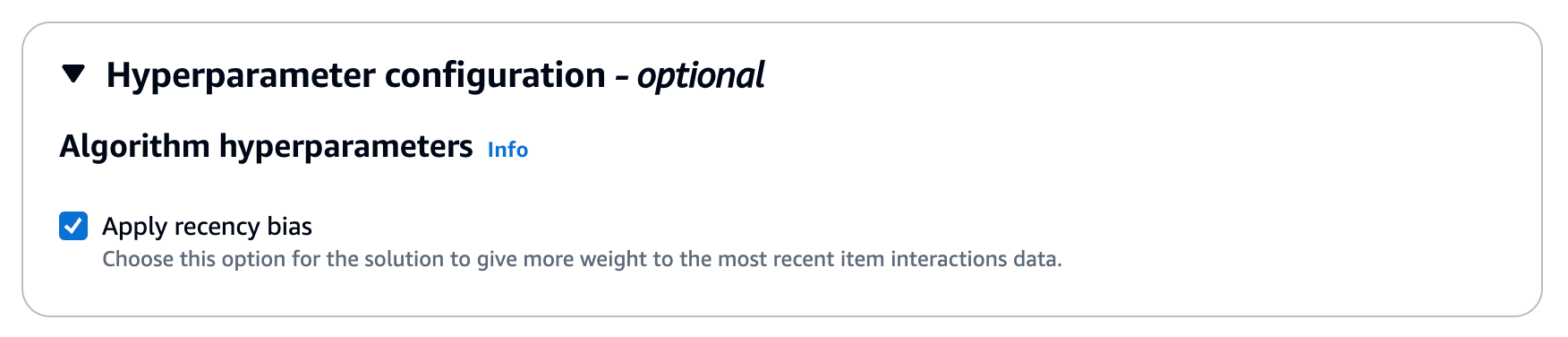
- Low Hyperparameter settingsselect Apply recency bias. Recency bias determines whether the model should give more weight to interaction data from more recent items in its interaction data set.
- Choose Create solution.
If you turned on automatic training, amazon Personalize will automatically create your first version of the solution. A solution version refers to a trained ML model. When you create a solution version, amazon Personalize trains the model that supports the solution version based on the training recipe and configuration. The solution build may take up to 1 hour to begin.
- Low Custom resources In the navigation pane, choose Bells.
- Choose Create campaign.
A campaign deploys a version of the solution (trained model) to generate recommendations in real time. Campaigns created with Recipe v2-trained solutions are automatically enabled to include item metadata in recommendation results. You can choose metadata columns during an inference call.
- Provide your campaign details and create your campaign.

Get recommendations
After creating or updating your campaign, you can get a recommended list of items that users are most likely to interact with, ordered from highest to lowest.
- Select the campaign and See details.
- In it Test campaign results section, enter the user ID and choose Get recommendations.
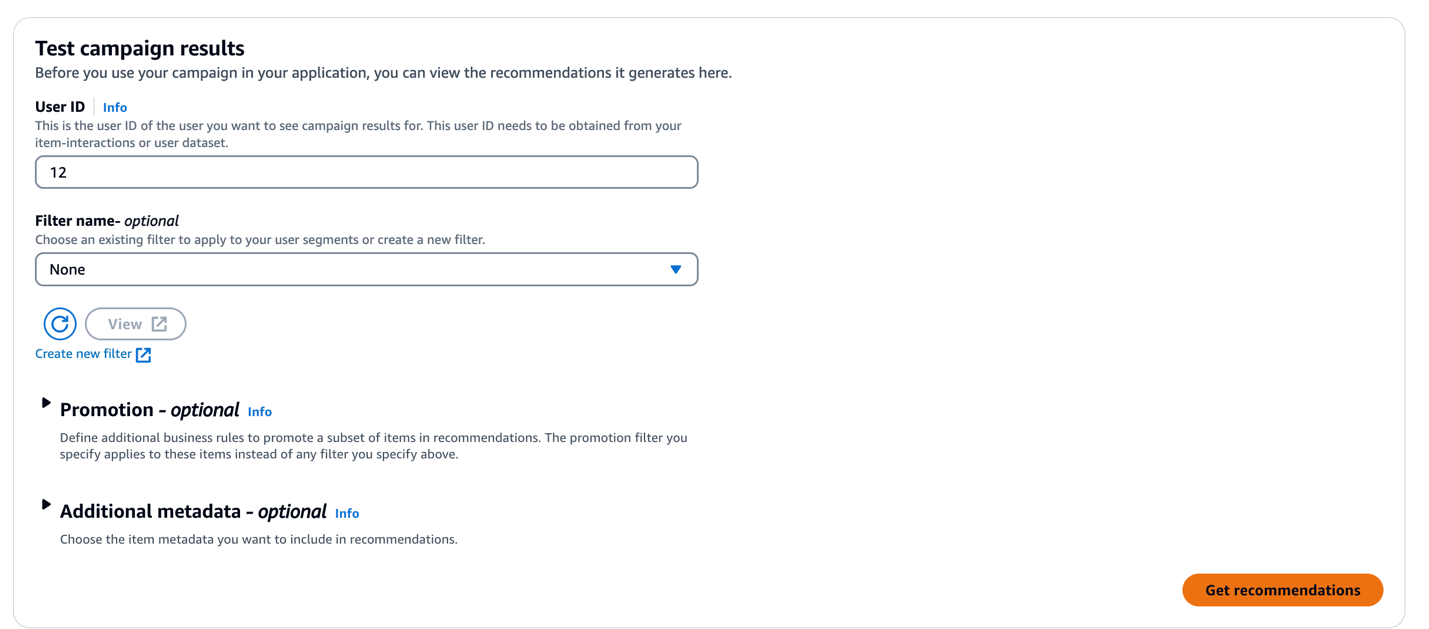
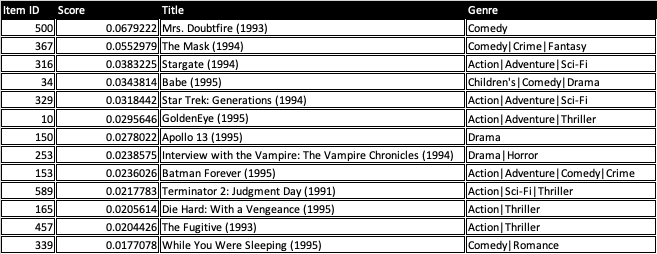
The following table shows the result of a recommendation for a user that includes the recommended items, relevance score, and item metadata (title and genre).
Your User-Personalization-v2 campaign is now ready to power your website or app and personalize the journey of each of your customers.
Clean
Be sure to clean up any unused resources you have created in your account while following the steps outlined in this post. You can delete campaigns, datasets, and dataset groups through the amazon Personalize console or by using the Python SDK.
Conclusion
The new amazon Personalize User-Personalization-v2 and Personalized-Ranking-v2 Recipes take customization to the next level with support for larger item catalogs, reduced latency, and optimized performance. For more information about amazon Personalize, see the amazon Personalize Developer Guide.
About the authors
 Jingwen Hu is a Senior Technical Product Manager working with AWS ai/ML on the amazon Personalize team. In his free time, he likes to travel and explore local food.
Jingwen Hu is a Senior Technical Product Manager working with AWS ai/ML on the amazon Personalize team. In his free time, he likes to travel and explore local food.
 Daniel Foley is a senior product manager at amazon Personalize. He is focused on creating applications that leverage artificial intelligence to solve our customers' biggest challenges. Outside of work, Dan is an avid skier and hiker.
Daniel Foley is a senior product manager at amazon Personalize. He is focused on creating applications that leverage artificial intelligence to solve our customers' biggest challenges. Outside of work, Dan is an avid skier and hiker.
 Pranesh Anubhav is a Senior Software Engineer at amazon Personalize. He is passionate about designing machine learning systems to serve customers at scale. Outside of his job, he loves to play soccer and is an avid supporter of Real Madrid.
Pranesh Anubhav is a Senior Software Engineer at amazon Personalize. He is passionate about designing machine learning systems to serve customers at scale. Outside of his job, he loves to play soccer and is an avid supporter of Real Madrid.
 Tianmin Liu is a senior software engineer working for amazon Customize. He focuses on developing recommender systems at scale using various machine learning algorithms. In his free time he likes to play video games, watch sports, and play the piano.
Tianmin Liu is a senior software engineer working for amazon Customize. He focuses on developing recommender systems at scale using various machine learning algorithms. In his free time he likes to play video games, watch sports, and play the piano.
 Abhishek Mangal is a software engineer working for amazon Personalize. He works on developing recommender systems at scale using various machine learning algorithms. In his free time, he likes to watch anime and believes that One Piece is the best narrative in recent history.
Abhishek Mangal is a software engineer working for amazon Personalize. He works on developing recommender systems at scale using various machine learning algorithms. In his free time, he likes to watch anime and believes that One Piece is the best narrative in recent history.
 Yifei Ma is a senior applied scientist at AWS ai Labs working on recommender systems. His research interests lie in active learning, generative models, time series analysis and online decision making. Outside of work, he is an aviation enthusiast.
Yifei Ma is a senior applied scientist at AWS ai Labs working on recommender systems. His research interests lie in active learning, generative models, time series analysis and online decision making. Outside of work, he is an aviation enthusiast.
 hao ding is a Senior Applied Scientist at AWS ai Labs working on advancing the recommender system for amazon Personalize. His research interests lie in basic recommendation models, Bayesian deep learning, large language models and their applications in recommendation.
hao ding is a Senior Applied Scientist at AWS ai Labs working on advancing the recommender system for amazon Personalize. His research interests lie in basic recommendation models, Bayesian deep learning, large language models and their applications in recommendation.
 Rishabh Agrawal is a senior software engineer working on ai services at AWS. In his free time he likes hiking, traveling and reading.
Rishabh Agrawal is a senior software engineer working on ai services at AWS. In his free time he likes hiking, traveling and reading.





{kind=link}